Java编程的逻辑 (88) - 正则表达式 (上)
本系列文章经补充和完善,已修订整理成书《Java编程的逻辑》,由机械工业出版社华章分社出版,于2018年1月上市热销,读者好评如潮!各大网店和书店有售,欢迎购买,京东自营链接:http://item.jd.com/12299018.html

上节我们提到了正则表达式,它提升了文本处理的表达能力,本节就来讨论正则表达式,它是什么?有什么用?各种特殊字符都是什么含义?如何用Java借助正则表达式处理文本?都有哪些常用正则表达式?由于内容较多,我们分为三节进行探讨,本节先简要探讨正则表达式的语法。
正则表达式是一串字符,它描述了一个文本模式,利用它可以方便的处理文本,包括文本的查找、替换、验证、切分等。
正则表达式中的字符有两类,一类是普通字符,就是匹配字符本身,另一类是元字符,这些字符有特殊含义,这些元字符及其特殊含义就构成了正则表达式的语法。
正则表达式有一个比较长的历史,各种与文本处理有关的工具、编辑器和系统都支持正则表达式,大部分编程语言也都支持正则表达式。虽然都叫正则表达式,但由于历史原因,不同语言、系统和工具的语法不太一样,本文主要针对Java语言,其他语言可能有所差别。
下面,我们就来简要介绍正则表达式的语法,我们先分为以下部分分别介绍:
- 单个字符
- 字符组
- 量词
- 分组
- 特殊边界匹配
- 环视边界匹配
最后针对转义、匹配模式和各种语法进行总结。
单个字符
大部分的单个字符就是用字符本身表示的,比如字符'0','3','a','马'等,但有一些单个字符使用多个字符表示,这些字符都以斜杠'\'开头,比如:
- 特殊字符,比如tab字符'\t',换行符'\n',回车符'\r'等;
- 八进制表示的字符,以\0开头,后跟1到3位数字,比如\0141,对应的是ASCII编码为97的字符,即字符'a';
- 十六进制表示的字符,以\x开头,后跟两位字符,比如\x6A,对应的是ASCII编码为106的字符,即字符'j';
- Unicode编号表示的字符,以\u开头,后跟四位字符,比如\u9A6C,表示的是中文字符'马',这只能表示编号在0xFFFF以下的字符,如果超出0XFFFF,使用\x{...}形式,比如对于字符'💎',可以使用\x{1f48e};
- 斜杠\本身,斜杠\是一个元字符,如果要匹配它自身,使用两个斜杠表示,即'\\';
- 元字符本身,除了'\',正则表达式中还有很多元字符,比如. * ? +等,要匹配这些元字符自身,需要在前面加转义字符'\',比如'\.'。
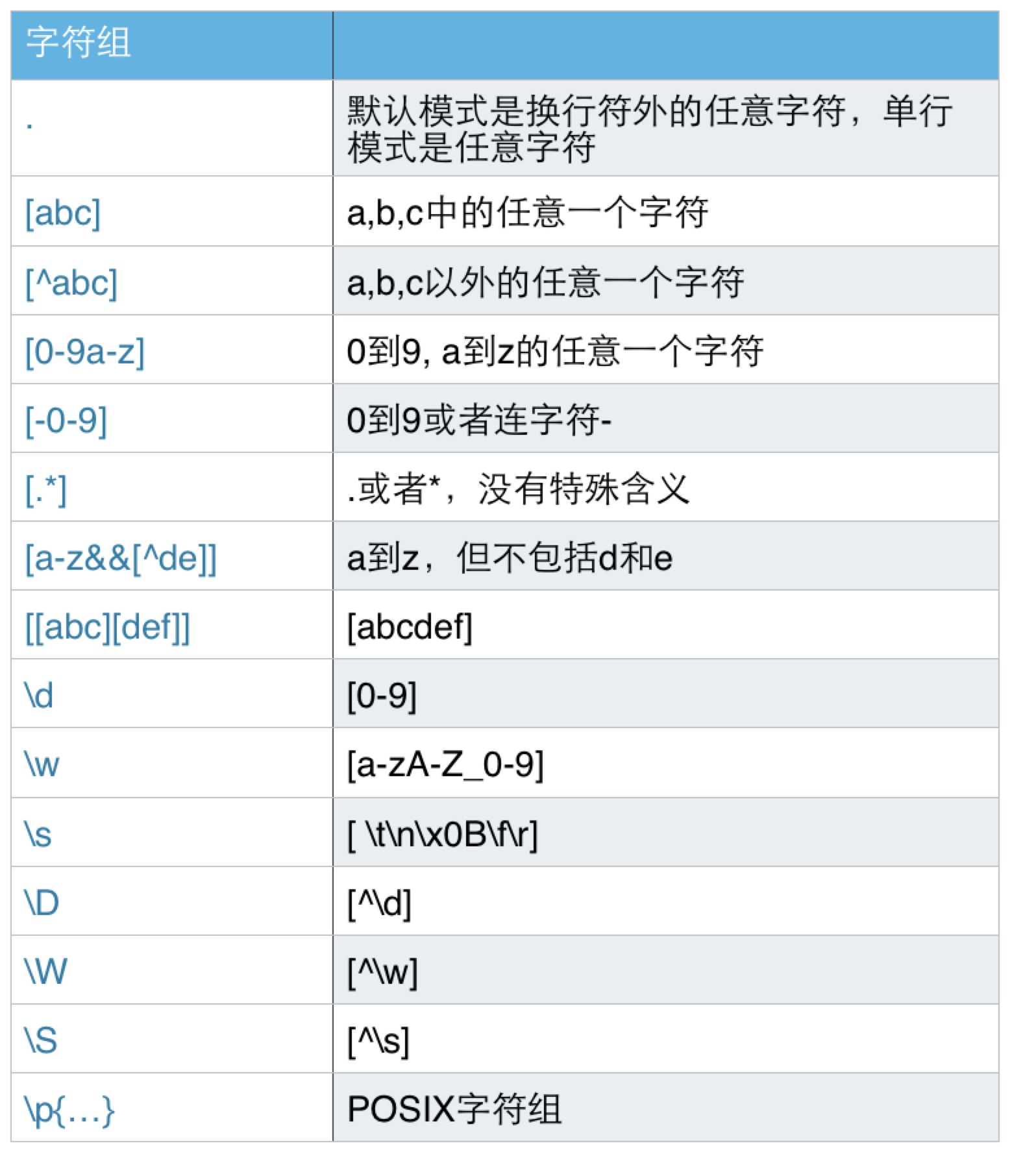
字符组
任意字符
点号字符'.'是一个元字符,默认模式下,它匹配除了换行符以外的任意字符,比如正则表达式:
a.f
既匹配字符串"abf",也匹配"acf"。
可以指定另外一种匹配模式,一般称为单行匹配模式或者叫点号匹配模式,在此模式下,'.'匹配任意字符,包括换行符。
可以有两种方式指定匹配模式,一种是在正则表达式中,以(?s)开头,s表示single line,即单行匹配模式,比如:
(?s)a.f
另外一种是在程序中指定,在Java中,对应的模式常量是Pattern.DOTALL,下节我们再介绍Java API。
指定的多个字符之一
在单个字符和任意字符之间,有一个字符组的概念,匹配组中的任意一个字符,用中括号[]表示,比如:
[abcd]
匹配a, b, c, d中的任意一个字符。
[0123456789]
匹配任意一个数字字符。
字符区间
为方便表示连续的多个字符,字符组中可以使用连字符'-',比如:
[0-9] [a-z]
可以有多个连续空间,可以有其他普通字符,比如:
[0-9a-zA-Z_]
在字符组中,'-'是一个元字符,如果要匹配它自身,可以使用转义,即'\-',或者把它放在字符组的最前面,比如:
[-0-9]
排除型字符组
字符组支持排除的概念,在[后紧跟一个字符^,比如:
[^abcd]
表示匹配除了a, b, c, d以外的任意一个字符。
[^0-9]
表示匹配一个非数字字符。
排除不是不能匹配,而是匹配一个指定字符组以外的字符,要表达不能匹配的含义,需要使用后文介绍的环视语法。
^只有在字符组的开头才是元字符,如果不在开头,就是普通字符,匹配它自身,比如:
[a^b]
就是匹配字符a, ^或b。
字符组内的元字符
在字符组中,除了^ - [ ] \外,其他在字符组外的元字符不再具备特殊含义,变成了普通字符,比如'.',[.*]就是匹配'.'或者'*'本身。
字符组运算
字符组内可以包含字符组,比如:
[[abc][def]]
最后的字符组等同于[abcdef],内部多个字符组等同于并集运算。
字符组内还支持交集运算,语法是使用&&,比如:
[a-z&&[^de]]
匹配的字符是a到z,但不能是d或e。
需要注意的是,其他语言可能不支持字符组运算。
预定义的字符组
有一些特殊的以\开头的字符,表示一些预定义的字符组,比如:
- \d:d表示digit,匹配一个数字字符,等同于[0-9] ;
- \w:w表示word,匹配一个单词字符,等同于[a-zA-Z_0-9];
- \s:s表示space,匹配一个空白字符,等同于[ \t\n\x0B\f\r]。
它们都有对应的排除型字符组,用大写表示,即:
- \D:匹配一个非数字字符,即[^\d] ;
- \W:匹配一个非单词字符,即[^\w];
- \S:匹配一个非空白字符,即[^\s]。
POSIX字符组
还有一类字符组,称为POSIX字符组,POSIX是一个标准,POSIX字符组是POSIX标准定义的一些字符组,在Java中,这些字符组的形式是\p{...},比如:
- \p{Lower}:小写字母,等同于[a-z];
- \p{Upper}:大写字母,等同于[A-Z];
- \p{Digit}:数字,等同于[0-9];
- \p{Punct} :标点符号,匹配!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~中的一个。
POSIX字符组比较多,本文就不列举了。
量词
常用量词 + * ?
量词指的是指定出现次数的元字符,有三个常见的元字符+ * ?:
- +:表示前面字符的一次或多次出现,比如正则表达式ab+c,既能匹配abc,也能匹配abbc,或abbbc;
- *:表示前面字符的零次或多次出现,比如正则表达式ab*c,既能匹配abc,也能匹配ac,或abbbc;
- ?:表示前面字符可能出现,也可能不出现,比如正则表达式ab?c,既能匹配abc,也能匹配ac,但不能匹配abbc。
通用量词 {m,n}
更为通用的表示出现次数的语法是{m,n},出现次数从m到n,包括m和n,如果n没有限制,可以省略,如果m和n一样,可以写为{m},比如:
- ab{1,10}c:b可以出现1次到10次
- ab{3}c:b必须出现三次,即只能匹配abbbc
- ab{1,}c:与ab+c一样
- ab{0,}c:与ab*c一样
- ab{0,1}c:与ab?c一样
需要注意的是,语法必须是严格的{m,n}形式,逗号左右不能有空格。
?, *, +, {是元字符,如果要匹配这些字符本身,需要使用'\'转义,比如
a\*b
匹配字符串"a*b"。
这些量词出现在字符组中时,不是元字符,比如表达式
[?*+{]
就是匹配其中一个字符本身。
贪婪与懒惰
关于量词,它们的默认匹配是贪婪的,什么意思呢?看个例子,正则表达式是:
<a>.*</a>
如果要处理的字符串是:
<a>first</a><a>second</a>
目的是想得到两个匹配,一个匹配:
<a>first</a>
另一个匹配:
<a>second</a>
但默认情况下,得到的结果却只有一个匹配,匹配所有内容。
这是因为.*可以匹配第一个<a>和最后一个</a>之间的所有字符,只要能匹配,.*就尽量往后匹配,它是贪婪的。如果希望在碰到第一个匹配时就停止呢?应该使用懒惰量词,在量词的后面加一个符号'?',针对上例,将表达式改为:
<a>.*?</a>
就能得到期望的结果。
所有量词都有对应的懒惰形式,比如:x??, x*?, x+?, x{m,n}?等。
分组
表达式可以用括号()括起来,表示一个分组,比如a(bc)d,bc就是一个分组,分组可以嵌套,比如a(de(fg))。
捕获分组
分组默认都有一个编号,按照括号的出现顺序,从1开始,从左到右依次递增,比如表达式:
a(bc)((de)(fg))
字符串abcdefg匹配这个表达式,第1个分组为bc,第2个为defg,第3个为de,第4个为fg。分组0是一个特殊分组,内容是整个匹配的字符串,这里是abcdefg。
分组匹配的子字符串可以在后续访问,好像被捕获了一样,所以默认分组被称为捕获分组。关于如何在Java中访问和使用捕获分组,我们下节再介绍。
分组量词
可以对分组使用量词,表示分组的出现次数,比如a(bc)+d,表示bc出现一次或多次。
分组多选
中括号[]表示匹配其中的一个字符,括号()和元字符'|'一起,可以表示匹配其中的一个子表达式,比如
(http|ftp|file)
匹配http或ftp或file。
需要注意区分|和[],|用于[]中不再有特殊含义,比如
[a|b]
它的含义不是匹配a或b,而是a或|或b。
回溯引用
在正则表达式中,可以使用斜杠\加分组编号引用之前匹配的分组,这称之为回溯引用,比如:
<(\w+)>(.*)</\1>
\1匹配之前的第一个分组(\w+),这个表达式可以匹配类似如下字符串:
<title>bc</title>
这里,第一个分组是"title"。
命名分组
使用数字引用分组,可能容易出现混乱,可以对分组进行命名,通过名字引用之前的分组,对分组命名的语法是(?<name>X),引用分组的语法是\k<name>,比如,上面的例子可以写为:
<(?<tag>\w+)>(.*)</\k<tag>>
非捕获分组
默认分组都称之为捕获分组,即分组匹配的内容被捕获了,可以在后续被引用,实现捕获分组有一定的成本,为了提高性能,如果分组后续不需要被引用,可以改为非捕获分组,语法是(?:...),比如:
(?:abc|def)
特殊边界匹配
在正则表达式中,除了可以指定字符需满足什么条件,还可以指定字符的边界需满足什么条件,或者说匹配特定的边界,常用的表示特殊边界的元字符有^, $, \A, \Z, \z和\b。
边界 ^
默认情况下,^匹配整个字符串的开始,^abc表示整个字符串必须以abc开始。
需要注意的是^的含义,在字符组中它表示排除,但在字符组外,它匹配开始,比如表达式^[^abc],表示以一个不是a,b,c的字符开始。
边界 $
默认情况下,$匹配整个字符串的结束,不过,如果整个字符串以换行符结束,$匹配的是换行符之前的边界,比如表达式abc$,表示整个表达式以abc结束,或者以abc\r\n或abc\n结束。
多行匹配模式
以上^和$的含义是默认模式下的,可以指定另外一种匹配模式,多行匹配模式,在此模式下,会以行为单位进行匹配,^匹配的是行开始,$匹配的是行结束,比如表达式是^abc$,字符串是"abc\nabc\r\n",就会有两个匹配。
可以有两种方式指定匹配模式,一种是在正则表达式中,以(?m)开头,m表示multiline,即多行匹配模式,上面的正则表达式可以写为:
(?m)^abc$
另外一种是在程序中指定,在Java中,对应的模式常量是Pattern.MULTILINE,下节我们再介绍Java API。
需要说明的是,多行模式和之前介绍的单行模式容易混淆,其实,它们之间没有关系,单行模式影响的是字符'.'的匹配规则,使得'.'可以匹配换行符,多行模式影响的是^和$的匹配规则,使得它们可以匹配行的开始和结束,两个模式可以一起使用。
边界 \A
\A与^类似,但不管什么模式,它匹配的总是整个字符串的开始边界。
边界 \Z和\z
\Z和\z与$类似,但不管什么模式,它们匹配的总是整个字符串的结束,\Z与\z的区别是,如果字符串以换行符结束,\Z与$一样,匹配的是换行符之前的边界,而\z匹配的总是结束边界。在进行输入验证的时候,为了确保输入最后没有多余的换行符,可以使用\z进行匹配。
单词边界 \b
\b匹配的是单词边界,比如\bcat\b,匹配的是完整的单词cat,它不能匹配category,\b匹配的不是一个具体的字符,而是一种边界,这种边界满足一个要求,即一边是单词字符,另一边不是单词字符。在Java中,\b识别的单词字符除了\w,还包括中文字符。
到底什么是边界匹配?
边界匹配可能难以理解,我们强调下,到底什么是边界匹配。边界匹配不同于字符匹配,可以认为,在一个字符串中,每个字符的两边都是边界,而上面介绍的这些特殊字符,匹配的都不是字符,而是特定的边界,看个例子:

上面的字符串是"a cat\n",我们用粗线显示出了每个字符两边的边界,并且显示出了每个边界与哪些边界元字符匹配。
环视边界匹配
定义
对于边界匹配,除了使用上面介绍的边界元字符,还有一种更为通用的方式,那就是环视,环视的字面意思就是左右看看,需要左右符合一些条件,本质上,它也是匹配边界,对边界有一些要求,这个要求是针对左边或右边的字符串的,根据要求不同,分为四种环视:
- 肯定顺序环视,语法是(?=...),要求右边的字符串匹配指定的表达式,比如表达式abc(?=def),(?=def)在字符c右面,即匹配c右面的边界,对这个边界的要求是,它的右边有def,比如abcdef,如果没有,比如abcd,则不匹配;
- 否定顺序环视,语法是(?!...),要求右边的字符串不能匹配指定的表达式,比如表达式s(?!ing),匹配一般的s,但不匹配后面有ing的s;
- 肯定逆序环视,语法是(?<=...),要求左边的字符串匹配指定的表达式,比如表达式(?<=\s)abc,(?<=\s)在字符a左边,即匹配a左边的边界,对这个边界的要求是,它的左边必须是空白字符;
- 否定逆序环视,语法是(?<!...),要求左边的字符串不能匹配指定的表达式,比如表达式(?<!\w)cat,(?<!\w)在字符c左边,即匹配c左边的边界,对这个边界的要求是,它的左边不能是单词字符。
可以看出,环视也使用括号(),不过,它不是分组,不占用分组编号。
这些环视结构也被称为断言,断言的对象是边界,边界不占用字符,没有宽度,所以也被称为零宽度断言。
否定顺序环视与排除型字符组
关于否定顺序环视,我们要避免与排除型字符组混淆,即区分s(?!ing)与s[^ing],s[^ing]匹配的是两个字符,第一个是s,第二个是i, n, g以外的任意一个字符。还要注意,写法s(^ing)是不对的,^匹配的是起始位置。
出现在左边的顺序环视
顺序环视也可以出现在左边,比如表达式:
(?=.*[A-Z])\w+
这个表达式是什么意思呢?
\w+匹配多个单词字符,(?=.*[A-Z])匹配单词字符的左边界,这是一个肯定顺序环视,对这个边界的要求是,它右边的字符串匹配表达式:
.*[A-Z]
也就是说,它右边至少要有一个大写字母。
出现在右边的逆序环视
逆序环视也可以出现在右边,比如表达式:
[\w.]+(?<!\.)
[\w.]+匹配单词字符和字符'.'构成的字符串,比如"hello.ma"。(?<!\.)匹配字符串的右边界,这是一个逆序否定环视,对这个边界的要求是,它左边的字符不能是'.',也就是说,如果字符串以'.'结尾,则匹配的字符串中不能包括这个'.',比如,如果字符串是"hello.ma.",则匹配的子字符串是"hello.ma"。
并行环视
环视匹配的是一个边界,里面的表达式是对这个边界左边或右边字符串的要求,对同一个边界,可以指定多个要求,即写多个环视,比如表达式:
(?=.*[A-Z])(?=.*[0-9])\w+
\w+的左边界有两个要求,(?=.*[A-Z])要求后面至少有一个大写字母,(?=.*[0-9])要求后面至少有一位数字。
转义与匹配模式
转义
我们知道,字符'\'表示转义,转义有两种:
- 把普通字符转义,使其具备特殊含义,比如'\t', '\n', '\d', '\w', '\b', '\A'等,也就是说,这个转义把普通字符变为了元字符;
- 把元字符转义,使其变为普通字符,比如'\.', '\*', '\?','\(', '\\'等。
记住所有的元字符,并在需要的时候进行转义,这是比较困难的,有一个简单的办法,可以将所有元字符看做普通字符,就是在开始处加上\Q,在结束处加上\E,比如:
\Q(.*+)\E
\Q和\E之间的所有字符都会被视为普通字符。
正则表达式用字符串表示,在Java中,字符'\'也是字符串语法中的元字符,这使得正则表达式中的'\',在Java字符串表示中,要用两个'\',即'\\',而要匹配字符'\'本身,在Java字符串表示中,要用四个'\',即'\\\\',关于这点,下节我们会进一步说明。
匹配模式
前面提到了两种匹配模式,还有一种常用的匹配模式,就是不区分大小写的模式,指定方式也有两种,一种是在正则表达式开头使用(?i),i为ignore,比如:
(?i)the
既可以匹配the,也可以匹配THE,还可以匹配The。
也可以在程序中指定,Java中对应的变量是Pattern.CASE_INSENSITIVE。
需要说明的是,匹配模式间不是互斥的关系,它们可以一起使用,在正则表达式中,可以指定多个模式,比如(?smi)。
语法总结
下面,我们用表格的形式简要汇总下正则表达式的语法。




小结
本节简要介绍了正则表达式中的语法,下一节,我们来探讨相关的Java API。
----------------
未完待续,查看最新文章,敬请关注微信公众号“老马说编程”(扫描下方二维码),从入门到高级,深入浅出,老马和你一起探索Java编程及计算机技术的本质。用心原创,保留所有版权。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号