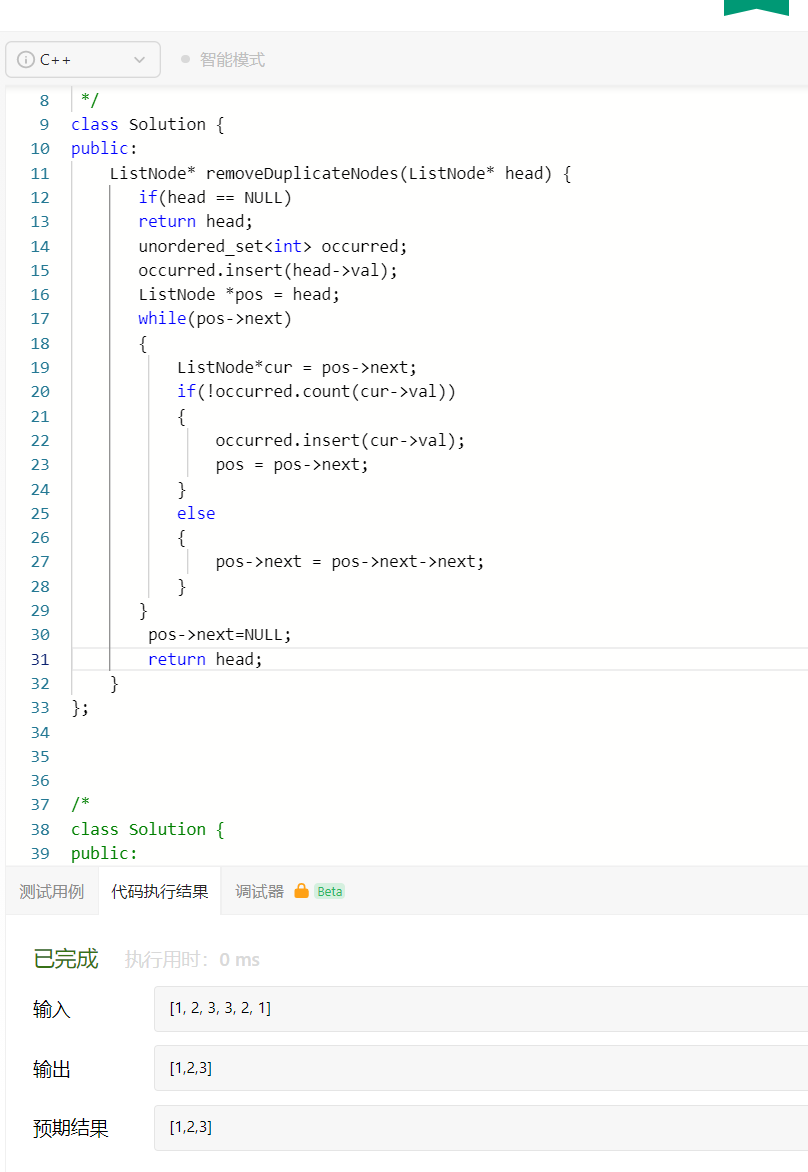
移除重复节点 *****
面试题 02.01. 移除重复节点
编写代码,移除未排序链表中的重复节点。保留最开始出现的节点。
示例1:
输入:[1, 2, 3, 3, 2, 1] 输出:[1, 2, 3]
示例2:
输入:[1, 1, 1, 1, 2] 输出:[1, 2]
提示:
- 链表长度在[0, 20000]范围内。
- 链表元素在[0, 20000]范围内。
进阶:
如果不得使用临时缓冲区,该怎么解决?
📖 文字题解
前言
在本题中,我们需要移除未排序链表中的重复节点。保留最开始出现的节点。在一些语言(例如 C++)中,并没有较好的内存回收机制,因此如果在面试中遇到了本题,可以和面试官确认是否需要释放被移除的节点占用的内存空间。本题解给出的 C++ 代码中默认不释放空间。
方法一:哈希表
我们对给定的链表进行一次遍历,并用一个哈希集合(HashSet)来存储所有出现过的节点。由于在大部分语言中,对给定的链表元素直接进行「相等」比较,实际上是对两个链表元素的地址(而不是值)进行比较。因此,我们在哈希集合中存储链表元素的值,方便直接使用等号进行比较。
具体地,我们从链表的头节点 \textit{head}head 开始进行遍历,遍历的指针记为 \textit{pos}pos。由于头节点一定不会被删除,因此我们可以枚举待移除节点的前驱节点,减少编写代码的复杂度。
这样枚举有什么好处?试想一下,如果我们直接枚举待移除节点,那么在将它进行移除时,我们本质上是将它的前驱节点连向后继节点。而由于题目给定的链表结构中,我们无法直接访问一个节点的前驱节点。因此,我们不如直接枚举前驱节点 u,那么节点本身就是 u.next,后继节点就是 u.next.next。
在遍历完成后,我们就得到了最终的答案链表。
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/remove-duplicate-node-lcci/solution/yi-chu-zhong-fu-jie-dian-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。