
1.hadoop入门
Hadoop入门
一.概念
1.hadoop是什么
(1)Hadoop是一个由apache基金会所开发的分布式系统基础架构
(2)主要解决,海量数据的存储和海量数据的分析计算问题
(3)广义上来说,hadoop通常是指一个更广泛的概念--hadoop生态圈
2.Hadoop发展历史
(1)创始人Doug Cutting,为了实现与Google类似的全文搜索功能,他在Lucene 框架基础上进行优化升级,查询引擎和索引引擎
(2)2001年年底Lucene成为Apache基金会的一个子项目
(3)对于海量数据的场景,Lucene框架面对与Google同样的困难,存储海量数据 困难,检索海量数据慢
(4)学习和模仿Google解决这些问题的方法:微型版Nutch
(5)可以说Google是Hadoop的思想之源(谷歌在大数据方面的三篇论文)
GFS -> HDFS
Map-Reduce -> MR
BigTable -> HBase
(6)2003-2004年,Google公开了部分GFS和MapReducee思想的细节,以此为基 础Doug Cutting等人用了两年业余时间实现了DFS和MapReduce机制,使Nutch 性能飙升
(7)2005年hadoop作为Lucence的子项目Nutch的一部分正式引入Apache基 金会
(8)2006年3月,Map-Reduce和Nutch Distributed File System(NDFS)分别被纳入到 Hadoop项目中,hadoop就此诞生,标志着大数据时代来临
(9)名字来源于Doug Cutting儿子的玩具大象
3.Hadoop的三大发行版本
Apache,Cloudera,Hortonworks
4.Hadoop的优势
(1)高可靠:Hadoop底层维护多个数据副本,所以即hadoop某个计算元素或存储 出现故障,也不会导致数据的丢失
(2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点
(3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度
(4)高容错性:能够自动将失败的任务重新分配
5.Hadoop的组成(面试重点)
(1)Hadoop1.x
MapReduce(计算+资源调度)
HDFS(数据存储)
Common(辅助工具)
(2)Hadoop2.x
Mapreduce(计算)
Yarn(资源调度)
HDFS(数据存储)
Common(辅助工具)
(3)Hadoop3.x
在组成上没有任何变化
5.1.HDFS架构概述
(1)namenode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生 成时间,副本数,文件权限),以及每个文件的块列表和块所在的datanode等
(2)datanode(dn):在本地文件系统存储文件块数据,以及块数据的校验和
(3)Secondary namenode(2nn):每隔一段时间对namenode元数据备份
5.2.yarn架构概述
(1)resourcemanager(rm):整个集群资源(内存,cpu等)的管理者
(2)nodemanager(nm):单个节点服务器资源的管理者
(3)applicationmaster(am):单个任务运行的老大
(4)container:容器,相当于一台独立的服务器,里面封装了任务运行所需要 的资源,如内存,cpu,磁盘,网络等

5.3.mapreduce架构概述
Mapreduce将计算过程分为两个阶段:map和reduce
(1)map阶段并行处理输入数据
(2)reduce阶段对map结果进行汇总
5.4.HDFS,yarn,mapreduce三者之间的关系
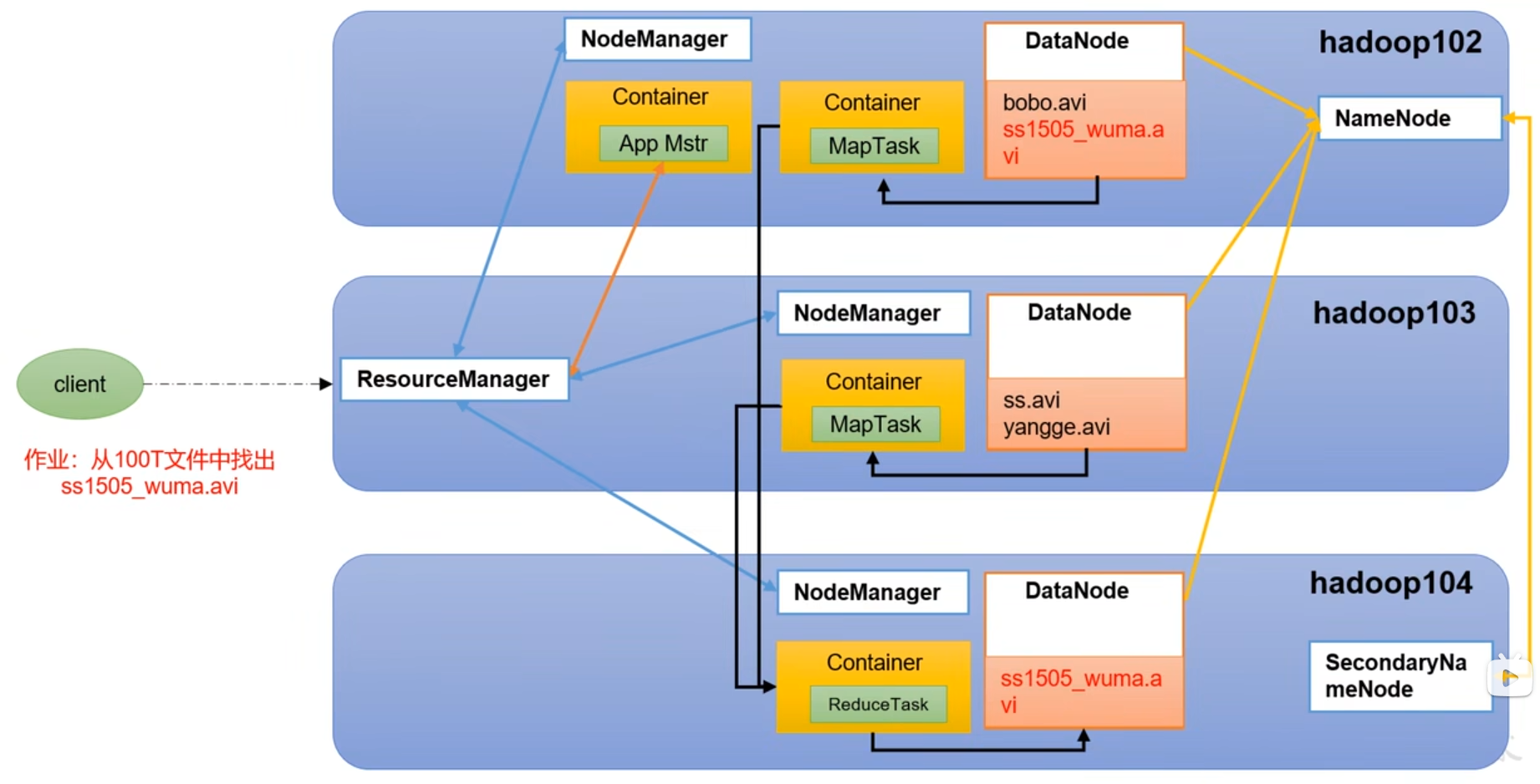
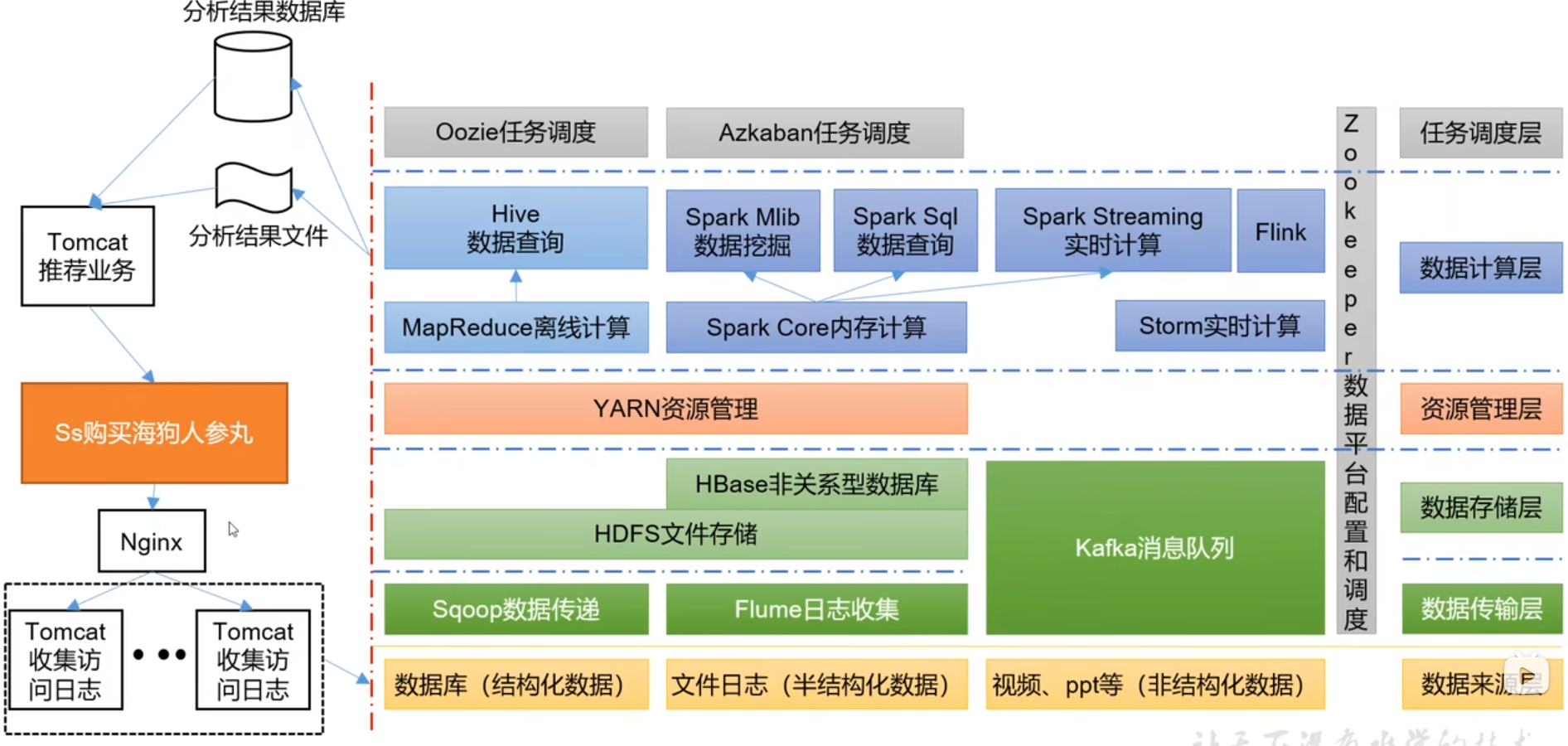
6.大数据技术生态体系

7.推荐系统案例
二.环境准备
1.模板虚拟机准备
2.克隆
3.安装jdk,hadoop
三.Hadoop生产集群搭建

1.本地模式
(1)在hadoop-3.1.1文件下创建一个wcinput文件夹

(2)在wcinput文件下创建一个word.txt文件并编辑

(3)输入以下内容保存并退出

(4)回到hadoop-3.1.1目录
(5)执行程序

(6)查看结果
cat wcoutput/part-r-00000
2.完全分布式集群(开发面试重点)
(1)准备三台虚拟机(关闭防火墙,静态ip,主机名称)
(2)安装jdk
(3)配置环境变量
(4)安装hadoop
(5)配置环境变量
(6)配置集群
(7)单点启动
(8)配置ssh
(9)群起并测试集群
2.1.虚拟机准备
2.2.编写集群分发脚本xsync
(1)scp(secure copy)安全拷贝
A.scp定义
Scp可以实现服务器与服务器之间的数据拷贝(from serverl to server2)
B.基本语法
scp -r $pdir/$fname $user@$host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地 路径/名称
(2)rsync远程同步工具
A.rsync定义
rsync主要用于备份和镜像.具有速度快,避免复制相同内容和支 持符号链接的优点
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync 只对差异文件做更新.scp把所有文件都复制过去
B.基本语法
rsync -av $pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的地用户@主机:目 的地路径/名称
参数说明
-a:归档拷贝
-v:显示复制过程
(3)xsync集群分发脚本
A.需求:循环复制文件到所有结点的相同目录下
B.需求分析:
(a)rsync命令原始拷贝
(b)期望脚本
(c)期望脚本在任何路径都能使用(脚本放在声明了全局环境变量 的路径)
C.脚本实现
2.3.ssh无密登录配置
(1)配置ssh
(2)无秘钥配置
2.4.集群配置
2.5.群起集群
第一次启动需要格式化
2.6.配置历史服务器
2.7.配置日志的聚焦
2.8.集群启动/停止方式总结
(1)各个模块分开启动/停止(前提配置ssh)
A.整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh
B.整体启动/停止yarn
start-yarn.sh/stop-yarn.sh
(2)各个服务组件逐一启动/停止
A.分别启动/停止HDFS组件

B.启动/停止yarn

2.9.编写hadoop集群常用脚本
2.10.常用端口号说明


