【K8S】K8S架构
整体架构
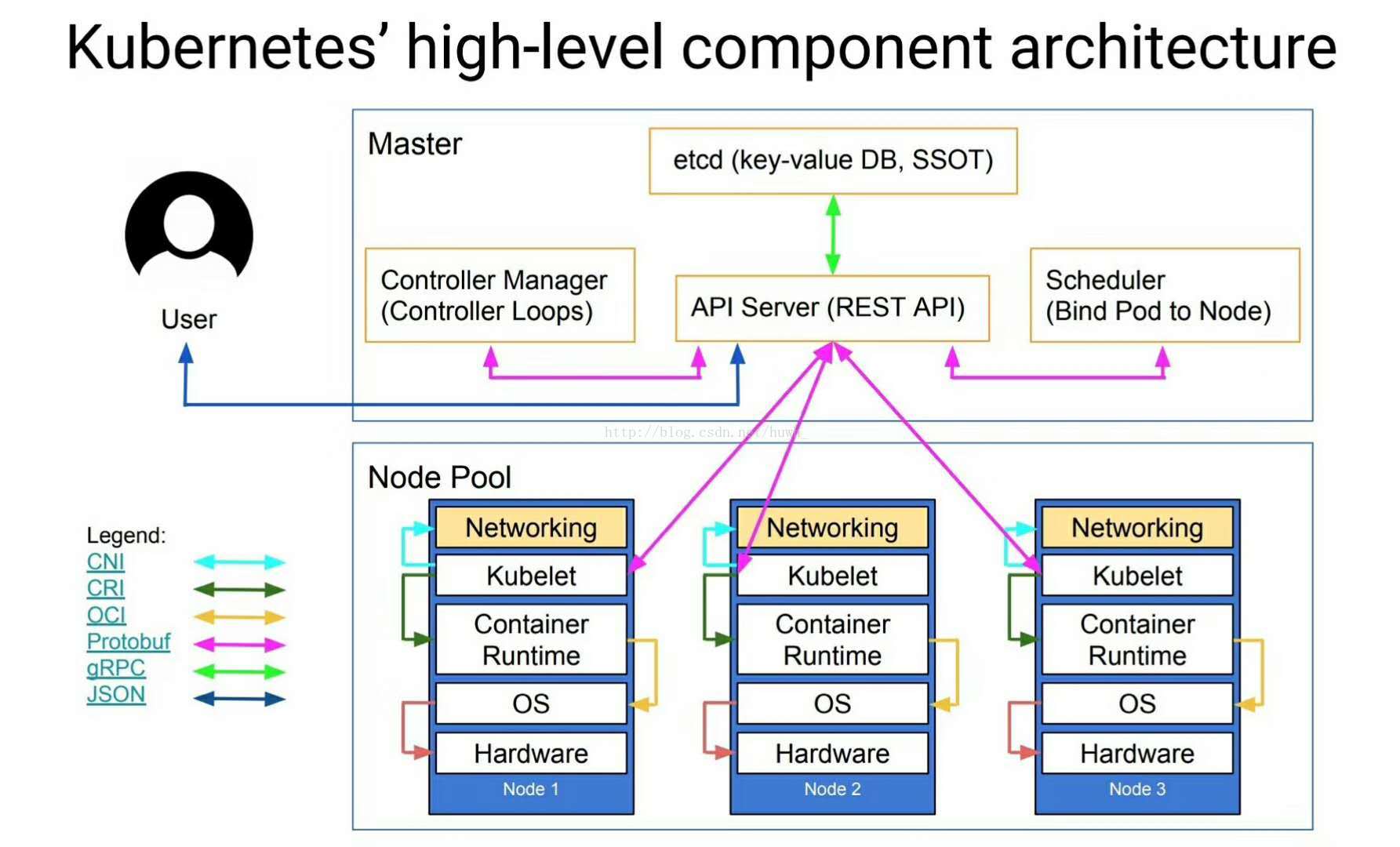
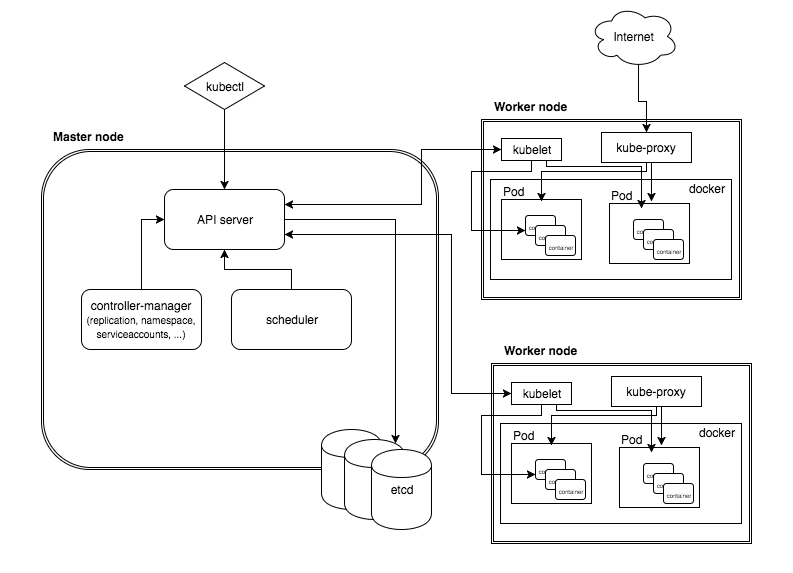
Kubernetes属于主从分布式架构
主要由Master Node和Worker Node组成,以及包括客户端命令行工具kubectl和其它附加项。
-
Master Node:
作为控制节点,对集群进行调度管理;
Master Node由API Server、Scheduler、Cluster State Store和Controller-Manger Server所组成; -
Worker Node:
作为真正的工作节点,运行业务应用的容器;
Worker Node包含kubelet、kube proxy和Container Runtime; -
kubectl:
用于通过命令行与API Server进行交互,而对Kubernetes进行操作,实现在集群中进行各种资源的增删改查等操作; -
Add-on:
是对Kubernetes核心功能的扩展,例如增加网络和网络策略等能力。、 -
repliceation :
于伸缩副本数量 -
Endpoint:
用于管理网络请求 -
scheduler:
调度器 -
Etcd:
高可用键值存储系统基本流程

-
提交创建Pod的请求
准备好一个包含应用程序的Deployment的yml文件或者json文件,然后通过kubectl客户端工具(或者Rest API)发送给ApiServer(对应EMS项目的apiGateway)。 -
ApiServer处理数据请求,存储Pod数据到Etcd。
ApiServer是Master的核心,所有的数据信息都要与ApiServer做交互。 -
Controller组件监控资源变化并作出反应
Controller包括scheduler、replication、endpoint
绑定Node: Schedule通过和 API Server的watch机制,查看到新的pod,尝试为Pod绑定Node;
过滤主机: 调度器用一组规则过滤掉不符合要求的主机,比如Pod指定了所需要的资源,那么就要过滤掉资源不够的主机;
主机打分: 对第一步筛选出的符合要求的主机进行打分,在主机打分阶段,调度器会考虑一些整体优化策略,比如把一个Replication Controller的副本分布到不同的主机上,使用最低负载的主机等;
选择主机: 选择打分最高的主机,进行binding操作,结果存储到Etcd中; -
ReplicaSet(replication)检查数据库变化,创建期望数量的pod实例。
-
Scheduler再次检查数据库变化,为剩余的Pod分配节点
发现尚未被分配到具体执行节点(node)的Pod,根据一组相关规则将pod分配到可以运行它们的节点上,并更新数据库,记录pod分配情况。
绑定成功后,scheduler会调用API Server的API在etcd中创建一个bound pod对象,描述在一个工作节点上绑定运行的所有pod信息。 -
kubelet根据调度结果执行Pod创建操作
Kubelet监控数据库变化,管理后续pod的生命周期,发现被分配到它所在的节点上运行的那些pod。如果找到新pod,则会在该节点上运行这个新pod。
运行在每个工作节点上的kubelet会定期与etcd同步bound pod信息,一旦发现应该在该工作节点上运行的bound pod对象没有更新,则调用Docker API创建并启动pod内的容器,docker run。 -
kubeProxy
运行在集群各个主机上,管理网络通信,如服务发现、负载均衡。
例如当有数据发送到主机时,将其路由到正确的pod或容器。对于从主机上发出的数据,它可以基于请求地址发现远程服务器,并将数据正确路由,在某些情况下会使用轮训调度算法(Round-robin)将请求发送到集群中的多个实例。
参考:
[1] https://www.cnblogs.com/wwchihiro/p/9261607.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号