
Java-----HashMap源码学习
1. HashMap数据结构
在JDK1.8之前, HashMap采用的散列表的形式来进行存储数据, 散列表又叫做哈希表, 是数组+链表的一种结构

优点: 具备数组的查找迅速的特点, 又具有链表增删快的特点
缺点: 消耗的内存相对来说比较大, 拿空间换取时间
而JDK1.8时, 用的就不仅仅是链表结构, 内部会进行判断, 当链表的长度大于8时,会转换成红黑树的结构
2 初始容量大小----initialCapacity
当我们去创建一个HashMap的时候, 它是有一个初始容量为16的大小, 这个容量其实就是那个数组的长度, 这点应该比较好理解,创建数组的时候是不是要指定一个长度?

并且我们如果调用HashMap的单参数构造, 就能够给默认大小赋值,但是这个大小必须是2的N次方,最大是2的30次方


这里有两个个问题:
2.1第一个问题是, 如果我们传入的值不是2的N次方怎么办?
Java设计人员已经写好了一个算法, 绝对保证了我们传入的值, 最终会被变为一个大于该值且最小的2的N次方数, 这个方法叫tableSizeFor()方法

改方法会在HashMap有参构造中被调用
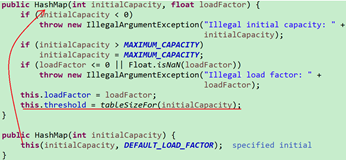
也许有的同学会感觉苦恼, 不会位运算, 这该如何是好? 不用担心, 有个最简单的方法, 就是将该方法的源码一个复制, 再一个粘贴到我们一个普通的main方法中, 进行一些简单的测试来观察结果即可, 这里举个简单例子传入7, 有兴趣的私下可以尝试其它数值
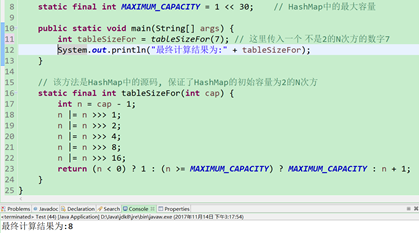
经过tableSizeFor()方法的运算, 如果我们传入的数字是7,那么最终会计算为一个大于7且最小的2的N次方, 也就是8, 经过该算法, 那么就绝对能获得2的N次方的数了, 那么紧接着第二个问题就来了.
2.2第二个问题是, 为什么一定要是2的N次方?
要解决这个问题, 先要考虑什么情况下HashMap的效率能达到最高?
(1) 只让往哈希表中的数组中存, 不往链表结构中存, 但是这种方式显然是很不合理. 这种方式的存储和数组结构无异, 并且数组的缺点就是插入和删除效率慢
(2) 再一种方式就是, 让所有的数据Entry均匀的分布在哈希表中, 不会出现仅仅只往某一两个下标所对应的链表中添加数据, 造成某几个链表过长的情况, 这种方式相对的效率就会达到最优, 这也是HashMap中所实现的方式
那么怎么才能让HashMap存入的值更均匀呢?
其实是一个很简单的取模运算,HashMap中, 将每一个Entry的key的哈希值,与HashMap的容量长度进行一次取模运算, 这么一个简单的算法,就能将每一个数据Entry插入的更加均匀, 这个方法的名字叫indexFor(), 下面是源码

Java设计人员所写的代码, 肯定不会满足于仅仅实现某个功能而是考虑怎么才能让效率更高, 开销更少, 在时间和空间上追求一种最优解,所以这里采用的是一中位运算的方式,
这个方法的实现其实是一个数学规律,“如果一个值x是2的N次方, 那么另一个值y对x的模运算结果等价于y和(x - 1)的&(按位与)运算!”,
其实就是 y % x == y & (x - 1)
而且,如果这个数不是2的N次方,那么进行h & (length - 1)的时候,有些值永远取不到, 也就意味着Entry永远不会添加到数组的某些下标中,这样就造成了Entry分布的不均匀,效率就会降低
而切身为开发人员我们应该知道, 位运算的比普通的数学运算效率要高! 这也就是为什么HashMap的容量一定要是2的N次方的原因
3 加载因子与扩容----loadFactor And ReSize
3.1 loadFactor
加载因子(loadFactor)有一个默认值0.75, 在构造方法中被赋值, 0.75是Java设计人员考虑空间和时间上的一个最优数值

这个加载因子的主要作用就是判断HashMap什么情况下扩容(Resize)—— 当HashMap中的Entry个数大于容量 * 加载因子时就会进行扩容,将数组的长度变为原来的2倍, 这个扩容条件由成员变量threshold来记录

3.2 Resize
HashMap发生Reszie的判定条件是size > threshold = capicity * loadFactor, 但是大家都知道数组是不可变的,所以HashMap中的处理方式是创建了一个新的数组
例如:
HashMap中数组的默认大小为16, 加载因子为0.75, 扩容条件为 16 * 0.75 = 12, 也就是HashMap中的Entry超过12个,就会创建一个新的数组, 这个数的大小为16 * 2 = 32, 然后每个Entry所在位置要进行重新计算
下面是部分源码分析:
Jdk1.7中部分源码:

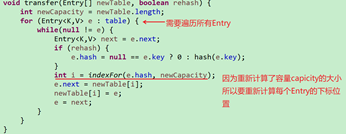
Jdk1.8中部分源码:
判断是否要Resize和重新计算新的容量及边界值
创建一个新的Node数组

将旧的节点Entry赋值到新的数组中,并重新计算Entry在新数组中的位置

4. put()方法
这里主要简述下HashMap中的put()方法

最终调用的是putval()方法
该方法不可被重写
下面通过画图来描述过程图

当要往Map中存值时(当前集合中的数据小于容量8), 会将Entry中的key取hash值, 然后计算要插入的下标(并不是按顺序插入, 具体在2.2中有讲解), 此处假设计算结果为1,那么就在下标为1的位置插入数值
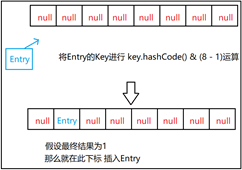
当某个下标运算结果后,这个位置已经有值,此时的情况有一个术语叫碰撞, 因为它是一种数组+链表的结构,所以就该链表结构发挥作用,就再往之前的某个下标的Entry前面增加信息。

当key的hashCode完全一样时,会覆盖调原来的节点的value,这也就是HashMap中key唯一的特点
当HashMap中的size(Entry的个数) 大于threshold(容量大小8 * 加载因子0.75 = 6)时,就会发生Resize的情况,源码中有这几行代码

关于resize()方法前面已经有了简述,这里不再赘述
以上大体就是HashMap相关的一些实现方式
如有错误, 敬请指正, 感激不尽!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号