

Linux内核设计第四周——扒开系统调用三层皮
一、知识点整理
1.用户态 内核态和中断处理程序
我们一般使用系统调用一般通过库函数的方式
- 用户态和内核态的区分:
【CPU有不同的执行级别,高执行级别下,代码可以执行特权指令,访问任何的物理地址;低执行级别下,就会受到一定的限制。(处于系统安全和稳定的目的)Intel X86 CPU有四种不同的执行级别0-3;linux只使用了其中的0级和3级分别来表示内核态和用户态。】
显著地区分:cs寄存器的最低两位表明了当前代码的特权级
在linux中,地址空间是一个显著地标志:
0xc0000000以上的地址空间只能在内核态下访问,
0xc00000000——0xbfffffff的地址空间两种状态下都可以访问。
- 中断发生过程:
- 中断处理是从用户态进入内核态的主要方式,同时,系统调用只是一种特殊的中断。
- 中断发生后第一件事就是保存现场:
- 中断/int指令会在堆栈上保存一些寄存器的值(用户态栈顶地址、当时的状态字、当时cs:eip的值)
- 中断结束前第一件事就是恢复现场。
save_all:
内核代码,完成中断服务。
2.系统调用概述和系统调用的三层皮:
系统调用(意义):用用户态进程和硬件设备进行交互提供了一组接口。
——把用户从底层的硬件编程中解放出来
API和系统调用的区别:
- API只是一个系统调用;
- 系统调用通过软中断向内核发出一个明确的请求。


系统调用的三层皮:
- xyz
- system_call
- sys_xyz
CPU切换到内核态:
方式:通过执行int $0x80来执行系统调用
(中断向量0x80与system_call绑定起来)
由于内核实现了很多不同的系统调用,进程必须指明那个系统调用,所以会需要一个系统调用号的参数。(使用eax寄存器)
系统调用号将xyz和sys_xyz联系起来
系统调用的参数传递方法:

二、实验过程
1.本次试验我选择我所熟知的write系统调用:
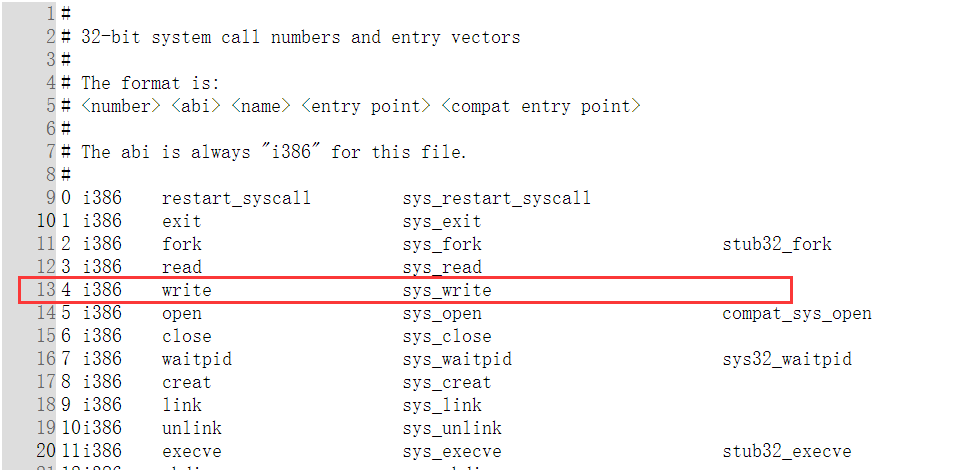
2.通过查看帮助文档我们可以看到关于write的一些信息:
$ man 2 write
参数2代表我们要去看Linux Programmer's Manual
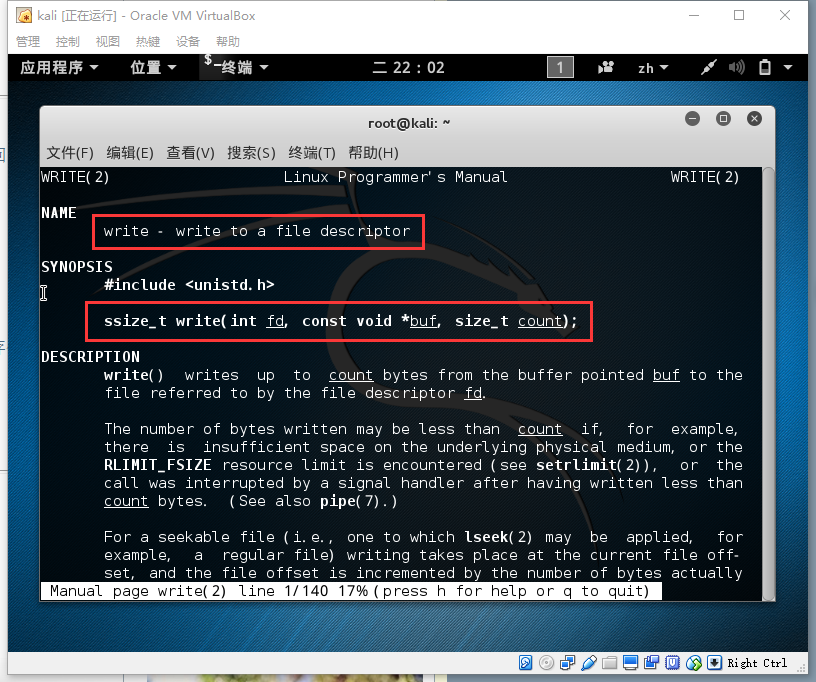
其中有些参数我们需要了解,可以帮助我们进行下面的工作:
- int fd, 这个代表你要往哪里写,Linux系统包含3种专门的文件描述符:
- 0-stdin: 标准输入,一般是键盘
- 1-stdout: 标准输出,一般是终端屏幕,我们一会就用这个。
- 2-stderr: 标准错误输出,一般是终端屏幕。
- buf 是指定要write的字符内容从哪里开始, 说白了就是一个字符串的最开始的内存位置。
- size_t count 是知道要write多少个字符出去。
3.编写C语言代码
// test.c
#include <unistd.h>
int main(){
char string[4] = {'s','z','s','\n'};
write(1,string, 5);
return 0;
}
4.编译c代码

当我进行执行.c文件的编译的时候,不自觉的和视频教学同步加了-m32,发现我的kali系统里没有相应的头文件,于是进行相关软件包的安装,后来发现不需要-m32,直接编译成64位的代码没有问题。
5.编译成功
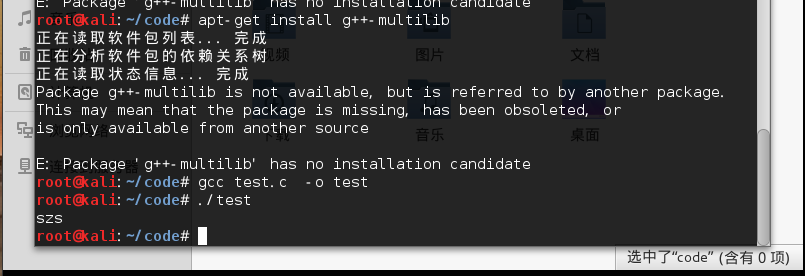
图中的szs即是我在之前代码中定义的字符串,用一号功能打印在屏幕上。
6.编写汇编代码
首先通过查阅资料了解到了一些汇编的知识:
我们用GNU的一组汇编工具就很方便,需要用到的编译连接程序(或者说命令)是as 和 ld。 其实,gcc命令其实就是把c文件编译成一个汇编文件后,再用as 和ld来生成最终程序或者库文件的。
我们都知道用汇编的话就得一个一个寄存器单独来使用了,那怎样进行系统调用呢?方法是严格按照这个顺序将参数传递给寄存器:
* EAX :存放系统调用号,决定进行什么系统调用
* EBX: 存放系统调用第一个参数
* ECX: 存放第二个参数,后面以此类推
* EDX: 第三个
* ESI: 第四个
* EDI:第五个
同时,结合在课程中学习的内容(以time函数为例):
使用库函数API获取系统当前时间
使用C代码嵌入汇编代码触发系统调用获取当前时间
系统调用传递的第一个参数使用ebx,这里是null。
使用eax传递系统调用号,使用的time调用号是13。
函数返回值也使用eax存储,和普通函数一样。
所以对应我们要用的wirte系统调用,要把值传递给相应的寄存器当中:
write(int fd, const void *buf, size_t count);
| | |
----------EBX-------------------ECX-------EDX
这样,我们就可以确定各个寄存器的作用以及传递的都是一些什么参数。
直接用了汇编代码,比C语言复杂不到那里去:
# teat1.s 这一行是注释
.section .data
output: #这是个标签,用来告诉编译器以后我用到“output”就是指这个内存地点
.ascii "i am suzhengsheng,20135333.\n" #这里开辟了一段ascii字符空间,有24个字符
output_end: #另一个标签
.equ len, output_end - output #相当于宏定义,意思是让len 这个变量 等于output_end - output的值
section .text
.globl _start
_start:
movl $4, %eax #依次由前文所述给各个寄存器赋值
movl $1, %ebx
movl $output, %ecx
movl $len, %edx
int $0x80 #进行一次系统调用
end:
movl $1, %eax #这里赋值以后又进行了一次系统调用,1这个系统调用是干什么的呢?
movl $0, %ebx #不知道的话可以去看/usr/include/asm/unistd_32.h求解哦,呵呵
int $0x80
7.编译汇编代码

三、实验总结
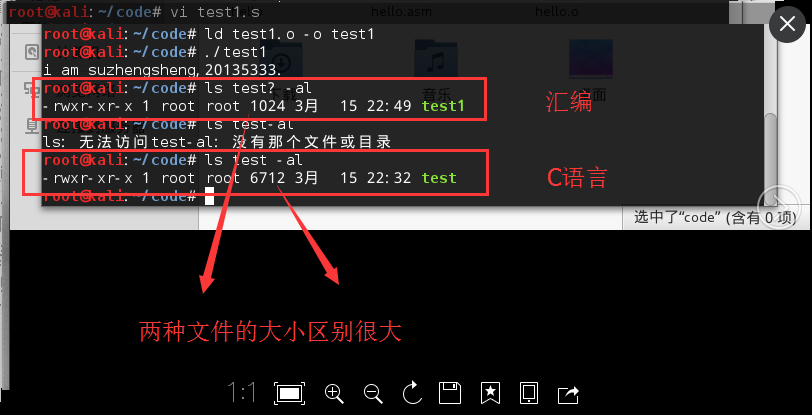
本次实验我通过调用4号调用write来进行了模拟系统调用的过程。对于以往繁杂的系统调用忽然有了亲切和清晰地理解。在上面已经把每一部分在做什么,怎么做都写了,就不再这里繁复的阐述了。
最后比较了一下两个代码,虽然完成的是同样的系统调用,但是通过比较可以看出汇编代码在体积方面有很大的优势:
四、遇到的问题
实验中遇到了自己的虚拟机安装的kali系统编译32位程序不成功的情况,目测是32位的搜索路径下没有sys/cdefs.h
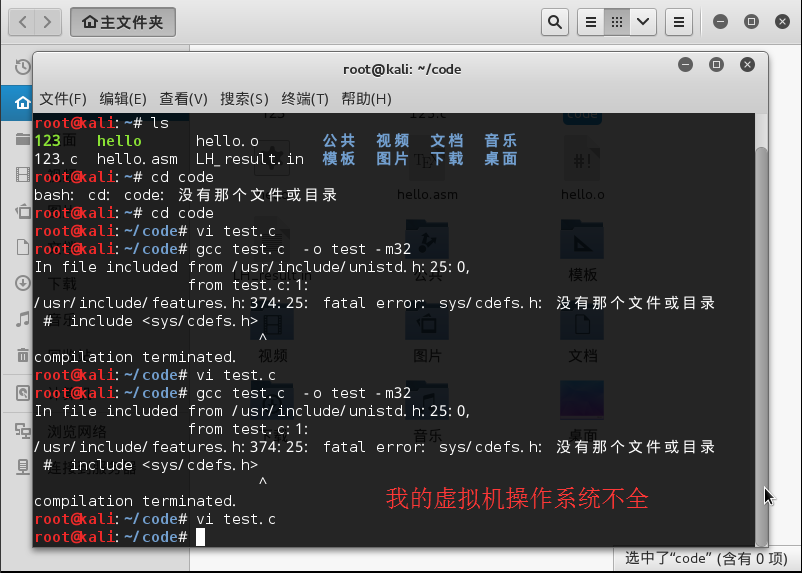
但是我想说的是,64位的机器已经是一个趋势了,代表了更快的速度和更高的效率,代码等都应该向着64位逐步优化。
网上有人这么说:
“一般64位系统最好不要安装32位库的-dev,经常有冲突,强行安装会破坏64位环境,头文件并不像共享库分得那么完美。
我觉得比较好的做法是,重新把某一个文件夹当成rootfs,在里面安装各种32位的库和库-dev,然后给gcc传递参数"--sysroot=路径"就可以让gcc重新选取那个文件夹为rootfs,而不再认为/为rootfs。其实这样就变成交叉编译了。也可以在这个rootfs中安装32位的必要软件包如bash,gcc,coreutils等等,然后chroot进去就变成host编译了。其实有个比较简单的方法,就是虚拟机下安一个32位的ubuntu,然后装好各种软件包,然后直接对/打包,再拿出来解压就是rootfs了,后面最多就是缺啥安啥,工作量比较小”
虽有偏颇,但还是有参考意义,在这里分享给大家。
参考资料
- 使用库函数API和C代码中嵌入汇编代码两种方式使用同一个系统调用 - 实验楼 https://www.shiyanlou.com/courses/running/731
- Linux内核分析 - 网易云课堂 http://mooc.study.163.com/learn/USTC-1000029000?tid=2001214000#/learn/content
- 64位UBUNTU 下 如何用GCC 编译出32位程序 http://zhidao.baidu.com/link?url=lh44LyEa81a7jC2DFTLIFrr9SZgxf2ramTLcyRDZDj9vaEzPckF0U1Oz2VVQJFbPZJ_9IscNBXTuEHZ0PWZ9MrxG7QaEjs1N9lXtrhyAANO
- 简单的Linux系统调用(C与汇编) http://blog.163.com/liufu_ty/blog/static/36725362009102605824425/
- Cross Reference: /linux-3.18.6/arch/x86/syscalls/syscall_32.tbl http://codelab.shiyanlou.com/xref/linux-3.18.6/arch/x86/syscalls/syscall_32.tbl

