

ui自动化页面元素定位语句编写和验证
Ui自动化的基础是页面元素定位。
在python Selenium语句中定位方式主要有By.Id()、By.Name()、By.Xpath()、By.tagName()、By.className()、By.CssSelector()、By.linkText()、By.partialLinkText()这8类。由于现在的页面元素不一定有Id、Name、tagName和className的属性,所以最常用的是By.Xpath()、By.CssSelector(),如果是定位页面上的超文本链接,用By.linkText()。
Xpath定位方法简单直接且唯一,功能全面。但是页面层级一旦变化,需要调整代码,可维护性不好。
css定位方法代码简洁,性能好,但是语法复杂,某些浏览器不支持CSS定位方式。
谷歌、火狐浏览器的console控制台自带验证Xpath和css的工具,可以帮助我们定位和验证页面元素。
Xpath定位语法
以百度输入框的绝对路径“/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input “为例讲解。
|
表达语句 |
描述 |
举例 |
解释 |
|
nodename |
选取此节点的所有同级节点 |
/html/body/div |
div节点下所有子节点 |
|
/ |
根节点选取 |
|
用于绝对路径选择 |
|
// |
不考虑位置 |
//body/div |
匹配到符合条件即可 |
|
. |
当前节点 |
/html/body/div/. |
与上面/html/body/div效果一致 |
|
.. |
当前节点的父节点 |
/html/body/div/.. |
匹配到body |
|
@ |
选取属性 |
//input[@id='kw'] |
’@‘后面输入属性条件 |
|
[n] |
选取元素下第N个子元素 |
/html/body/div[2] |
body下第2个div子元素 |
|
[last()] |
选取元素下倒数第一个子元素 |
/html/body/div[last()] |
body下倒数第一个div子元素 |
|
* |
匹配任何节点 |
/html/body/* |
body下所有子节点 |
|
preceding-sibling::nodename[N] |
匹配前N位的类型为nodename的同级节点 |
//form/preceding-sibling::div[1] |
与from同级的前面一位的兄弟div节点 |
|
following-sibling::nodename[N] |
匹配后N位的类型为nodename的同级节点 |
//form/following-sibling::div[1] |
与from同级的后面一位的兄弟div节点 |
|
child::nodename[N] |
匹配上级节点的子节点类型为nodename的第N个节点 |
//form/span[1]/child::input[1] |
Form下第一个span节点的第一个input子节点 |
|
parent::nodename[N] |
匹配上级节点的nodename类型的第N个节点 |
//form/parent::span[1] |
Form元素的父级节点中第一个span元素 |
xpath中支持运算符计算,但是很少用到。
|
运算符 |
描述 |
实例 |
返回值 |
|
| |
计算两个节点集 |
//book | //cd |
返回所有拥有 book 和 cd 元素的节点集 |
|
+ |
加法 |
6 + 4 |
10 |
|
- |
减法 |
6月4日 |
2 |
|
* |
乘法 |
6 * 4 |
24 |
|
div |
除法 |
8 div 4 |
2 |
|
= |
等于 |
price=9.80 |
满足条件为ture,不满足为false |
|
!= |
不等于 |
price!=9.80 |
满足条件为ture,不满足为false |
|
< |
小于 |
price<9.80 |
满足条件为ture,不满足为false |
|
<= |
小于或等于 |
price<=9.80 |
满足条件为ture,不满足为false |
|
> |
大于 |
price>9.80 |
满足条件为ture,不满足为false |
|
>= |
大于或等于 |
price>=9.80 |
满足条件为ture,不满足为false |
|
or |
或 |
/html//input[@name='wd'or @class='s_ipt'] |
满足条件为ture,不满足为false |
|
and |
与 |
/html//input[@name='wd'and @class='s_ipt'] |
满足条件为ture,不满足为false |
|
mod |
计算除法的余数 |
5 mod 2 |
1 |
xpath方法元素定位注意点:
1、属性内容在python代码中可以用双引号包裹,也可以用单引号包裹,但是在浏览器中验证的时候只能用单引号包裹。建议在代码中也使用单引号包裹,语句外层用双引号包裹,如下,text()='首页'中文字字段用单引号包裹,完整定位语句用双引号包裹。
WebDriverWait(browser, 15, 0.5).until(EC.presence_of_all_elements_located((By.XPATH, "//ul/div[1]/a/li/span[text()='首页']")))
在浏览器console中验证为“ $x("//input[@id='kw']") ”。注意全英文。
2、非属性内容,不需要加“@”,例如代码
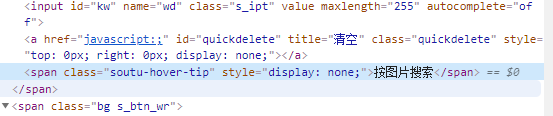
定位语句为:“/html/body//span[2][text()='按图片搜索']”。因为”按图片搜索“不是span元素的属性。
3、尽量避免使用绝对路径来定位,而是使用属性id、name、class、type等定位。如果子集节点没有唯一属性,可以找父级节点、祖父节点等。例如:百度页面输入框绝对路径为:“/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input”,可以替换为“//form[@id='form']/span[1]/input”。这样减轻了代码量,同时减少元素层级变化带来的代码维护量。
4、xpath还提供contains()方法,实现模糊定位。contains()需要输入2个属性,一个是元素名称,一个是元素内容,中间以逗号隔开。例如:“//form[@id='form']/span[1]/input”可以替换为“//*[contains(@id,'form')]/span[1]/input”;再例如“/html/body//span[2][text()='按图片搜索']”可以修改为“/html/body//span[contains(text(),'按图片搜索')]”。
5、child::与parent::如果加上*,则表示查找所有子节点或者父节点。
6、查找子节点中“//form/span[1]/child::input[1]”与“//form/span[1]/input[1]”效果一致。
7、查找父节点中,“//form/parent::*/parent::*”与“//form/../..”效果一致。
css定位语法
基本语法如下:css语法与与Xpath有诸多类似的地方。
|
表达语句 |
描述 |
举例 |
解释 |
|
nodename |
元素选择,同时选择多个元素可用逗号分隔 |
input |
选择所有input元素 |
|
# |
id选择器符号 |
#head |
选择所有id=head的元素 |
|
>或者空格 |
上下级元素分隔符为>或者空格 |
html>body>div>div>div>div>div>form>span>input |
用于绝对路径选择 |
|
. |
class选择器 |
form.fm>span>input.s_ipt |
选择所有class=s_ipt的元素 |
|
* |
所有元素 |
form.fm>span>* |
符合span查找的当前等级下所有的下级节点 |
|
[表达式] |
元素内容筛选。以字符^指明从字符串的开始匹配,以字符以字符*指明在需要进行模糊查询,以字符$指明在字符串的结尾匹配 |
input[name='wd'] |
查找name='wd'的input元素 |
|
:first-child |
第一个子节点 |
div#u1 a:first-child |
id为u1的div元素的第1个子a元素 |
|
:nth-child(N) |
第N个子节点 |
div#u1 a:nth-child(3) |
id为u1的div元素的第3个子a元素 |
|
:last-child |
最后一个子节点 |
div#u1 a:last-child |
id为u1的div元素的最后一个子a元素 |
css方法定位元素注意点:
1、css的绝对路径不能省略。
2、css定位没有有能够获取父节点的办法,也不能获取当前元素的所有子节点。
页面元素定位语句编写和调试
火狐浏览器和谷歌浏览器都很好的支持元素的查找、定位、调试。以谷歌浏览器为例:
1、F12打开开发者工具,进入到Elements查看器,查看页面元素。
2、选择被定位元素。
点击Elements查看器上方定位按钮。
选择后鼠标停留在需要定位的元素内容上,元素的代码部分就会突出显示。
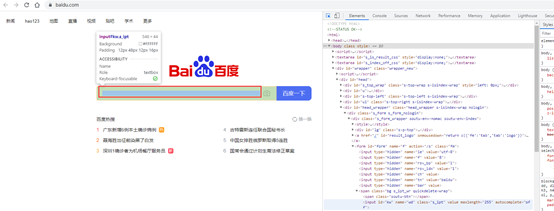
例如我们定位到百度页面的输入框内容如下:

3、编辑定位语句。
如果使用xpath语句定位元素,选中语句,右键--copy--copy Full Xpath 点击。xpath层级就被复制到剪贴板,如下:“/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input”经过语法处理,可以为“//form[@id='form']/span[1]/input”。
如果使用css语句定位,根据语句id=‘kw‘,编辑定位语句为"#kw"。
4、定位语句调试。
定位语句编辑好之后往往需要验证是否正确,是否唯一。
切换到Console控制台验证定位语句。
验证定位语句需要用Console中的属性,如下:
- $():简单理解就是 document.querySelector,可用于验证css定位语句,但是只能在回车后才能看到匹配结果,不建议使用。
- $$():简单理解就是 document.querySelectorAll ,可用于验证css定位语句。编辑时可显示匹配结果,建议使用。

- $x():Xpath选择器,可用于验证xpath定位语句。注意x必须小写。编辑时可显示匹配结果,很方便,建议使用。
- $_ // 是上一个表达式的值,等同于键盘的“向上”快捷键。连续使用上一个值时,建议用键盘快捷键。
定位语句需要以双引号包裹。以xpath方式验证如下:定位到唯一的正确元素后,就可以在python代码中使用定位语句了。
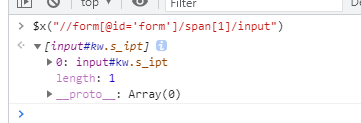
5、使用定位语句
获取的定位语句在python中可以直接使用。如下:
browser.find_element_by_xpath(“ //form[@id='form']/span[1]/input “).send_keys('UI自动化')
