mysql高可用Galera Cluster集群
Galera Cluster:
集成了Galera插件的MySQL集群,是一种新型的,数据不共享的,高度冗余的高可用方案,目前Galera Cluster有两个版本,分别是Percona Xtradb Cluster及MariaDB Cluster
Galera本身是具有多主特性的,即采用multi-master的集群架构,是一个既稳健,又在数据一致性、完整性及高性能方面有出色表现的高可用解决方案
官方文档:
#提供mysql、mariadb、xtradb三种galera cluster集群安装文档
https://galeracluster.com/library/documentation/install.html
#pxc官方
https://www.percona.com/doc/percona-xtradb-cluster/LATEST/index.html
#mariadb galera cluster官方
https://mariadb.com/kb/en/library/getting-started-with-mariadb-galera-cluster/
说明:
- 至少3台主机。并且不能安装mysql-server、mariadb-server,只能用 cluster版
基于wresp协议的复制:
- percona-cluster
- mariadb-cluster
特点:
- 多主架构:真正的多点读写的集群,在任何时候读写数据,都是最新的
- 同步复制:集群不同节点之间数据同步,没有延迟,在数据库挂掉之后,数据不会丢失
- 并发复制:从节点APPLY数据时,支持并行执行,更好的性能
- 故障切换:在出现数据库故障时,因支持多点写入,切换容易
- 热插拔:在服务期间,如果数据库挂了,只要监控程序发现的够快,不可服务时间就会非常少。在节点故障期间,节点本身对集群的影响非常小
- 自动节点克隆:在新增节点,或者停机维护时,增量数据或者基础数据不需要人工手动备份提供,Galera Cluster会自动拉取在线节点数据,最终集群会变为一致
- 对应用透明:集群的维护,对应用程序是透明的
缺点:
- 由于DDL需全局验证通过,则集群性能由集群中最差性能节点决定(一般集群节点配置都是一样的)
- 新节点加入或延后较大的节点重新加入需全量拷贝数据(SST,State Snapshot Transfer),作为donor(贡献者,如:同步数据时的提供者)的节点在同步过程中无法提供读写
- 只支持innodb存储引擎的表
galera cluster工作原理:
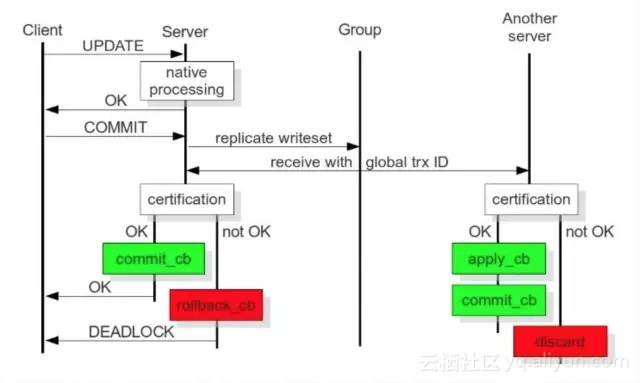
- A、B两台主机,当客户端发起修改请求,A主机接收并执行sql操作,完成后返回客户端一个OK结果,客户端看到OK结果后,提交事务(commit),但此时并没有真的将事务提交并同步磁盘,而是进行事物验证
- A收到事务提交后,不会立即返回事务提交成功结果,而是把sql执行产生的数据,复制到B(若有其他集群节点也是依次复制)
- B主机同时检查该sql是否在本机运行并产生数据,全局事务ID是否冲突(也就是集群中所有节点检查事物ID),所有节点检查完成后,没有问题,A才会返回成果结果
两个关键组件:
Galera replication library 启用写集复制服务功能
WSREP api 复制提供程序,与数据库服务器引擎集成,以实现写集复制
mysql版下载地址: https://releases.galeracluster.com/
mariadb版官方文档对应:https://mariadb.com/kb/en/getting-started-with-mariadb-galera-cluster/

PXC(Percona Xtradb Cluster):
PXC常用4个端口号:
| 端口 | 说明 |
|---|---|
| 3306 | 数据库对外服务的端口号 |
| 4444 | 请求SST的端口号,全量数据传输(全量备份) |
| 4567 | 组成员之间进行沟通的端口号 |
| 4568 | 传输IST的端口号,增量数据传输(增量备份) |
PXC原理
等同于上面的galera cluster原理,毕竟PXC只是做了补丁开发,但在网上看到这个图清晰一点就贴一下
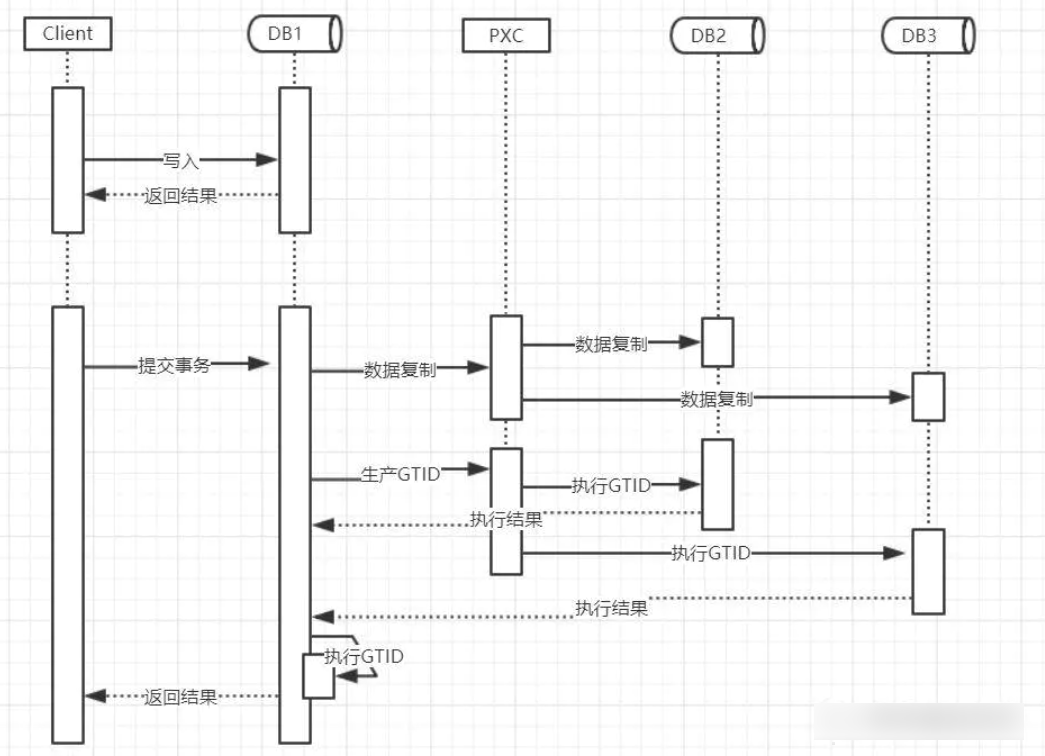
PXC中涉及到的重要概念和核心参数:
(1)集群中节点的数量:
整个集群中节点数量应该控制在最少3个、最多8个的范围内。脑裂现象的标志就是输入任何命令,返回的结果都是unknown command。
节点在集群中,会因新节点的加入或故障、同步失效等原因发生状态的切换。
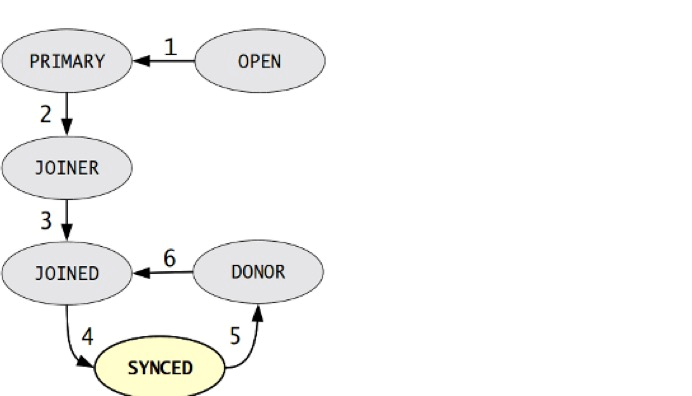
(2)节点状态的变化阶段:
open-->primary-->joiner-->joined-->synced-->donor-->joined(循环最后3步)
- open: 节点启动成功,尝试连接到集群时的状态
- primary:节点已处于集群中,在新节点加入并选取donor进行数据同步时的状态
- joiner: 节点处于等待接收,同步文件时的状态
- joined:节点完成数据同步工作,尝试保持和集群进度一致时的状态
- synced:节点正常提供服务时的状态,表示已经同步完成并和集群进度保持一致
- donor: 节点处于为新加入的节点提供全量数据时的状态
(3)节点的数据传输方式:
SST: State Snapshot Transfer,全量数据传输
IST: Incremental State Transfer,增量数据传输
注意:
- SST数据传输有xtrabackup、mysqldump和rsync三种方式
- IST数据传输就只有一种方式xtrabackup,生产环境中一般数据量较小时,可以使用SST全量数据传输,但也只使用xtrabackup方法
(4)GCache模块:
在PXC中一个特别重要的模块,它的核心功能就是为每个节点缓存当前最新的写集
如果有新节点加入进来,就可以把新数据的增量传递给新节点,而不需要再使用SST传输方式,这样可以让节点更快地加入集群中
停机时需要注意的点:
避免全部节点挂掉后出现SST:
当全部节点挂掉后,gcache数据会丢失,所以需要停机时,必须保证有一个节点是运行的,正确的停机顺序是:
#单个停机修复顺序
节点1停机,修复完后加入 --> 节点2停机,修复后加入 --> 节点3停机,修复后加入
#全部停机修复顺序(数据库关闭之后,最会保存一个last Txid,所以启动时,先要启动最后一个关闭的节点)
关闭:节点1停 --> 节点2停 --> 节点3停
启动:节点3起 --> 节点2起 --> 节点1起
配置参数:
gcache.size #缓存写集增量信息的大小,它的默认大小是128MB,通过wsrep_provider_options参数设置,建议调整为2GB~4GB范围,足够的空间便于缓存更多的增量信息,若要停机一小时,需要确认1小时内产生多大的binlog来算出参数大小
gcache.mem_size #GCache中内存缓存的大小,适度调大可以提高整个集群的性能
gcache.page_size #如果内存不够用(GCache不足),就直接将写集写入磁盘文件中
配置文件解读:
wsrep.cnf文件
wsrep_provider #指定Galera库的路径
wsrep_cluster_name #Galera集群的名称
wsrep_cluster_address #集群中各节点地址。地址使用组通信协议
gcomm://ip1,ip2 用于工作实现的选项
dummy:// 用于运行测试和分析,不执行任何实际复制,并且忽略以下所有参数
wsrep_node_name #本节点在集群中的名称
wsrep_node_address #本节点在集群中的通信地址
wsrep_sst_method #SST使用的传输方法有mysqldump、rsync和xtrabackup,前两者在传输时都需要对Donor加全局只读锁(FLUSH TABLES WITH READ LOCK),xtrabackup则不需要(它使用percona自己提供的backup lock)。强烈建议采用xtrabackup
wsrep_sst_auth #在SST传输时的用户密码,为:"用户:密码"
pxc_strict_mode #是否限制PXC启用正在试用阶段的功能,ENFORCING是默认值,表示不启用
binlog_format #二进制日志的格式。Galera只支持row格式的二进制日志
default_storage_engine #指定默认存储引擎。Galera的复制功能只支持InnoDB
innodb_autoinc_lock_mode #只能设置为2,设置为0或1时会无法正确处理死锁问题
wsrep_recover #1为开启,用于从log中分析gtid
集群中加入新节点为两种情况:
新节点加入集群:
新节点加入集群时,需要从当前集群中选择一个Donor节点来同步数据,也就是所谓的SST过程。SST同步数据的方式由选项wsrep_sst_method决定,一般是xtrabackup
注意:
- 新节点加入Galera时,会删除新节点上所有已有数据,再通过xtrabackup(假设使用的是该方式)从Donor处完整备份所有数据进行恢复。所以,如果数据量很大,新节点加入过程会很慢。而且,在一个新节点成为Synced状态之前,不要同时加入其它新节点,否则很容易将集群压垮。
- 如果是这种情况,可以考虑使用wsrep_sst_method=rsync来做增量同步(导出集群中一部分数据,然后在新节点导入),既然是增量同步,最好保证新节点上已经有一部分数据基础,否则和全量同步没什么区别,且这样会对Donor节点加上全局只读锁
旧节点加入Galera集群
旧节点加入Galera集群,说明这个节点在之前已经在Galera集群中呆过,有一部分数据基础,缺少的只是它离开集群时的数据。这时加入集群时,用IST传输机制,即增量传输
注意:
- 这部分增量传输的数据源是Donor上缓存在GCache文件中的,这个文件有大小限制,如果缺失的数据范围超过已缓存的内容,则自动转为SST传输(参考前面Gcache的原因)
- 如果旧节点上的数据和Donor上的数据不匹配(例如这个节点离组后人为修改了一点数据),则自动转为SST传输。
有时间再整理部署过程
Mariadb Galera Cluster:
与PXC类似,毕竟都是做补丁开发,所以只做部署部分,了解详情看官方文档
文档: https://galeracluster.com/library/documentation/install-mariadb.html
3个工具脚本:
/usr/bin/clustercheck #集群节点状态检查,需要配置/etc/sysconfig/clustercheck文件,指定MYSQL_USERNAME、MYSQL_PASSWORD
/usr/bin/galera_new_cluster #初始化集群,只用在一个节点执行
/usr/bin/galera_recovery #用于从非正常关机中恢复,获取最后存储的全局事务ID,进行回显
安装:
| 主机 | 说明 |
|---|---|
| 2.2.2.12 | PXC1、A主机、centos8 |
| 2.2.2.22 | PXC2、B主机、centos8 |
| 2.2.2.32 | PXC3、C主机、centos8 |
1)所有主机操作
dnf install mariadb-server-galera -y
vim /etc/my.cnf.d/galera.cnf
wsrep_cluster_address="gcomm://2.2.2.12,2.2.2.22,2.2.2.32"
2)在A主机执行初始化
galera_new_cluster
3)在B、C主机启动mariadb
systemctl start mariadb.service
tai -f /var/log/mariadb/mariadb.log
4)验证集群状态
mysql
-->SHOW VARIABLES LIKE 'wsrep_%'\G;
SHOW STATUS LIKE 'wsrep_%';
create database t1;
grant all on *.* to root@'%' identified by '123';
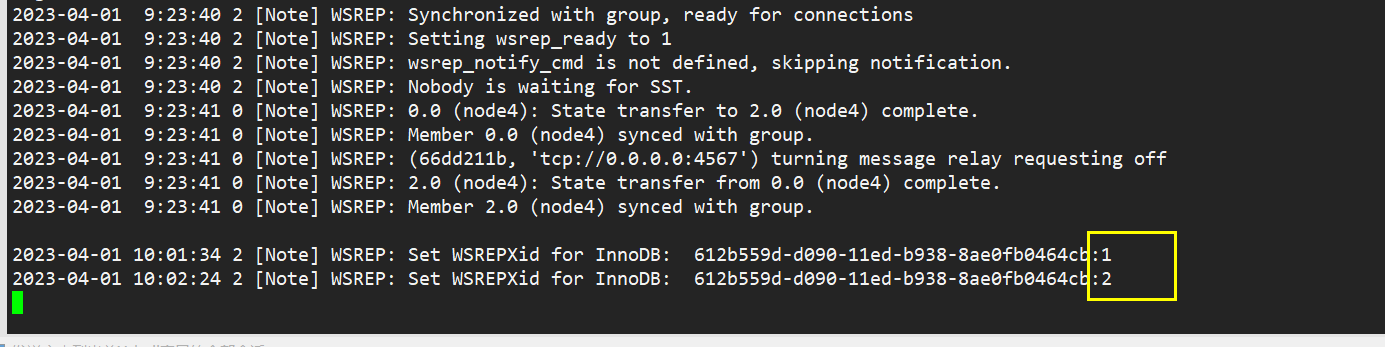
集群新加了两条新数据,日志中显示记录

 浙公网安备 33010602011771号
浙公网安备 33010602011771号