

接口实战:登录古诗文网站(有验证码)
一、先找到网页的接口:使用假的密码登录,找到登录的接口
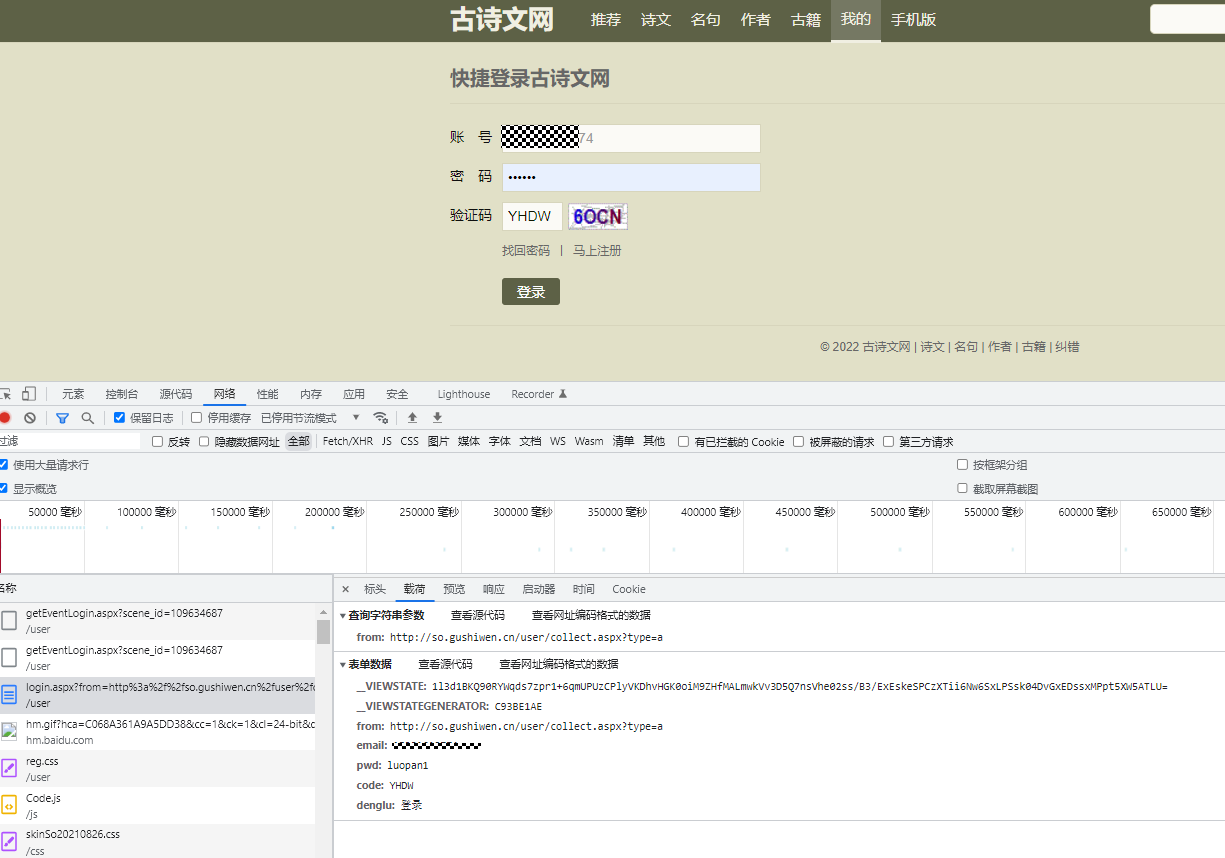
2、分析参数:有以下6个参数,经过分析 只需要获取这两个参数即可:__VIEWSTATE、code。
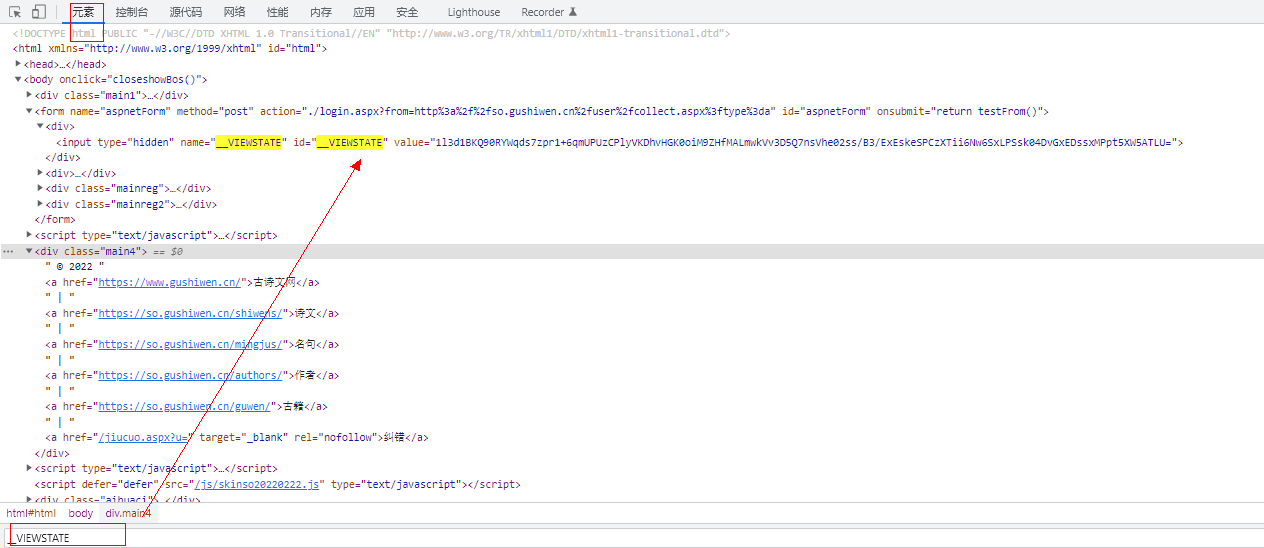
__VIEWSTATE参数可以直接获取截取:
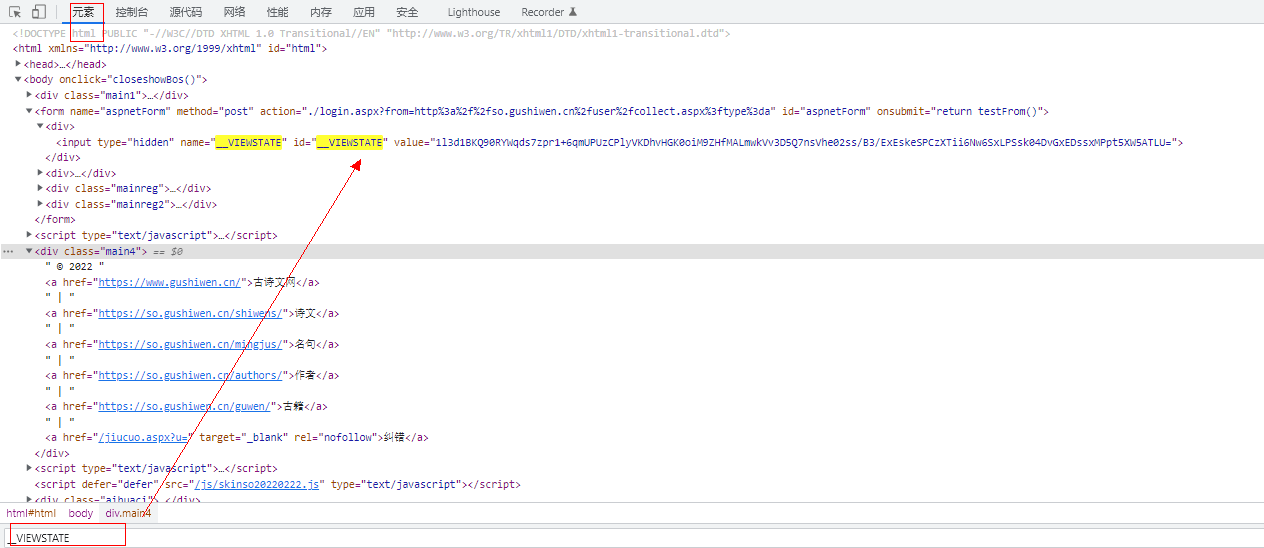
而code是验证码需要去识别:
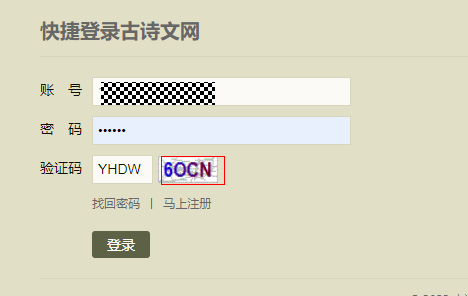
3、首先获取 __VIEWSTATE
import requests
from lxml import etree
import re
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36", }
session = requests.Session() # 创建session对象
# 第一次使用session,捕获请求cookie
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
page_text = session.get(url = url,headers = headers).text
tree = etree.HTML(page_text)
# 获取'__VIEWSTATE (截取数据两种办法)'和'__VIEWSTATEGENERATOR'
# VIEWSTATE = tree.xpath('//input[@id="__VIEWSTATE"]/@value')[0] #方法一 html调取
VIEWSTATE=re.findall('id="__VIEWSTATE" value="(.+?)"',page_text)[0] #方法二 截取
VIEWSTATEGENERATOR = tree.xpath('//input[@id="__VIEWSTATEGENERATOR"]/@value')[0]
4、解析验证码
# 解析验证码图片地址
img_src = 'https://so.gushiwen.cn/' + tree.xpath('//*[@id="imgCode"]/@src')[0]
# 将验证码图片保存到本地
img_data = session.get(img_src,headers = headers).content
with open('./code.png','wb') as fp:
fp.write(img_data)
# 解析验证码图片
from PIL import Image,ImageEnhance
import pytesseract
import os
#图片处理
im=Image.open('./code.png')
#PIL有九种不同模式: 1,L,P,RGB,RGBA,CMYK,YCbCr,I,F。
tesseract_cmd = 'C:\\Users\\l84196880\AppData\\Local\\Tesseract-OCR\\tesseract-uninstall.exe' #此需下载
# 下面为增强部分
im= im.convert("YCbCr")
enh_con = ImageEnhance.Contrast(im)
contrast = 1.5
image_contrasted = enh_con.enhance(contrast)
# 增强亮度
enh_bri = ImageEnhance.Brightness(image_contrasted)
brightness = 1.5
image_brightened = enh_bri.enhance(brightness)
# image_brightened.show()
# 增强对比度
enh_col = ImageEnhance.Color(image_brightened)
color = 1.5
image_colored = enh_col.enhance(color)
# image_colored.show()
# 增强锐度
enh_sha = ImageEnhance.Sharpness(image_colored)
sharpness = 3.0
image_sharped = enh_sha.enhance(sharpness)
# image_sharped.show()
# 灰度处理部分
im2 = image_sharped.convert("L")
# im2.show()
code_text = pytesseract.image_to_string(im2,lang='eng').strip() # 使用image_to_string识别验证码
print(code_text)
code_text = code_text.replace("\n","") #解析了验证码
#验证码图片重命名
src = os.path.join(os.path.abspath("./"), 'code.png')
dst = os.path.join(os.path.abspath("./"), code_text[0:4] + '.png')
os.rename(src, dst)
5、模拟登陆
# 流程:1 对点击登录按钮对应的请求进行发送(post请求)
# 2 处理请求参数:
# 用户名 密码 验证码 其他防伪参数
login_url = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data = {
'__VIEWSTATE': VIEWSTATE,
'__VIEWSTATEGENERATOR': 'C93BE1AE',
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': '15281619774', # 更换自己的用户名
'pwd': 'luopan', # 更换自己的密码
'code': code_text,
'denglu': '登录'
}
# 对点击登录按钮发起请求,获取登录成功后对应的页面源码数据,保存为网页
page_text_login = session.post(url = login_url,data = data,headers = headers).text
with open('./gushiwen.html','w',encoding = 'utf-8') as fp:
fp.write(page_text_login)
#如果登录成功则删除图片
if page_text_login.find(u"已绑定") !=-1: #登录成功
os.remove("./"+ code_text[0:4] + '.jpg')
return "登录成功"
else :
return "登录失败"
os.remove("./" + " .jpg")
if __name__ == "__main__":
r = 0
while xxxx() == "登录失败" :
r +=1
print(r)以上的代码合起来即可。

