D28 prometheus 自定义监控服务的qps
需求拆解
- 1.我们在kubernetes集群中部署了n多个go服务
- 2.我们已经有了一套在kubernetes集群之外部署的Prometheus
- 3.现在我们需要监控所有服务去qps
- 4.监控起来之后需要在grafana上通过不通的研发部门{北京 上海两个研发部门}进行展示
- 5.现在想通过要将qps超过10的 发送到不同的研发钉钉群
- 6.现在想要做下告警升级qps超过100以后发送给运维小伙伴
1. 我们在kubernetes集群中部署了n多个go服务
1.1 go服务代码
suyajun@MacBook-Pro-2 abc % cat main.go
package main
import (
"flag"
"github.com/gin-gonic/gin"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
"log"
"net/http"
"os"
)
var version = flag.String("v", "v1", "Version of the service")
// 创建一个 HTTP 请求计数器
var httpRequestsTotal = prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "http_requests_total",
Help: "Total number of HTTP requests processed",
},
[]string{"method", "version"}, // 用 method 和 version 作为标签来区分请求
)
func init() {
// 解析命令行参数
flag.Parse()
// 注册计数器到 Prometheus
prometheus.MustRegister(httpRequestsTotal)
}
func main() {
// 初始化 Gin 路由
router := gin.Default()
// 处理 /metrics 路径,暴露 Prometheus 指标
router.GET("/metrics", gin.WrapH(promhttp.Handler()))
// 处理根路径
router.GET("/", func(c *gin.Context) {
// 获取主机名
hostname, err := os.Hostname()
if err != nil {
hostname = "unknown" // 如果获取主机名失败,返回 "unknown"
log.Printf("Error getting hostname: %v", err)
}
// 记录请求计数
httpRequestsTotal.WithLabelValues(c.Request.Method, *version).Inc()
// 返回响应
c.String(http.StatusOK, "This is version:%s running in pod %s", *version, hostname)
})
// 启动 Gin 服务
router.Run(":8080")
}
1.2 go服务的dockfile
suyajun@MacBook-Pro-2 abc % cat Dockerfile
###################1.构建阶段###################
# 使用 Golang 1.23.4 镜像作为构建环境
FROM uhub.service.ucloud.cn/librarys/golang:1.23.4 AS build
# 构建阶段的工作目录
WORKDIR /go/src/test/
# 将当前目录下的所有文件复制到 Docker 容器的 /go/src/test/ 目录中
COPY . /go/src/test/
# 设置 Go 的代理,使用国内的 goproxy.cn 以提高下载速度
RUN go env -w GOPROXY=https://goproxy.cn,direct
# 使用 GOARCH=amd64 和 GOOS=linux 标志编译 Go 应用为 Linux 下的可执行文件。
# CGO_ENABLED=0 禁用 CGO(C 语言调用 Go 语言),确保静态链接。
# go build -v -o main . 会在工作目录中生成名为 main 的二进制文件。
RUN CGO_ENABLE=0 GOARCH=amd64 GOOS=linux go build -v -o main .
###################2.运行阶段###################
# 使用 Ubuntu 最新版本的镜像作为运行时环境
FROM uhub.service.ucloud.cn/librarys/ubuntu:latest AS api
# 在容器内创建一个 /app 目录,用于存放构建好的应用
RUN mkdir /app
# 将从构建阶段复制过来的 main 文件复制到容器内的 /app 目录
COPY --from=build /go/src/test/main /app
# 设置容器的工作目录为 /app,之后所有命令将在该目录下执行
WORKDIR /app
# 定义容器启动时的默认执行命令:执行 main 程序并传入参数 "-v" 和 "1.0"
ENTRYPOINT ["./main", "-v", "1.1"]
- 打包并推送到镜像仓库
docker build -t uhub.service.ucloud.cn/librarys/abc:v1.1 .
docker push uhub.service.ucloud.cn/librarys/abc:v1.1
1.3 go服务的资源清单文件
[root@k8s-master pods]# ll
总用量 32
-rw-r--r--. 1 root root 290 12月 9 11:50 abc-pod-v1.0.yaml
-rw-r--r--. 1 root root 290 12月 9 11:50 abc-pod-v1.1.yaml
-rw-r--r--. 1 root root 290 12月 9 11:50 abc-pod-v1.2.yaml
-rw-r--r--. 1 root root 290 12月 9 11:49 abc-pod-v1.3.yaml
-rw-r--r--. 1 root root 290 12月 9 11:49 abc-pod-v1.4.yaml
-rw-r--r--. 1 root root 290 12月 9 11:49 abc-pod-v1.5.yaml
-rw-r--r--. 1 root root 290 12月 9 11:47 abc-pod-v1.6.yaml
-rw-r--r--. 1 root root 205 12月 10 10:47 abc-service.yaml
[root@k8s-master pods]# cat abc-service.yaml
apiVersion: v1
kind: Service
metadata:
name: abc
spec:
selector:
app: abc
version: v1.1
ports:
- name: http
port: 8080
targetPort: 8080
nodePort: 31080
type: NodePort
[root@k8s-master pods]# cat abc-pod-v1.0.yaml
apiVersion: v1
kind: Pod
metadata:
name: abc-v1-0
labels:
app: abcv0
ports: '8080'
version: v1.1
annotations:
prometheus.alarm/group: 上海
prometheus.alarm/scrape: 'false'
spec:
containers:
- name: abc
image: uhub.service.ucloud.cn/librarys/abc:v1.1
[root@k8s-master pods]# cat abc-pod-v1.1.yaml
apiVersion: v1
kind: Pod
metadata:
name: abc-v1-1
labels:
app: abcv1
ports: '8080'
version: v1.1
annotations:
prometheus.alarm/group: 上海
prometheus.alarm/scrape: 'false'
spec:
containers:
- name: abc
image: uhub.service.ucloud.cn/librarys/abc:v1.1
[root@k8s-master pods]# cat abc-pod-v1.2.yaml
apiVersion: v1
kind: Pod
metadata:
name: abc-v1-2
labels:
app: abcv2
ports: '8080'
version: v1.1
annotations:
prometheus.alarm/group: 上海
prometheus.alarm/scrape: 'false'
spec:
containers:
- name: abc
image: uhub.service.ucloud.cn/librarys/abc:v1.1
[root@k8s-master pods]# cat abc-pod-v1.3.yaml
apiVersion: v1
kind: Pod
metadata:
name: abc-v1-3
labels:
app: abcv3
ports: '8080'
version: v1.1
annotations:
prometheus.alarm/group: 北京
prometheus.alarm/scrape: 'false'
spec:
containers:
- name: abc
image: uhub.service.ucloud.cn/librarys/abc:v1.1
[root@k8s-master pods]# cat abc-pod-v1.4.yaml
apiVersion: v1
kind: Pod
metadata:
name: abc-v1-4
labels:
app: abcv4
ports: '8080'
version: v1.1
annotations:
prometheus.alarm/group: 北京
prometheus.alarm/scrape: 'false'
spec:
containers:
- name: abc
image: uhub.service.ucloud.cn/librarys/abc:v1.1
[root@k8s-master pods]# cat abc-pod-v1.5.yaml
apiVersion: v1
kind: Pod
metadata:
name: abc-v1-5
labels:
app: abcv5
ports: '8080'
version: v1.1
annotations:
prometheus.alarm/group: 北京
prometheus.alarm/scrape: 'false'
spec:
containers:
- name: abc
image: uhub.service.ucloud.cn/librarys/abc:v1.1
[root@k8s-master pods]# cat abc-pod-v1.6.yaml
apiVersion: v1
kind: Pod
metadata:
name: abc-v1-6
labels:
app: abcv6
ports: '8080'
version: v1.6
annotations:
prometheus.alarm/group: 北京
prometheus.alarm/scrape: 'false'
spec:
containers:
- name: abc
image: uhub.service.ucloud.cn/librarys/abc:v1.1
1.4 发版go服务到k8s集群中
[root@k8s-master pods]# kubectl apply -f .
pod/abc-v1-0 created
pod/abc-v1-1 created
pod/abc-v1-2 created
pod/abc-v1-3 created
pod/abc-v1-4 created
pod/abc-v1-5 created
pod/abc-v1-6 created
service/abc created
[root@k8s-master pods]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
abc-v1-0 1/1 Running 2 (72m ago) 23h app=abcv0,ports=8080,version=v1.1
abc-v1-1 1/1 Running 3 (72m ago) 3d18h app=abcv1,ports=8080,version=v1.1
abc-v1-2 1/1 Running 2 (72m ago) 25h app=abcv2,ports=8080,version=v1.1
abc-v1-3 1/1 Running 2 (72m ago) 25h app=abcv3,ports=8080,version=v1.1
abc-v1-4 1/1 Running 2 (72m ago) 25h app=abcv4,ports=8080,version=v1.1
abc-v1-5 1/1 Running 2 (72m ago) 25h app=abcv5,ports=8080,version=v1.1
abc-v1-6 1/1 Running 2 (72m ago) 23h app=abcv6,ports=8080,version=v1.6
# 现在我们通过下面的脚本进行模拟访问go服务提前制造一些qps的数据
cat /data/yace/yace.py
import subprocess
import requests
import time
import threading
# 执行 kubectl 命令并解析结果
def get_services():
# 执行 kubectl 命令,获取 pod 信息
cmd = "kubectl get pod -A -owide | egrep 'abc-' | awk '{print $(NF-3)}' | grep '10.244.85.196'"
# 使用 Python 3.6 兼容的方式来捕获输出
result = subprocess.run(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True)
# 分析 kubectl 输出,假设 pod 名称是服务的地址
services = []
for idx, line in enumerate(result.stdout.strip().split('\n')):
# 根据服务的索引定义 QPS,假设第1个服务QPS为10,依次增加
qps = 100 * (idx + 1)
services.append({"url": f"http://{line}:8080", "qps": qps})
return services
# 模拟请求函数
def send_requests(service):
url = service["url"]
qps = service["qps"]
delay = 1 / qps # 每个请求之间的延迟
while True:
response = requests.get(url)
print(f"Sent request to {url}, status: {response.status_code}")
time.sleep(delay) # 控制每秒的请求数量
# 启动每个服务的请求模拟
def start_services():
services = get_services() # 动态生成服务列表
threads = []
for service in services:
thread = threading.Thread(target=send_requests, args=(service,))
threads.append(thread)
thread.start()
# 等待所有线程结束
for thread in threads:
thread.join()
if __name__ == "__main__":
start_services()
# 执行脚本
python3.6 /data/yace/yace.py
2. 我们已经有了一套在kubernetes集群之外部署的Prometheus
- 安装Prometheus,下载解压prometheus并生成访问kubernetes集群的token
mkdir /data/prometheus/
cd /data/prometheus/
wget -c https://github.com/prometheus/prometheus/releases/download/v2.53.3/prometheus-2.53.3.linux-amd64.tar.gz
tar xf prometheus-2.53.3.linux-amd64.tar.gz
kubectl create token prometheus-secret -n kube-system > /data/prometheus/prometheus-2.53.3.linux-amd64/k8s_token
3. 现在我们需要监控所有服务的qps
- 配置prometheus
这里为了方便把所有的配置都放在一起了,其实可以分开逐步去添加配置内容会便于理解。
如果读者看到有想要交流的 欢迎添加微信 suyajun9 一起讨论
[root@k8s-master prometheus-2.53.3.linux-amd64]# cat prometheus.yml
# my global config
global:
scrape_interval: 5s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 5s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- api_server: 'https://172.16.99.71:6443'
role: pod
bearer_token_file: /data/prometheus/prometheus-2.53.3.linux-amd64/k8s_token
tls_config:
insecure_skip_verify: true
relabel_configs:
# 将 Pod 的 IP 和固定端口组合成 __address__
- source_labels: [__meta_kubernetes_pod_ip, __meta_kubernetes_pod_label_ports]
separator: ":"
regex: "([0-9.]+):([0-9]+)" # 精确匹配 IP 和端口,([0-9.]+):精确匹配 IP 地址(数字和点),([0-9]+):精确匹配端口号(只允许数字)
target_label: __address__
replacement: "$1:$2"
action: replace
# 保留服务名称
- source_labels: [__meta_kubernetes_pod_label_app]
replacement: "$1"
target_label: "service"
action: replace
# 保留业务群组
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_alarm_group]
replacement: "$1"
target_label: "alarm_group"
action: replace
# 可选:仅抓取匹配 app value的值包括abc 的 Pod
- source_labels: [__meta_kubernetes_pod_label_app]
regex: "abc.*"
action: keep
- 启动Prometheus
cd /data/prometheus/prometheus-2.53.3.linux-amd64
nohup ./prometheus --config.file=prometheus.yml --web.enable-lifecycle --log.level=debug &
[root@k8s-master prometheus-2.53.3.linux-amd64]# netstat -lntup|grep prome
tcp6 0 0 :::9090 :::* LISTEN 67052/./prometheus
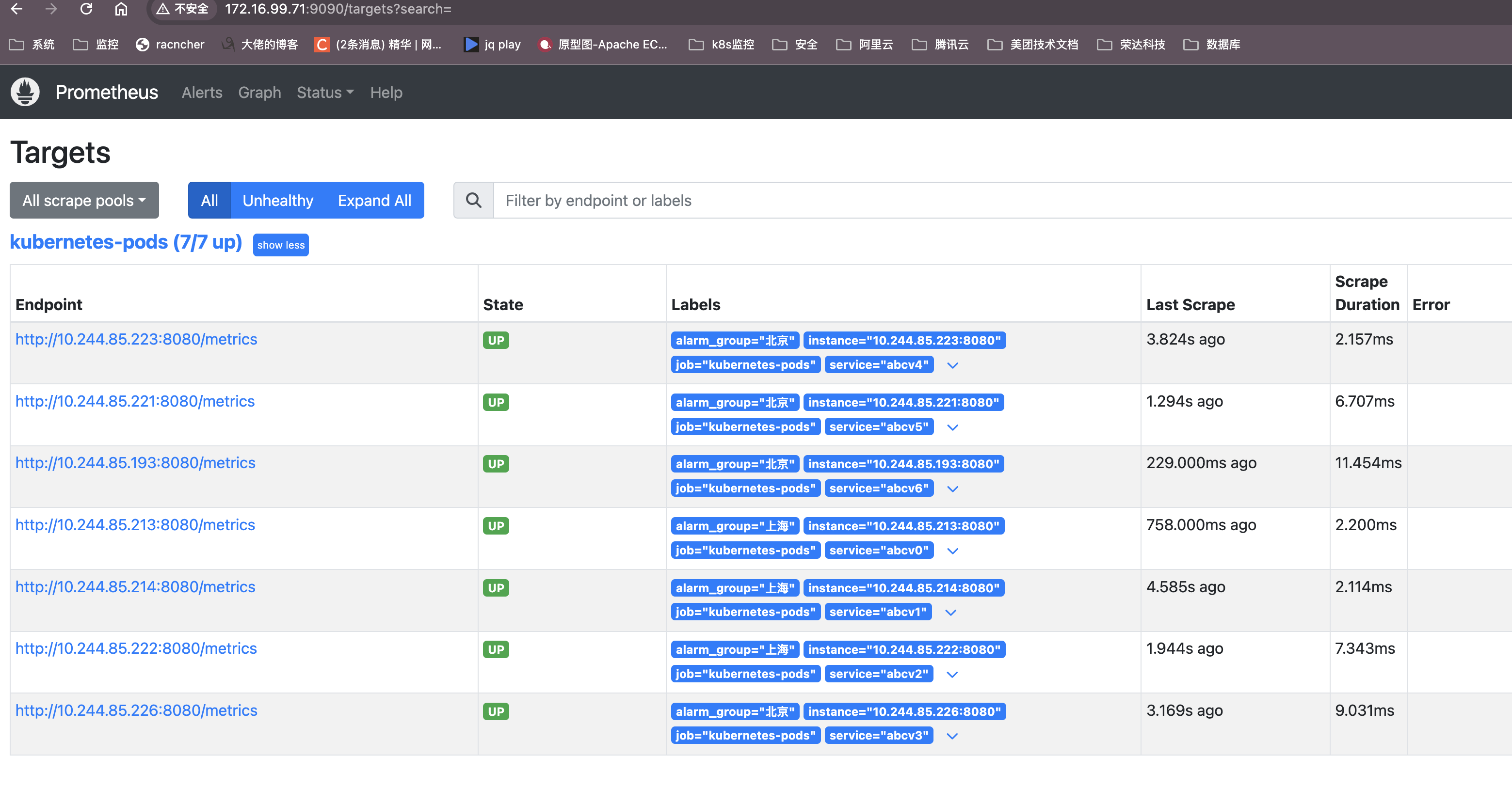
4. 监控起来之后需要在grafana上通过不通的研发部进行展示
- 安装grafana
mkdir /data/grafana/
cd /data/grafana/
wget https://dl.grafana.com/oss/release/grafana-11.3.0+security-01.linux-amd64.tar.gz
cd grafana-v11.3.0+security-01/bin/
nohup ./grafana-server &
netstat -lntup|grep 3000
# 登录grafana
http://172.16.99.71:3000
默认的账户名和密码都是admin,会提示让修改
- 配置grafana数据源为Prometheus,导入下面的dashboard
{
"annotations": {
"list": [
{
"builtIn": 1,
"datasource": {
"type": "grafana",
"uid": "-- Grafana --"
},
"enable": true,
"hide": true,
"iconColor": "rgba(0, 211, 255, 1)",
"name": "Annotations & Alerts",
"type": "dashboard"
}
]
},
"editable": true,
"fiscalYearStartMonth": 0,
"graphTooltip": 0,
"id": 1,
"links": [],
"panels": [
{
"datasource": {
"type": "prometheus",
"uid": "fe6cl2of23lz4c"
},
"fieldConfig": {
"defaults": {
"color": {
"mode": "palette-classic"
},
"custom": {
"axisBorderShow": false,
"axisCenteredZero": false,
"axisColorMode": "text",
"axisLabel": "",
"axisPlacement": "auto",
"barAlignment": 0,
"barWidthFactor": 0.6,
"drawStyle": "line",
"fillOpacity": 0,
"gradientMode": "none",
"hideFrom": {
"legend": false,
"tooltip": false,
"viz": false
},
"insertNulls": false,
"lineInterpolation": "linear",
"lineWidth": 1,
"pointSize": 5,
"scaleDistribution": {
"type": "linear"
},
"showPoints": "auto",
"spanNulls": false,
"stacking": {
"group": "A",
"mode": "none"
},
"thresholdsStyle": {
"mode": "off"
}
},
"mappings": [],
"thresholds": {
"mode": "absolute",
"steps": [
{
"color": "green",
"value": null
},
{
"color": "red",
"value": 80
}
]
}
},
"overrides": []
},
"gridPos": {
"h": 14,
"w": 13,
"x": 0,
"y": 0
},
"id": 3,
"options": {
"legend": {
"calcs": [],
"displayMode": "list",
"placement": "bottom",
"showLegend": true
},
"tooltip": {
"mode": "single",
"sort": "none"
}
},
"pluginVersion": "11.3.0+security-01",
"targets": [
{
"datasource": {
"type": "prometheus",
"uid": "fe6cl2of23lz4c"
},
"disableTextWrap": false,
"editorMode": "code",
"expr": "rate(http_requests_total{alarm_group=~\"$group_name\",service=~\"$service\"}[1m])",
"fullMetaSearch": false,
"includeNullMetadata": true,
"instant": false,
"legendFormat": "__auto",
"range": true,
"refId": "A",
"useBackend": false
}
],
"title": "service qps",
"type": "timeseries"
}
],
"preload": false,
"schemaVersion": 40,
"tags": [],
"templating": {
"list": [
{
"allValue": ".*",
"current": {
"text": "All",
"value": "$__all"
},
"datasource": {
"type": "prometheus",
"uid": "fe6cl2of23lz4c"
},
"definition": "label_values(alarm_group)",
"description": "",
"includeAll": true,
"label": "部门名称",
"name": "group_name",
"options": [],
"query": {
"qryType": 1,
"query": "label_values(alarm_group)",
"refId": "PrometheusVariableQueryEditor-VariableQuery"
},
"refresh": 1,
"regex": "",
"type": "query"
},
{
"allValue": ".*",
"current": {
"text": "All",
"value": "$__all"
},
"datasource": {
"type": "prometheus",
"uid": "fe6cl2of23lz4c"
},
"definition": "label_values(service)",
"description": "",
"includeAll": true,
"label": "服务名称",
"name": "service",
"options": [],
"query": {
"qryType": 1,
"query": "label_values(service)",
"refId": "PrometheusVariableQueryEditor-VariableQuery"
},
"refresh": 1,
"regex": "",
"type": "query"
}
]
},
"time": {
"from": "now-5m",
"to": "now"
},
"timepicker": {},
"timezone": "browser",
"title": "qps dashboard",
"uid": "be6clek9y0hs0e",
"version": 29,
"weekStart": ""
}
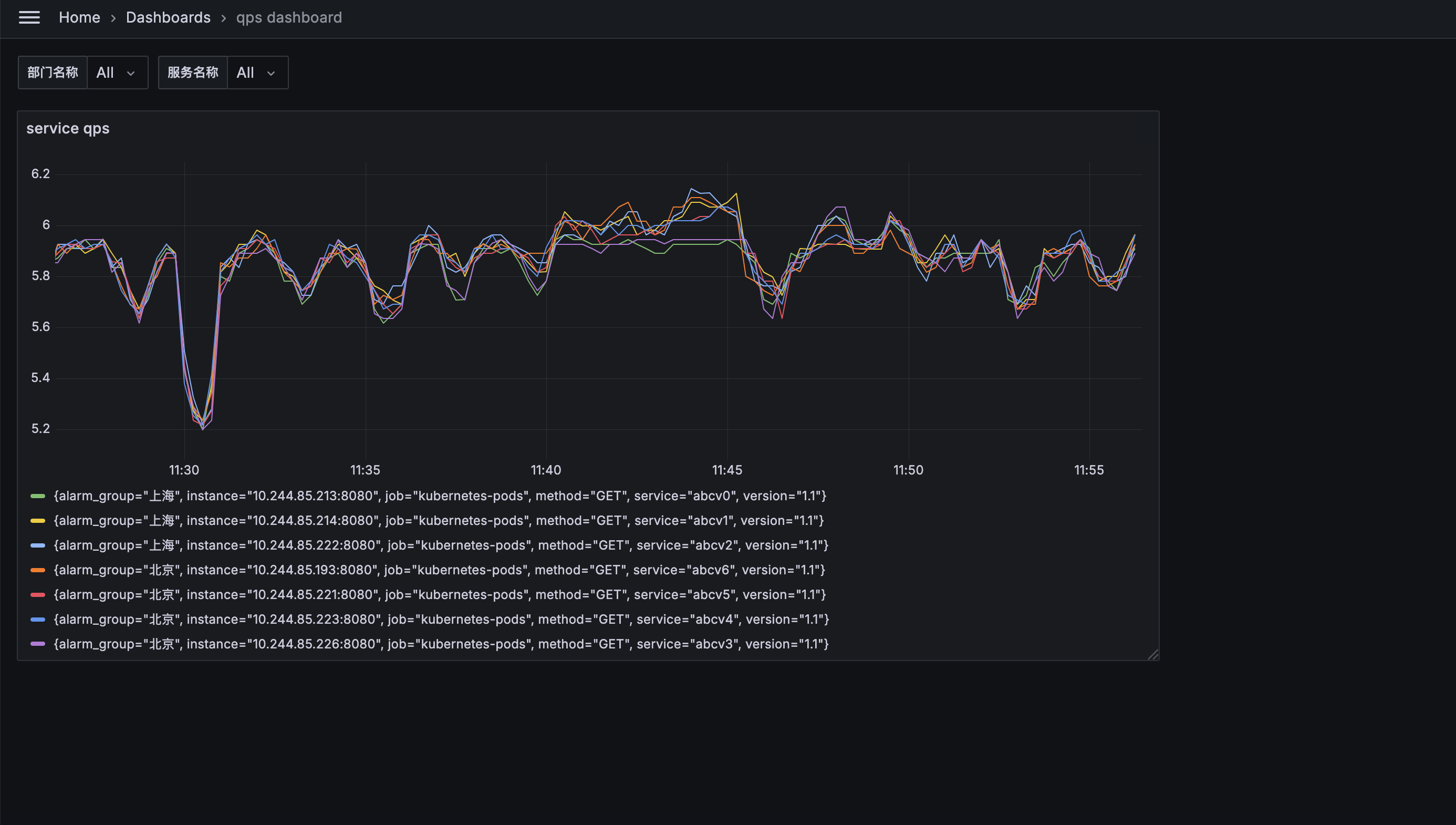
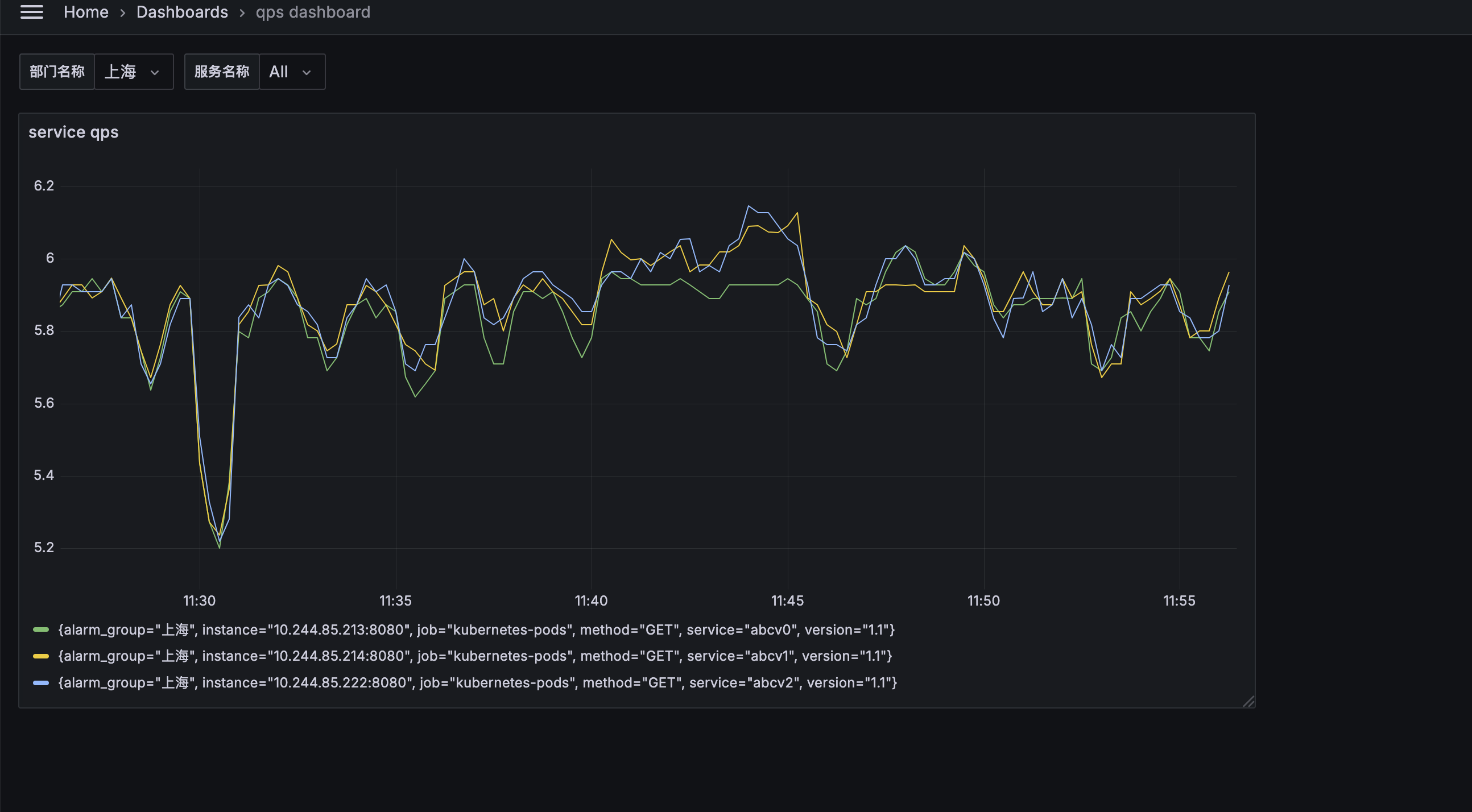
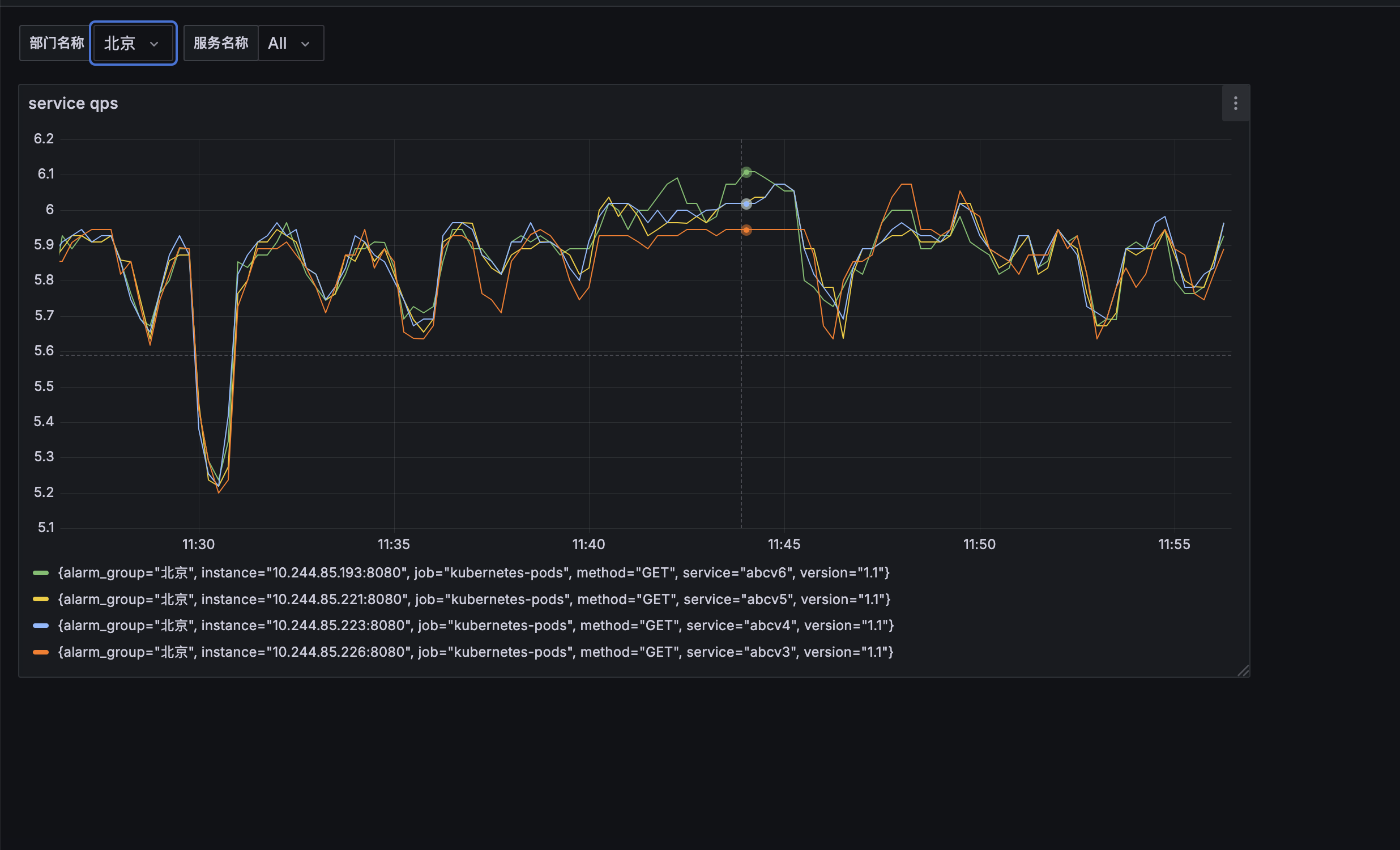
5.现在想通过要将qps超过10的 发送到不同的研发钉钉群
5.1 部署 alertmanager
5.1.1 下载alertmanager
wget https://githubfast.com/prometheus/alertmanager/releases/download/v0.26.0/alertmanager-0.26.0.linux-amd64.tar.gz
5.1.2 部署alertmanager
tar -xzvf alertmanager-0.26.0.linux-amd64.tar.gz -C /usr/local
cd /usr/local/
mv alertmanager-0.26.0.linux-amd64/ alertmanager
5.1.3 alertmanager钉钉告警配置
[root@k8s-master yace]# cat /data/alertmanager/alertmanager/alertmanager.yml
route:
group_by: ['alertname'] #采用哪个标签作为分组
group_wait: 30s #//收到报警不是立马发送出去,而是等待一段时间,看看当前组中是否有其他报警(比如当前组叫group_by: ['alertname']),如果有就一并发送
group_interval: 10s #//告警状态检查时间间隔,官方文档推荐 default = 5m
#// 如果告警状态发生变化,Alertmanager会在上一条发送告警<repeat_interval=配置的时间>之后发送告警。
#// 如需告警状态没有变化,Alertmanager会在上一条发送告警<repeat_interval=配置的时间+group_interval=配置的时间>之后发送告警
repeat_interval: 1m #//重新发送该告警的间隔时间,官方文档推荐 default = 4h
#// 如果告警状态发生变化,Alertmanager会在上一条发送告警<repeat_interval=配置的时间>之后发送告警。
#// 如需告警状态没有变化,Alertmanager会在上一条发送告警<repeat_interval=配置的时间+group_interval=配置的时间>之后发送告警
receiver: 'dingtalk_webhook' #//接收者是谁
receivers:
- name: 'dingtalk_webhook' #//接收者的名字,这里和route中的receiver对应
webhook_configs:
- url: 'http://localhost:8060/dingtalk/webhook1/send' #//接受者的url,通过prometheus-webhook-dingtalk发送
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
5.1.4 检查alertmanager配置文件格式
cd /data/alertmanager/alertmanager/
./amtool check-config alertmanager.yml
5.1.5 启动alertmanager
cd /data/alertmanager/alertmanager/
nohup ./alertmanager --config.file=./alertmanager.yml --log.level=debug &
5.1.6 访问alertmanager
http://172.16.99.71:9093
5.1.7 热加载alertmanager配置文件生效
curl -X POST http://localhost:9093/-/reload
5.1.8 Prometheus集成alertmanager
- 在Prometheus Server中的prometheus.yml文件中配置与Alertmanager通信的地址和端口
ll /data/prometheus/prometheus-2.53.3.linux-amd64/prometheus.yml
- 找到alerting并将其修改为如下配置(如果没有则进行添加):
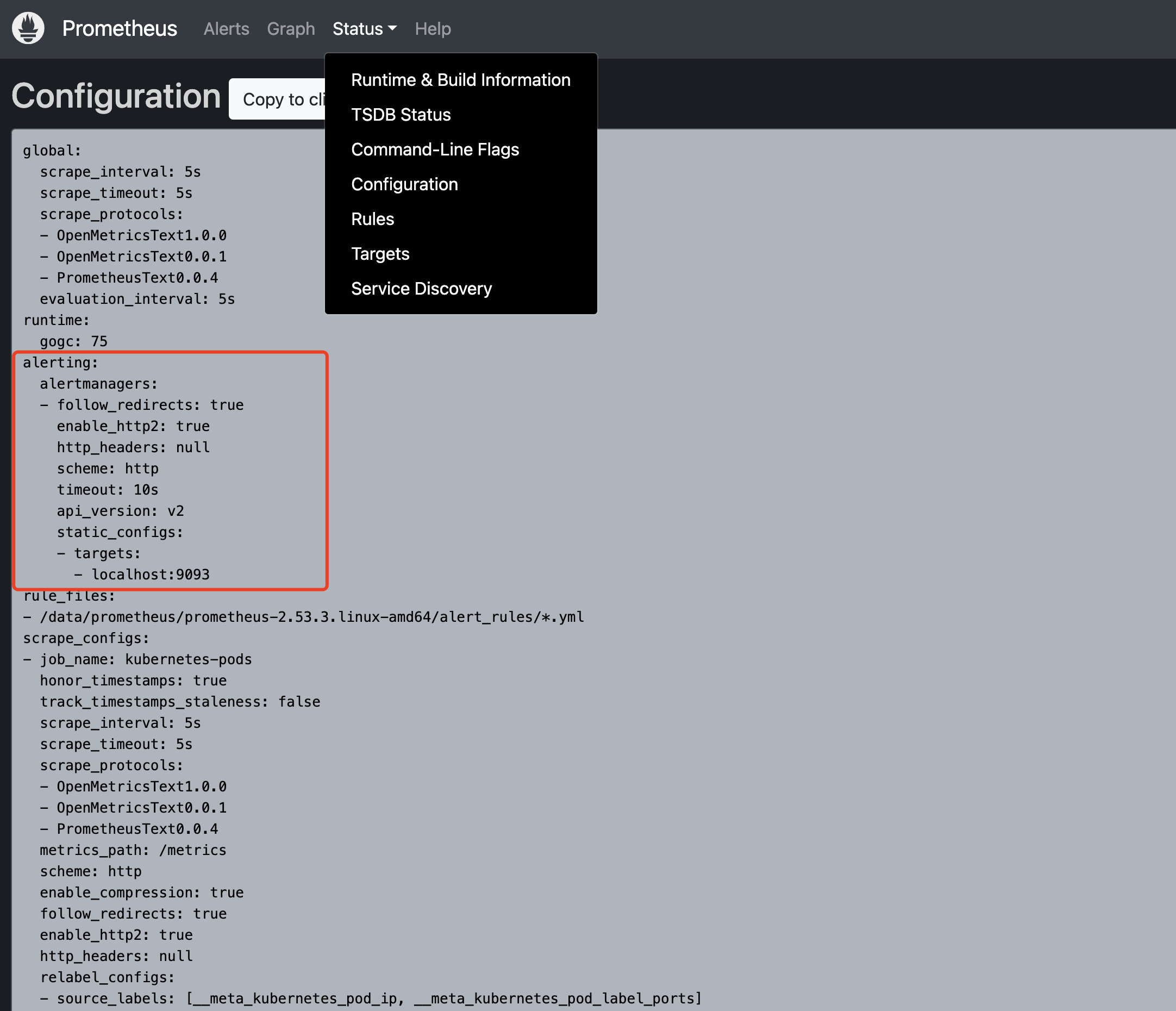
alerting:
alertmanagers:
- follow_redirects: true
scheme: http
timeout: 10s
api_version: v2
static_configs:
- targets: ['localhost:9093']
5.1.9 热加载Prometheus配置文件生效
curl -X POST http://localhost:9090/-/reload
- 在Prometheus网页界面查看配置
![image]()
5.2 配置 Prometheus告警规则(类似于在zabbix中创建触发器)
5.2.1 自定义Prometheus告警规则,监控qps超过100发送告警
mkdir /data/prometheus/prometheus-2.53.3.linux-amd64/alert_rules/
vim /data/prometheus/prometheus-2.53.3.linux-amd64/alert_rules/alert_rules.yml
- 添加
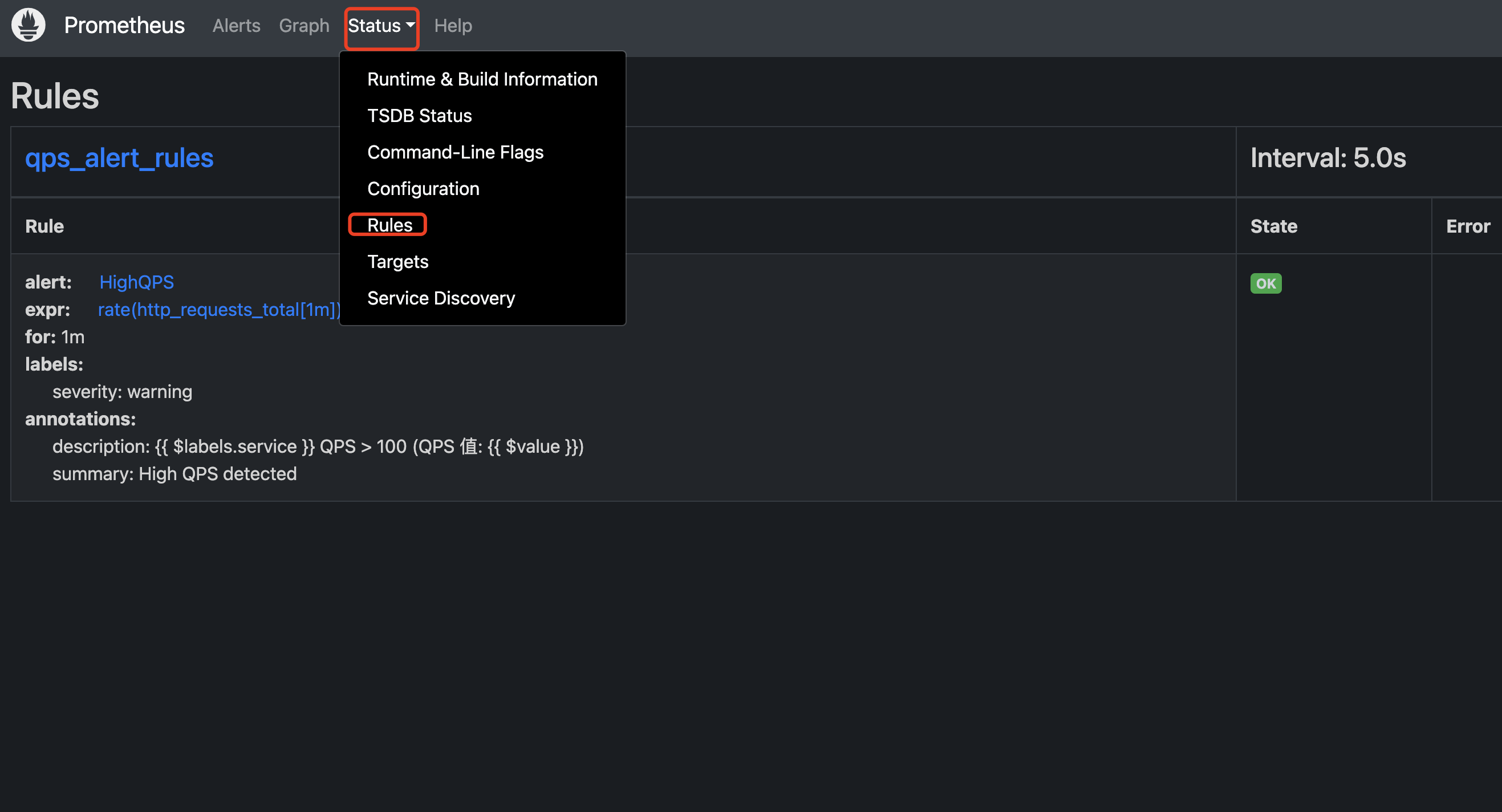
groups:
- name: qps_alert_rules #警报规则组的名称
rules:
- alert: HighQPS # 警报规则的名称
expr: rate(http_requests_total[1m]) > 100 #使用promql表达式完成的警报触发条件,用于计算是否满足触发条件
for: 1m #定义后,触发告警先转成Pending状态,达到for时间条件后转换为Firing状态。俩个周期才能触发警报条件,若是没有设置for,会直接从Inactive状态转换成Firing状态,触发警报,发送给alertmanager.yml中Receiver设置的通知人
labels: # 自定义标签,容许自定义标签添加在警报上
severity: warning
annotations: # 用来设置有关警报的一组描述信息,其中包括自定义的标签,以及expr计算后的值
summary: "High QPS detected"
description: "{{ $labels.service }} QPS > 100 (QPS 值: {{ $value }})"
- Prometheus热加载配置
curl -X POST http://localhost:9090/-/reload
- 在Prometheus界面查看规则
![image]()
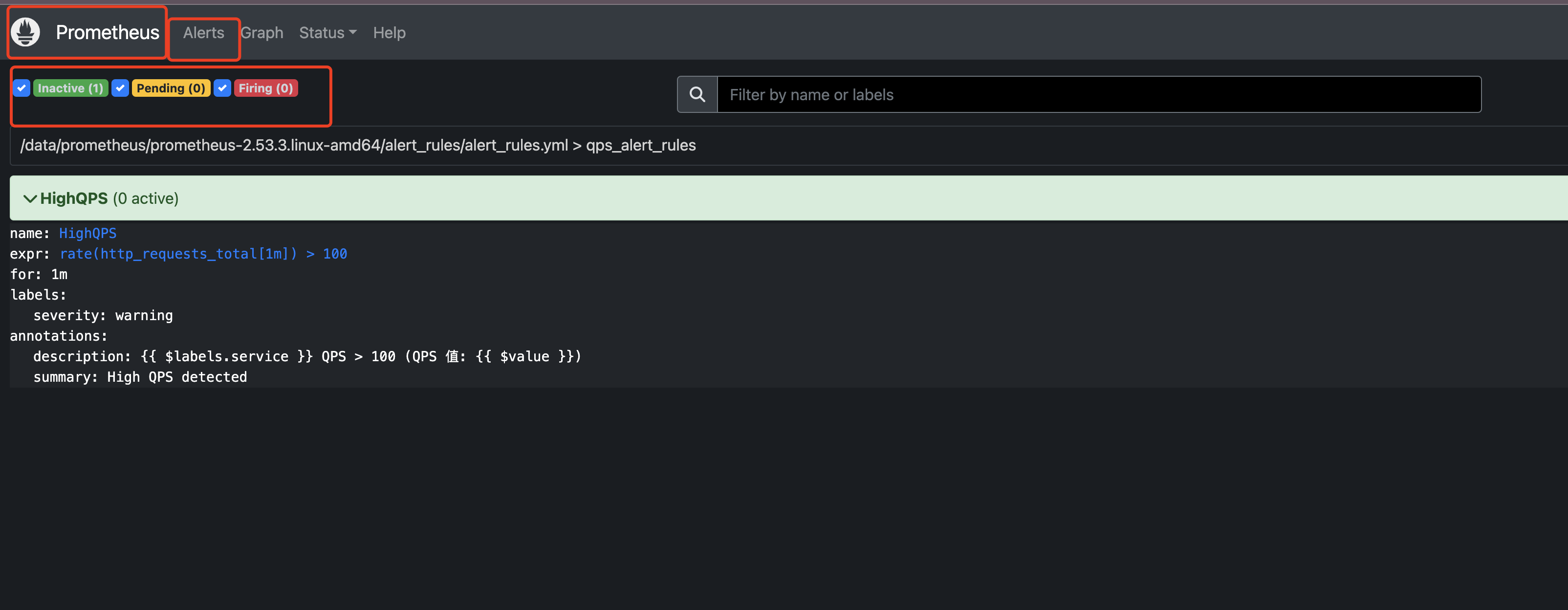
Prometheus告警规则状态
- Interval:正常状态,未激活警报
- Pending:已知触发条件,但没有达到发送时间条件,在rule规则中for 1m定义发送时间条件
- Firing:已触发阈值且满足告警持续时间,告警发送给接受者
![image]()
5.3 部署钉钉告警插件
- Prometheus的alertmanager自身不支持钉钉报警,需要通过插件的方式来达到报警条件
5.3.1 下载prometheus-webhook-dingtalk
wget https://githubfast.com/timonwong/prometheus-webhook-dingtalk/releases/download/v1.4.0/prometheus-webhook-dingtalk-1.4.0.linux-amd64.tar.gz
tar -xvf prometheus-webhook-dingtalk-1.4.0.linux-amd64.tar.gz -C /data/
cd /data
mv prometheus-webhook-dingtalk-1.4.0.linux-amd64 prometheus-webhook-dingtalk
5.3.2 配置钉钉报警模版
mkdir -p /data/prometheus-webhook-dingtalk/contrib/templates/
vim /data/prometheus-webhook-dingtalk/contrib/templates/dingding.tmpl
{{ define "__subject" }}
[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}]
{{ end }}
{{ define "__alert_list" }}{{ range . }}
---
**告警类型**: {{ .Labels.alertname }}
**告警级别**: {{ .Labels.severity }}
**故障主机**: {{ .Labels.instance }}
**告警信息**: {{ .Annotations.description }}
**触发时间**: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
**当前时间**: {{ now.Format "2006-01-02 15:04:05" }}
{{ end }}{{ end }}
{{ define "__resolved_list" }}{{ range . }}
---
**告警类型**: {{ .Labels.alertname }}
**告警级别**: {{ .Labels.severity }}
**故障主机**: {{ .Labels.instance }}
**告警信息**: {{ .Annotations.description }}
**触发时间**: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
**恢复时间**: {{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
**当前时间**: {{ now.Format "2006-01-02 15:04:05" }}
{{ end }}{{ end }}
{{ define "ops.title" }}
{{ template "__subject" . }}
{{ end }}
{{ define "ops.content" }}
{{ if gt (len .Alerts.Firing) 0 }}
**====侦测到{{ .Alerts.Firing | len }}个故障====**
{{ template "__alert_list" .Alerts.Firing }}
---
{{ end }}
{{ if gt (len .Alerts.Resolved) 0 }}
**====恢复{{ .Alerts.Resolved | len }}个故障====**
{{ template "__resolved_list" .Alerts.Resolved }}
{{ end }}
{{ end }}
{{ define "ops.link.title" }}{{ template "ops.title" . }}{{ end }}
{{ define "ops.link.content" }}{{ template "ops.content" . }}{{ end }}
{{ template "ops.title" . }}
{{ template "ops.content" . }}
5.3.2 钉钉机器人配置
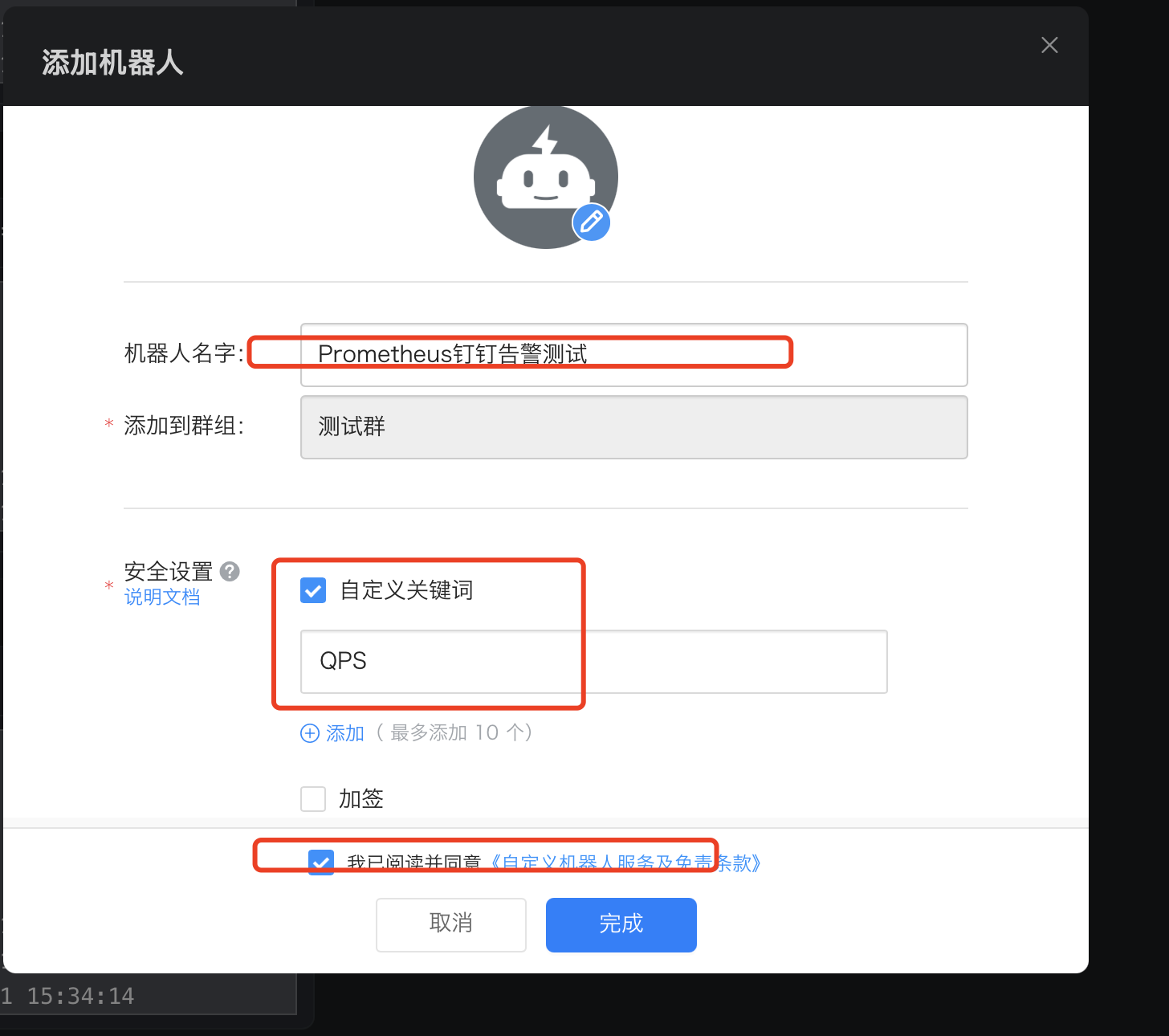
- 打开钉钉,在群中添加自定义机器人
![image]()
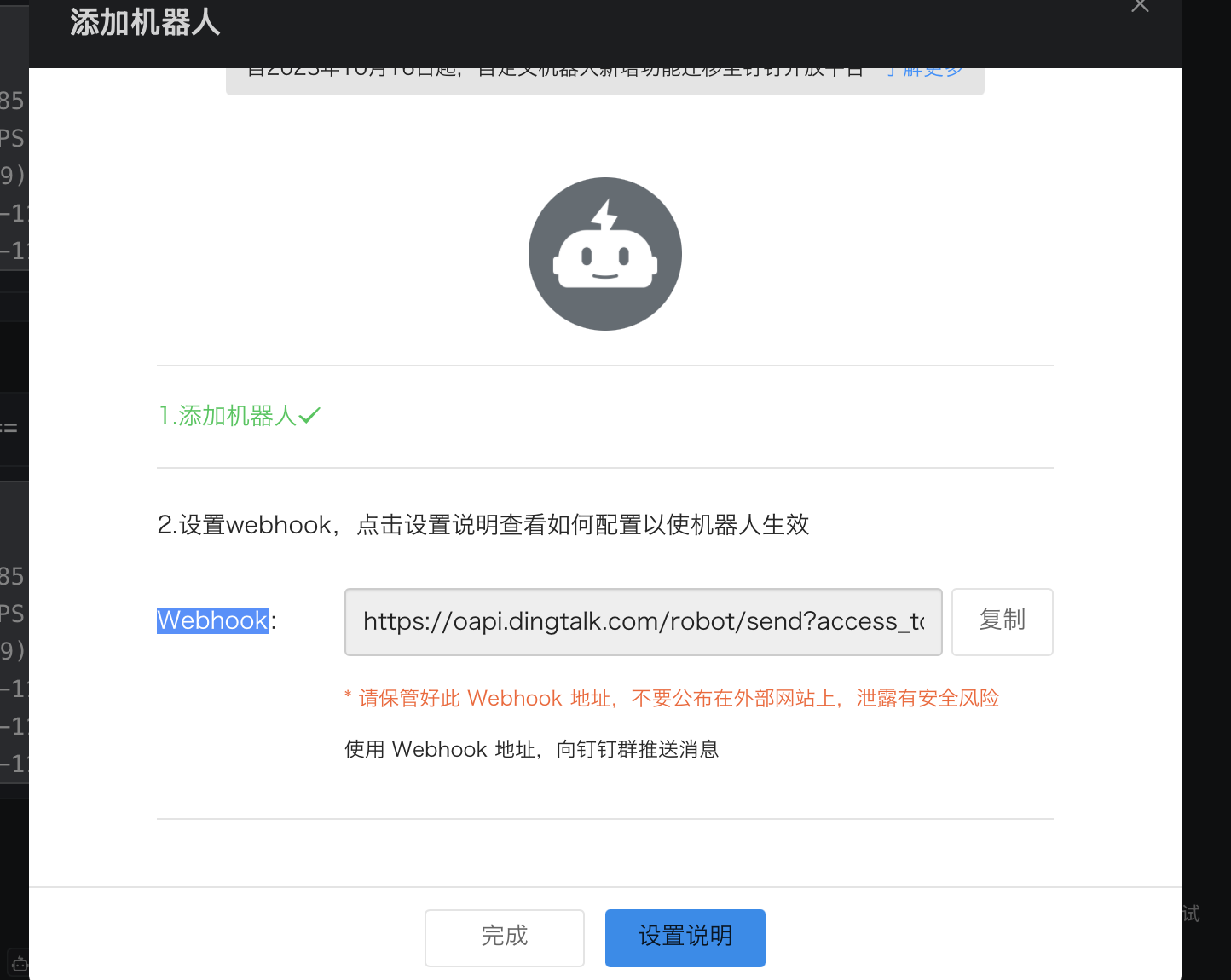
- 复制Webhook
![image]()
5.3.3 编辑prometheus-webhook-dingtalk配置文件
cd /data/prometheus-webhook-dingtalk/
cp config.example.yml config.yml
- 修改对应内容,url为复制的钉钉机器人webhook地址
templates:
- /data/prometheus-webhook-dingtalk/contrib/templates/dingding.tmpl
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=xxx
message:
title: '{{ template "ops.title" . }}'
text: '{{ template "ops.content" . }}'
- 启动
nohup /data/prometheus-webhook-dingtalk/prometheus-webhook-dingtalk --config.file=/data/prometheus-webhook-dingtalk/config.yml --log.level=debug --web.enable-lifecycle &
- 重载 (如果有更新可以reload重新加载配置生效)
curl -X POST http://localhost:8060/-/reload
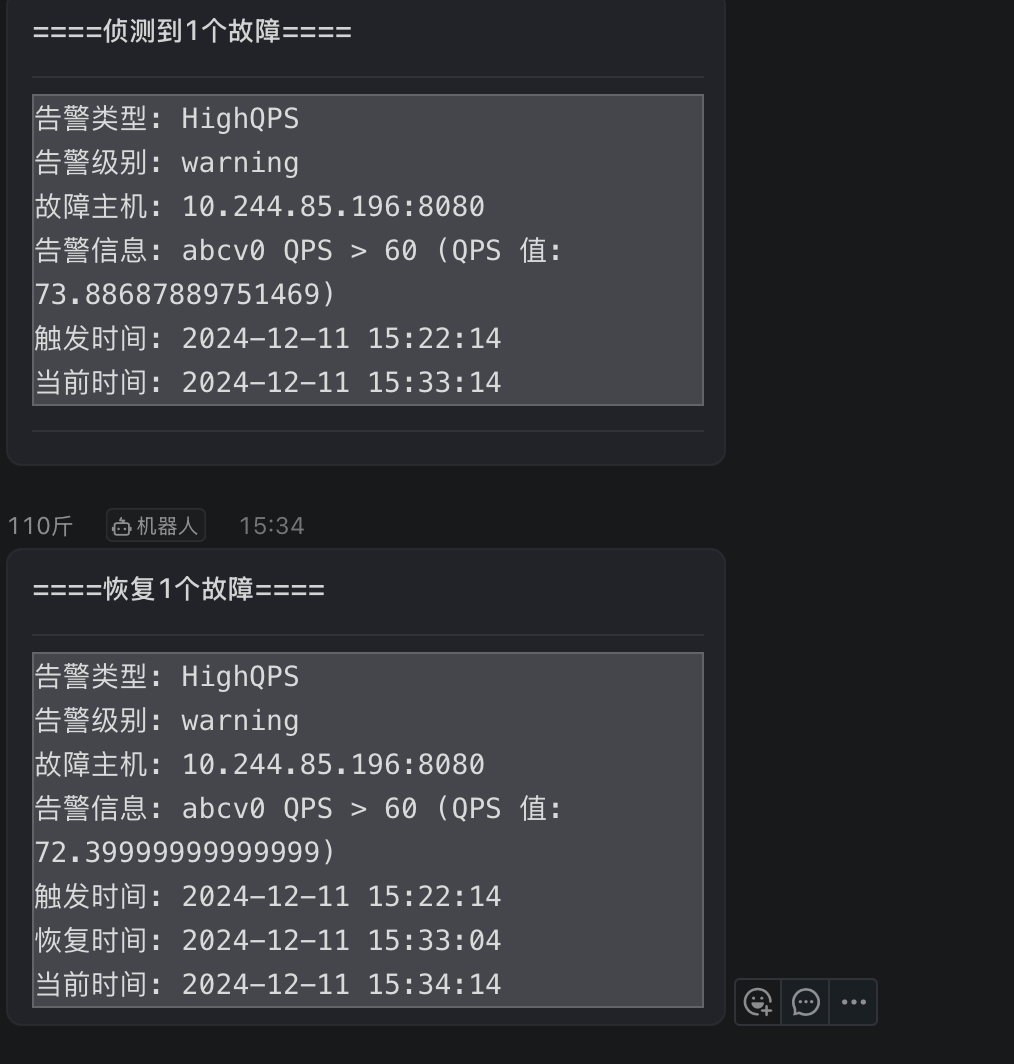
- 查看钉钉告警
![image]()
5.3.4 alertmanager实现不同的告警发送给不同的接收人
北京的研发接受自己服务的告警
上海的研发接受自己服务的告警
其余的又运维统一接受
- alertmanager配置文件如下
cat alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.qq.com:25'
smtp_from: '1092279986@qq.com' #填写自己qq邮箱
smtp_auth_username: '1092279986@qq.com' #填写自己qq邮箱
smtp_auth_password: 'ngudgwvbmydoghjd' #填写qq邮箱授权码
smtp_require_tls: false
route:
receiver: 'default-monitor' #//默认接收者
group_by: ['alertname', 'instance'] #采用哪个标签作为分组
group_wait: 30s #//收到报警不是立马发送出去,而是等待一段时间,看看当前组中是否有其他报警(比如当前组叫group_by: ['alertname']),如果有就一并发送
group_interval: 10s #//告警状态检查时间间隔,官方文档推荐 default = 5m
#// 如果告警状态发生变化,Alertmanager会在上一条发送告警<repeat_interval=配置的时间>之后发送告警。
#// 如需告警状态没有变化,Alertmanager会在上一条发送告警<repeat_interval=配置的时间+group_interval=配置的时间>之后发送告警
repeat_interval: 1m #//重新发送该告警的间隔时间,官方文档推荐 default = 4h
#// 如果告警状态发生变化,Alertmanager会在上一条发送告警<repeat_interval=配置的时间>之后发送告警。
#// 如需告警状态没有变化,Alertmanager会在上一条发送告警<repeat_interval=配置的时间+group_interval=配置的时间>之后发送告警
routes:
- receiver: 'default-monitor'
group_wait: 10m
match_re:
severity: p0
- receiver: 'yunwei'
match_re:
source: 'prometheus'
- receiver: 'phone'
match_re:
phone: 'true'
- receiver: 'beijing'
match_re:
alarm_group: "北京"
- receiver: 'shanghai'
match_re:
alarm_group: "上海"
receivers:
- name: 'default-monitor' #//接收者的名字,这里和route中的receiver对应
webhook_configs:
- url: 'http://localhost:8060/dingtalk/beijings/send' #//接受者的url,通过prometheus-webhook-dingtalk发送
send_resolved: true
- name: 'yunwei' #//接收者的名字,这里和route中的receiver对应
webhook_configs:
- url: 'http://service.113.37:38081/dingtalk/mingyang/send' #//接受者的url,通过prometheus-webhook-dingtalk发送
send_resolved: true
- name: 'phone' #//接收者的名字,这里和route中的receiver对应
webhook_configs:
- url: 'http://phone.alert.com/sendAlert' #//接受者的url,通过自己写的脚本发送
# send_resolved: true
- name: 'beijing' #//接收者的名字,这里和route中的receiver对应
webhook_configs:
- url: 'http://localhost:8060/dingtalk/beijing/send' #//接受者的url,通过prometheus-webhook-dingtalk发送
send_resolved: true
- name: 'shanghai' #//接收者的名字,这里和route中的receiver对应
webhook_configs:
- url: 'http://localhost:8060/dingtalk/shanghai/send' #//接受者的url,通过prometheus-webhook-dingtalk发送
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
- prometheus-webhook-dingtalk 配置文件如下
[root@k8s-master alertmanager]# cat /data/prometheus-webhook-dingtalk/config.yml
templates:
- /data/prometheus-webhook-dingtalk/contrib/templates/dingding.tmpl
targets:
beijing:
url: https://oapi.dingtalk.com/robot/send?access_token=xxx
message:
title: '{{ template "ops.title" . }}'
text: '{{ template "ops.content" . }}'
shanghai:
url: https://oapi.dingtalk.com/robot/send?access_token=xxx
message:
title: '{{ template "ops.title" . }}'
text: '{{ template "ops.content" . }}'
5.3.5 发送到电话告警
cat alert_rules.yml
groups:
- name: qps_alert_rules
rules:
- alert: HighQPS
expr: rate(http_requests_total[1m]) > 30
for: 1m
labels:
severity: warning
annotations:
summary: "High QPS detected"
description: "{{ $labels.service }} QPS > 30 (QPS 值: {{ $value }})"
- name: HTTP-Probe
rules:
- alert: http_check_helth
expr: probe_success { job="kube-http-probe",env="online" } == 0
for: 11s
labels:
service: k8s
severity: critical
annotations:
description: "{{ $labels.service }} check health fail"
- alert: http_check_helth_10min
expr: probe_success { job="kube-http-probe",env="online" } == 0
for: 10m
labels:
phone: true
phone_group: 告警组
service: k8s
severity: critical
annotations:
description: "{{ $labels.service }} 10min check health fail"
cat /data/alertmanager/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.qq.com:25'
smtp_from: '1092279986@qq.com' #填写自己qq邮箱
smtp_auth_username: '1092279986@qq.com' #填写自己qq邮箱
smtp_auth_password: 'ngudgwvbmydoghjd' #填写qq邮箱授权码
smtp_require_tls: false
route:
receiver: 'default-monitor' #//默认接收者
group_by: ['alertname', 'instance'] #采用哪个标签作为分组
group_wait: 30s #//收到报警不是立马发送出去,而是等待一段时间,看看当前组中是否有其他报警(比如当前组叫group_by: ['alertname']),如果有就一并发送
group_interval: 10s #//告警状态检查时间间隔,官方文档推荐 default = 5m
#// 如果告警状态发生变化,Alertmanager会在上一条发送告警<repeat_interval=配置的时间>之后发送告警。
#// 如需告警状态没有变化,Alertmanager会在上一条发送告警<repeat_interval=配置的时间+group_interval=配置的时间>之后发送告警
repeat_interval: 1m #//重新发送该告警的间隔时间,官方文档推荐 default = 4h
#// 如果告警状态发生变化,Alertmanager会在上一条发送告警<repeat_interval=配置的时间>之后发送告警。
#// 如需告警状态没有变化,Alertmanager会在上一条发送告警<repeat_interval=配置的时间+group_interval=配置的时间>之后发送告警
routes:
- receiver: 'default-monitor'
group_wait: 10m
match_re:
severity: p0
- receiver: 'yunwei'
match_re:
source: 'prometheus'
- receiver: 'phone'
match_re:
phone: 'true'
- receiver: 'beijing'
match_re:
alarm_group: "北京"
- receiver: 'shanghai'
match_re:
alarm_group: "上海"
receivers:
- name: 'default-monitor' #//接收者的名字,这里和route中的receiver对应
webhook_configs:
- url: 'http://localhost:8060/dingtalk/beijings/send' #//接受者的url,通过prometheus-webhook-dingtalk发送
send_resolved: true
- name: 'yunwei' #//接收者的名字,这里和route中的receiver对应
webhook_configs:
- url: 'http://service.113.37:38081/dingtalk/mingyang/send' #//接受者的url,通过prometheus-webhook-dingtalk发送
send_resolved: true
- name: 'phone' #//接收者的名字,这里和route中的receiver对应
webhook_configs:
- url: 'http://phone.alert.com/sendAlert' #//接受者的url,通过自己写的脚本发送
# send_resolved: true
- name: 'beijing' #//接收者的名字,这里和route中的receiver对应
webhook_configs:
- url: 'http://localhost:8060/dingtalk/beijing/send' #//接受者的url,通过prometheus-webhook-dingtalk发送
send_resolved: true
- name: 'shanghai' #//接收者的名字,这里和route中的receiver对应
webhook_configs:
- url: 'http://localhost:8060/dingtalk/shanghai/send' #//接受者的url,通过prometheus-webhook-dingtalk发送
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
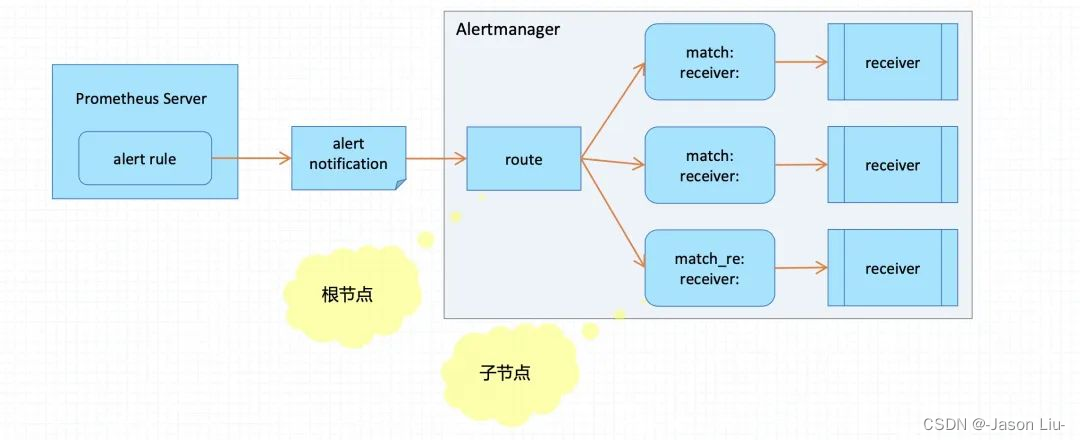
5.4 Prometheus alertmanager告警路由配置
alertmanager路由配置可以将不同的告警通过标签定义分别发送给不同的媒介接收人。
alertmanager的route配置段支持定义树状路由表,入口位置称为根节点,每个子节点可以基于匹配条件定义出一个独立的路由分支
所有告警都将进入根节点,然后进行子节点遍历;
若路由上的continue字段的值为false,则遇到第一个匹配的的路由分之后即终止;否则,将继续匹配后续的子节点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号