RabbitMQ常见问题
参考:https://blog.csdn.net/youbl/article/details/80425959
0、防止消息丢失
生产者:confire模式。异步等待MQ回调通知是否接收到消息,判断是否重发。
MQ:持久化。设置Queue持久化 + Msg持久化deliveryMode=2
消费者:手动ACK。注意:超时、死循环、Qos、幂等
1、自动ack机制会导致消息丢失的问题
自动ack消费者接到消息立即ack。将自动ack改为手动ack
2、启用手动ack机制后,没有及时ack导致的队列异常(Unacked过多)
模式:成功ack,异常失败无操作。
为解决问题1,处理消息完成后再做ack响应,失败什么都不做,这样消息会储存在MQ的Unacked消息里不会丢失。
但是如果RabbitMQ没有得到ack响应,这些消息会堆积在Unacked消息里,不会抛弃。
而且若Consumer不断开连接,这些Unacked消息也不会变回ready的消息,不能重新推送。

3 启用nack+重入队 机制后,导致的死循环(Ready过多)
模式:成功ack,异常失败nack+ requeue=true
为解决问题2,在处理消息异常时nack。正常就ack,失败就nack消息重新入队首,并等下一次重新消费。
但是新问题现象是Ready的消息猛增,一直不见减少。原因是出异常后,把消息塞回队列头部,下一步又消费这条会出异常的 消息,又出错塞回队列头部……进入了死循环了,新来的消息不会被消费,导致堆积了
可以考虑通过给队列绑定死信交换机DLX(basic.reject/basic.nack 且 requeue=false 消息进入绑定的DLX),保存并处理异常或多次重试的信息。
https://blog.csdn.net/shanchahua123456/article/details/84324059
方案1:
避免反复重试的方法,在消费消息时先在redis中记入 消息ID:count +TTL,下次再消费时判断redis中次数,超次则不重入队,记录失败消息内容或转发其他MQ或进入DLX。这样保证在一定时间内同一消息不会反复消费失败,避免死循环阻塞,且避免消息丢失等待补偿机制。补偿机制也可以参考redis中 消息ID:count 判断是否再次补偿
4、启用Qos和ack机制后,没有及时ack导致的队列堵塞;
// 启用QoS,每次预取5条消息,避免消息处理不过来,全部堆积在本地缓存里
channel.BasicQos(0, 5, false);
开启QoS,当RabbitMQ的队列达到5条Unacked消息时,不会再推送消息给Consumer;
参考上边解决没有及时ack
5 消费者要注意幂等性设计,以防重复消费
出现重发的情况
1.代码逻辑/补偿机制等情况可能出现消息重发。
2.消费者断开连接时Unacked的消息会再次入队,但是重入队的消息可能已经被消费 。
3.nack重入队
首要前提消息要有唯一标示
a.根据ID判断是否重复消费(可以用Redis+lua保证原子性的判断更新)
b.多次重复执行,结果一致
c.利用数据库主键/唯一键
d.update+where 条件乐观锁执行
6 提高消费者效率
增加消费者单机监听线程数,直接增加消费者进程数
7 消息堆积处理
7.1 线上消费者出现BUG,或消费逻辑过慢
一般手动AKC+重入队会造成消息堆积,自动ACK虽然不会堆积,但是可能造成消息丢失。
方法一:若时间来得及可以修复消费者BUG,并部署更多的消费者一起消费快速将堆积的消息落库。
方法二:若来不及修复,此时可以部署几台新消费者,其工作只从队列里读取数据,不执行业务逻辑直接把消息转存到新的MQ中(或缓存中),使原业务MQ恢复畅通避免MQ被撑爆。再部署几倍量的无bug的消费者去消费新队列中的消息,快速将堆积的消息落库
注意:
1 为消息设置TTL时,最好绑定死信队列,避免消息超时丢失。
2 有序性问题
3 自动ACK丢失补偿问题
7.2 避免触发流控机制,导致不接收生产者消息。
服务端默认配置是当内存使用达到40%,磁盘空闲空间小于50M,即启动内存报警,磁盘报警;报警后服务端触发流控(flow control)机制。一般地,当发布端发送消息速度快于订阅端消费消息的速度时,队列中堆积了大量的消息,导致报警,就会触发流控机制。
如下边流程图所示,发送消息后MQ首先确认消息堆积情况。MQ会持续从队列中取出堆积的消息将其发送出去,直到触发图中分支能返回接收新信息。否则MQ就会持续的发送堆积消息,不去处理新来的消息,在流控机制的作用下,发送端就被阻塞了

7.3避免触发流控应对措施:
- 加消费机器,加消费线程。
- 打破发送循环条件。如上图中返回接收新消息的分支。
- 设置合适的qos值,当qos值被用光,而新的ack未被mq接收时,就可以跳出发送循环,去接收新的消息。
- 消息者到主动block接收进程,消费者感知到接收消息的速度过快时,主动block,利用block与unblock方法调节接收速率。当接收进程被block时,mq跳出发送循环。
- 建立新的队列:若服务器cpu资源有较多剩余,而又不需要保证消息的顺序的情况下可以通过建立新的vhost,在该vhost下创建queue,生产者将消息发送掉新的queue,消费者同时订阅新旧queue。
- 使用缓存:在生产者端使用缓存,当生产速率受到流控限制时,缓存数据。在堆积的消息被处理完后,生产速率恢复正常时,此时将缓存的数据发送给MQ。
- 更新rabbitmq版本,在新版2.8.4中,在有大量消息堆积时,生产速率会受到抑制,但生产者不会完全被阻塞。
8 任务间相互依赖和有序性
相互依赖:
相互依赖的任务一定要注意入队顺序,或是分配到不同队列中防止阻塞。
例如:B依赖A先执行,但是A在B之后入队。
有序性:
比如同步数据库操作binlog顺序不能错。或update状态时先后顺序不能乱。
一个queue多个消费者时就可能出现执行顺序混乱。
解决:保证queue一对一消费。若想要提高消费能力可以考虑设计规则拆分队列,但是每个队列只有一个消费者。

9 消息持久化
注意队列持久化与消息持久化不同,队列持久化是指保存队列信息,重启后自动创建和绑定。但是只有队列持久化是无法恢复消息的。需要设置消息持久化。
(1)exchange持久化,在声明时指定durable => 1
(2)queue持久化,在声明时指定durable => 1
(3)消息持久化,在投递时指定delivery_mode => 2(1是非持久化)
RabbitMQ在两种情况下会将消息写入磁盘:
消息本身在publish发布的时候就要求消息写入磁盘;
内存紧张,需要将部分内存中的消息转移到磁盘;
写入文件前会有一个Buffer,大小为1M(1048576),数据在写入文件时,首先会写入到这个Buffer,如果Buffer已满,则会将Buffer写入到文件(未必刷到磁盘); 有个固定的刷盘时间:25ms,也就是不管Buffer满不满,每隔25ms,Buffer里的数据及未刷新到磁盘的文件内容必定会刷到磁盘; 每次消息写入后,如果没有后续写入请求,则会直接将已写入的消息刷到磁盘。
10 高可用
普通集群模式:只是增加吞吐量,不保证高可用,不推荐
镜像集群模式:保证高可用,queue内容会拷贝到各节点服务器中。支持任一节点生产+消费。
缺点:非分布式,每个节点都有全部拷贝。
可在控制台创建镜像同步策略,创建queue时绑定策略
https://blog.csdn.net/winy_lm/article/details/81128181#t2
mirror queue内部有一套选举算法,会选出一个master,和若干个slaver。master和slaver 通过相互间不断发送心跳来检查是否连接断开。可以通过指定net_ticktime来控制心跳检查频率。
consumer,任意连接一个节点,若连上的不是master,请求会转发给master,为了保证消息的可靠性,consumer回复ack给master后,master删除消息并广播所有的slaver去删除。
publisher ,任意连接一个节点,若连上的不是master,则转发给master,由master存储并转发给其他的slaver存储。
如果master挂掉,则从slaver中选择消息队列最长的为master,在这种情况下可以存在消息未同步给ack消息未同步的情况,会造成消息重发(默认是异步同步的)。总共有以下几件事情发生:
1)1个最老的(队列最长的)的slaver提升为master,如果没有一个slaver是和master同步的则会造成消息丢失。
2) 要提升为master的slaver会认为以前所有连接挂掉的master的消费者都断开了连接。那么存在clinet发送了ack的消息单还在路上是master挂掉的情况,或者master收到了ack但是在广播给slaver的时候master挂掉的情况,所以新的master别无选择,只能认为消息没有被确认。他会requeue他认为没有ack的消息。那么client可能就收到了重复的消息,并要再次发送ack。
3)从镜像队列中消费的client支持了consumer Cancellation通知的,将收到通知并订阅的mirrored-queue被取消了,这是因为该mirrored-queue 升级成了master,这是client需要重现去找mirrored-queue上消费,这样就避免了client继续发送ack到老的挂掉的master上。避免收到新的master发送的相同的消息。
4)如果noAck=true,且在mirrored-queue上消费,那么在切换时由于服务器是先ack然后发送到noAck=true的消费者,这时连接断开可能导致该数据丢失
如果slaver挂掉,则集群的节点状态没有任何变化。只要client没有连到这个节点上,也不会给client发送失败的通知。在检测到slaver挂掉的期间publish消息会有延迟。如果配置了高可用策略是自动同步,当slaver起来后,队列中有大量的消息需要同步,将会整个集群阻塞长时间的不能读写直到同步结束。
这两个挂掉的情况都需要客户端镜像容错,比如在连接断开的时候进行重连(官方的Java和.net 客户端提供了callback方法在监听到链接失败的时候调用。Java在Connection和channel类中提供了ShutdownListener 的callback方法,.net client在IConnecton中提供了ConnectionShuedown在Imodel中提供了ImodelShutdown事件供调用) 。也可以在client和server之间加入LoadBalancer.比如haproxy做负载均衡。
11 RabbitMQ的用户角色分类
none、management、policymaker、monitoring、administrator
none
不能访问 management plugin
management
用户可以通过AMQP做的任何事外加:
列出自己可以通过AMQP登入的virtual hosts
查看自己的virtual hosts中的queues, exchanges 和 bindings
查看和关闭自己的channels 和 connections
查看有关自己的virtual hosts的“全局”的统计信息,包含其他用户在这些virtual hosts中的活动。
policymaker
management可以做的任何事外加:
查看、创建和删除自己的virtual hosts所属的policies和parameters
monitoring
management可以做的任何事外加:
列出所有virtual hosts,包括他们不能登录的virtual hosts
查看其他用户的connections和channels
查看节点级别的数据如clustering和memory使用情况
查看真正的关于所有virtual hosts的全局的统计信息
administrator
policymaker和monitoring可以做的任何事外加:
创建和删除virtual hosts
查看、创建和删除users
查看创建和删除permissions
关闭其他用户的connections
12 控制台使用
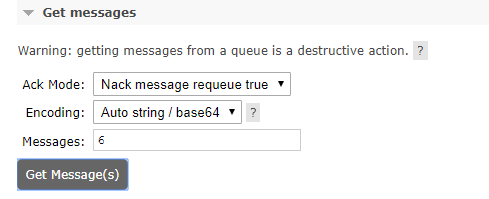
a.查看队列中的消息,进入对应队列的详情页,选择get messages。可以设置ack模式,编码格式,查看消息量。
如果只想查看请选择NACK模式。

13 创建channel过多异常
默认一个RabbitTemplate在RabbitMQ中相当于一个connection,每发送一次消息相当于channel,MQ确认收到消息后释放channel。每个connection最多支持2048个channel,从一个connection同时超过2048个线程并发发送,channel超过2048,会报异常org.springframework.amqp.AmqpResourceNotAvailableException: The channelMax limit is reached. Try later。
后台管理页面查看connection+channel
10个线程并发发送10个消息,监控到10个channel生成,接收完成后释放channel。如果发送方是publisher-confirms模式,channel会保持到confirm回调完成再释放,影响并发性能。每个connection最多支持2048个channel。
测试启动publisher-confirms后,500个线程并发发送,部分消息报AmqpResourceNotAvailableException。400个线程通过一个RabbitTemplate并发发送10000消息,最高同时就可能产生1000多的channel。因为channel在等待执行confirm回调。10000消息全部发送在几秒内完成,10000消息全部confirm回调完成用时22秒,此时所有channel全部释放。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号