

Lift, Splat, Shoot_ Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
Abstract
The goal of perception for autonomous vehicles is to extract semantic representations from multiple sensors and fuse these representations into a single "bird's-eye-view" coordinate frame for consumption by motion planning. We propose a new end-to-end architecture that directly extracts a bird's-eye-view representation of a scene given image data from an arbitrary number of cameras. The core idea behind our approach is to "lift" each image individually into a frustum of features for each camera, then "splat" all frustums into a rasterized bird's-eye-view grid. By training on the entire camera rig, we provide evidence that our model is able to learn not only how to represent images but how to fuse predictions from all cameras into a single cohesive representation of the scene while being robust to calibration error. On standard bird's-eye-view tasks such as object segmentation and map segmentation, our model outperforms all baselines and prior work. In pursuit of the goal of learning dense representations for motion planning, we show that the representations inferred by our model enable interpretable end-to-end motion planning by "shooting" template trajectories into a bird's-eye-view cost map output by our network. We benchmark our approach against models that use oracle depth from lidar. Project page with code: https://nv-tlabs.github.io/lift-splat-shoot .
Comments
ECCV 2020
LSS: 通过隐式非投影到3D的方式,对任意配置的camera图像(不同数量相机)进行encoding
输入多视角的环视图像,输出BEV坐标下的语义信息,车辆、可通行区域、车道线等
LSS一般被称作是BEV的开山之作,后续一系列的工作都是基于LSS做的
Q&A
0.背景动机
传统的一般的计算机视觉任务,比如目标检测、语义分割等,输入一张图片,在和输入图片相同的坐标系中做出预测,这和自动驾驶真正需要的感知任务不是很契合。在自动驾驶中,不同坐标系下的传感器数据会作为输入,感知的下游规划模块需要的是ego坐标下的感知结果:
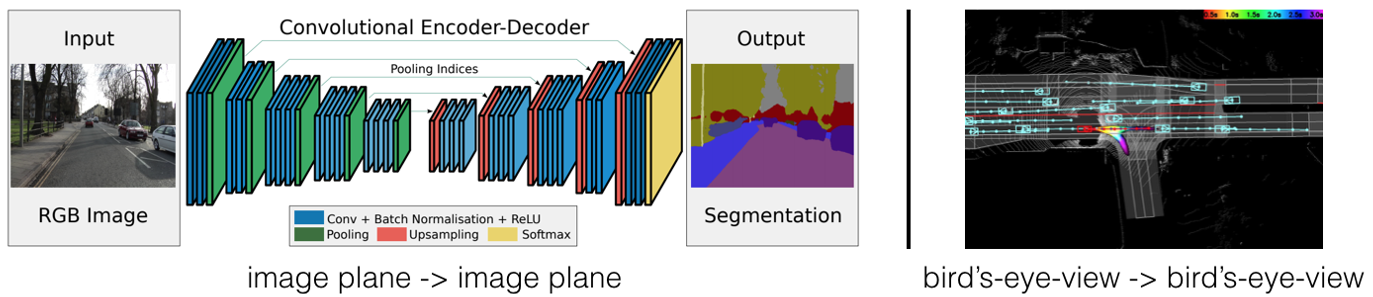
有许多简单实用的策略可以将single-image的范式扩展到multi-view的。
对于从n个camera中进行3D目标检测这个问题来说,可以在各个视角的图片上使用一个相同的single-image检测器做2D检测,然后根据相机内外参将检测结果投影到ego坐标系下。
这种扩展方式有三个有价值的对称性:
- 平移不变性: 图片中的像素坐标系发生偏移,输出结果也会对应偏移相同数量
- 排列不变性:n个相机不同的排列对最终的输出结果没有影响
- ego坐标系等距等差性:无论捕获图像的相机相对于ego位于何处,都将在给定图像中检测到相同的物体。也就是说如果ego坐标系发生平移旋转,输出结果也会对应平移旋转。
这种简易的处理方式缺点也很明显:
无法使用data-driven的方法找到最合适用于 融合跨相机的信息的方法。也没有办法使用反向传播来利用下游planner的反馈来自动优化感知系统。
提出了一个名为“Lift-Splat”的模型,它保留了上面设计中确定的 3 个对称性,同时也是端到端可微分的,是data-driven的。
LSS这种从多视图相机中学习内在表示的方法是建立在 当时最新的传感器融合和单目目标检测的基础上的。nuscense,lyft,waymo和argo等360环视相机数据集的建立也功不可没。
Monocular Object Detection
单目目标检测器是根据它们如何对从图像平面到给定 3D 坐标系的变换进行建模来定义的。
1. 一般的方法是基于PV视角来做的
标准的技术路线是二阶段的:首先在图像上应用一个成熟的2D目标检测网络,然后训练第二个网络将2D框回归为3D框(SSD-6D、Monogrnet等),另外一种思路是训练一个标准2D检测网络的同时预测深度,使用损失来预测深度,该损失旨在将由于不正确的深度引起的误差与由于不正确的边界框引起的误差分开。这些方法在 3D 目标检测benchmark上取得了出色的性能,因为图像平面中的目标检测消除了掩盖在单目深度估计中的歧义性。
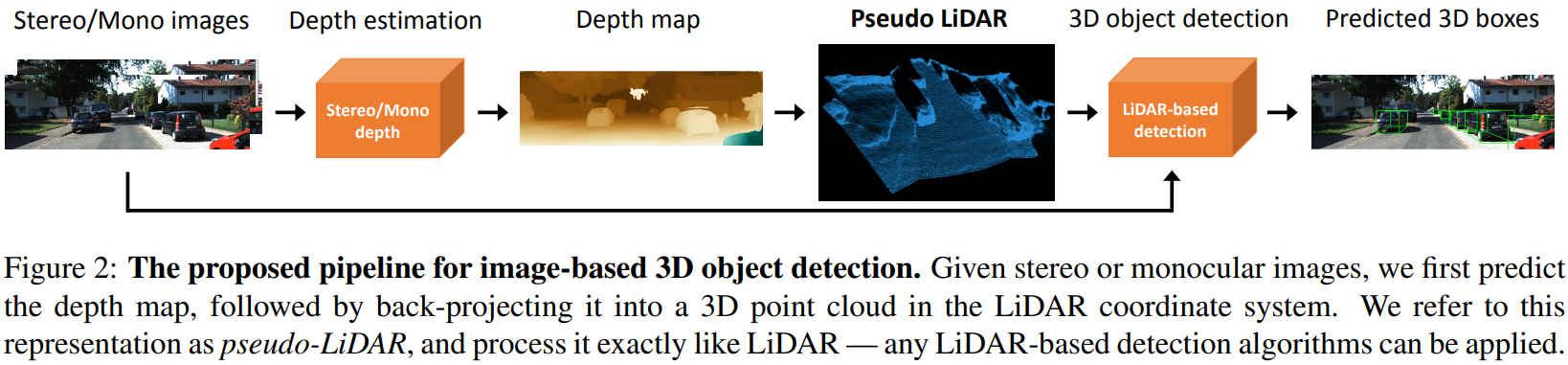
2. 基于PseudoLidar的方法
训练一个网络进行单目深度估计,另一个网络进行3D/BEV检测
这种方法可以work并且很成功的一个直观原因是,基于pseudolidar的方法训练了一个在BEV下的检测网络
- 与最终模型评测时使用的坐标系相同
- 相对于图像平面,在BEV下的欧氏距离更有实际意义
CVPR19 Pseudo-LiDAR from Visual Depth Estimation
3.使用三维物体基元先验,根据其在所有可用相机上的投影来获取特征
2016_Monocular 3D Object Detection for Autonomous Driving
在地平面上生成3D 候选框,再投影到2D中
2018_Orthographic Feature Transform for Monocular 3D Object Detection
OFT知乎讲解
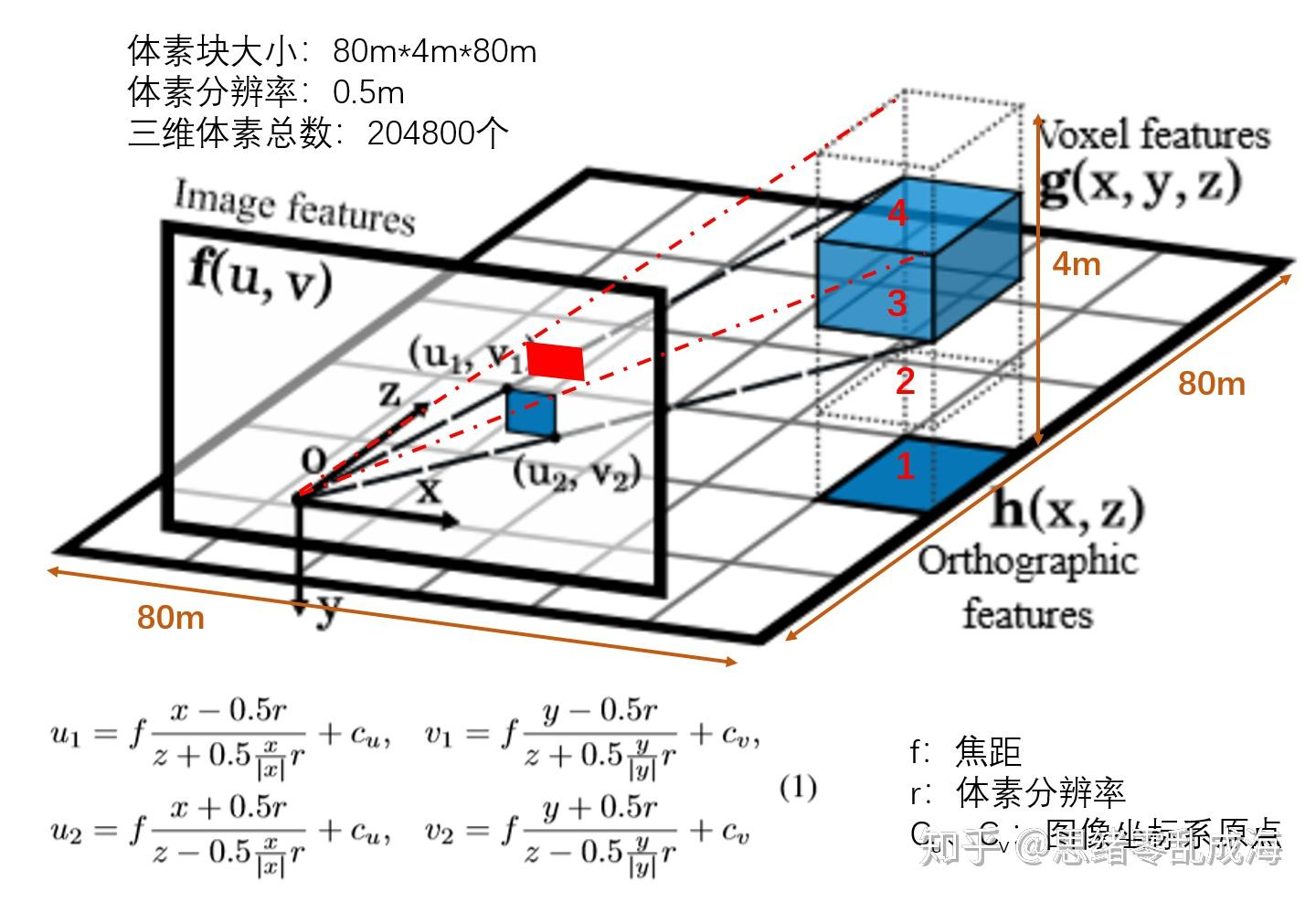
OFT的目标是用前端特征提取器提取的基于图像的特征图 中的相关n维特征填充3D体素特征图 。
立体像素特征图定义在一个均匀间隔的3D网格,它与地平面距离是固定的,在相机坐标 以下,维度为W,H,D,体素大小为 r 。对于给定的体素网格位置 (不能 确定是否是体素中心点),通过对对应与体素的2D投影的图像特征图的区域进行特征累加,得到体素特征。
一般情况下,每一个体素(大小为r 的立方体)都会投射到像平面上的六边形区域,作者用一个矩形包围框来近似它
OFT中像素为每个体素贡献相同的特征,而与该像素处的对象的深度无关, 每个体素格子投影到2D得到的矩形之间会有overlap,近处的格子和远处的格子得到的feature是相同的。
Inference in the BEV Frame
使用内外参直接在BEV框架中进行推理的模型最近受到了广泛的关注。
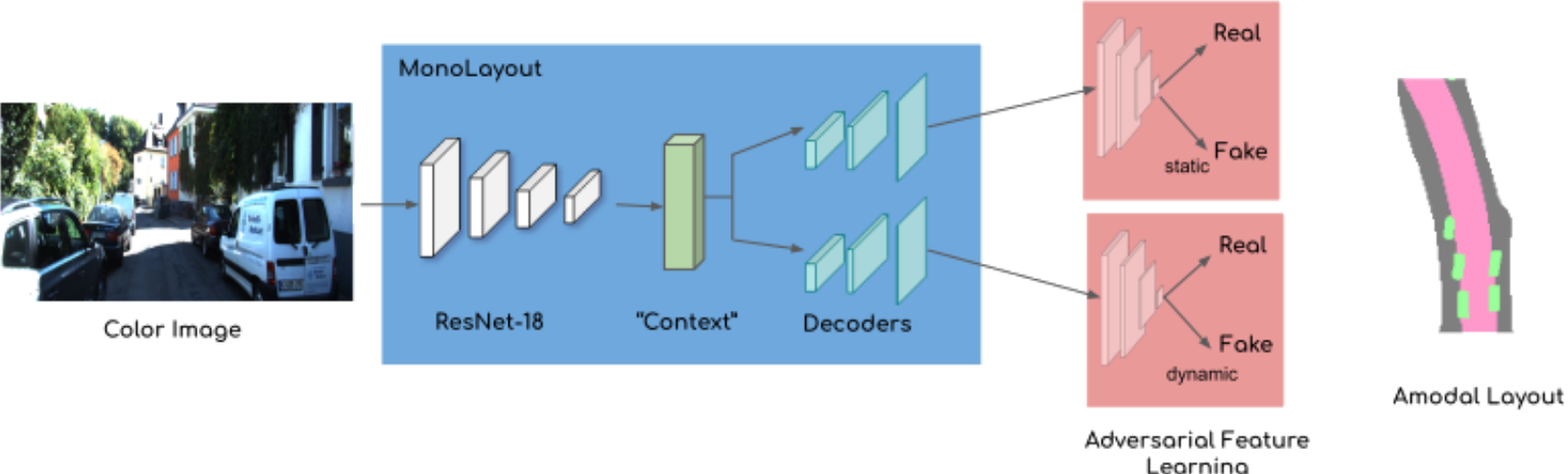
MonoLayout 从一张图片中进行BEV推理,使用对抗损失(adversarial loss)鼓励模型修复看似合理的隐藏物体,这个思路可以用于map-less中以及应对遮挡 :

也有利用Transformer把图片表征转为BEV表征的
这些架构以及LSS的架构都使用类似于机器学习图形社区的“多平面”图像的数据结构
1.LSS分别是什么含义
输入: n images 以及每一张图片的外参矩阵 内参矩阵
输出: 当前场景在BEV坐标 下的表示
对于世界坐标系中的一个点 通过内外参矩阵可以投影到像素坐标系
Lift: Latent Depth Distribution
潜在深度分布
首先对每个相机得到的图像单独做处理,把每一张图像从2D坐标lift到一个多个相机公用的3D坐标系中。
单目传感器融合的挑战在于,需要将深度转换到参考坐标系中,但与每个像素相关的“深度”本质上是不明确的,有可能是d1,也有可能是d2, 一方面是因为2D到3D本就不是一一对应的关系,有一个系数存在,单幅RGB图像对应的真实场景可能有无数个,而图像中没有稳定的线索来约束这些可能性
LSS的解决方案是为每个像素生成所有可能的深度表示
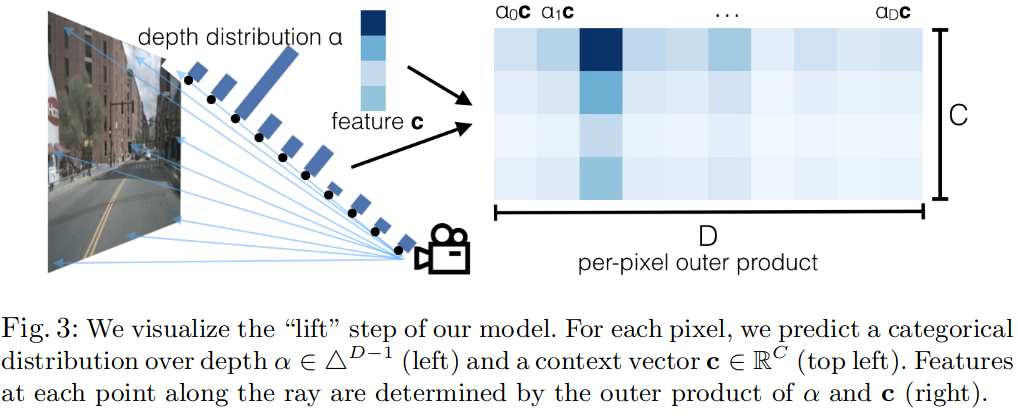
input: 图像 外参 , 内参
图像上一点记为 ,将 个点 与每一个像素关联, 其中 是离散深度的集合 , 这里不包含可学习的参数。经过这样的操作后,就将输入图像转换为一个大小的点云(其实是个视锥);
点云中每个点的上下文向量被参数化以匹配注意力和离散深度 推理的概念:
在像素处 网络输出特征 ,并预测 深度分布 (为什么是D-1?)
在大小的点云中的点 处的feature 定义为像素处的feature 乘以深度分布 (注意力)
对于深度预测,如果是one-hot编码形式的离散深度,根据上面的计算, 只有一个位置是非零的,那么位置处的特征只有在单一深度处有值(same as pseudolidar);
如果网络预测的是深度的均匀分布,那么对于分配给像素处的个点来说,它们的特征是与深度无关的相同feature(why? 如果是均匀分布,Fig3中的D个depth distribution都是相同的大小,特征与之相乘之后就没有注意力的功能了,也就是和depth无关了)(same in OFT)
LSS将depth分为很多个bin的预测方式在理论上可以选择将图像中某一个位置的feature放置到BEV下的特定位置(深度预测没有歧义,类似于one-hot),或者是当深度预测具有歧义时传播到整个depth分布上, 即fig3中的一条射线上。
经过Lift后 3xHxW的图片转化为 CxDxHxW的feature
但是目前还没有说明2D是怎么转到BEV视角下的
Splat: Pillar Pooling
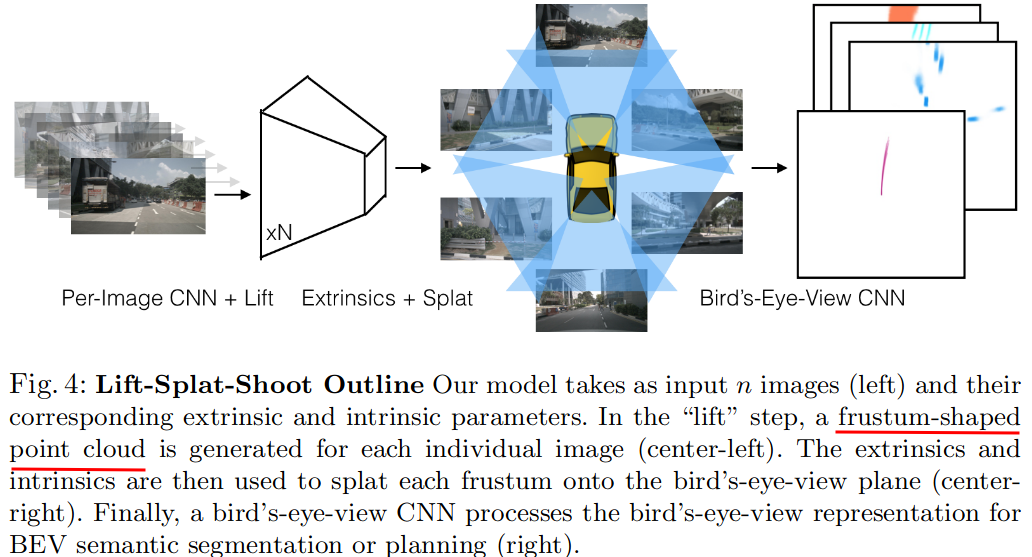
Lift步骤中得到了DxHxW大小的“点云”CxDxHxW,利用相机内外参把每一个点分配到距离最近的pillar中,然后做sum pooling 得到CxHxW的tensor
根据LS的步骤,得到的CxHxW应该也是稀疏的 远处更加稀疏
考虑到生成的点云的大小,效率对于训练模型至关重要,使用 cumsum trick进行sum pooling加速
使用 cumsum进行 sum pooling可以避免在pointpillars中使用max_pooling时需要进行的padding操作,减少内存使用
pointpillars中的做法:
先将点云投影到BEV, 栅格化,将非空pillar聚合在一起得到(D,P,N)大小的tensor, D:点特征维度,P:非空Pillar的个数,N:Pillar中的点数,对于非常稀疏的点云来说,很多pillar中的点的个数并不会满足设置的个数N,采用zero-padding进行补全,通过一个PointNet,得到(C,P,N)的feature,再max_pooling得到(C,P)的feature,最后scatter回BEV得到(C,H,W)的feature
cumulative sum的做法:
先根据bin_id将所有点进行排序,然后对特征进行累加,然后减去bin边界处的累计和就可以得到各个bin的sum_pooling结果
code:
def cumsum_trick(x, geom_feats, ranks): x = x.cumsum(0) kept = torch.ones(x.shape[0], device=x.device, dtype=torch.bool) kept[:-1] = (ranks[1:] != ranks[:-1]) x, geom_feats = x[kept], geom_feats[kept] x = torch.cat((x[:1], x[1:] - x[:-1])) return x, geom_feats class QuickCumsum(torch.autograd.Function): @staticmethod def forward(ctx, x, geom_feats, ranks): x = x.cumsum(0) kept = torch.ones(x.shape[0], device=x.device, dtype=torch.bool) kept[:-1] = (ranks[1:] != ranks[:-1]) x, geom_feats = x[kept], geom_feats[kept] x = torch.cat((x[:1], x[1:] - x[:-1])) # save kept for backward ctx.save_for_backward(kept) # no gradient for geom_feats ctx.mark_non_differentiable(geom_feats) return x, geom_feats @staticmethod def backward(ctx, gradx, gradgeom): kept, = ctx.saved_tensors back = torch.cumsum(kept, 0) back[kept] -= 1 val = gradx[back] return val, None, None
pillar分配:
2D到3D的逆投影 :[[../Perception/Projective_Geometry_射影几何|Projective_Geometry_射影几何]]
Shoot: Motion Planning
没有细看,直接在camera-only得到的BEV cost map上规划,shoot 撒不同的轨迹,计算cost,选择cost最小的轨迹;
2.LSS对图像overlap有要求吗?对于overlap很小或者没有overlap的情况,有特别处理吗?
LSS单目深度估计,每一个相机单独处理,所以对overlap没有要求
3.对相机丢失以及标定误差容忍是怎样实现的
- 在训练时丢弃一些camera,当测试camera丢失时会有更好的性能
- 测试时使用全部的camera,训练时随机drop一个camera的模型表现最好,传感器丢失迫使模型学习不同相机上图像之间的相关性,类似于其他dropout
- 在训练时加入相机外参噪声,可以得到更好的测试结果
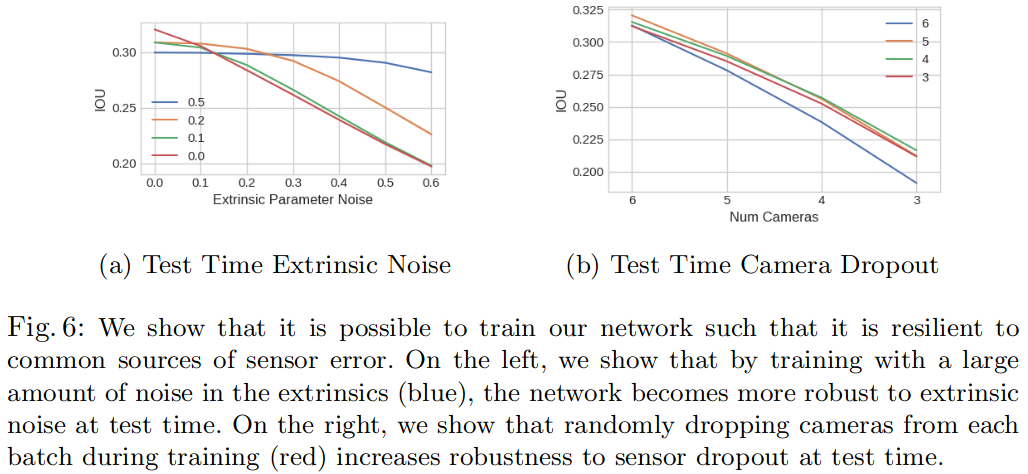
LSS具有zero-shot的能力
在nuscene上,只用一部分数量的相机来训练,但是测试时用全部的相机,虽然没有训练过,但是会有更好的性能;nuscens的模型可以泛化到Lyft上
与度量学习的一些概念很像
4.LSS强调的三个对称性有什么重要意义
- 平移不变性: 图片中的像素坐标系发生偏移,输出结果也会对应偏移相同数量
- 排列不变性:n个相机不同的排列对最终的输出结果没有影响
- ego坐标系等距等差性:无论捕获图像的相机相对于ego位于何处,都将在给定图像中检测到相同的物体。也就是说如果ego坐标系发生平移旋转,输出结果也会对应平移旋转。
5.LSS怎样训练的,怎样监督
端到端训练,depth没有监督
6.后续论文
LSS是在很多单目检测以及单目深度估计论文的基础上发展起来了,了解这些单目方法可以更好的理解LSS
- 单目3D目标检测的发展, mono3D等方法,还是有不少眼前一亮的方法的
- 基于LSS做检测的论文
7. LSS的缺点以及可以改进的方向
- 深度没有监督,有可能特征是对的,但是深度不对,表现就是BEV下的FP
- 视锥是不是太致密了?很多地方其实没有被射线击中
- 好像只是在ray射线上做深度估计,横向多个ray之间的关系是不是也可以加入约束
- 对于没有障碍物的地方,depth应该是线性增加的,有障碍物的地方增加会减缓很多,可不可以加入约束 Real-Time Compact Environment Representation for UAV Navigation
- depth需要很大的范围比如LSS中的
[4, 45]每 1m一个bin,如果想看到150m, 得到的视锥会很大
Pipeline
Performance
比lidar差但是比其他单目方法要好
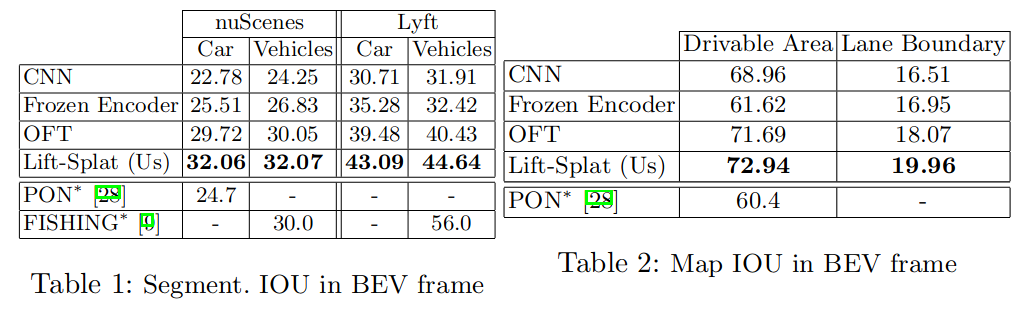
具体性能不是很高,但是是后续很多工作的基础


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现