jieba 分词个人笔记-使用指南
jieba 分词
官网介绍:
“结巴”中文分词:做最好的 Python 中文分词组件要想用代码看效果,首先,你需要先安装 jieba 模块:
pip3 install jieba
概述-个人理解
jieba 分词,见名知意,其作用就是分词,也就如同生活中的结巴,可以帮我们把大段文本的内容给拆成一个个的词语或者成语等(想想如果你面对的是海量数据,要让你一个个拆词,拆出来,然后再统计出出现频率最高的 100 个词语?你慢慢划,我先玩泥巴去了。)
说实话,你让我分我也分不来,太复杂了,何况是让机器去分,仔细翻了翻文档,发现一堆乱七八糟的数学原理,原来难在实现啊,并不是使用
本文比官网文档冗余多了,只是为了让自己快速了解回顾而作,也推荐你去看【官方文档】
举个例子
来,念一下后面这句话:小明硕士毕业于中国科学院计算所,后在日本京都大学深造
如果你是结巴,可能会念成:小 小明 硕士毕 毕业 于 中国科学 学院 计算所,后在 在日本 京都大学 深 深造
如果是 jieba 分词,可能是这样的结果:小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
上面是 jieba 分词搜索引擎模式的结果,跟结巴,是不是有点像?
别不屑,它支持一些配置,可以让结果更加符合你的预想,也可以过滤一些内容,客官且慢慢往后看
分词原理
参考自:https://blog.csdn.net/weixin_42686879/article/details/89497081
- 利用自带的中文词库,确定汉字之间的关联概率
- 汉字间概率大的组成词组,形成分词结果
除了系统给定分词,还支持用户自定义添加词组
目前 jieba 分词为我们提供了一个 5.07 MB 的词典对应文件,共 349046 行数据,即接近 35万 个词语来匹配
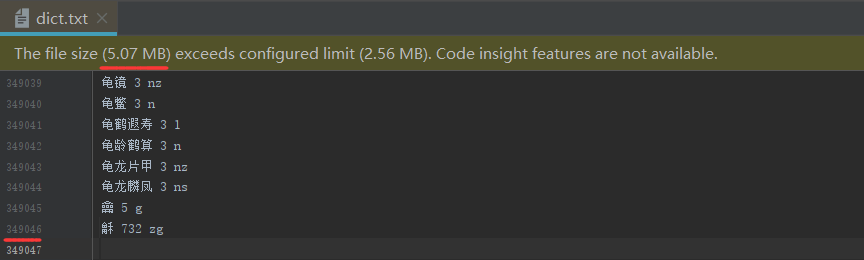
如上图,每行有三个部分,用空格隔开,分别是:词语、词频(可省略)、词性(可省略)
词频省略时使用自动计算的能保证分出该词的词频
可以用来干嘛?
jieba 分词,做的事就是把一堆文本分词(中英文都行),对于分词后的结果,我们可以用来做:词频统计、热点词展示、搜索等等等等(主要我还没遇到对应的业务场景,也举不出来例子)
三种模式
jieba 分词支持三种分词模式:
-
精确模式
jieba.cut("需要分词的文本", cut_all=True)试图将句子最精确地切开,适合文本分析,无冗余
-
全模式
jieba.cut("需要分词的文本", cut_all=False)把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义,存在冗余
-
搜索引擎模式
jieba.cut_for_search("需要分词的文本")在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词,存在冗余
代码示例
# encoding=utf-8
import jieba
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
# 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
# ---->【全模式】
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
# 我/ 来到/ 北京/ 清华大学
# ---->【精确模式】
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print(", ".join(seg_list))
# 他, 来到, 了, 网易, 杭研, 大厦
# ----> 【新词识别】(此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了)
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
# 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
# ----> 【搜索引擎模式】
如果按自己想的去分词-自定义词典
比较常见的就是专业术语?因为比较少见,可能分词对这部分的处理会很不到位
这时候通过自定义词典就可以极大的提高我们的分词准确性了
那么,想要 jieba 分词分出来的词语更加符合自己的预期,我们就可以效仿 jieba 默认提供的分词词典来自定义自己的词典,然后加上 jieba.load_userdict(file_name) 来加载自定义词典
更多可能性-程序中动态修改词典
-
增加词典中的分词:
add_word(word, freq=None, tag=None) -
删除词典中的分词:
del_word(word) -
修改词典中分词语频:
suggest_freq(segment, tune=True)调节单个词语的词频,使其能(或不能)被分出来。
word:自定义的分词,例如:创新办、全日制
freq:词频,可省略
tag:词性,可省略
tune:True,让其能被分出来,False,让其不能备份出来
我们可以搭配上述方法在程序中动态的修改分词词典,让分词结果更加定制化!
案例
未使用时的效果
默认分词代码
# encoding=utf-8
from __future__ import print_function, unicode_literals
import sys
sys.path.append("../")
import jieba
import jieba.posseg as pseg
test_sent = (
"李小福是创新办主任也是云计算方面的专家; 什么是八一双鹿\n"
"例如我输入一个带“韩玉赏鉴”的标题,在自定义词库中也增加了此词为N类\n"
"「台中」正確應該不會被切開。mac上可分出「石墨烯」;此時又可以分出來凱特琳了。"
)
words = jieba.cut(test_sent)
print('/'.join(words))
print("=" * 40)
result = pseg.cut(test_sent)
for w in result:
print(w.word, "/", w.flag, ", ", end=' ')
print("\n" + "=" * 40)
terms = jieba.cut('easy_install is great')
print('/'.join(terms))
terms = jieba.cut('python 的正则表达式是好用的')
print('/'.join(terms))
print("=" * 40)
# test frequency tune
testlist = [
('今天天气不错', ('今天', '天气')),
('如果放到post中将出错。', ('中', '将')),
('我们中出了一个叛徒', ('中', '出')),
]
for sent, seg in testlist:
print('/'.join(jieba.cut(sent, HMM=False)))
word = ''.join(seg)
print('%s Before: %s, After: %s' % (word, jieba.get_FREQ(word), jieba.suggest_freq(seg, True)))
print('/'.join(jieba.cut(sent, HMM=False)))
print("-" * 40)
结果
李小福/是/创新/办/主任/也/是/云/计算/方面/的/专家/;/ /什么/是/八/一双/鹿/
/例如/我/输入/一个/带/“/韩玉/赏鉴/”/的/标题/,/在/自定义词/库中/也/增加/了/此/词为/N/类/
/「/台/中/」/正確/應該/不會/被/切開/。/mac/上/可/分出/「/石墨/烯/」/;/此時/又/可以/分出/來凱/特琳/了/。
========================================
李小福 / nr , 是 / v , 创新 / v , 办 / v , 主任 / b , 也 / d , 是 / v , 云 / n , 计算 / v , 方面 / n , 的 / uj , 专家 / n , ; / x , / x , 什么 / r , 是 / v , 八 / m , 一双 / m , 鹿 / nr ,
/ x , 例如 / v , 我 / r , 输入 / v , 一个 / m , 带 / v , “ / x , 韩玉 / nr , 赏鉴 / v , ” / x , 的 / uj , 标题 / n , , / x , 在 / p , 自定义词 / n , 库中 / nrt , 也 / d , 增加 / v , 了 / ul , 此 / r , 词 / n , 为 / p , N / eng , 类 / q ,
/ x , 「 / x , 台 / q , 中 / f , 」 / x , 正確 / ad , 應該 / v , 不 / d , 會 / v , 被 / p , 切開 / ad , 。 / x , mac / eng , 上 / f , 可 / v , 分出 / v , 「 / x , 石墨 / n , 烯 / x , 」 / x , ; / x , 此時 / c , 又 / d , 可以 / c , 分出 / v , 來 / v , 凱特琳 / nrt , 了 / ul , 。 / x ,
========================================
easy/_/install/ /is/ /great
python/ /的/正则表达式/是/好/用/的
========================================
今天天气/不错
今天天气 Before: 3, After: 0
今天/天气/不错
----------------------------------------
如果/放到/post/中将/出错/。
中将 Before: 763, After: 494
如果/放到/post/中/将/出错/。
----------------------------------------
我们/中/出/了/一个/叛徒
中出 Before: 3, After: 3
我们/中/出/了/一个/叛徒
----------------------------------------
是不是分的有些不够理想?看看下面添加自定义分词后的结果吧
使用自定义词典后的效果
userdict.txt 自定义的分词词典
云计算 5
李小福 2 nr
创新办 3 i
easy_install 3 eng
好用 300
韩玉赏鉴 3 nz
八一双鹿 3 nz
台中
凱特琳 nz
Edu Trust认证 2000
test_userdict.py 分词代码
# encoding=utf-8
from __future__ import print_function, unicode_literals
import sys
sys.path.append("../")
import jieba
jieba.load_userdict("userdict.txt") # 加载咱们自定义的词典:userdict.txt
import jieba.posseg as pseg
jieba.add_word('石墨烯') # 动态往词典添加分词:石墨烯(把它分成整体)
jieba.add_word('凱特琳')
jieba.del_word('自定义词') # 删除词典里的分词:自定义词(避免分出这个整体)
# 测试数据
test_sent = (
"李小福是创新办主任也是云计算方面的专家; 什么是八一双鹿\n"
"例如我输入一个带“韩玉赏鉴”的标题,在自定义词库中也增加了此词为N类\n"
"「台中」正確應該不會被切開。mac上可分出「石墨烯」;此時又可以分出來凱特琳了。"
)
words = jieba.cut(test_sent)
print('/'.join(words))
print("=" * 40)
result = pseg.cut(test_sent)
for w in result:
print(w.word, "/", w.flag, ", ", end=' ')
print("\n" + "=" * 40)
terms = jieba.cut('easy_install is great')
print('/'.join(terms))
terms = jieba.cut('python 的正则表达式是好用的')
print('/'.join(terms))
print("=" * 40)
# test frequency tune
testlist = [
('今天天气不错', ('今天', '天气')),
('如果放到post中将出错。', ('中', '将')),
('我们中出了一个叛徒', ('中', '出')),
]
for sent, seg in testlist:
print('/'.join(jieba.cut(sent, HMM=False)))
word = ''.join(seg)
print('%s Before: %s, After: %s' % (word, jieba.get_FREQ(word), jieba.suggest_freq(seg, True)))
print('/'.join(jieba.cut(sent, HMM=False)))
print("-" * 40)
上述代码打印结果
李小福/是/创新办/主任/也/是/云计算/方面/的/专家/;/ /什么/是/八一双鹿/
/例如/我/输入/一个/带/“/韩玉赏鉴/”/的/标题/,/在/自定义/词库/中/也/增加/了/此/词为/N/类/
/「/台中/」/正確/應該/不會/被/切開/。/mac/上/可/分出/「/石墨烯/」/;/此時/又/可以/分出/來/凱特琳/了/。
========================================
李小福 / nr , 是 / v , 创新办 / i , 主任 / b , 也 / d , 是 / v , 云计算 / x , 方面 / n , 的 / uj , 专家 / n , ; / x , / x , 什么 / r , 是 / v , 八一双鹿 / nz ,
/ x , 例如 / v , 我 / r , 输入 / v , 一个 / m , 带 / v , “ / x , 韩玉赏鉴 / nz , ” / x , 的 / uj , 标题 / n , , / x , 在 / p , 自定义 / l , 词库 / n , 中 / f , 也 / d , 增加 / v , 了 / ul , 此 / r , 词 / n , 为 / p , N / eng , 类 / q ,
/ x , 「 / x , 台中 / s , 」 / x , 正確 / ad , 應該 / v , 不 / d , 會 / v , 被 / p , 切開 / ad , 。 / x , mac / eng , 上 / f , 可 / v , 分出 / v , 「 / x , 石墨烯 / x , 」 / x , ; / x , 此時 / c , 又 / d , 可以 / c , 分出 / v , 來 / zg , 凱特琳 / nz , 了 / ul , 。 / x ,
========================================
easy_install/ /is/ /great
python/ /的/正则表达式/是/好用/的
========================================
今天天气/不错
今天天气 Before: 3, After: 0
今天/天气/不错
----------------------------------------
如果/放到/post/中将/出错/。
中将 Before: 763, After: 494
如果/放到/post/中/将/出错/。
----------------------------------------
我们/中/出/了/一个/叛徒
中出 Before: 3, After: 3
我们/中/出/了/一个/叛徒
----------------------------------------
创新办、云计算、八一双鹿....是不是感觉好多了?
繁体词典、内存更小的字典
如果你的目标文本内容是繁体,你可以使用 jieba 提供的这个词典:dict.txt.big
如果你想要 jieba 分词使用的内存小点,可以使用 jieba 提供的这个词典:dict.txt.small
下载你所需要的词典 jieba.set_dictionary('data/dict.txt.big') 导入即可,亦或是覆盖 jieba 分词提供的 jieba/dict.txt
在命令行使用 jieba 分词
jieba 分词还贴心的给我们提供了命令行执行方式
在仅需要分词结果时,我们可以使用命令行模式快速地使用分词,而不需要去新建一个 python 文件,然后写代码
使用示例:python -m jieba news.txt > cut_result.txt
命令行选项:
使用: python -m jieba [options] filename
结巴命令行界面。
固定参数:
filename 输入文件
可选参数:
-h, --help 显示此帮助信息并退出
-d [DELIM], --delimiter [DELIM]
使用 DELIM 分隔词语,而不是用默认的' / '。
若不指定 DELIM,则使用一个空格分隔。
-p [DELIM], --pos [DELIM]
启用词性标注;如果指定 DELIM,词语和词性之间
用它分隔,否则用 _ 分隔
-D DICT, --dict DICT 使用 DICT 代替默认词典
-u USER_DICT, --user-dict USER_DICT
使用 USER_DICT 作为附加词典,与默认词典或自定义词典配合使用
-a, --cut-all 全模式分词(不支持词性标注)
-n, --no-hmm 不使用隐含马尔可夫模型
-q, --quiet 不输出载入信息到 STDERR
-V, --version 显示版本信息并退出
如果没有指定文件名,则使用标准输入。
--help 选项输出:
$> python -m jieba --help
Jieba command line interface.
positional arguments:
filename input file
optional arguments:
-h, --help show this help message and exit
-d [DELIM], --delimiter [DELIM]
use DELIM instead of ' / ' for word delimiter; or a
space if it is used without DELIM
-p [DELIM], --pos [DELIM]
enable POS tagging; if DELIM is specified, use DELIM
instead of '_' for POS delimiter
-D DICT, --dict DICT use DICT as dictionary
-u USER_DICT, --user-dict USER_DICT
use USER_DICT together with the default dictionary or
DICT (if specified)
-a, --cut-all full pattern cutting (ignored with POS tagging)
-n, --no-hmm don't use the Hidden Markov Model
-q, --quiet don't print loading messages to stderr
-V, --version show program's version number and exit
If no filename specified, use STDIN instead.
默认采用延迟加载
jieba 默认采用延迟加载,import jieba 和 jieba.Tokenizer() 不会立即触发词典的加载,一旦有必要才开始加载词典构建前缀字典。
如果你想手工初始 jieba,也可以手动初始化。
import jieba
jieba.initialize() # 手动初始化(可选)
词频统计
网上的封装词频统计案例
统计哈姆雷特和三国演义的词频
import string
import jieba
# 统计hamlet的词频 -> 可以用做英文的通用分词和统计
class Hamlet(object):
def __init__(self, name):
"""
:param name: 文本名字或路径
"""
self.text_name = name
def get_text(self):
"""
获取文本并进行相关处理
:return: 返回文本内容
"""
txt = open(self.text_name, "r").read().lower()
for ch in string.punctuation:
txt = txt.replace(ch, " ")
return txt
def count(self):
"""
统计单词出现的次数并输出结果
"""
hamlet_txt = self.get_text()
words = hamlet_txt.split()
counts = {}
for word in words:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
# key指定用列表中每一项中第二个值作为排序依据, reverse设置排序顺序 设为True的排序顺序为从大到小
items.sort(key=lambda x: x[1], reverse=True)
for i in range(10):
print(items[i][0], items[i][1])
# 统计三国演义中人物名字的词频 -> 可以用做中文的通用分词及统计
class ThreeKindDom(object):
def __init__(self, name):
"""
:param name: 文本名字或路径
"""
self.text_name = name
def get_text(self):
"""
获取文本并进行相关处理
:return: 返回文本内容
"""
txt = open(self.text_name, "r", encoding="utf-8").read()
return txt
def split_txt(self):
"""
对文本进行分词
:return: 返回分词后的列表
"""
threekingdom_txt = self.get_text()
words = jieba.lcut(threekingdom_txt)
return words
def count(self):
"""
统计单词出现的次数并输出结果
"""
words = self.split_txt()
# excludes为要去掉的词
excludes = {"将军", "却说", "二人", "不可", "荆州", "不能", "如此", "商议", "如何", "左右",
"军马", "引兵", "军士", "次日", "主公", "大喜", "天下", "东吴", "于是", "今日", "魏兵"}
counts = {}
for word in words:
rword = word
if len(word) == 1:
continue
# 对一些特殊的词进行处理
elif word == "诸葛亮" or word == "孔明" or word == "孔明曰":
rword = "孔明"
elif word == "关公" or word == "云长":
rword = "关羽"
elif word == "玄德" or word == "玄德曰":
rword = "刘备"
elif word == "孟德" or word == "丞相":
rword = "曹操"
counts[rword] = counts.get(rword, 0) + 1
for word in excludes:
del counts[word]
items = list(counts.items())
# key指定用列表中每一项中第二个值作为排序依据, reverse设置排序顺序 设为True的排序顺序为从大到小
items.sort(key=lambda x: x[1], reverse=True)
for i in range(8):
print(items[i][0], items[i][1])
if __name__ == '__main__':
# s1 = Hamlet("hamlet.txt")
# s1.count()
s2 = ThreeKindDom("threekingdoms.txt")
s2.count()
关键字提取
jieba 分词自带两种关键词抽取算法
TF-IDF 算法抽取
首先要用这个需要导入:import jieba.analyse
使用
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence 为待提取的文本
- topK 为返回的 TF/IDF 权重最大的关键词个数,默认值为 20
- withWeight 为是否返回关键词权重值,默认值为 False
- allowPOS 指定筛选词性,元组类型
停止词过滤
停止词是指在句子中无关紧要的词语,例如标点符号、指示代词等等,做分词前要先将这些词去掉
分词方法
cut不支持直接过滤停止词,需要手动处理
通过:jieba.analyse.set_stop_words("../extra_dict/stop_words.txt") 指定停止词文件
stop_words.txt 官方提供的停止词列表,你也可以自定义
the
of
is
and
to
in
that
we
for
an
are
by
be
as
on
with
can
if
from
which
you
it
this
then
at
have
all
not
one
has
or
that
的
了
和
是
就
都
而
及
與
著
或
一個
沒有
我們
你們
妳們
他們
她們
是否
TextRank 算法抽取
【官网】中有描述,我也看不懂就不放这儿了。。。
词性标注 ***
作用
可以给分词结果标注上类型,然后我们根据类型来统计
比如一段电影剧本,我们可以用词性标注分词器来分词,然后循环结果,对分词词性为 人名 nr 的分词结果进行统计,统计出本剧本中的人名有哪些
词性表
更全的可以参考:jieba词性表
个人推测:名词 an、成语 i、数词 m、数量词 mq、名词 n、人名 nr、地名 ns、机构团体 nt、其他专名 nz 可能会用的多一点,反正都是用到了再查嘛~

词性标注使用
效果和原理:标注句子分词后每个词的词性,采用和 ictclas 兼容的标记法。
用法示例
import jieba.posseg as pseg
words = pseg.cut("我爱北京天安门")
# 亦或是自定义的分词器(jieba.posseg.dt 是默认的词性标注分词器)
# fenciqi = posseg.POSTokenizer(tokenizer=jieba.posseg.dt)
# words = fenciqi.cut("我爱北京天安门")
for word, flag in words:
print('%s %s' % (word, flag))
# 我 r
# 爱 v
# 北京 ns
# 天安门 ns
自定义分词器
jieba.posseg.POSTokenizer(tokenizer=None) 新建自定义分词器,tokenizer 参数可指定内部使用的 jieba.Tokenizer 分词器:jieba.posseg.dt 为默认词性标注分词器。
并行分词
利用多进程提高分词效率...
暂时用不到,标记有这么个功能,用到再查
原理:将目标文本按行分隔后,把各行文本分配到多个 Python 进程并行分词,然后归并结果,从而获得分词速度的可观提升
- 基于 python 自带的 multiprocessing 模块,目前暂不支持 Windows
用法:
jieba.enable_parallel(4)开启并行分词模式,参数为并行进程数jieba.disable_parallel()关闭并行分词模式
例子:
https://github.com/fxsjy/jieba/blob/master/test/parallel/test_file.py
实验结果:在 4 核 3.4GHz Linux 机器上,对金庸全集进行精确分词,获得了 1MB/s 的速度,是单进程版的 3.3 倍。
- 注意:并行分词仅支持默认分词器
jieba.dt和jieba.posseg.dt。
返回词语在原文的起始位置
输入参数只接受 unicode 编码格式
- 默认模式(不出现重复利用)
result = jieba.tokenize(u'永和服装饰品有限公司') # 参数必须要是 unicode 编码格式才行
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
# word 永和 start: 0 end:2
# word 服装 start: 2 end:4
# word 饰品 start: 4 end:6
# word 有限公司 start: 6 end:10
- 搜索模式(联想搜词)
result = jieba.tokenize(u'永和服装饰品有限公司', mode='search') # 指定模式为搜索模式,参数必须要是 unicode 编码格式才行
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
# word 永和 start: 0 end:2
# word 服装 start: 2 end:4
# word 饰品 start: 4 end:6
# word 有限 start: 6 end:8
# word 公司 start: 8 end:10
# word 有限公司 start: 6 end:10
常见函数用法速查
| 代码 | 功能 |
|---|---|
| jieba.cut(s) | 精确模式,返回一个可迭代的数据类型 |
| jieba.cut(s,cut_all=True) | 全模式,输出文本s中所有可能单词 |
| jieba.cut_for_search(s) | 搜索引擎模式,适合搜索建立索引的分词 |
| jieba.lcut(s) | 精确模式,返回一个列表类型,常用 |
| jieba.lcut(s,cut_all=True) | 全模式,返回一个列表类型,常用 |
| jieba.lcut_for_search(s) | 搜索引擎模式,返回一个列表类型,常用 |
| jieba.add_word(w) | 向词典中增加新词 |
常见问题
模型的数据是如何生成的?
详见: https://github.com/fxsjy/jieba/issues/7
“台中”总是被切成“台 中”?(以及类似情况)
P(台中) < P(台)×P(中),“台中”词频不够导致其成词概率较低
解决方法:强制调高词频
jieba.add_word('台中')` 或者 `jieba.suggest_freq('台中', True)
“今天天气 不错”应该被切成“今天 天气 不错”?(以及类似情况)
解决方法:强制调低词频
jieba.suggest_freq(('今天', '天气'), True)
或者直接删除该词 jieba.del_word('今天天气')
切出了词典中没有的词语,效果不理想?
解决方法:关闭新词发现
jieba.cut('丰田太省了', HMM=False)` `jieba.cut('我们中出了一个叛徒', HMM=False)
更多问题请点击:https://github.com/fxsjy/jieba/issues?sort=updated&state=closed

 浙公网安备 33010602011771号
浙公网安备 33010602011771号