Pod
1 Pod的基本概念
- 最小的部署单元
- 一组容器的集合
- 一个pod中的容器共享网络命名空间
- pod是短暂的,只要有更新,pod的地址就会变化
2 Pod存在的意义
pod是为了解决应用程序的亲密性,应用场景:
- 两个应用之间发生文件交互
- 两个应用需要通过127.0.0.1或者socket 通信(例如:nginx+php)
- 两个应用需要发生频繁的调用
3 Pod实现机制与设计模式
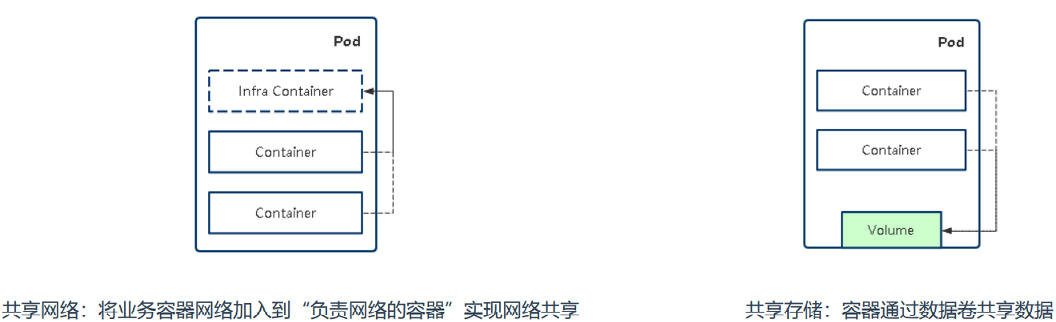
- 共享网络
- 共享存储
在宿主机上通过docker ps可以看到 infra Containter信息,k8s系统为每个Pod都启动了一个infra containter.使用的镜像是registry.aliyuncs.com/google_containers/pause:3.2
[root@node1 ~]# docker ps CONTAINER ID IMAGE COMMAND NAMES 407128176ee2 registry.aliyuncs.com/google_containers/pause:3.2 "/pause" k8s_POD_java-demo-574598985c-h9nhq_test_0a75cb99-4f2c-41c0-b215-4aff31fce63a_50 58647e3edc65 registry.aliyuncs.com/google_containers/pause:3.2 "/pause" k8s_POD_k8s-logs-ssqc5_ops_2906b90d-8741-4216-845a-811008cd6761_46 3af7774d708a registry.aliyuncs.com/google_containers/pause:3.2 "/pause" k8s_POD_elasticsearch-0_ops_172d4f4d-b4f7-4d55-8f4e-d61b4740048f_86 e625bf497da4 registry.aliyuncs.com/google_containers/pause:3.2 "/pause" k8s_POD_filebeat-6r2hg_ops_8cefc479-cb85-4c20-9609-4b16db58c7ee_57 daf713bc7722 registry.aliyuncs.com/google_containers/pause:3.2 "/pause" k8s_POD_dashboard-metrics-scraper-694557449d-pj5kk_kubernetes-dashboard_d69dd18e-3423-4e94-bf14-5fdeb42acaba_1131 bbad63177bf2 registry.aliyuncs.com/google_containers/pause:3.2 "/pause" k8s_POD_kubernetes-dashboard-5ff49d5845-l5l78_kubernetes-dashboard_ec5f7aa8-813e-4447-b119-11a0c60f7ac3_1144 dfc694ceff78 registry.aliyuncs.com/google_containers/pause:3.2 "/pause" k8s_POD_nfs-client-provisioner-7676dc9cfc-x5hv7_default_d8036fe1-226f-4304-9bf8-1bb0ba86e500_88 d8315d725f5c registry.aliyuncs.com/google_containers/pause:3.2 "/pause" k8s_POD_kube-flannel-ds-amd64-8gk95_kube-system_192f630a-4278-4c09-88fa-28a4da8930e0_60 5a1f4cd0518f registry.aliyuncs.com/google_containers/pause:3.2 "/pause" k8s_POD_nginx-ingress-controller-7ct4s_ingress-nginx_b3645238-9acd-4046-b2c5-252d90f7c482_20 7c1397d6b085 registry.aliyuncs.com/google_containers/pause:3.2 "/pause" k8s_POD_kube-proxy-97sv9_kube-system_37fa295f-94fb-4783-8ff7-634d0e6e1f7e_60 [root@node1 ~]#
- Pod中容器的类型
- Infrastructure Container基础容器: 维护整个Pod网络空间
- InitContainers初始化容器:先于业务容器开始执
- Containers业务容器 :并行启动
4 镜像拉取策略(imagePullPolicy)
- Always: 默认值,每次创建 Pod 都会重新拉取一次镜像
- IfNotPresent:镜像在宿主机上不存在时才拉取
- Never: Pod 永远不会主动拉取这个镜像
apiVersion: v1 kind: Pod metadata: name: my-pod spec: containers: - name: java image: java-demo imagePullPolicy: IfNotPresent #imagePullPolicy的位置与image平级 apiVersion: v1 kind: Pod metadata: name: foo namespace: awesomeapps spec: containers: - name: foo image: janedoe/awesomeapp:v1 imagePullSecrets: #当拉取的镜像是私有创建的镜像时,需要配置拉镜像时的凭证 - name: myregistrykey
5 资源限制
Pod资源配额有两种:
- requests 申请配额:容器请求资源时,k8s会根据这个请求,把pod启动在可以满足这个资源要求的node上,如果无法满足那么pod不会被创建。
spec.containers[ ].resources.requests.cpu
spec.containers[ ].resources.requests.memory
- limits 限制配额:允许这个Pod使用的最大资源,防止单个pod过度消耗node上的资源
spec.containers[ ].resources.limits.cpu
spec.containers[ ].resources.limits.memory
使用案例:
apiVersion: v1 kind: Pod metadata: name: web spec: containers: - name: java image: java-demo resources: requests: #该pod期望得到的资源,k8s会尽力把它调度到能满足这个需求的node节点上 memory: "500M" cpu: "900m" limits: #该pod对资源的使用不能大于这个值,limits通常大于requests约20% memory: "512M" #其中cpu值比较抽象,可以这么理解: cpu: "1000m" #1核=1000m;1.5核=1500m
6 重启策略(restartPolicy)
pod使用的资源如何超出limits会被k8s kill掉,所以需要有重启策略
- Always: 默认策略,当容器终止退出后,总是重启容器,用于守护进程 nginx,mysql
- OnFailure:当容器异常退出(退出状态码非0)时,才重启容器。
- Never: 当容器终止退出,从不重启容器。用于批处理任务
使用案例: 注意 restartPolicy策略要与containers平级
apiVersion: v1 kind: Pod metadata: name: my-pod spec: containers: - name: java image: java-demo restartPolicy: Always
7 健康检查 (Probe)
健康检查+重启策略 可以实现应用程序的修复。
执行kubectl get pods查看pod的状态时,kubelet根据容器状态作为健康依据,但不能检查容器中应用程序状态,例如程序假死。这就会导致程序假死时无法提供服务,丢失流量。因此引入健康检查机制确保容器健康存活。
Probe健康检查有两种类型:
- livenessProbe (存活检查):如果检查失败,将会杀死容器,然后根据pod的restartPolicy策略来实现重启。
- redinessProbe(就绪检查):如果检查失败,Kubernetes会把Pod从service endpoints中剔除
每种类型都支持以下三种健康检查方法:
- httpGet 发送HTTP请求,返回200-400范围状态码为在功
- exec 执行shell命令,返回状态码是0为成功
- tcpSocket 发起tcpSocket建立成功
livenessProber的exec案例演示:
启动一个busybox容器,创建一个/tmp/healthy文件 ,休眠30,再删除这个文件,再休眠600s apiVersion: v1 kind: Pod metadata: labels: test: liveness name: liveness-exec spec: containers: - name: liveness image: k8s.gcr.io/busybox args: - /bin/sh - -c - touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600 livenessProbe: #livenessProbe与resources平级 exec: command: - cat - /tmp/healthy #通过检查/tmp/healthy是否存在,来判断是否重启Pod initialDelaySeconds: 10 #容器启动之后多少秒执行健康检查 periodSeconds: 5 #每次健康检查的周期 [root@master Pod]# kubectl apply -f livenessProbe.yaml pod/liveness-exec created NAME READY STATUS RESTARTS AGE liveness-exec 1/1 Running 1 2m6s [root@master Pod]# [root@master Pod]# kubectl describe pod liveness-exec Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 2m40s default-scheduler Successfully assigned default/liveness-exec to node2 Normal Pulling 65s (x2 over 2m40s) kubelet, node2 Pulling image "busybox" Normal Pulled 64s (x2 over 2m18s) kubelet, node2 Successfully pulled image "busybox" Normal Created 64s (x2 over 2m18s) kubelet, node2 Created container liveness Normal Started 64s (x2 over 2m18s) kubelet, node2 Started container liveness #健康检查已开始执行 Warning Unhealthy 20s (x6 over 105s) kubelet, node2 Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory Normal Killing 20s (x2 over 95s) kubelet, node2 Container liveness failed liveness probe, will be restarted [root@master Pod]#
livenessProber的HttpGet案例演示:
nginx中的页面文件在/usr/share/nginx/html/index.html, 对容器web2的网页文件进行检查 spec: containers: - name: web image: lizhenliang/java-demo ports: - containerPort: 80 - name: web2 image: nginx livenessProbe: httpGet: path: /index.html port: 80 initialDelaySeconds: 10 periodSeconds: 5
redinessProber的HttpGet案例演示
配置方法和livenessProbe一样, 如果redinessProber的健康检查被触发,它会移除kubectl get ep中发生故障pod的IP。
通常livenessProber和redinessProber策略可以同时配置。
spec: containers: - name: web image: lizhenliang/java-demo ports: - containerPort: 80 - name: web2 image: nginx readinessProbe: httpGet: path: /index.html port: 80 initialDelaySeconds: 10 periodSeconds: 5
8 调度策略
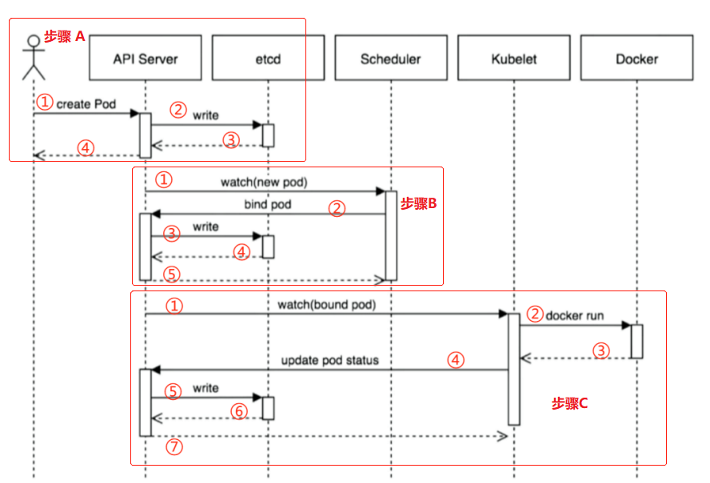
一创建一个pod的工作流程:
步骤A
1 user通过kubectl指令创建一个pod,它把指令发送给了API Server
2 API Server收到这个事件后,它会把它写入etcd数据库
3 etcd写入成功后,响应给API Server
4 API Server从ectd中拿到事件,响应给kubectl
A步骤仅仅是指令执行成功,后台还没有创建pod
步骤B : scheduler负责调度pod
1 scheduler从API中 watch list. 获取到有新的pod,根据自己的调度算法选择一个合适的节点
2 scheduler对该pod打一个标签,记录它被分配到了哪个node,然后把这个信息返回给API
3 API Server把信息写入到etcd,
4 ectd把响应信息反馈给API Server
5 API Server把反馈信息返回给scheduler
B步骤完在对该pod应该分配到哪个node的调度任务
步骤C:
1 对应node节点的kubectl会收到分配到自己节点pod的信息
2 kubectl 调用docker的API(/var/run/docker.sock)并创建容器
3 docker把创建信息反馈给kubecctl
4 kubectl把创建容器的状态响应给API Server
5 API Server把信息写入到etcd
6 etcd把写入信息响应给API Server
7 API Server把信息反馈给kubectl
User再次通过kubectl get pod时,就可以看到pod的信息了
二 在调度过程中有哪些属性会影响调度的结果
影响Pod最终放在哪个节点上的因素有哪些:
1 控制器中的资源调度依据:resources
ks8s会根据resources中request的值找有足够资源的node来存放pod
2 调度策略:
schedulerName: default-scheduler
nodeName: " "
nodeSelector: { } 根据node的label来筛选
affinity: { }
tolerations: [ ]

- 资源限制对Pod调度的影响

-
调度策略对Pod的影响
nodeSelector的使用案例:
[root@master ~]# kubectl get node NAME STATUS ROLES AGE VERSION master Ready master 6d16h v1.18.0 node1 Ready <none> 6d14h v1.18.0 node2 Ready <none> 6d14h v1.18.0 [root@master ~]# [root@master ~]# kubectl label nodes node1 disktype=ssd #在Node1节点上添加一个标签:disktype=ssd node/node1 labeled [root@master ~]# kubectl get node --show-labels #查看node1上的标签 NAME STATUS ROLES AGE VERSION LABELS node1 Ready <none> 6d14h v1.18.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=ssd,kubernetes.io/arch=amd64, kubernetes.io/hostname=node1,kubernetes.io/os=linux [root@master ~]# #创建一个deploy,使用nodeSelector匹配ssd的node [root@master ~]# vim deploy-nodeSelector.yaml 1 apiVersion: apps/v1 2 kind: Deployment 3 metadata: 4 name: nodeselecto 5 spec: 6 replicas: 1 7 selector: 8 matchLabels: 9 project: blog 10 app: java-demo 11 template: 12 metadata: 13 labels: 14 project: blog 15 app: java-demo 16 spec: 17 nodeSelector: 18 disktype: "ssd" 19 containers: 20 - name: web 21 image: java-demo 22 ports: 23 - containerPort: 80 [root@master ~]# kubectl apply -f deploy-nodeSelector.yaml deployment.apps/nodeselecto created #确认新的Pod是否落在了node1上 [root@master ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE nodeselecto-6f587b749-q45qr 1/1 Running 0 32s 10.244.1.37 node1 [root@master ~]#
nodeAffinity的使用案例:
它的功能和nodeSelector类似,可以根据节点上的标签来约束Pod可以调度到哪些节点,。nodeSelector是精确匹配,如果没有node满足它的要求,pod一直处于Pending, 无法被创建。而nodeSelector有更多的逻辑组合,可以实现更录活的匹配。它能实现必须满足,也可以实现尝试满足。
硬(required): 必须满足
软(preferred):尝试满足,但不保证
操作符:In、NotIn、Exists、DoesNotExist、Gt、Lt
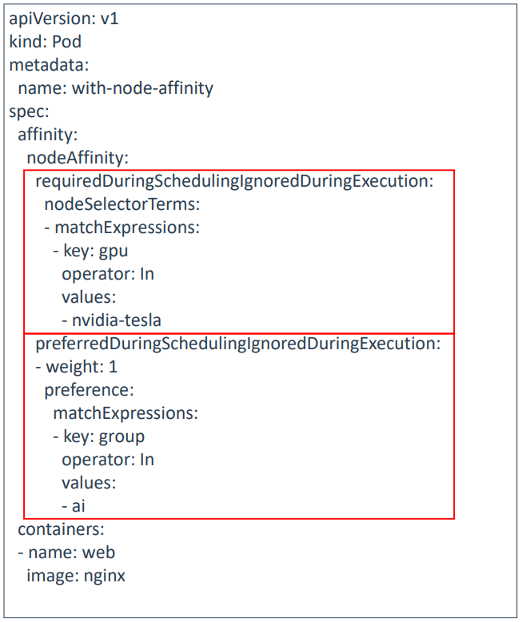
案例分析1:
硬性要求node节点必须满足 gpu=nvidia-tesla这个标签时,才可以创建pod
1) 在node2节点上打gpu的标签
[root@master ~]# kubectl label nodes node2 gpu=nvidia-tesla node/node2 labeled [root@master ~]# kubectl get node --show-labels | grep gpu node2 Ready <none> 296d v1.18.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,gpu=nvidia-tesla,kubernetes.io/arch=amd64,kubernetes.io/hostname=node2,kubernetes.io/os=linux [root@master ~]#
2) 用yaml创建一个Pod
[root@master Pod]# cat pod-nodeaffinity.yaml apiVersion: v1 kind: Pod metadata: name: with-node-affinity spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: gpu operator: In values: - nvidia-tesla containers: - name: web image: nginx [root@master Pod]# [root@master Pod]# kubectl apply -f pod-nodeaffinity.yaml pod/with-node-affinity created [root@master Pod]#
3) 确认Pod是否创建成功,且落在了node2上
[root@master Pod]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES with-node-affinity 1/1 Running 0 43s 10.244.2.122 node2 <none> <none> [root@master Pod]# [root@master Pod]# kubectl delete -f pod-nodeaffinity.yaml pod "with-node-affinity" deleted [root@master Pod]#
4 )删除node2上的标签,再次创建这个Pod
[root@master Pod]# kubectl label nodes node2 gpu- node/node2 labeled [root@master Pod]# kubectl get node --show-labels | grep gpu [root@master Pod]# [root@master Pod]# kubectl apply -f pod-nodeaffinity.yaml pod/with-node-affinity created
5) 因为硬性要求无法满足,这个Pod无法创建成功
[root@master Pod]# [root@master Pod]# kubectl get pod NAME READY STATUS RESTARTS AGE with-node-affinity 0/1 Pending 0 8s [root@master Pod]# kubectl describe pod with-node-affinity Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector. Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector. [root@master Pod]#
案例分析2:
软性要求,尝试node节点满足 gpu=nvidia-tesla这个标签,如果无法满足也会把pod创建成功
[root@master Pod]# cat pod-nodeaffinity2.yaml apiVersion: v1 kind: Pod metadata: name: with-node-affinity spec: affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - key: gpu operator: In values: - nvidia-tesla containers: - name: web image: nginx [root@master Pod]# Node2上没有gpu的标签,最终pod也可以创建成功 [root@master Pod]# kubectl apply -f pod-nodeaffinity2.yaml pod/with-node-affinity created [root@master Pod]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES with-node-affinity 1/1 Running 0 24s 10.244.2.123 node2 <none> <none> [root@master Pod]#
Taint(污点) 对Pod调度的影响
Taints:避免Pod调度到特定Node上
Tolerations:允许Pod调度到持有Taints的Node上
应用场景:
• 专用节点:根据业务线将Node分组管理,希望在默认情况下不调度该节点,只有配置了污点容忍才允许分配
• 配备特殊硬件:部分Node配有SSD硬盘、GPU,希望在默认情况下不调度该节点,只有配置了污点容忍才允许分配
• 基于Taint的驱逐
配置方法
第一步:给节点添加污点 格式:
kubectl taint node [node] key=value:[effect]
例如:kubectl taint node k8s-node1 gpu=yes:NoSchedule
验证:kubectl describe node k8s-node1 |grep Taint
其中[effect] 可取值:
• NoSchedule :当node节点的effect=NoSchedule,没有配置污点容忍的pod一定不会被分配到这个node上
• PreferNoSchedule:尽量不要调度,没有污点容忍的pod还有可能会被分配到这个节点。
• NoExecute:不仅不会调度,还会驱逐Node上已有的Pod
第二步:添加污点容忍(tolrations)字段到Pod配置中
去掉污点:
kubectl taint node [node] key:[effect]-
案例演示
1 在node1上打污点gpu,值为yes; 在node2上打污点gpu,值为no,并查看污点.
[root@master ~]# kubectl taint node node1 gpu=yes:NoSchedule node/node1 tainted [root@master ~]# [root@master ~]# kubectl taint node node2 gpu=no:NoSchedule node/node2 tainted [root@master ~]# [root@master ~]# kubectl describe node | grep -i taint Taints: node-role.kubernetes.io/master:NoSchedule Taints: gpu=yes:NoSchedule Taints: gpu=no:NoSchedule [root@master ~]#
2 使用deploy启动一个pod,因为没有为pod配置污点容忍,所以无法pod无法创建成功。
[root@master Pod]# kubectl create deployment web666 --image=nginx deployment.apps/web666 created [root@master Pod]# kubectl get pods NAME READY STATUS RESTARTS AGE web666-79d4bf78c9-5s9wt 0/1 Pending 0 6s [root@master Pod]# [root@master Pod]# kubectl describe pod web666-79d4bf78c9-5s9wt Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 52s (x2 over 52s) default-scheduler 0/3 nodes are available: 1 node(s) had taint {gpu: no}, that the pod didn't tolerate, 1 node(s) had taint {gpu: yes}, that the pod didn't tolerate, 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate. [root@master Pod]#
3 用yaml方式创建一个pod, 并为pod配置污点容忍,并让pod落在node2上。
[root@master Pod]# cat tolerations.yaml apiVersion: apps/v1 kind: Deployment metadata: name: web spec: replicas: 1 selector: matchLabels: app: web template: metadata: labels: app: web spec: #污点容忍tolerations与containers同级 tolerations: #配置它的key为 gpu=no, - key: "gpu" #操作符为等于 operator: "Equal" #effect: "NoSchedule" value: "no" effect: "NoSchedule" containers: - image: lizhenliang/java-demo name: java-demo [root@master Pod]# [root@master Pod]# kubectl apply -f tolerations.yaml deployment.apps/web created [root@master Pod]# [root@master Pod]# kubectl get pods NAME READY STATUS RESTARTS AGE web-69c49b7845-vtkx5 1/1 Running 0 29s [root@master Pod]# [root@master Pod]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES web-69c49b7845-vtkx5 1/1 Running 0 43s 10.244.2.131 node2 <none> <none> [root@master Pod]#
nodeName 调度策略
用于将Pod调度到指定的Node上,不经过调度器
[root@master Pod]# cat nodename.yaml apiVersion: apps/v1 kind: Deployment metadata: name: web spec: replicas: 1 selector: matchLabels: app: web template: metadata: labels: app: web spec: nodeName: "node2" containers: - image: lizhenliang/java-demo name: java-demo [root@master Pod]# [root@master Pod]# kubectl apply -f nodename.yaml deployment.apps/web configured [root@master Pod]# [root@master Pod]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES web-859db5f7df-6k5ll 1/1 Running 0 83s 10.244.2.138 node2 <none> <none> [root@master Pod]# 此时node1,node2上仍是有污点的, 因为使用了Nodename的策略所以,控制器上配置的所有策略都会被跳过,所以最终pod最终可以落在node2上
删除污点
[root@master Pod]# kubectl taint node node1 gpu- node/node1 untainted [root@master Pod]# kubectl taint node node2 gpu- node/node2 untainted [root@master Pod]# [root@master Pod]# kubectl describe node | grep -i taint Taints: node-role.kubernetes.io/master:NoSchedule Taints: <none> Taints: <none> [root@master Pod]#
9 故障的排查方法:
Pod故障的排差方法:
kubectl describe TYPE/NAME
查看创建,启动容器时的问题
kubectl logs TYPE/NAME [-c CONTAINER]
查看容器的日志,观察有没有日志异常的日志
kubectl exec POD [-c CONTAINER] -- COMMAND [args...]
pod已启动成功,进入调度容器内的应用
一个pod中运行两个容器模板
[root@master pod]# vim deployment.yaml 1 apiVersion: apps/v1 2 kind: Deployment 3 metadata: 4 name: java-demo2 5 spec: 6 replicas: 1 7 selector: 8 matchLabels: 9 project: blog 10 app: java-demo 11 template: 12 metadata: 13 labels: 14 project: blog 15 app: java-demo 16 spec: 17 containers: 18 - name: web 19 image: lizhenliang/java-demo 20 ports: 21 - containerPort: 80 22 - name: web2 23 image: nginx [root@master pod]# [root@master pod]# kubectl apply -f deployment.yaml deployment.apps/java-demo2 configured [root@master pod]# kubectl get pod NAME READY STATUS RESTARTS AGE java-demo2-c579f88db-kf6fw 2/2 Running 0 63s [root@master pod]#
Init Container
用于初始化工作,执行完后就结束,可以理解为一次性任务。支持大部分应用容器配置,但不支持健康检查;优先于应用容器执行。
应用场景:
环境检查:例如确保应用容器依赖的服务启动后再启动应用容器
初始化配置:例如给应用容器准备配置文件
案例:部署一个web网站,网站的首页因为变动较为频繁,所以没有放到应用镜像中。希望可以从代码仓库中动态摘取放到应用容器中。
apiVersion: v1 kind: Pod metadata: name: init-demo spec: initContainers: #initContainer执行了一个wget动作,去www.ctnrs.com下首页并保存到了/opt/目录下 - name: download image: busybox command: - wget - "-O" - "/opt/index.html" - http://www.ctnrs.com volumeMounts: #在initContainer中挂载一个emptyDir类型的卷,这个卷挂载在/opt中 - name: wwwroot mountPath: "/opt" containers: - name: nginx image: nginx ports: - containerPort: 80 volumeMounts: #应用容器中也挂载这个卷从而实现与initConter中的卷实现共享 - name: wwwroot mountPath: /usr/share/nginx/html volumes: - name: wwwroot emptyDir: {}
示例
apiVersion: v1 kind: Pod metadata: name: my-pod spec: containers: - name: busybox image: busybox # command: ['sh', '-c', 'echo "Hello, Kubernetes!" && sleep 3600'] args: - /bin/sh - -c - sleep 3600 volumeMounts: - name: data mountPath: /data volumes: - name: data hostPath: path: /tmp type: Directory

 浙公网安备 33010602011771号
浙公网安备 33010602011771号