
python 图像处理模块
1. 安装 pytesseract模块是会自动安装Pillow模块。
pillow 为标准图像处理库
手册地址 http://pillow-cn.readthedocs.io/zh_CN/latest/index.html
pytesseract 模块用于文字识别
pip3 install pytesseract
2. 安装 tesseract-ocr 这个用于文字识别
pytesseract 需要调用它
https://github.com/tesseract-ocr/tesseract/wiki
参考:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/0014320027235877860c87af5544f25a8deeb55141d60c5000
https://blog.csdn.net/dcba2014/article/details/78969658
https://blog.csdn.net/iodjSVf8U1J7KYc/article/details/79308086
3. 常见错误:
1. 注意使用python版本和安装模块的版本
2. ImageOps 需要使用 from PIL import ImageOps
不能直接使用PIL.ImageOps
3. 先引入
from lxml import html
from pyquery import PyQuery as pq
在引入
# 图片识别
from PIL import ImageOps
from PIL import Image
import pytesseract
发现报错误OSError: codec configuration error when reading image file
问题感觉比较奇葩
解决: 将图片库的引入在 pqquery 之前
例子1
转自:https://www.cnblogs.com/MrRead/p/7656800.html 有简单修改 让代码能在python3上运行
1、验证码的识别是有针对性的,不同的系统、应用的验证码区别有大有小,只要处理好图片,利用好pytesseract,一般的验证码都可以识别
2、我在识别验证码的路上走了很多弯路,重点应该放在怎么把图片处理成这个样子,方便pytesseract的识别,以提高成功率
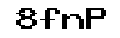
3、原图为:
# 图片识别
from PIL import ImageOps
from PIL import Image
import pytesseract
def initTable(threshold=140):
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
return table
im = Image.open('8fnp.png')
#图片的处理过程
im = im.convert('L')
binaryImage = im.point(initTable(), '1')
im1 = binaryImage.convert('L')
im2 = ImageOps.invert(im1)
im3 = im2.convert('1')
im4 = im3.convert('L')
#将图片中字符裁剪保留
box = (30,10,90,28)
region = im4.crop(box)
#将图片字符放大
out = region.resize((120,38))
asd = pytesseract.image_to_string(out)
print(asd)
print (out.show())
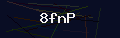
上面代码可以识别出图片验证码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号