kafka消息队列
简介:
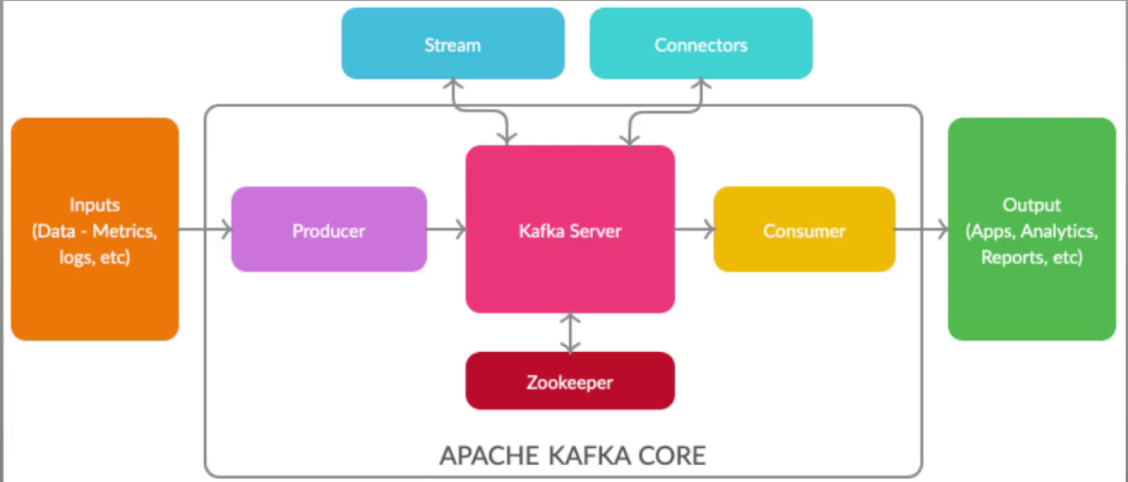
Kafka被称为下一代分布式消息系统,由scala和Java编写
用于构建实时数据管道和流应用程序。它具有水平可伸缩性,容错性,快速性,可在数千家公司中投入生产
使用内存映射和零时拷贝机制达到io高性能
常用消息队列对比:
kafka最主要的优势是其具备分布式功能、并可以结合 zookeeper可以实现动态扩容,Kafka是一种高吞吐量的分布式发布订阅消息系统(较新版本kafka内开始部使用kraft,使用kafka内置的功能存储元数据,想替代zookeeper,不过看官方文档中指明,生产环境不建议使用,还未进入稳定版本)
kafka 优势:
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息
- 支持通过Kafka服务器分区消息
- 支持Hadoop并行数据加载
写数据时:
内存映射:kafka的数据直接写入到内存中,并通知请求者,数据已写入,后面过段时间后才会同步到磁盘
读数据时:
零拷贝技术:kafka发起磁盘读请求后,直接全权交给内核自处理,读取到数据后,复制到内核内存后直接从网卡发出去
kafka基础概念:
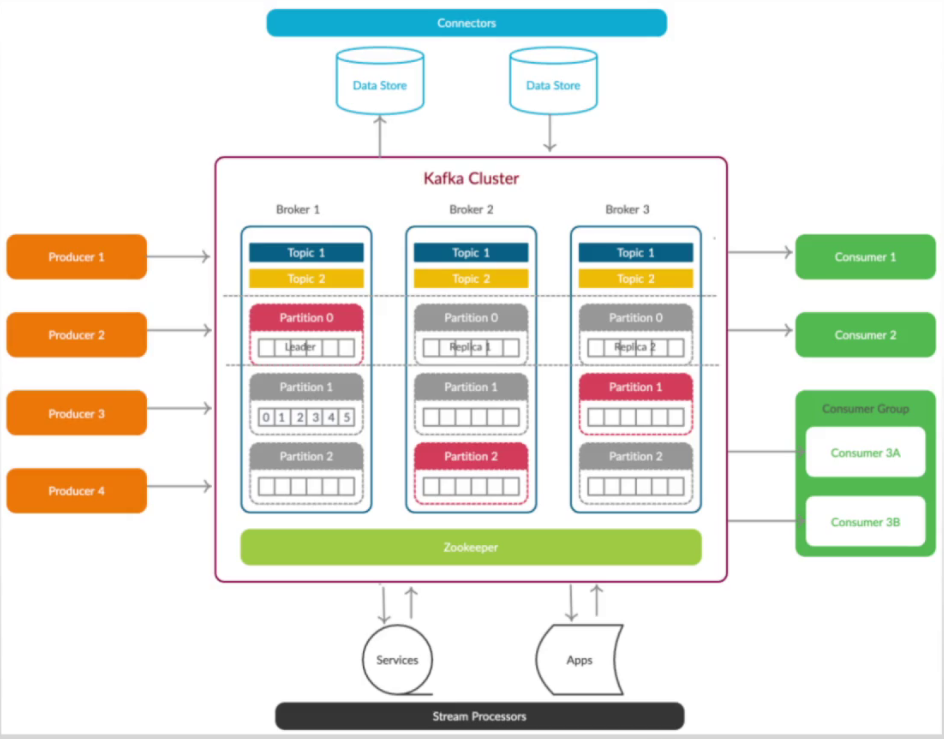
Broker:
Broker 是 Kafka 集群中的一个节点,负责存储和处理消息
每个 Broker 都是一个独立的 Kafka 服务器,可以在不同的机器上运行
一个Kafka 集群由多个Broker组成,其中1个是leader,其他都是Follower,它们协同工作以提供高可用性和可扩展性
Topic:
Topic 是 Kafka 中消息的逻辑分类。它是消息的发布和订阅的目标,类似于一个消息队列的名称(类似channel)
生产者将消息发送到特定的Topic,而消费者则从Topic订阅消息。Topic可以被分区(保存在partition中),以便实现消息的并行处理和负载均衡(1个topic的数据,可保存在1到多个分区中,每个分区中,有1个leader,1到多个replicas/followers)
逻辑上一个topic的消息虽然保存于一个或多个broker上但用户只需指定消息的topic即可生产或消费数据而不必关心数据存于何处
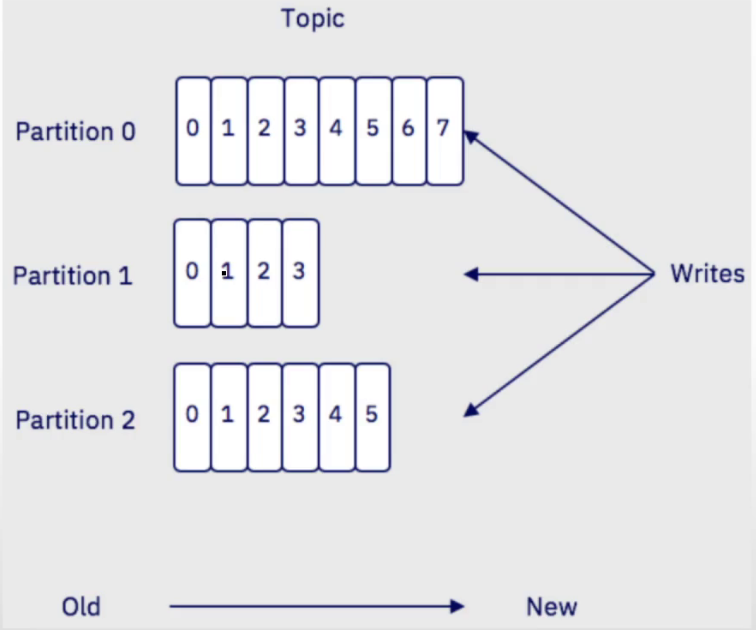
Partition:
物理上的概念,topic的子单元,partition是topic中具体存消息的队列,会并行存储在多个broker上,读取数据时,从所有Partition读取
1个topic由多个partition组成,每个paratition自身又有副本数,主副本提供工作,从副本备用。当消息写入时,定义了topic有3个分区,集群是3个节点,根据算法分配时,msg1写入A节点的topic中A分区,msg2写入B节点的topic中B分区,以此类推
创建topic时可指定parition数量,每个partition对应于一个文件夹,该文件夹下存储该partition的数据和索引文件
- 每个Partition都是一个按时间排序的不可变记录序列,存于日志
- 消费者按记录于日志中的存储顺序读取消息
- 每个消息都有1个称为offset的id
注:分区配置要小于等于节点数,毕竟大于节点数也没有备份的意义
Replica:
Replica 是 Partition 的副本,用于提供数据的冗余和容错性。
每个 Partition 可以有多个副本,其中一个被称为 Leader(领导者),其他副本被称为 Follower(跟随者)。Leader 负责处理消息的读写请求,而 Follower 则复制 Leader 的数据以提供容错性
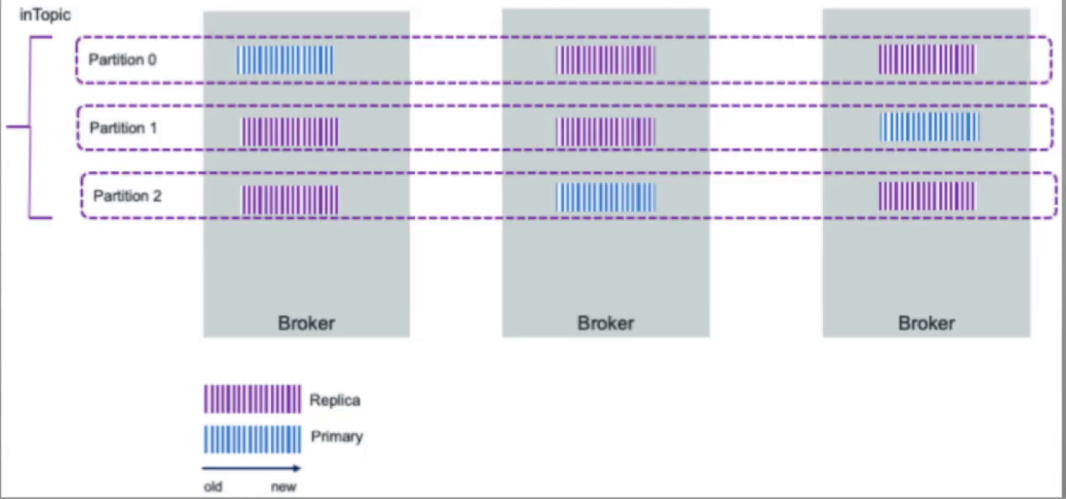
复制因子
复制因子是指每个 Partition 的副本数量。在创建 Topic 时,可以指定复制因子的值。复制因子决定了每个 Partition 的副本数,通常设置为大于等于 2,以提供数据的冗余和容错性。复制因子越高,数据的可靠性和可用性就越高,但同时也会增加存储和网络开销
副本优势(复制因子为 3):
- 实现存储空间的横向扩容,即将多个kafka服务器的空间结合利用
- 提升性能,多服务器读写
- 实现高可用,分区leader分布在不同的kafka服务器,比如分区0的leader为服务器A,则服务器B和服务器C为A的follower,而分区1的leader为服务器B,则服务器A和C为服务器B的follower,而分区2的leader为C,则服务器A和B为C的follower
groups
消费者组,在同一个组内的消费者,共享同一个公共id,即group id,一起消费topic的所有分区
同1个topic中的分区,只能由同一个消费组内的1个消费者消费,组内共享订阅
Producer:
负责发布消息到Kafka broker
Consumer:
消费消息,每个consumer属于一个特定的consuer group(可为每个consumer指定group name, 若不指定group name则属于默认的group)
使用consumer high level API时, 同一topic的一条消息只能被同一个consumer group内的一个consumer消费,但多个 consumer group 可同时消费这一消息
log
存储消息的物理文件,每个 Kafka Topic 都有一个或多个分区,而每个分区都有一个对应的日志文件,也称为日志段(log segment)
Kafka 的日志以追加写入的方式进行,即新的消息会被追加到日志的末尾。每个日志段都有一个固定的大小限制,一旦达到限制,就会创建一个新的日志段。这种追加写入的方式使得 Kafka 具有高吞吐量和低延迟的特性。
每个日志段都有一个唯一的偏移量(offset),用于标识其中的消息的位置。偏移量是一个递增的整数,从 0 开始。消费者可以通过指定偏移量来读取特定位置的消息。
Kafka 的日志文件是持久化存储的,即使消息被消费或者过期,它们仍然会保留在日志中。这种持久化存储的特性使得 Kafka 可以提供可靠的消息传递,并支持消息的回溯和重放
ISR(In-Sync Replica)
每个分区在Kafka中都有一个主副本(Leader)和一组副本(Replicas)。主副本负责处理读写请求,而副本用于提供冗余和故障转移。ISR是指那些与主副本保持同步的副本,也就是与主副本保持相同的数据副本。
当消息被写入主副本时,主副本会将消息复制到ISR中的副本。只有在ISR中的副本完成了消息的复制,主副本才会认为写操作成功。这样可以确保数据的可靠性和一致性。
如果某个副本与主副本的同步进程出现故障或延迟,它将被移出ISR。一旦副本与主副本的同步恢复正常,它将重新加入ISR。这种机制可以确保只有与主副本保持同步的副本才能成为新的主副本,从而保证数据的一致性
kafka消息记录
基于pub/sub和queue模型构建topic,使用消费者组(consumer group)的概念将处理任务划分为1组消费者进程并运行,且将消息广播到多个组中
待存入topic的消息记录未明确指定partition时,kafka会根据记录的key的hash码选择1个partition;未明确指定时间戳时,producer将会使用当前作为时间戳
格式:每个消息记录(record)的格式一般由key、value、timestamp和一些元数据组成
数据存储目录:
- 配置
log.dir:各topci会映射到目录的子目录中。kafka会保留所有记录,无论是否已经被消费 - 记录在broker配置中定义的retention period内保留,默认时长为7天
kafka程序:
端口: 9092
程序脚本:
kafka-server-start.sh
服务启动脚本
-daemon server.properties路径 后台启动
kafka-server-stop.sh
服务停止
kafka-topics.sh
topic使用脚本
--create 创建
--topic topic名称
--bootstrap-server ip:9092 指定kafka主机
--delete 删除操作
--zookeeper ip:port zk主机
kafka-console-producer.sh
生产消息
--broker-list ip:port 连接到kafka,写数据
--topic topic名称 在指定topic中写数据
kafka-console-consumer.sh
接收消息
--topic name
--bootstrap-server ip:port 指定kafka主机
--from-beginning 从最开始获取数据
其他
kafka-configs.sh #配置更新,允许动态更新broker部分配置
kafka-producer-perf-test.sh #压测脚本
kafka-streams-application-reset.sh #stream流压测脚本
kafka-leader-election.sh #leader重新选举
kafka-preferred-replica-election.sh #分区副本重新选举
主配置文件:server.properties
broker.id=1 #集中节点id,保持唯一性
listeners=PLAINTEXT://0.0.0.0:9092 #监听所有,侦听器名称不是安全协议,则还必须设置 listener.security.protocol.map
SSL://:9091
CLIENT://0.0.0.0:9092,REPLICATION://localhost:9093
PLAINTEXT://127.0.0.1:9092,SSL://[::1]:9092
num.network.threads=16 #开启网络线程数,每个侦听器都会创建自己的线程池,默认3
num.io.threads=16 #磁盘io线程数,默认8
num.recovery.threads.per.data.dir=1 #每个数据目录在启动时用于日志恢复和关机时刷新的线程数
log.dirs=目录1,目录2 #kakfa用于保存数据的目录,所有的消息都会存储在该目录当中
num.partitions=1 #创建topic分区数量,建议跟kafka服务器数量一致
log.retention.hours=168 #设置kafka中消息保留时间,超过后自动轮询删除,默认为168h=7d
advertised.host.name #主机名,注册到zk中的服务名,提供给客户端访问。Iaas环境中需要与broker绑定不同的端口。仅advertised.listeners或listeners未配置时使用
advertused.listeners #监听器发布到zk供客户端使用如果与listeners配置不同。在IaaS环境,这可能需要与broker绑定不通的接⼝。如果没有设置,将使⽤`listeners`的配置。与`listeners`不同的是,配置0.0.0.0元地址是⽆效的。
advertised.port #监听端口,仅在listeners未配置时使用
auto.create.topic.enable=true #是否自动创建topic
auto.leader.rebalance.enable=true #自动Leader Partition平衡,默认true
leader.imbalance.per.broker.percentage=10 #默认是10%。每个broker允许的不平衡的leader的比率。如果每个broker超过了这个值,控制器会触发leader的平衡
background.threads=10 #用于处理各种后台任务的线程数量,默认10
compression.type=producer #指定topic的最终压缩类型,默认producer
uncompressed,不压缩
zstd,
lz4
snappy
gzip
producer,表示保留生产者设置的原始压缩编解码器
control.plane.listener.name #不能与 inter.broker.listener.name 的值相同
controller.quorum.election.backoff.max.ms=1000 #开始新选举之前的最长时间,默认1000ms。这用于二进制指数退避机制,有助于防止选举陷入僵局
controller.quorum.election.timeout.ms=1000 #在触发新选举之前,在无法从领导者处获取的最长时间,默认1000ms
controller.quorum.fetch.timeout.ms=2000 #在成为候选人并触发选民选举之前,没有成功从现任领导人那里获得的最长时间;在四处询问以查看是否有新的领导者纪元之前,未收到来自大多数仲裁的提取的最长时间
controller.quorum.voters=id号@主机:端口,... #参与选举投票的
delete.topic.enable=true #启用topic删除
log.segment.bytes=1073741824 #单个日志文件的最大大小,默认1g
log.segment.delete.delay.ms=60000 #删除文件之前,等待时间,默认60000ms(1m)
log.cleanup.policy=delete #日志清理策略,默认delete,compact为压缩
log.flush.interval.messages=10000 #当一个分区中的消息数量达到1w条时,将分区的日志刷新到磁盘上。默认10000
log.flush.interval.ms=1000 #自动触发日志刷新的时间间隔。当一个分区中的消息在指定的时间间隔内没有达到刷新的条件时,Kafka会自动将该分区的日志刷新到磁盘上,默认1000ms
log.retention.bytes=1073741824 #每个分区中消息日志的保留字节数,当一个分区的消息日志大小达到或超过该阈值时,Kafka会开始删除最旧的消息以释放空间
log.retention.check.interval.ms=300000 #检查日志保留策略的时间间隔。Kafka会定期检查每个分区的消息日志,并根据配置的保留策略来删除过期的消息
message.max.bytes=1048588 #broker端接收每个批次消息最大字节,默认1m
max.message.bytes=1048588 #topic处配置每个批次消息最大字节,默认1m
max.request.size=1048588 #默认1m,生产者发往broker每个请求消息最大值。针对topic级别设置消息体的大小
replica.fetch.max.bytes=1048588 #默认1m,副本同步数据,每个批次消息最大值
metadata.log.dir=目录 #仅kraft时有效,单独配置元数据存储,默认存于log.dirs中第一个目录
num.replica.alter.log.dirs.threads #在日志目录之间移动副本的线程数,其中可能包括磁盘 I/O
num.replica.fetchers=1 #从每个消息事件源复制记录的提取程序线程数,总数为:此处配置*broker数。增加此值可以提高从属代理和主代理的I/O并行度,但代价是CPU和内存利用率更高
offsets.topic.num.partitions=50 #偏移提交主题的分区数(部署后不应更改),默认50
offsets.topic.replication.factor=3 #偏移主题的复制因子(设置得更高以确保可用性)。在群集大小满足此复制因子要求之前,内部主题创建将失败
transaction.state.log.min.isr=2 #设置事务状态日志的最小副本同步因子。在写操作时,至少需要2个副本完成同步才算成功,建议为复制因子的3分之2
offsets.topic.segment.bytes=104857600 #偏移主题段字节应保持相对较小,以便更快地进行日志压缩和缓存加载,默认100m
queued.max.requests=500 #在阻塞网络线程之前,数据平面允许的排队请求数
replica.high.watermark.checkpoint.interval.ms=5000 #更新副本高水位标记检查点的时间间隔,以确保副本状态的恢复和故障容错能力
replica.socket.receive.buffer.bytes=65536 #套接字接收缓冲区,用于向leader发出网络请求以复制数据,默认65536字节
replica.lag.time.max.ms=30000 #ISR中,如果Follower长时间未向Leader发送通信请求或同步数据,则该Follower将被踢出ISR。该时间阈值,默认30s
replica.socket.timeout.ms=30000 #网络请求的套接字超时。它的值应至少为 replica.fetch.wait.max.ms
request.timeout.ms=30000 #客户端等待请求响应的最长时间。如果在超时结束之前未收到响应,则客户端将在必要时重新发送请求,如果重试用尽,则请求将失败
socket.receive.buffer.bytes=102400 #套接字服务器套接字的SO_RCVBUF缓冲区。如果值为 -1,则将使用OS的
socket.request.max.bytes=104857600 #套接字请求最大字节数,默认100m
socket.send.buffer.bytes=102400 #套接字服务器套接字的SO_SNDBUF缓冲区。如果值为 -1,则将使用 OS
transaction.max.timeout.ms=900000 #事务允许的最大超时时间。如果客户端请求的交易时间超过此时间,则代理将在InitProducerIdRequest中返回错误。这样可以防止客户端超时过大,这可能会使使用者停止读取事务中包含的主题,默认15m
transaction.state.log.num.partitions=50 #事务topic的分区数(部署后不应更改)
transaction.state.log.replication.factor=3 #事务主题的复制因子(设置得更高以确保可用性)。在群集大小满足此复制因子要求之前,内部主题创建将失败
unclean.leader.election.enable=fasle #是否允许将不在 ISR 集中的副本选为领导者作为最后的手段,即使这样做可能会导致数据丢失
zookeeper.connect=localhost:2181
zookeeper.connection.timeout.ms #未配置则使用zookeeper.session.timeout.ms
zookeeper.session.timeout.ms=18000 #zk会话超时时间,默认18s
connections.max.idle.ms=600000 #空闲超时等待,默认600000(10m)
controlled.shutdown.max.retries=3 #故障重试启动次数
controlled.shutdown.retry.backoff.ms=5000 #重试启动间隔,默认5s
log.cleaner.io.buffer.size=524288 #用于所有清理线程的日志清理器 I/O 缓冲区的总内存
log.cleaner.threads=1 #日志清理的后台线程数
max.incremental.fetch.session.cache.slots=1000 #增量提取会话的最大数量
remote.log.manager.thread.pool.size=10 #调度任务用于复制分段、获取远程日志索引和清理远程日志分段的线程池的大小
remote.log.reader.max.pending.tasks=100 #最大远程日志读取器线程池任务队列大小。如果任务队列已满,则提取请求会出错
remote.log.reader.threads=10 #为处理远程日志读取而分配的线程池的大小
security.inter.broker.protocol=PLAINTEXT #访问broker时的协议
PLAINTEXT,明文,默认配置
SSL,ssl加密
SASL_PLAINTEXT,使用简单认证和安全层(SASL)的明文传输协议。SASL 是一种用于身份验证和安全通信的框架,可以在明文传输的基础上提供一定的安全性。需要配置用户名和密码等认证信息
SASL_SSL,使用 SASL 和 SSL/TLS 加密传输协议。这是最安全的配置项,同时使用了身份验证和加密传输,适用于对数据安全性要求非常高的生产环境
socket.listen.backlog.size=50 #套接字上挂起的最大连接数。还需要配置系统somaxconn、tcp_max_syn_backlog内核参数才能使配置生效
ssl.client.auth=认证方法 #与kafka交互时,访问的方法
required,必须验证客户端身份
requested,非强制认证客户端身份
none,不验证客户端
ssl.keystore.type=JKS 秘钥格式
JK
PKCS12
PEM
ssl.keystore.certificate.chain=证书
ssl.keystore.key=key文件
ssl.key.password=key文件的密码
min.insync.replicas=1 #当生产者将 acks 设置为“all”(或“-1”)时,此配置指定必须确认写入才能被视为写入成功的最小副本数。如果无法满足此最小值,则生产者将引发异常(NotEnoughReplicas 或 NotEnoughReplicasAfterAppend)。此配置为2,acks 为“all”生成。这将确保生产者在大多数副本未收到写入时引发异常
segment.ms=604800000 #控制Kafka在多长时间后强制滚动日志,即使段文件未满,也可确保保留期可以删除或压缩旧数据
group.initial.rebalance.delay.ms=0 #设置消费者组初始重新平衡的延迟时间,影响消费者组的启动和分区分配的时间。当一个新的消费者加入消费者组或者消费者组中的消费者发生变化时,Kafka会触发重新平衡操作,重新分配分区给消费者
服务故障解决
先尝试重新启动一下,如果能启动正常,那直接解决。
如果重启不行,考虑增加内存、增加CPU、网络带宽。
如果将kafka整个节点误删除,如果副本数大于等于2,可以按照服役新节点的方式重新服役一个新节点,并执行负载均衡
集群数据迁移/备份
迁移参考博客:https://www.cnblogs.com/smartloli/p/10551165.html
备份参考博客:https://cloud.tencent.com/developer/article/2315378
例:备份脚本
#!/bin/bash
bak_topic=test
bak_dir=/tmp/bak
bak_file=$bak_dir/${bak_topic}.txt
bak(){
install -d $bak_dir
kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic $bak_topic \
--from-beginning \
> $bak_dir/${bak_topic}.txt
}
recover(){
kafka-console-producer.sh \
--broker-list localhost:9092 \
--topic $bak_topic \
--new-producer \
< $bak_file
}
kafka提升吞吐量
分区数一般设置为:3-10个
- 提高生产者吞吐量,从buffer、延迟、压缩等着手
- 增加消费者处理能力
- 增加partition,副本数增大,确保最小副本数大于2。分区数不是越多越好,也不是越少越好,需要搭建完集群,进行压测,再灵活调整分区个数
关于分区数压测
- 创建一个只有1个分区的topic。
- 测试这个topic的producer吞吐量和consumer吞吐量。
- 假设他们的值分别是Tp和Tc,单位可以是MB/s。
- 然后假设总的目标吞吐量是Tt,那么:分区数 = Tt / min(Tp,Tc)
例:
producer吞吐量 = 20m/s;consumer吞吐量 = 50m/s,期望吞吐量100m/s;
分区数 = 100 / 20 = 5分区
压测
生产者压测
#创建test主题,设3分区3副本
kafka-topics.sh --bootstrap-server 2.2.2.55:9092 --create --replication-factor 1 --partitions 3 --topic test
#每条消息1k,发100w条,不做限流,batch为32k,缓存为64m
kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=2.2.2.55:9092 batch.size=32768 linger.ms=0 buffer.memory=3221225472
消费者压测
kafka-consumer-perf-test.sh --bootstrap-server 2.2.2.55:9092 --topic test --messages 1000000 --consumer.config config/consumer.properties

 浙公网安备 33010602011771号
浙公网安备 33010602011771号