从整理上理解进程创建、可执行文件的加载和进程执行进程切换,重点理解分析fork、execve和进程切换
327
原创作品转载请注明出处 + https://github.com/mengning/linuxkernel/
阅读并理解 task_struct 数据结构
代码位于 http://codelab.shiyanlou.com/source/xref/linux-3.18.6/include/linux/sched.h#1235
该结构体定义了 Linux 操作系统中的 PCB
其中最重要的项有:
- state:描述进程状态,-1 表示不可运行,0 表示可运行,大于 0 表示停止运行
- stack:描述进程栈
- usage:描述进程是否被使用
- flags:描述进程的标志
- prio,static_prio,normal_prio:描述进程优先级
- sched 相关结构体:描述进程调度相关数据
- policy:描述进程策略
- cpu 相关结构体:描述进程的 cpu 相关数据
- tasks,children 等:存储所有当前进程的子进程
- mm,active_mm,vmacache:描述进程内存分配与缓存相关数据
- exit_state,exit_code,exit_signal 等:描述进程退出状态
- pid:描述进程 id
- real_parent,parent:描述父进程 PCB
- start_time,real_start_time 等 time 相关数据:描述进程运行时间
- fs,files:描述进程文件系统信息与打开的文件相关信息
- signal,blocked 等数据:描述进程调度状态信息
- lock 等数据:描述进程加锁状态信息
通过阅读该数据结构,可以更深刻的体会到操作系统相关知识在具体实践中的应用
分析 fork 函数对应的内核处理过程 do_fork
代码位于 http://codelab.shiyanlou.com/source/xref/linux-3.18.6/kernel/fork.c#1623
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid;
trace_sched_process_fork(current, p);
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p);
if (unlikely(trace))
ptrace_event_pid(trace, pid);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}
首先根据标志位 clone_flags 判断是否要对该函数进行追踪
然后复制当前进程结构体,指针 p 指向新创建的进程结构体
判断 p 是否存在,若不存在,返回错误 nr = PTR_ERR(p)
若存在,则进一步执行 fork 处理
先从新进程结构体中取出进程 pid,并将其设置为返回值 nr
接着根据 clone_flags 设置父进程 id
然后判断否是 vfork,若不是,不做处理;若是,要确保父进程在子进程完成初始化后才能运行
将子进程加入调度队列
处理 vfork 调用中父进程等待子进程,确保子进程先运行
使用 gdb 跟踪分析一个 fork 系统调用内核处理函数 do_fork
使用 MenuOS 中的 test_fork.c 代替 test.c 启动 MenuOS
其中 Fork 测试函数如下
int Fork(int argc, char *argv[])
{
int pid;
/* fork another process */
pid = fork();
if (pid<0)
{
/* error occurred */
fprintf(stderr,"Fork Failed!");
exit(-1);
}
else if (pid==0)
{
/* child process */
printf("This is Child Process!\n");
}
else
{
/* parent process */
printf("This is Parent Process!\n");
/* parent will wait for the child to complete*/
wait(NULL);
printf("Child Complete!\n");
}
}
在 GDB 中打以下断点
b sys_clone b dup_task_struct b do_fork b copy_process b copy_thread b ret_from_fork
运行结果
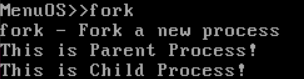
其中调试过程如下

观察实验结果,Fork 函数的调用过程为 sys_clone->do_fork->copy_process->dup_task_struct->copy_thread->ret_form_fork
理解编译链接的过程和 ELF 可执行文件格式
整个编译链接过程如下
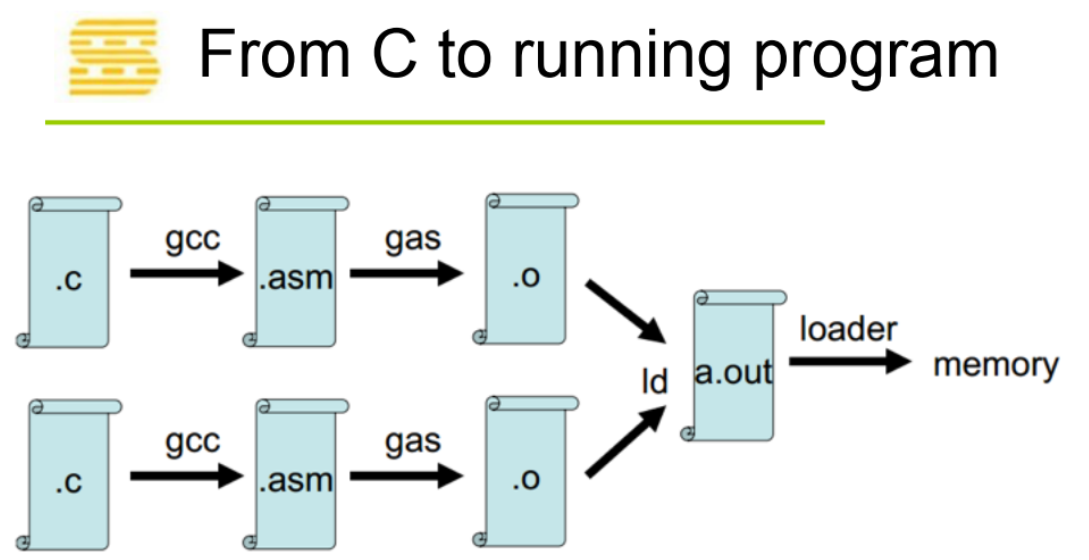

源文件 .c/.cpp 经过预处理,编译,汇编之后生成 .o,所有的 .o 链接起来共同构成可执行文件
预处理:主要是做一些代码文本的替换工作(该替换是一个递归逐层展开的过程)
编译:把预处理完的文件进行一系列词法分析(lex)、语法分析(yacc)、语义分析及优化后生成汇编代码,这个过程是程序构建的核心部分
汇编:汇编代码->机器指令
链接:这里讲的链接,严格说应该叫静态链接。多个目标文件、库->最终的可执行文件(拼合的过程)
ELF 格式可执行文件为 Linux 可执行文件格式,包括三种主要的类型:可执行文件、可重定向文件、共享库
一个可执行(executable)文件保存着一个用来执行的程序;该文件指出了exec(BA_OS)如何来创建程序进程映象
一个可重定位(relocatable)文件保存着代码和适当的数据,用来和其他的object文件一起来创建一个可执行文件或者是一个共享文件
一个共享库文件保存着代码和合适的数据,用来被不同的两个链接器链接
编程使用 exec* 库函数加载一个可执行文件
编写一个 .c 文件
#include <stdio.h>
int main()
{
printf("Hello World!\n");
return 0;
}
再编写一个 exec* 测试文件
#include <unistd.h>
int main() {
char *argv[] = {"./test", "test", (char *)0};
char *envp[] = {0};
execve("./test", argv, envp);
return 0;
}
将这两个文件编译成可执行文件
gcc test.c -o test
gcc exec.c -o exec
运行 exec 即可打印出 Hello World!
使用 gdb 跟踪分析一个 execve 系统调用内核处理函数 do_execve
在之前的 MenuOS 的 Fork 函数中加入 execlp("/bin/ls",“ls”,NULL);
在 GDB 中打以下断点
b do_execve b sys_execve b do_execve_common b exec_biniprm b search_binary_hanlder b load_elf_binary
运行结果
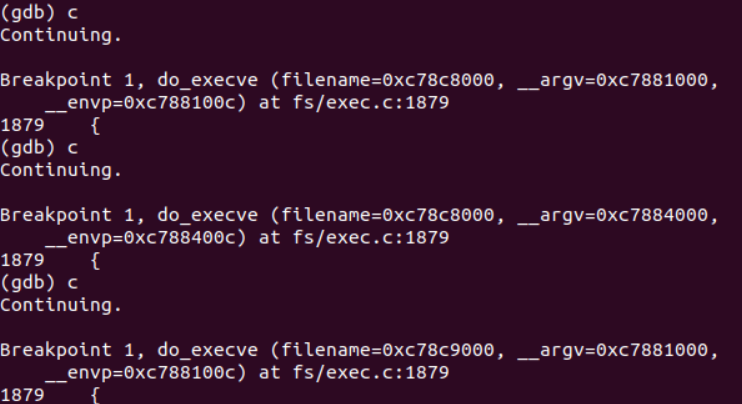
观察实验结果,调用顺序为sys_execve()->do_execve()->do_execveat_common()->__do_execve_file()->prepare_binprm()->search_binary_handler()->load_elf_binary()->start_thread()
理解Linux系统中进程调度的时机
调用schedule()的位置:
中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule()
内核线程可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度
用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度
搜索 schedule() 调用文件


可发现在网络,驱动,文件系统,加锁,内核相关处理中多次调用 schedule 函数
使用 gdb 跟踪分析一个 schedule() 函数
使用 gdb 打断点
b schedule b pick_next_task b context_switch b __switch_to
运行结果如下
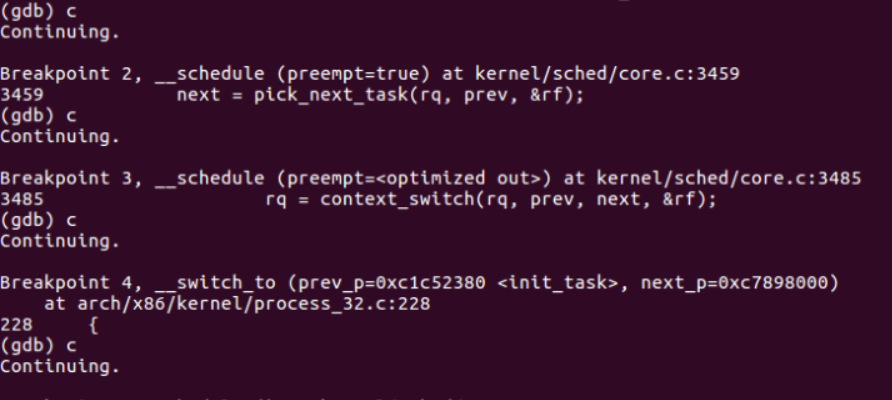
可以看出 schedule 调用 _schedule,_schedule 调用 pick_next_task,context_switch 函数,context_switch 函数调用 __switch_to
分析switch_to中的汇编代码
asm volatile("pushfl\n\t" /* 保存当前进程的标志位 */
"pushl %%ebp\n\t" /* 保存当前进程的堆栈基址EBP */
"movl %%esp,%[prev_sp]\n\t" /* 保存当前栈顶ESP */
"movl %[next_sp],%%esp\n\t" /* 把下一个进程的栈顶放到esp寄存器中,完成了内核堆栈的切换,从此往下压栈都是在next进程的内核堆栈中。 */
"movl $1f,%[prev_ip]\n\t" /* 保存当前进程的EIP */
"pushl %[next_ip]\n\t" /* 把下一个进程的起点EIP压入堆栈 */
__switch_canary
"jmp __switch_to\n" /* 因为是函数所以是jmp,通过寄存器传递参数,寄存器是prev-a,next-d,当函数执行结束ret时因为没有压栈当前eip,所以需要使用之前压栈的eip,就是pop出next_ip。 */
"1:\t" /* 认为next进程开始执行。 */
"popl %%ebp\n\t" /* restore EBP */
"popfl\n" /* restore flags */
/* output parameters 因为处于中断上下文,在内核中
prev_sp是内核堆栈栈顶
prev_ip是当前进程的eip */
: [prev_sp] "=m" (prev->thread.sp),
[prev_ip] "=m" (prev->thread.ip), //[prev_ip]是标号
"=a" (last),
/* clobbered output registers: */
"=b" (ebx), "=c" (ecx), "=d" (edx),
"=S" (esi), "=D" (edi)
__switch_canary_oparam
/* input parameters:
next_sp下一个进程的内核堆栈的栈顶
next_ip下一个进程执行的起点,一般是$1f,对于新创建的子进程是ret_from_fork*/
: [next_sp] "m" (next->thread.sp),
[next_ip] "m" (next->thread.ip),
/* regparm parameters for __switch_to(): */
[prev] "a" (prev),
[next] "d" (next)
__switch_canary_iparam
: /* reloaded segment registers */
"memory");
} while (0)
首先在当前进程 prev 的内核栈中保存 esi,edi 及 ebp 寄存器的内容
然后将 prev 的内核堆栈指针 ebp 存入 prev->thread.esp 中
把将要运行进程 next 的内核栈指针 next->thread.esp 置入 esp 寄存器中将 popl 指令所在的地址保存在 prev->thread.eip 中
这个地址就是 prev 下一次被调度通过 jmp 指令(而不是call指令)转入一个函数 __switch_to() 恢复 next 上次被调离时推进堆栈的内容
从现在开始,next 进程就成为当前进程而真正开始执行.
总结
本次实验加深了我对Linux系统的执行过程的理解
其中 Linux 通过复制父进程来创建一个新进程,通过调用 do_fork 来实现并为每个新创建的进程动态地分配一个 task_struct 结构
fork() 函数被调用一次,但返回两次
可以通过 fork,复制一个已有的进程,进而产生一个子进程
而 schedule() 函数实现进程调度,context_ switch 完成进程上下文切换,switch_ to 完成寄存器的切换

 浙公网安备 33010602011771号
浙公网安备 33010602011771号