mysql主从复制
主从复制:
主从复制架构和原理:
master节点挂掉时,slave节点上位
在数据架构中:主负责写操作,从负责读操作
架构:
- MASTER/SLAVE
- 一主多从
- 一主一从,从连接多从(级联复制)
- master/master(双主,实际为一主一从互补)
MySQL的扩展:
- 读写分离
- 复制:每个节点都有相同的数据集,向外扩展,基于二进制日志的单向复制
复制的功用:
- 数据分布
- 负载均衡读操作
- 备份
- 高可用和故障切换
- MySQL升级测试
原理:
中继日志(relay log)在每次复制完成后,会自动清理内容
- master节点的二进制日志变更后,被salve服务(dump线程)捕捉到,然后dump线程发送给从节点
- slave节点会开一个io线程,该线程负责接收二进制日志,保存到本地并改名为:relay log文件,mysql服务会通过自己的sql线程,读取该二进制文件并执行,做数据更新
- slave节点,在执行接收过来的relay log内容时,并不会把执行记录写入到自己的二进制日志中去。自己的二进制日志只会记录: 客户端用户修改slave本地数据的记录
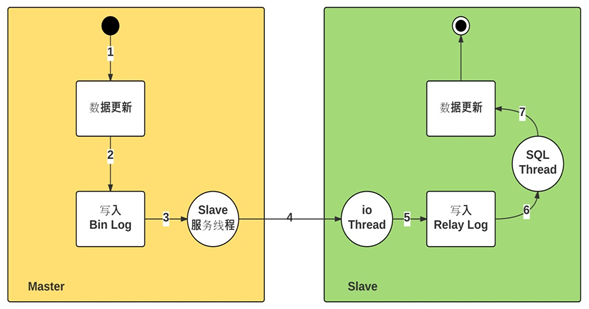
主从复制相关线程
主节点:
- dump-Thread:为每个Slave的I/O Thread启动一个dump线程,用于向其发送binary log-events
从节点:
- I/O-Thread:向Master请求二进制日志事件,并保存于中继日志中
- SQL-Thread:从中继日志中读取日志事件,在本地完成重放
跟复制功能相关的文件:
master.info:
- 保存slave连接至master时的相关信息,如账号、密码、服务器地址等
relay-log.info:
- 保存在当前slave节点上已经复制的当前二进制日志和本地relay log日志的对应关系
mariadb-relay-bin.00000#:
- 中继日志,保存从主节点复制过来的二进制日志,本质就是二进制日志
主从复制特点:
异步复制,可能导致数据不一致(常见)
复制需要考虑二进制日志事件记录格式
STATEMENT(5.0之前) 语句型容易数据丢失,早期版本默认
ROW(5.1之后,推荐) 数据行型,mysql8.0默认
MIXED 至少是混合型,新版默认
主从复制配置:
主节点配置:
官方链接: https://mariadb.com/kb/en/library/server-system-variables/
服务配置文件
[mysql]
log-bin
server-id=1 #必须参数,主机唯一标识符
log-basename=master #可选参数,二进制日志的前缀名
sync_binlog=0 #二进制日志异步写磁盘
innodb_flush_log_at_trx_commit=2 #二进制日志记录模式改成数据型
sync_master_info=# #几次事件后master.info同步到磁盘
innodb_support_xa=ON #分布式事务MariaDB10.3.0废除
expire_logs_days=10 #二进制日志自动清除时间,默认10天清理一次
max_binlog_size=1073741824 #二进制日志多大就滚动一次
server-id参数说明:
- 1~4294967295 (>= MariaDB 10.2.2),默认值为1
- 0~4294967295 (<= MariaDB 10.2.1),默认为0。0时拒绝所有slave连接
- 每个主机必须不同,否则冲突
创建一个有复制权限的用户账号
grant replication slave,replication client on *.* to 'repluser'@'%' identified by '123456';
从节点配置:
启动中继日志:
[mysqld]
server-id=2
log-bin #可选,开始是为了方便成为master
read-only=on #设置从节点数据只读(可用于读写分离),对超级用户无效
relay-log=relay #可选项,relay log的前缀名,默认为: 主机名-relay-bin
relay-log-index=relay.index #日志索引的文件名,默认:主机名-relay-bin.index
skip-slave-start=ON #不自动启动slave
sync_relay_log=次数 #几次写后同步relay log到磁盘
sync_relay_log_info=次数 #几次事务后同步relay-log.info到磁盘
连接主节点的数据库
使用有复制权限的账号连接到master、启动复制线程
#连接master节点
change master to MASTER_HOST='主服务器地址',
MASTER_USER='账号',
MASTER_PASSWORD='密码',
MASTER_LOG_FILE=‘master的二进制日志’',
MASTER_LOG_POS=字节位置;
#启动从节点同步
START SLAVE [IO_THREAD|SQL_THREAD];
#关闭从节点同步
stop slave 停止线程
#显示主从同步状态信息
SHOW SLAVE STATUS;
注意:
第一次使用时,要手动启动io、sql线程
start slave [in_thread | sql_thread]; 不指定时全部启动
show slave status;
从节点清除主从信息:
RESET SLAVE #从服务器清除master.info ,relay-log.info, relay log ,开始新的relay log
RESET SLAVE ALL #清除所有从服务器上设置的主服务器同步信息,如HOST,PORT,USER和PASSWORD等
start slave语句,定点执行
START SLAVE [thread_types]
START SLAVE [SQL_THREAD] UNTIL
MASTER_LOG_FILE = 'log_name', MASTER_LOG_POS = log_pos
START SLAVE [SQL_THREAD] UNTIL
RELAY_LOG_FILE = 'log_name', RELAY_LOG_POS = log_pos
thread_types:
[thread_type [, thread_type] ... ]
thread_type: IO_THREAD | SQL_THREAD
主从同步状态的关键输出信息:
| 信息 | 说明 |
|---|---|
| Slave_IO_Running | IO线程状态 |
| Slave_SQL_Running | sql线程状态 |
| Seconds_Behind_Master | 主从之间复制的延时,null未进行,0为已经完成 |
| Read_Master_Log_Pos | 读取的主节点的二进制日志的最新位置。上任时要在多台slave中选最新的上任 |
| Last_SQL_Errno | sql执行错误的错误码 |
主从复制搭建遇到错误的解决方法
可以在从服务器忽略几个主服务器的复制事件,此为global变量,或指定跳过事件的ID
注意:
- Centos 8.1以上版本上主从节点同时建同名的库和表不会冲突,建主键记录会产生冲突
- CentOS7上Mariadb 5.5在slave创建库和表,再在master上创建同名的库和表,会出现复制冲突
- 如果添加相同的主键记录都会冲突
#系统变量,指定跳过复制事件的个数
SET global sql_slave_skip_counter = N
#服务器选项,只读系统变量,指定跳过事件的ID
[mysqld]
slave_skip_errors=1007|ALL
主从复制的监控和维护:
清理日志:
PURGE { BINARY | MASTER } LOGS { TO 'log_name' | BEFORE datetime_expr }
RESET MASTER TO # #mysql 不支持。二进制文件编号起点
RESET SLAVE [ALL]
复制监控(状态):
SHOW MASTER STATUS
SHOW BINARY LOGS
show master logs;
SHOW BINLOG EVENTS
SHOW SLAVE STATUS
SHOW PROCESSLIST
从服务器是否落后于主服务:
show slave status\G;
Seconds_Behind_Master:0 #0为完全相同
检查主从节点数据是否一致:
使用percona-toolkit工具检查
不完整时,一般建议删除从数据库,重新复制
主从复制的问题和解决方案:
数据损坏或丢失解决方法:
- Master节点: MHA + semisync replication
- Slave: 重新复制
不惟一的server id:
- 重新复制
混合使用存储引擎(杜绝)
复制延迟解决:
- 需要额外的监控工具的辅助
- 一从多主: mariadb10 版后支持
- 多线程复制: 对多个数据库复制,依赖于GTID,版本>5.6。可参考文章:并行复制方案
- 网络延迟: 增加网络带宽
- 数据库负载太高:主库的话换更高硬件配置,或采用中继节点同步,缓解主库压力(或者在部署主从库时就修改系统大内存页,尽量提高数据库tps)。从库的话可关闭二进制日志,缓解磁盘io压力,或修改日志刷写磁盘的模式
- 慢sql引起或大事物引起:从库在一段时间内Relay_Master_Log_File , Exec_Master_Log_Pos没有变化,如果是慢sql引起除了优化sql外就没其他办法了。大事物则应该拆开,分开执行
- 表上无索引,且二进制日志格式为row: 表现为一段时间内,Relay_Master_Log_File , Exec_Master_Log_Pos不会变化。如果表上没有任何索引,对它进行操作,在主库上只是一次全表扫描。但在从库重放时,因为是 ROW格式,对于每条记录的操作都会进行一次全表扫描,所以应该在从库上临时创建个索引,加快记录的重放(尽量选择一个区分度高的列添加索引,列的区分度越高,重放的速度就越快)。并且将参数slave_rows_search_algorithms 设置为 INDEX_SCAN,HASH_SCAN
造成主从不一致的原因:
- 主库binlog格式为sql语句型,同步到从库执行后可能造成主从不一致
- 主库执行更改前有执行set sql_log_bin=0,会使主库不记录binlog,从库也无法变更这部分数据
- 从节点未设置只读,误操作写入数据
- 主库或从库意外宕机,宕机可能会造成binlog或者relaylog文件出现损坏,导致主从不一致
- 主从实例版本不一致,特别是高版本是主,低版本为从的情况下,主数据库上面支持的功能,从数据库上面可能不支持该功能
- MySQL自身bug导致
主从不一致修复方法:
从库重建:
- 这个方案恢复时间比较慢,而且有时候从库也是承担一部分的查询操作的,不能贸然重建
使用percona-toolkit工具辅助:
- PT工具包中包含pt-table-checksum和pt-table-sync两个工具,主要用于检测主从是否一致以及修复数据不一致情况。这种方案优点是修复速度快,不需要停止主从辅助,缺点是需要知识积累,需要时间去学习,去测试,特别是在生产环境,还是要小心使用
- 关于使用方法,可以参考下面链接:https://www.cnblogs.com/feiren/p/7777218.html
手动重建不一致的表:
- 在从库发现某几张表与主库数据不一致,而这几张表数据量也比较大,手工比对数据不现实,并且重做整个库也比较慢,这个时候可以只重做这几张表来修复主从不一致
- 这种方案缺点是在执行导入期间需要暂时停止从库复制,不过也是可以接受的
例: A,B,C这三张表主从数据不一致
1)从库停止Slave复制
2)在主库上dump这三张表,并记录日志名、位置
mysqldump -q --single-transaction --master-data=2 testdb A B C >/backup/A_B_C.sql
grep MASTER_LOG_FILE /backup/A_B_C.sql
3)把A_B_C.sql拷贝到Slave机器上,并指定位置启动
只恢复到备份时的位置,备份时间后面的不管
start slave until MASTER_LOG_FILE='mysql-bin.888888',MASTER_LOG_POS=666;
4)从库还原数据
mysql
->set sql_log_bin=0;
\. /backup/A_B_C.sql
set sql_log_bin=1;
start slave;
避免主从不一致的方法:
- 主库binlog采用ROW格式
- 主从实例数据库版本保持一致
- 主库做好账号权限把控,不可以执行set sql_log_bin=0
- 从库开启只读,不允许人为写入
- 定期进行主从一致性检验

 浙公网安备 33010602011771号
浙公网安备 33010602011771号