Hadoop伪分布式安装
一、安装jdk
安装:sudo apt-get install openjdk-7-jdk
配置环境变量:
修改文件 sudo nano /etc/profile , 添加以下内容:

立即执行使之生效:
![]()
二、Hadoop伪分布式
1、下载Hadoop
http://hadoop.apache.org/releases.html
2、解压,目录下几个重要目录
sbin:启动或者停止Hadoop相关服务的脚本
bin:对Hadoop相关服务(HDFS,YARN)进行操作的脚本
etc:Hadoop的配置文件目录
share:Hadoop依赖的jar包和文档,文档可以删掉,jar包不能
lib:Hadoop的本地库(对数据进行压缩解压缩功能的)
3、配置Hadoop伪分布式,修改其中5个配置文件
第一个配置文件Hadoop-env.sh:
![]()
修改如下:
![]()
第二个配置文件core-site.xml:
![]()
配置HDFS的地址、协议、端口号和Hadoop运行时产生数据的存储目录,不临时数据
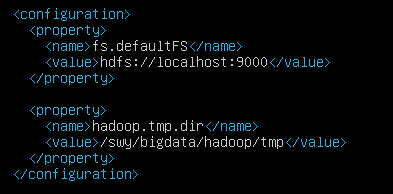
第三个配置文件hdfs-site.xml:
![]()
指定HDFS数据副本数存储量,由于是伪分布式,只有一台机器,所以value为1

第四个配置文件:
重命名:
![]()
![]()
指定mapreduce编程模型运行在yarn之上

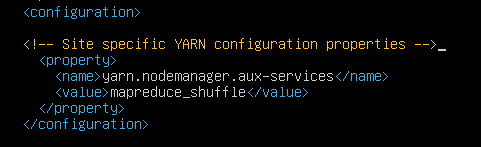
第五个配置文件yarn-site.xml:
![]()
参数解释https://blog.csdn.net/xiaoshunzi111/article/details/51221139
默认参数http://hadoop.apache.org/docs/r2.4.1/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
mapreduce执行shuffle时获取数据的方式
4、配置Hadoop环境变量
![]()
添加
![]()
执行
![]()
5、配置ssh免密码
这是单机模式下的,相当于自己访问自己
方法一:
(在输入下面这几个命令之前试过其他方法,遇到很多问题,执行过其他一些操作,最后是找到如下方法操作成功的,但是不知道之前的操作有没有影响)
参考https://blog.csdn.net/budapest/article/details/8022926
生成ssh公钥和私钥
![]()
![]()
![]()
方法二:
(这个方法我没试过,是视频里学的)
命令1:ssh-keygen -t rsa (四个回车)
~/.ssh id-rsa(私钥)、id_rsa.pub(公钥)
命令2:ssh-copy-id localhost
拷贝公钥, ~/.ssh下产生了一个authorized_keys文件,是公钥的配置文件,查看下面两个文件,发现是一样的

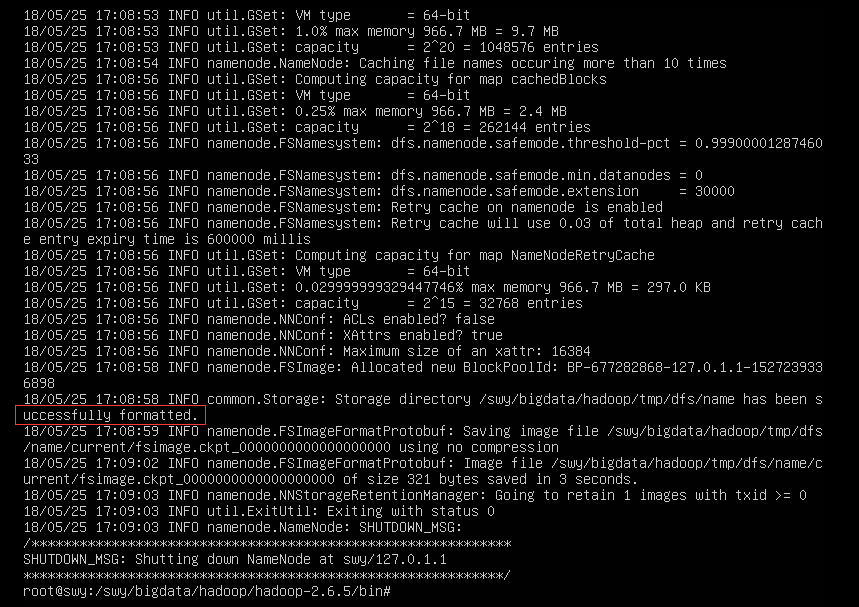
6、格式化hdfs

报如下的错误,检查发现是mapred-site.xml标签</property>少了斜杠

修改再重新执行,成功
7、启动Hadoop
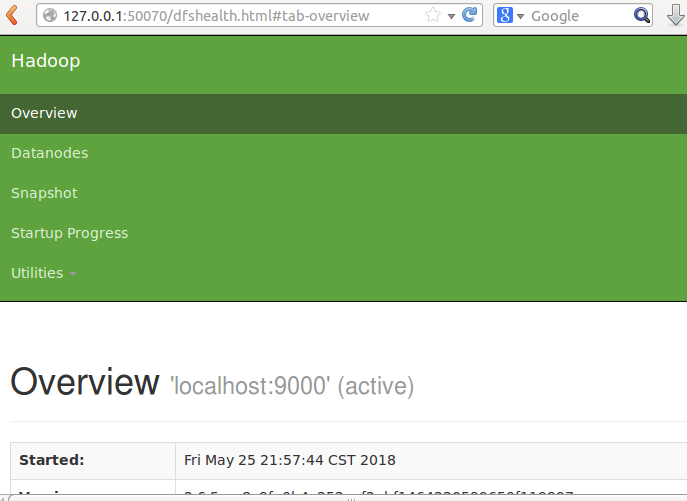
①、启动start-dfs.sh

启动成功

浏览器输入127.0.0.1:50070,进入管理界面:
②、启动start-yarn.sh

下面这几个缺一不可,必须全部启动才算成功
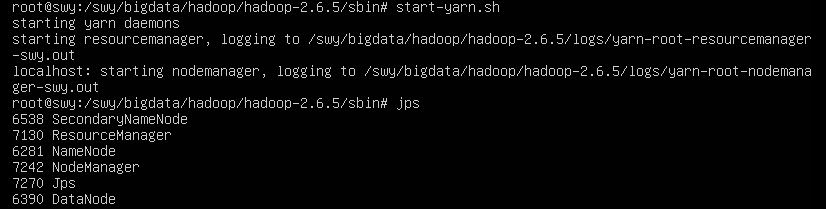
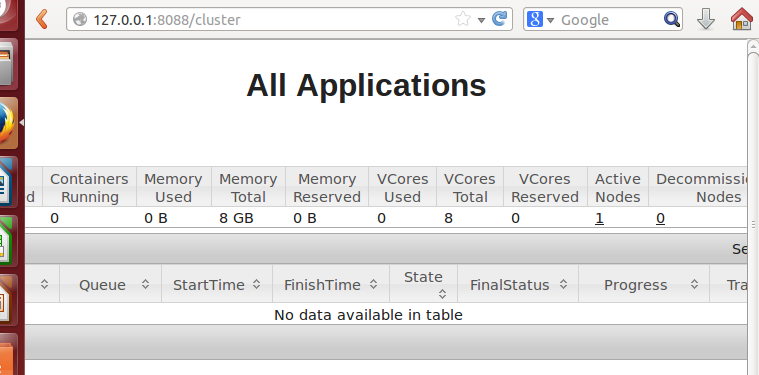
浏览器输入127.0.0.1:8088,进入yarn管理界面

 浙公网安备 33010602011771号
浙公网安备 33010602011771号