

segfault at 7fff6d99febc ip 0000003688644323 sp 00007fff6d99fd30 error 7 in libc.so.6[3688600000+175000]
简述:
进程信号11段错误,出core。内核dmesg打印:*****(程序名字)[31255]: segfault at 7fff6d99febc ip 0000003688644323 sp 00007fff6d99fd30 error 7 in libc.so.6[3688600000+175000]
直接原因:
sp指针向下增长时,越界,访问到mmap以只读映射的地址空间,导致写操作异常。do_page_fault失败,给进程发了信号11。
环境:
root ~ # uname -a
Linux localhost 2.6.30-gentoo-r8 #47 SMP Mon Sep 21 03:44:07 EDT 2015 x86_64 GNU/Linux
根本原因:
进程地址空间大致如下分布如下(我的环境是这个分布):
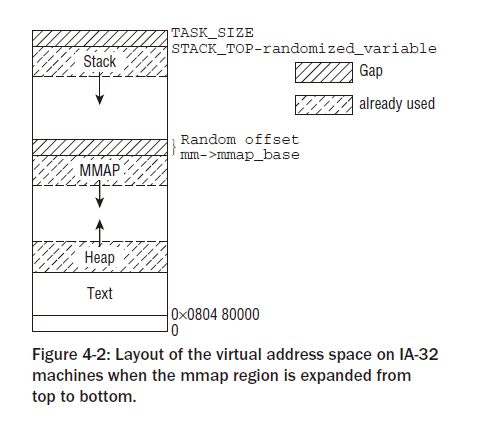
(图片摘自《深入Linux内核架构》)
与问题相关的关键点
①stack向下增长,所以系统必须给stack留下足够的地址空间。位于stack下面的是受限于mm->mmap_base的mmap地址空间。
②mm->mmap_base表示用于mmap的地址空间的最大值,查找方向向下,所有的mmap系统调用分配出来的地址空间位于mm->mmap_base之下。
综合①和②,可以得到结论mm->mmap_base必须小于并远离Stack。但是2.6内核这里存在bug,不能一定满足该条件。
mmap_base赋值分析:
mm->mmap_base赋值在load_elf_binary()->arch_pick_mmap_layout()->mmap_base()中:
static unsigned long mmap_base(void)
{
unsigned long gap = current->signal->rlim[RLIMIT_STACK].rlim_cur;//改值为栈大小限制,系统可配,默认1M。问题环境改值为8M
if (gap < MIN_GAP)
gap = MIN_GAP; //走这个逻辑,MIN_GAP值为128M,gap值更新为128M。
else if (gap > MAX_GAP)
gap = MAX_GAP;
//7FFFFFFFF000(TASK_SIZE) - 8000000(gap)
//[0,FFFFFFF000], mmap_rnd()的取值范围区间
//[7EFFF8000000,7FFFF7FFF000],返回的mmap_base的地址的取值范围
return PAGE_ALIGN(TASK_SIZE - gap - mmap_rnd());
}
从代码中看,mmap_base赋值中只考虑了当前栈大小,但并不能保证远离stack。
极端情况下,mmap_rnd随机值为0时,mmap_base被赋值为TASK_SIZE-128M的位置,即:7FFFF7FFF000
栈底赋值分析:
Stack的栈底为:STACK_TOP - random_variable,经计算取值范围为:[7FFC00000000,7FFFFFFFF000]
#define STACK_TOP TASK_SIZE
retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP),
executable_stack);
static unsigned long randomize_stack_top(unsigned long stack_top)
{
unsigned int random_variable = 0;
if ((current->flags & PF_RANDOMIZE) &&
!(current->personality & ADDR_NO_RANDOMIZE)) {
random_variable = get_random_int() & STACK_RND_MASK; //[0, 3fffff000]
random_variable <<= PAGE_SHIFT;
}
#ifdef CONFIG_STACK_GROWSUP
return PAGE_ALIGN(stack_top) + random_variable;
#else
return PAGE_ALIGN(stack_top) - random_variable; //[7FFC00000000,7FFFFFFFF000]
#endif
}
综上,这里确认2.6的内核存在bug。改动方法是,给mmap_base至少再减去 STACK_RND_MASK。
该问题内核最早于2009年修复:
https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/commit/arch/x86/mm/mmap.c?id=80938332d8cf652f6b16e0788cf0ca136befe0b5
新版本的内核实现:
https://code.woboq.org/linux/linux/arch/x86/mm/mmap.c.html#mmap_base
问题排查过程:
①充分分析core文件,确认栈的增长是正常的。导致异常的地址,也确实是正常的。函数调用时,参数正常压栈的地址。
②怀疑内核问题(缺页中断失败?)。找到全部打印 segfault at 的内核代码,逐个分析,对可能的路径添加调试。确认错误原因在,do_page_fault的1130行,判断vm是否可写时失败。
③正常来说,这个vm是stack的vm_area_struct结构体,一定是有写权限的。怀疑vm的问题,增加调试,在出问题时,打印vm_area_struct的信息。根据vma中的file指针找到被mmap的文件的名字(我的环境是个字符设备)。
至此确认问题原因:栈的增长踩到了字符设备的mmap地址空间,该mmap是只读。调试代码如下:
/* * This routine handles page faults. It determines the address, * and the problem, and then passes it off to one of the appropriate * routines. */ dotraplinkage void __kprobes do_page_fault(struct pt_regs *regs, unsigned long error_code) { struct vm_area_struct *vma; struct task_struct *tsk; unsigned long address; struct mm_struct *mm; int write; int fault; tsk = current; mm = tsk->mm; prefetchw(&mm->mmap_sem); /* Get the faulting address: */ address = read_cr2(); ... if (unlikely(expand_stack(vma, address))) { bad_area(regs, error_code, address); return; } /* * Ok, we have a good vm_area for this memory access, so * we can handle it.. */ good_area: write = error_code & PF_WRITE; if (unlikely(access_error(error_code, write, vma))) { printk("svking vm_next info :start:%lx end:%lx flags:%lx\n", vma->vm_next->vm_start, vma->vm_next->vm_end, vma->vm_next->vm_flags); printk("svking vm info :start:%lx end:%lx flags:%lx\n", vma->vm_start, vma->vm_end, vma->vm_flags); printk("svking vm info :vm_file: %p\n", vma->vm_file); if (vma->vm_file) { printk("svking file name :%s, %s\n", vma->vm_file->f_dentry->d_iname, vma->vm_file->f_dentry->d_name.name); } bad_area_access_error(regs, error_code, address); return; } /* * If for any reason at all we couldn't handle the fault, * make sure we exit gracefully rather than endlessly redo * the fault: */ fault = handle_mm_fault(mm, vma, address, write); ... }
④分析mmap机制,确认mmap的返回的地址空间受控于进程的mm->mmap_base。同时mm->mmap_base是在进程启动时执行exec函数时确定的。所以怀疑mm->mmap_base赋值时存在问题。
⑤分析进程地址空间和mmap_base赋值函数,确认根本原因: “mm->mmap_base必须小于并远离Stack” 未能满足。
附:
调试日志(***屏蔽了业务关键字):
root ~ # tail -f /var/log/messages | grep -E "svking|segfault"
Jul 21 16:44:16 localhost kernel: [ 5489.150802] svking vm_next info :start:7fff13d58000 end:7fff13d6d000 flags:100177
Jul 21 16:44:16 localhost kernel: [ 5489.150990] svking vm info :start:7ffdcb558000 end:7fff13d58000 flags:400844fd
Jul 21 16:44:16 localhost kernel: [ 5489.151155] svking vm info :vm_file: ffff880082dbbcc0
Jul 21 16:44:16 localhost kernel: [ 5489.151260] svking file name :******, ******
Jul 21 16:44:16 localhost kernel: [ 5489.151388] ******[22867]: segfault at 7fff13d57ffc ip 00007fff6469ae99 sp 00007fff13d57ff0 error 7 in lib****.so[7fff64681000+2a000]
Jul 21 16:48:42 localhost kernel: [ 5754.180545] svking vm_next info :start:7fffb5202000 end:7fffb5217000 flags:100177
Jul 21 16:48:42 localhost kernel: [ 5754.180772] svking vm info :start:7ffe6ca02000 end:7fffb5202000 flags:400844fd
Jul 21 16:48:42 localhost kernel: [ 5754.180971] svking vm info :vm_file: ffff880082f74240
Jul 21 16:48:42 localhost kernel: [ 5754.181136] svking file name :******, ******
Jul 21 16:48:42 localhost kernel: [ 5754.181277] ******[32049]: segfault at 7fffb5201ff8 ip 00007ffff5b744ae sp 00007fffb5202000 error 7
ps:个人笔记,如有错误,期待指出,不喜勿喷。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号