DAGScheduler stage 划分算法
DAGScheduler stage 划分算法
stage划分算法很重要,对于spark开发人员来说,必须对stage划分算法很清晰,知道自己编写的spark Application被划分成了几个job,每个job被划分成了几个stage,每个stage包括哪些代码,这样当发现哪个stage报错或者执行特别慢,才能针对对应代码排查问题和性能调优
stage 划分思想:
由submitStage() 和getMissingParentStage() 组成
会从触发Action操作的那个RDD开始往前,首先为最后一个RDD创建一个stage,然后在往前,如果遇到某个RDD是宽依赖,就会为宽依赖创建一个新的stage,新的RDD就是最新的stage的最后一个RDD,然后以依次类推,继续往前,根据宽依赖或者窄依赖进行stage划分,知直到最后一个RDD遍历完为止
stage划分步骤:
1、使用出发job的最后一个RDD,创建finalStage(创建一个stage对象,并且将stage加入到DAGScheduler内部的内存缓存中)
2、使用finalStage创建一个job(这个job的最后一个stage,就是 finalStage)
3、将job加入到内存缓存中
4、使用 submitStage() 提交 finalStage
提交stage的方法(stage划分算法入口):
调用 getMissingParentStage() 获取当前这个 stage 的父 stage:
往栈中推入stage的最后一个RDD
while循环对stage的最后一个RDD,调用自己定义的visit()方法
visit():如果是窄依赖,将RDD放入栈中,如果是宽依赖,使用宽依赖的那个RDD创建一个stage,将isShuffleMap设为true
提交stage,为stage创建一批task,task数量与Partition数量相同
计算每个task对应的Partition的最佳位置(就是从stage最后一个RDD开始,去找被cache或checkpoint的RDD的Partition,task的最佳位置,就是该Partition的位置,这样task就在那个节点上执行,不需要计算之前的RDD;如果从最后一个RDD到最开始的RDD,都没有被cache或checkpoint,那么最佳位置就是Nil,就是没有最佳位置)
5.、针对stage的task,创建TaskSet对象,调用TaskScheduler的submitTask方法,提交TaskSet,提交到Excutor上去执行
总结如下:
1、从finalstage倒推,
2、通过宽依赖进行新的stage划分
3、使用递归,优先提交父stage
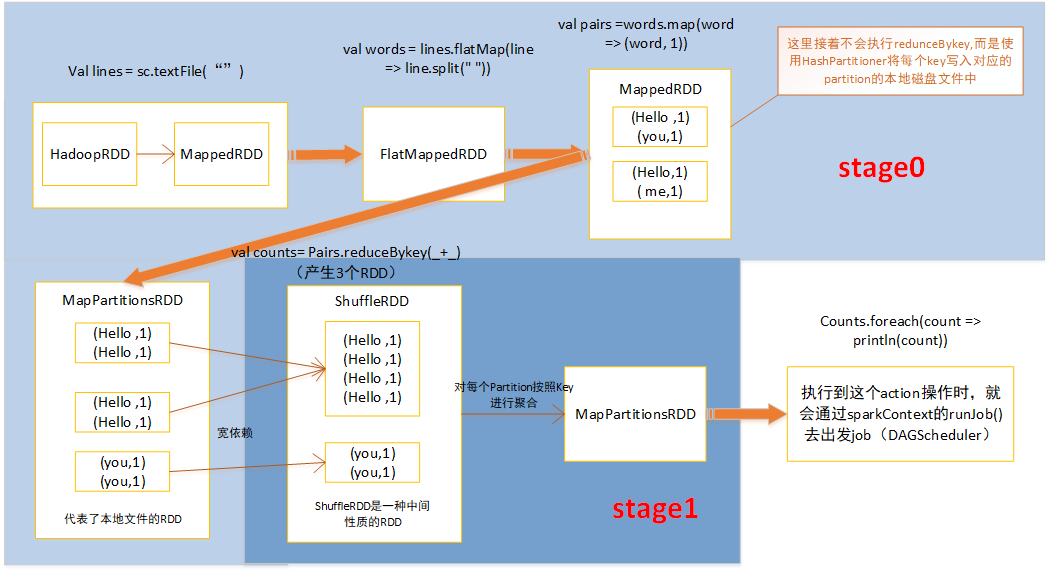
对于每一种有shuffle的操作。底层对应了三个RDD:MapPartitionsRDD、ShuffleRDD、MapPartitionsRDD

 浙公网安备 33010602011771号
浙公网安备 33010602011771号