
JVM 调优/问题排查 浅谈
参考:https://www.cnblogs.com/xingzc/p/5756119.html
https://www.cnblogs.com/yang-hao/p/5939487.html
https://blog.csdn.net/chenjianandiyi/article/details/52442021
https://www.bilibili.com/video/av52674111
JVM指令
标准指令,X指令,XX指令,其中XX指令是调优的关键。
XX指令
boolean型:-XX:[+-] name 表示启用/禁用name属性。比如:-XX:+UseG1GC
KV类型:-XX:[+-] name=value
查看类指令
-XX:+PrintFlagsFinal

JPS -l 查看JAVA进程PID
![]()
jinfo -flag <参数名 不写打印全部属性> 进程PID 查看进程属性值
![]()
jstat 查看JVM类装载、垃圾收集、jit编译
jstat -gc pid <间隔ms> <连续打印次数>


JMAP 堆内存dump 导出后用MAT分析

Jstack -l ${PID} (线程dump -l 打印锁信息)
打印进程7930的线程dump到txt文件,并下载到本地。SecureCRT作为Linux客户端为例。
![]()
Java 的内存模型
- Young,年轻代(易被 GC)。Young 区被划分为三部分,Eden 区和两个大小严格相同的 Survivor 区,其中 Survivor 区间中,某一时刻只有其中一个是被使用的,另外一个留做垃圾收集时复制对象用,在 Young 区间变满的时候,minor GC 就会将存活的对象移到空闲的Survivor 区间中,根据 JVM 的策略,在经过几次垃圾收集后,任然存活于 Survivor 的对象将被移动到 Tenured 区间。
- Tenured,终身代。Tenured 区主要保存生命周期长的对象,一般是一些老的对象,当一些对象在 Young 复制转移一定的次数以后,对象就会被转移到 Tenured 区,一般如果系统中用了 application 级别的缓存,缓存中的对象往往会被转移到这一区间。
- Perm,永久代。(jdk8 PermSize被MetaspaceSize代替?) 主要保存 class,method,filed 对象,这部门的空间一般不会溢出,除非一次性加载了很多的类,不过在涉及到热部署的应用服务器的时候,有时候会遇到 java.lang.OutOfMemoryError : PermGen space 的错误,造成这个错误的很大原因就有可能是每次都重新部署,但是重新部署后,类的 class 没有被卸载掉,这样就造成了大量的 class 对象保存在了 perm 中,这种情况下,一般重新启动应用服务器可以解决问题。
Linux 修改 /tomcat/bin/catalina.sh 文件,把下面信息添加到文件第一行。
机子内存如果是 8G,一般 PermSize 配置是主要保证系统能稳定起来就行:
https://www.cnblogs.com/redcreen/archive/2011/05/04/2037057.html
JAVA_OPTS="-Dfile.encoding=UTF-8 -server -Xms6144m -Xmx6144m -XX:NewSize=1024m
-XX:MaxNewSize=2048m -XX:PermSize=512m -XX:MaxPermSize=512m
-XX:MaxTenuringThreshold=10 -XX:NewRatio=2 -XX:+DisableExplicitGC"-Dfile.encoding:默认文件编码
-server:表示这是应用于服务器的配置,JVM 内部会有特殊处理的
-XX:+UseConcMarkSweepGC (CMS) 设置GC收集器(注意碎片化,见下文)
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path/heap/dump 让JVM在遇到OOM(OutOfMemoryError)时生成Dump文件
--堆栈设置
-Xmx1024m:设置JVM最大可用内存为1024MB(默认物理内存1/4)
-Xms1024m:设置JVM最小内存为1024m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xss128k:设置每个线程的栈大小。JDK5.0以后每个线程栈大小为1M(单线程栈不够用或线程过多都有可能栈溢出)
--设置年轻代
-Xmn1g:设置年轻代大小为1G。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小。
-XX:NewSize:设置年轻代大小
-XX:NewRatio=4:设置年轻代(包括 Eden 和两个 Survivor 区)与老年代的比值(除去永久代)。设置为 4,则年轻代与老年代所占比值为 1:4,年轻代占整个堆的 1/5
-XX:MaxNewSize:设置最大的年轻代大小
-XX:SurvivorRatio=n
--设置永久代
-XX:PermSize:设置永久代大小.jdk8 PermSize被MetaspaceSize代替?,MetaspaceSize共享heap,不会再有java.lang.OutOfMemoryError:PermGen space,可以不设置
-XX:MaxPermSize:设置最大永久代大小
--打印信息
-XX:+PrintGCDetails
输出形式: [GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured: 112761K->10414K(121024K),0.0433488 secs] 121376K->10414K(130112K), 0.0436268 secs]
-XX:+PrintGCTimeStamps(打印GC发生的时间)
输出形式:11.851: [GC 98328K->93620K(130112K), 0.0082960 secs]
-XX:+PrintGCApplicationStoppedTime(GC程序暂停时间)
输出形式:Total time for which application threads were stopped: 0.0468229 seconds
-XX:+PrintGCApplicationConcurrentTime(打印每次GC前,程序未中断的执行时间,两次GC间隔?)
输出形式:Application time: 0.5291524 seconds
-XX:MaxTenuringThreshold=10:设置垃圾最大年龄,默认为:15。如果设置为 0 的话,则年轻代对象不经过 Survivor 区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在 Survivor 区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概论。
-XX:+DisableExplicitGC:这个将会忽略手动调用 GC 的代码使得 System.gc() 的调用就会变成一个空调用,完全不会触发任何 GC
并行GC
-XX:+UseParallelOldGC
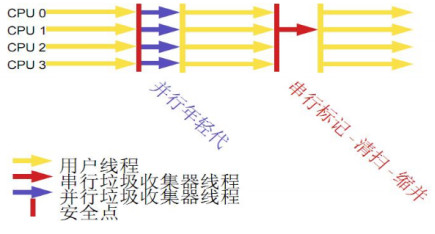
CMS 并发标记清除
-XX:+UseConcMarkSweepGC
优点:STW时间短
缺点:碎片化问题,需要手动触发FULLGC或重启,解决碎片

Full gc
full gc是对新生代,旧生代,以及持久代的统一回收,比较慢,系统中应当尽量减少full gc的次数。
如下几种情况下会发生full gc:
《老年代空间不足
《持久代空间不足
《CMS GC时出现了promotion failed和concurrent mode failure
《统计得到新生代minor gc时晋升到旧生代的平均大小小于旧生代剩余空间(分担担保)
《直接调用System.gc,可以DisableExplicitGC来禁止
《存在rmi调用时,默认会每分钟执行一次System.gc,可以通过-Dsun.rmi.dgc.server.gcInterval=3600000来设置大点的间隔。
调优建议
基本步骤:打印GC日志、通过日志分析项目吞吐量+STW、分析GC原因
GC日志分析工具:GCeasy网站、GcViewer(github) 有助于分析GC原因、并提出优化意见
GcViewer:https://www.cnblogs.com/o-andy-o/p/4058271.html https://blog.csdn.net/u013213157/article/details/74687028
若JVM内存出现问题,首先考虑分析内存dump->hprof文件信息
代码调优优先参数调优,根本是找到代码问题,JVM调优只是最终手段
Jvm内存溢出:堆溢出(dump检查);metadata溢出(Class加载过多);栈总内存溢出(可能Tread过多);单线程栈溢出 等
设置-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path/heap/dump
dump内存对比,推荐使用MAT,定位占用内存的 大对象或数量异常对象,
加大虚拟机内存,调整内存分配比例,检查引用释放问题(数组,容器,TL),检查局部变量(单线程栈溢出 )
Minor/Full GC频繁:(分别低于10s/10分钟一次,仅参考)
有无异常占用或是碎片:
dump内存对比gc前后,哪些对象一直不能被GC,哪些增长过于迅速。
检查引用释放问题。
减少大对象/数组等创建(复用、及时释放)
容量过小:
提高对应年代的内存容量。或调整年轻代老年代比例。
(年轻代太小会造成频繁MinorGC,导致更多对象进入老年代,导致频繁Full GC)
Minor/Full GC STW时间过长:(勇士超过50ms/1s,仅参考)
改变GC策略(CMS 最小停顿/G1 吞吐量大适合4g以上堆内存)。
堆内存可能过大,可适当缩小堆,
或集群、分布式处理,减少单进程堆大小且保证并发量
总结:
1、减少使用、创建全局变量和大对象,多复用减少new(),并及时释放;
2、调整新生代/老年代的大小到最合适;
3、选择合适的GC收集器;
简单例子:
使用-Xmn调到1/3 总内存,避免年轻代过大,gc时间长。(用-XX:NewRatio设置可能无效,用 -Xmn)。
添加-XX:+PrintTenuringDistribution 参数观察各个Age的对象总大小,调整进入老年代年龄-XX:MaxTenuringThreshold。
-Xms -Xmx,最大最小值设置相同,防止垃圾收集器收缩堆产生额外开销
网络借鉴的调优总结
https://www.cnblogs.com/lcword/p/5857918.html
年轻代大小选择
- 响应时间优先的应用:尽可能设大,直到接近系统的最低响应时间限制(根据实际情况选择)。在此种情况下,年轻代收集发生的频率也是最小的。同时,减少到达年老代的对象。
- 吞吐量优先的应用:尽可能的设置大,可能到达Gbit的程度。因为对响应时间没有要求,垃圾收集可以并行进行,一般适合8CPU以上的应用。
年老代大小选择
- 响应时间优先的应用:年老代使用并发收集器,所以其大小需要小心设置,一般要考虑并发会话率和会话持续时间等一些参数。如果堆设置小了,可以会造成内存碎片、高回收频率以及应用暂停而使用传统的标记清除方式;如果堆大了,则需要较长的收集时间。最优化的方案,一般需要参考以下数据获得: 减少年轻代和年老代花费的时间,一般会提高应用的效率
- 并发垃圾收集信息
- 持久代并发收集次数
- 传统GC信息
- 花在年轻代和年老代回收上的时间比例
- 吞吐量优先的应用:一般吞吐量优先的应用都有一个很大的年轻代和一个较小的年老代。原因是,这样可以尽可能回收掉大部分短期对象,减少中期的对象,而年老代尽存放长期存活对象。
较小堆引起的碎片问题
因为年老代的并发收集器使用标记、清除算法,所以不会对堆进行压缩。当收集器回 收时,他会把相邻的空间进行合并,这样可以分配给较大的对象。但是,当堆空间较小时,运行一段时间以后,就会出现“碎片”,如果并发收集器找不到足够的空 间,那么并发收集器将会停止,然后使用传统的标记、清除方式进行回收。如果出现“碎片”,可能需要进行如下配置:
- -XX:+UseCMSCompactAtFullCollection:使用并发收集器时,开启对年老代的压缩。
- -XX:CMSFullGCsBeforeCompaction=0:上面配置开启的情况下,这里设置多少次Full GC后,对年老代进行压缩
使用CMS垃圾收集器产生promotion failed –> concurrent mode failure
https://blog.csdn.net/21aspnet/article/details/88772421
CMS并行GC是大多数应用的最佳选择,然而, CMS并不是完美的,在使用CMS的过程中会产生2个最让人头痛的问题:
- promotion failed
- concurrent mode failure
第一个问题promotion failed 是在进行Minor GC时,Survivor Space放不下,对象只能放入老年代,而此时老年代也放不下造成的,多数是由于老年带有足够的空闲空间,但是由于碎片较多,这时如果新生代要转移到老年带的对象比较大,所以,必须尽可能提早触发老年代的CMS回收来避免这个问题(promotion failed时老年代CMS还没有机会进行回收,又放不下转移到老年带的对象,因此会出现下一个问题concurrent mode failure,需要stop-the-wold GC- Serail Old)。
下面是一个promotion failed的一条gc日志:
106.641: [GC 106.641: [ParNew (promotion failed): 14784K->14784K(14784K), 0.0370328 secs]106.678: [CMS106.715: [CMS-concurrent-mark: 0.065/0.103 secs] [Times: user=0.17 sys=0.00, real=0.11 secs]
(concurrent mode failure): 41568K->27787K(49152K), 0.2128504 secs] 52402K->27787K(63936K), [CMS Perm : 2086K->2086K(12288K)], 0.2499776 secs] [Times: user=0.28 sys=0.00, real=0.25 secs]第二个问题concurrent mode failure 是在执行CMS GC的过程中同时业务线程将对象放入老年代,而此时老年代空间不足,这时CMS还没有机会回收老年带产生的,或者在做Minor GC的时候,新生代救助空间放不下,需要放入老年代,而老年代也放不下而产生的。尽管CMS使用一个叫做分配担保的机制,每次Minor GC之后要保证新生代的空间survivor + eden > 老年带的空闲时间,但是对象分配是不可预测的,总会有写对象分配在老年带是满足不了的。
下面是一个concurrent mode failure的一条gc日志:
0.195: [GC 0.195: [ParNew: 2986K->2986K(8128K), 0.0000083 secs]0.195: [CMS0.212: [CMS-concurrent-preclean: 0.011/0.031 secs] [Times: user=0.03 sys=0.02, real=0.03 secs]
(concurrent mode failure): 56046K->138K(57344K), 0.0271519 secs] 59032K->138K(65472K), [CMS Perm : 2079K->2078K(12288K)], 0.0273119 secs] [Times: user=0.03 sys=0.00, real=0.03 secs]首先我们经常遇到promotion failed问题,这也确实是个很头痛的问题,一般是进行Minor GC的时候,发现救助空间不够,所以,需要移动一些新生带的对象到老年带,然而,有些时候尽管老年带有足够的空间,但是由于CMS采用标记清除算法,默认并不使用标记整理算法,可能会产生很多碎片,因此,这些碎片无法完成大对象向老年带转移,因此需要进行CMS在老年带的Full GC来合并碎片。
这个问题的直接影响就是它会导致提前进行CMS Full GC, 尽管这个时候CMS的老年带并没有填满,只不过有过多的碎片而已,但是Full GC导致的stop-the-wold是难以接受的。
解决这个问题的办法就是可以让CMS在进行一定次数的Full GC(标记清除)的时候进行一次标记整理算法,CMS提供了以下参数来控制:
-XX:UseCMSCompactAtFullCollection -XX:CMSFullGCBeforeCompaction=5也就是CMS在进行5次Full GC(标记清除)之后进行一次标记整理算法,从而可以控制老年带的碎片在一定的数量以内,甚至可以配置CMS在每次Full GC的时候都进行内存的整理。
另外,有些应用存在比较大的对象朝生熄灭,这些对象在救助空间无法容纳,因此,会提早进入老年带,老年带如果有碎片,也会产生promotion failed, 因此我们应该控制这样的对象在新生代,然后在下次Minor GC的时候就被回收掉,这样避免了过早的进行CMS Full GC操作,下面的一个配置样例就通过增加救助空间的大小来解决这个问题:
-Xmx4000M -Xms4000M -Xmn600M -XXmSize=500M -XX:MaxPermSize=500M -Xss256K -XX:+DisableExplicitGC -XX:SurvivorRatio=1 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled eCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSClassUnloadingEnabled -XX:LargePageSizeInBytes=128M -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+PrintClassHistogram -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:log/gc.log上面讨论了promotion failed引起的原因以及解决方案,除了promotion failed还有一个情况会引起CMS回收失败,从而退回到Serial Old收集器进行回收,我们在线上尤其要注意的是concurrent mode failure出现的频率,这可以通过-XX:+PrintGCDetails来观察,当出现concurrent mode failure的现象时,就意味着此时JVM将继续采用Stop-The-World的方式来进行Full GC,这种情况下,CMS就没什么意义了,造成concurrent mode failure的原因是当minor GC进行时,旧生代所剩下的空间小于Eden区域+From区域的空间,或者在CMS执行老年带的回收时有业务线程试图将大的对象放入老年带,导致CMS在老年带的回收慢于业务对象对老年带内存的分配。
解决这个问题的通用方法是调低触发CMS GC执行的阀值,CMS GC触发主要由CMSInitiatingOccupancyFraction值决定,默认情况是当旧生代已用空间为68%时,即触发CMS GC,在出现concurrent mode failure的情况下,可考虑调小这个值,提前CMS GC的触发,以保证旧生代有足够的空间。
总结:
1. promotion failed –> concurrent mode failure
Minor GC后, Survivor Space容纳不了剩余对象,将要放入老年带,老年带有碎片或者不能容纳这些对象,就产生了concurrent mode failure, 然后进行stop-the-world的Serial Old收集器。
解决办法:-XX:UseCMSCompactAtFullCollection -XX:CMSFullGCBeforeCompaction=5(CMS一定频率执行标记整理法) 或者 调大新生代或者救助空间
2. concurrent mode failure
CMS是和业务线程并发运行的,在执行CMS的过程中有业务对象需要在老年带直接分配,例如大对象,但是老年代没有足够的空间来分配,所以导致concurrent mode failure, 然后需要进行stop-the-world的Serial Old收集器。
解决办法:+XX:CMSInitiatingOccupancyFraction(调低触发CMS GC执行的阀值,提前触发GC),调大老年带的空间,+XX:CMSMaxAbortablePrecleanTime
总结一句话:使用标记整理清除碎片和提早进行CMS GC操作。
检查工具
GC日志分析
GCeasy网站、GcViewer(github) 有助于分析GC原因、并提出优化意见
GcViewer:https://www.cnblogs.com/o-andy-o/p/4058271.html https://blog.csdn.net/u013213157/article/details/74687028
https://www.bilibili.com/video/av52674111/?p=31
GcViewer几个关键值:吞吐量(推荐达到90%以上)、FullGC次数、FullGC用时占比、各GC最大/平均pause时间
Eclipse Memory Analysis Tools (MAT内存泄漏)
https://cloud.tencent.com/developer/article/1361381
https://www.bilibili.com/video/av52674111/?p=7
官网下载安装后是一个单独的Eclipse程序,MAT可以分析heapdump[hprof]文件,分析可疑的问题对象,找到占用最大内存的对象类型,定位到其保存的引用,找到未释放的引用。
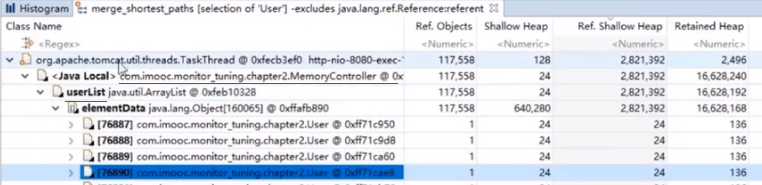
MAT按内存占用查找
发现User对象占用异常,右键分析其GCROOTS

分析结果,找到大量User对象强引用存在于MemoryController.userList中未被释放
MAT按照对象数量查找
同样可以右键分析

Linux Top
排查定位占用CPU/内存异常 的JAVA进程ID和JAVA线程ID
top 找到进程7930占用CPU异常

top 打印进程7930的线程占用情况,进程7930中前四个线程占用cpu较高。
![]()
此处线程PID对应jstack的线程dump文件中的nid=0x2037 (10-16进制转化)。可以直接定位线程dump文件中的问题所在。


Jstack -l ${PID} (线程dump -l 打印锁信息)
jps/top 查看java程序PID。
打印进程7930的线程dump到txt文件,并下载到本地。SecureCRT作为Linux客户端为例。
![]()
查看线程状态,检查使线程阻塞/等待的方法,并找到死锁的对应线程。
可以看到线程处于阻塞状态 at org.apache.lucene.index.IndexWriter.commit方法中,其在等待锁 waiting to lock <0x000000072039ce18> 。其已经拿到的锁locked <0x0000000711ab59c8>。通过期等待可以找到对应的持锁线程,看其停留在哪个方法里,导致不能释放锁。
"Thread-33" prio=10 tid=0x00002aaac8013000 nid=0x3264 waiting for monitor entry [0x00000000437e4000]
java.lang.Thread.State: BLOCKED (on object monitor)
at org.apache.lucene.index.IndexWriter.commit(IndexWriter.java:3525)
- waiting to lock <0x000000072039ce18> (a java.lang.Object)
at org.apache.lucene.index.IndexWriter.commit(IndexWriter.java:3505)
at com.xiaomi.miliao.mt.fulltextindex.UserIndexUpdater.updatePlUserIndex(UserIndexUpdater.java:229)
- locked <0x0000000711ab59c8> (a java.lang.Object)
at com.xiaomi.miliao.mt.fulltextindex.SearcherDelegate.updatePlUserIndex(SearcherDelegate.java:522)
at 一般在线程dump文件结尾会有deadlock分析

VisualVM (堆dump,大内存对象检查,线程dump+死锁)


可以查看对象的成员变量,和他被哪些外部对象引用。排查未被释放的原因,但是其没有MAT直观,不利于反向推导问题引用。

线程dump与Jstack相同,死锁分析会在最后显示

cpu抽样器:动态实时检查方法/线程 总用时和占用CPU时间

内存抽样器:动态实时检查各类型对象/线程占用内存情况

jconsole(监控内存中各个区使用状况和GC频率,检查Thread死锁)



 浙公网安备 33010602011771号
浙公网安备 33010602011771号