Django-手撸简易web框架-实现动态网页-wsgiref初识-jinja2初识-python主流web框架对比-00
自己动手实现一个简易版本的web框架
在了解python的三大web框架之前,我们先自己动手实现一个。
备注:
这部分重在掌握实现思路,代码不是重点
代码中也有许多细节并未考虑,重在实现思路
手撸一个web服务端
我们一般是使用浏览器当做客户端,然后基于HTTP协议自己写服务端代码作为服务端
先自行去回顾一下HTTP协议这一块儿的知识
import socket
server = socket.socket() # 基于socket通信(TCP)
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
conn, addr = server.accept()
data = conn.recv(2048) # 接收请求
print(str(data, encoding='utf-8'))
conn.send(b'HTTP/1.1 200 OK\r\n\r\n') # 依据HTTP协议,发送响应给客户端(浏览器),这里是响应首行 + 响应头 + 空行
# response = bytes('<h3>这是响应内容</h3>', encoding='GBK')
response = '<h3>这是响应内容</h3>'.encode('GBK') # 我电脑上是GBK编码,所以使用GBK编码将字符串转成二进制
conn.send(response) # 继续发送响应体
conn.close() # 断开连接(无状态、无连接)
# 浏览器发过来的数据如下
'''
GET / HTTP/1.1
Host: 127.0.0.1:8080
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: _qddaz=QD.w3c3g1.j2bfa7.jvp70drt; csrftoken=kJHVGICQOglLxJNiui0o0UyxNtR3cXbJPXqaUFs5FoxeezuskRO7jlQE0JNwYXJs
GET /favicon.ico HTTP/1.1
Host: 127.0.0.1:8080
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36
Accept: image/webp,image/apng,image/*,*/*;q=0.8
Referer: http://127.0.0.1:8080/
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: _qddaz=QD.w3c3g1.j2bfa7.jvp70drt; csrftoken=kJHVGICQOglLxJNiui0o0UyxNtR3cXbJPXqaUFs5FoxeezuskRO7jlQE0JNwYXJs
'''
然后右键运行,在浏览器访问 127.0.0.1:8080 即可看到响应数据
关于启动服务器与页面请求(在我处理的时候,页面网络请求会经常处于 pending状态,不是很清楚原因,一般这个情况下,直接重启一下服务器即可)

根据请求 url 做不同的响应处理
上面的代码已经实现了基本请求响应,那如何根据不同的请求作出不同的响应呢?
我们输入不同的url,看看服务器端会返回什么
分析请求
浏览器访问 http://127.0.0.1:8080/index
GET /index HTTP/1.1
Host: 127.0.0.1:8080
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: _qddaz=QD.w3c3g1.j2bfa7.jvp70drt; csrftoken=kJHVGICQOglLxJNiui0o0UyxNtR3cXbJPXqaUFs5FoxeezuskRO7jlQE0JNwYXJs
浏览器访问 http://127.0.0.1:8080/home
GET /home HTTP/1.1
Host: 127.0.0.1:8080
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: _qddaz=QD.w3c3g1.j2bfa7.jvp70drt; csrftoken=kJHVGICQOglLxJNiui0o0UyxNtR3cXbJPXqaUFs5FoxeezuskRO7jlQE0JNwYXJs
原来请求首行的 GET 后面跟的就是请求我们想要信息(/index 首页、/home 家)
这些信息也是我们接收到的(data = conn.recv(2048) print(str(data, encoding='utf-8'))),那可不可以取出来,根据值的不同作不同处理呢?
处理请求,获取 url
data = '''GET /home HTTP/1.1
Host: 127.0.0.1:8080
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: _qddaz=QD.w3c3g1.j2bfa7.jvp70drt; csrftoken=kJHVGICQOglLxJNiui0o0UyxNtR3cXbJPXqaUFs5FoxeezuskRO7jlQE0JNwYXJs'''
print(data.split('\n')[0].split(' ')[1]) # ... ---> GET /home HTTP/1.1 --> ['GET', '/home', 'HTTP/1.1'] --> /home
# /home
依据上述切割规则,我们来对不同的请求作出不同的响应
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
conn, addr = server.accept()
data = conn.recv(2048).decode('utf-8')
data = data.split('\n')[0].split(' ')[1]
print(data)
conn.send(b'HTTP/1.1 200 OK\r\n\r\n')
if data == '/index':
response = '<h3>这里是 index...</h3>'.encode('GBK')
elif data == '/home':
response = '<h3>这里是 home...</h3>'.encode('GBK')
else:
response = '<h3>404 NOT FOUND...\n找不到您要找的资源...</h3>'.encode('GBK')
conn.send(response)
conn.close()
# --- 浏览器请求 http://127.0.0.1:8080/index 的打印信息
# /index
# /favicon.ico
# --- 浏览器请求 http://127.0.0.1:8080/home 的打印信息
# /home
# /favicon.ico
# --- 浏览器请求 http://127.0.0.1:8080/de2332f 的打印信息
# /de2332f
# /favicon.ico
页面成功显示不同的信息
http://127.0.0.1:8080/index
http://127.0.0.1:8080/home
http://127.0.0.1:8080/de2332f

404页面也应该算作设计网站的一部分,可以给人不一样的感觉
基于wsgiref模块实现服务端
前面处理 scoket 和 http 的那堆代码通常是不变的,且与业务逻辑没什么关系,如果每个项目都要写一遍,那岂不是很麻烦?那封装成模块嘛~
不过这个操作已经有人帮我们做了,并且封装的更加强大,就是 wsgiref 模块
用wsgiref 模块的做的两件事
- 在请求来的时候,自动解析 HTTP 数据,并打包成一个字典,便于对请求发过来的数据进行操作
- 发响应之前,自动帮忙把数据打包成符合 HTTP 协议的格式(响应数据格式,不需要再手动写
conn.send(b'HTTP/1.1 200 OK\r\n\r\n')了),返回给服务端
from wsgiref.simple_server import make_server # 导模块
def run(env, response):
"""
先不管这里的 env 和 response 什么个情况
env:是请求相关的数据,wsgiref帮我们把请求包装成了一个大字典,方便取值
response:是响应相关的数据
"""
response('200 OK', [])
print(env)
current_path = env.get('PATH_INFO')
print(current_path)
if current_path == '/index':
return ['hello, there is index...'.encode('utf-8')]
elif current_path == '/login':
return ['hello, there is login...'.encode('utf-8')]
else:
return ['sorry... that pages you want is not found...'.encode('utf-8')]
if __name__ == '__main__':
# 实时监测 127.0.0.1:8080 地址,一旦有客户端连接,会自动加括号调用 run 方法
server = make_server('127.0.0.1', 8080, run)
server.serve_forever() # 启动服务器
# /index
# ---> env 的数据(手动删减了一些),可以看到其中有个 PATH_INFO 是我们要的东西(还有浏览器版本啊,USER-AGENT啊,客户端系统环境变量啊之类的信息)
'''{'ALLUSERSPROFILE': 'C:\\ProgramData', ...省略部分... , 'COMSPEC': 'C:\\Windows\\system32\\cmd.exe', 'PROCESSOR_IDENTIFIER': 'Intel64 Family 6 Model 60 Stepping 3, GenuineIntel', 'PROCESSOR_LEVEL': '6', 'PROCESSOR_REVISION': '3c03', 'PYTHONIOENCODING': 'UTF-8', 'SESSIONNAME': 'Console', 'SYSTEMDRIVE': 'C:', 'SERVER_PORT': '8080', 'REMOTE_HOST': '', 'CONTENT_LENGTH': '', 'SCRIPT_NAME': '', 'SERVER_PROTOCOL': 'HTTP/1.1', 'SERVER_SOFTWARE': 'WSGIServer/0.2', 'REQUEST_METHOD': 'GET', 'PATH_INFO': '/index', 'QUERY_STRING': '', 'REMOTE_ADDR': '127.0.0.1', 'CONTENT_TYPE': 'text/plain', 'HTTP_HOST': '127.0.0.1:8080', 'HTTP_CONNECTION': 'keep-alive', 'HTTP_UPGRADE_INSECURE_REQUESTS': '1', 'HTTP_USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36', 'HTTP_ACCEPT': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3', csrftoken=kJHVGICQOglLxJNiui0o0UyxNtR3cXbJPXqaUFs5FoxeezuskRO7jlQE0JNwYXJs', mode='w' encoding='UTF-8'>, 'wsgi.version': (1, 0), }'''
伏笔

拆分服务端代码
服务端代码、路由配置、视图函数,照目前的写法全都冗在一块儿,后期功能扩展时,这个文件会变得很长,不方便维护,所以选择把他拆分开来
就是将服务端代码拆分成如下三部分:
-
server.py 放服务端代码
-
urls.py 放路由与视图函数对应关系
-
views.py 放视图函数/类(处理业务逻辑)
views.py
def index(env):
return 'index'
def login(env):
return 'login'
urls.py
from views import *
urls = [
('/index', index),
('/login', login),
]
server.py
from wsgiref.simple_server import make_server # 导模块
from urls import urls # 引入 urls.py 里的 urls列表(命名的不是很规范)
def run(env, response):
response('200 OK', [])
current_path = env.get('PATH_INFO')
func = None
for url in urls:
if current_path == url[0]:
func = url[1]
break
if func:
res = func(env)
else:
res = '404 Not Found.'
return [res.encode('utf-8')] # 注意这里返回的是一个列表(可迭代对象才行),wsgiref 模块规定的,可能还有其他的用途吧
if __name__ == '__main__':
server = make_server('127.0.0.1', 8080, run)
server.serve_forever()
支持新的请求地址(添加新页面/新功能)
经过上面的拆分后,后续想要支持其他 url,只需要在 urls.py 中添加一条对应关系,在 views.py 中把该函数实现,重启服务器即可访问
以支持 http://127.0.0.1:8080/new_url 访问为例
urls.py
from views import *
urls = [
('/index', index),
('/login', login),
('/new_url', new_url),
]
views.py
def index(env):
return 'index'
def login(env):
return 'login'
def new_url(env):
# 这里可以写一堆逻辑代码
return 'new_url'
重启服务器,打开浏览器即可访问 http://127.0.0.1:8080/new_url
扩展性高了很多,且逻辑更清晰了,更不容易弄错(框架的好处提现,也是为什么脱离了框架不会写的原因,这块代码写的太少,不常用到,没了框架又写不出来)
动态静态网页--拆分模板文件
前面写了那么多,都只是一直在返回纯文本信息,而我们一般请求页面返回的都是浏览器渲染好的华丽的页面,那要怎么放回华丽的页面呢?
页面嘛,就是 HTML + CSS + JS 渲染出来的,所以我们也可以把 HTML文件当成数据放在响应体里直接返回回去
新建一个功能的步骤还是复习一下
- 在 urls.py 里面加一条路由与视图函数的对应关系
- 在 views.py 里面加上那个视图函数,并写好内部逻辑代码
- 重启服务器,浏览器打开页面访问
返回静态页面--案例
这里咱们就接着上面的 new_url 写,用他来返回 一个网页
新建一个 templates 文件夹,专门用来放 HTML 文件
templates/new_url.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>New URL</h1>
<h5>Wellcome!</h5>
</body>
</html>
views.py
def index(env):
return 'index'
def login(env):
return 'login'
def new_url(env):
# 读取并把 new_url 文件返回给客户端(浏览器)
with open(r'templates/new_url.html', 'rb') as f:
html_data = f.read()
return html_data.decode('utf-8') # 因为 run 函数那里做了 encode, 而二进制数据没有 encode这个方法,所以这里先解码一下,然后那边再编码一下
重启服务器,使用浏览器访问
上面提到了静态页面,那什么是静态页面?什么又是动态页面呢?
-
静态网页:纯html网页,数据是写死的,所有同url的请求拿到的数据都是一样的
-
动态网页:后端数据拼接,数据不是写死的,是动态拼接的,比如:
后端实时获取当前时间“传递”(塞)给前端页面展示
后端从数据库获取数据“传递”给前端页面展示
实现返回时间--插值思路(动态页面)
要怎么在 html 里插入时间呢?
往 html 里的插入?那替换好像也可以达到效果啊?
html_data = f.read() ? 好像 html 被读出出来了,而且还是二进制的,二进制可以 decode 变成字符串,字符串有 replace方法可以替换字符串,那我随便在网页里写点内容,然后替换成时间?
先把基础歩鄹做好
templates/get_time.html 编写展示页面
put_times_here 用来做占位符,一会儿给他替换成时间
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>北京时间:</h1>
<h1>put_time_here</h1>
</body>
</html>
urls.py 路由与视图函数对应关系
from views import *
urls = [
('/index', index),
('/login', login),
('/new_url', new_url),
('/get_time', get_time),
]
views.py 实现视图函数
def index(env):
return 'index'
def login(env):
return 'login'
def new_url(env):
# 读取并把 new_url 文件返回给客户端(浏览器)
with open(r'templates/new_url.html', 'rb') as f:
html_data = f.read()
return html_data
def get_time(env):
# 读取并把 get_time 文件返回给客户端(浏览器)
with open(r'templates/get_time.html', 'rb') as f:
html_data = f.read().decode('utf-8')
import time
html_data = html_data.replace('put_time_here', time.strftime("%Y-%m-%d %X"))
return html_data
重启服务器并打开浏览器访问 http://127.0.0.1:8080/get_time
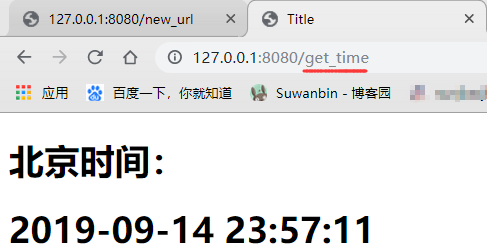
关键思路:相当于占位符,字符串替换,后期把前端要替换的字符的格式统一规定下,方便阅读与统一处理,这其实也就是目前的模版语法的雏形
我们只需要把处理好的字符串(HTML格式的)返回给浏览器,待浏览器渲染即可有页面效果
利用 jinja2 模块实现动态页面
jinja2模块有着一套 模板语法,可以帮我更方便地在 html 写代码(就想写后台代码一样),让前端也能够使用后端的一些语法操作后端传入的数据
安装 jinja2
jinja2 并不是 python 解释器自带的,所以需要我们自己安装
由于 flask 框架是依赖于 jinja2 的,所下载 flask 框架也会自带把 jinja2 模块装上
命令行执行,pip3 install jinja2 或图形化操作安装(参考 Django 的安装方法)
初步使用
这里只是知道有模板语法这么一个东西可以让我们很方便的往 html 写一些变量一样的东西,并不会讲 jinja2 的语法,后续会有的
案例--展示字典信息
urls.py
from views import *
urls = [
('/index', index),
('/login', login),
('/new_url', new_url),
('/get_time', get_time),
('/show_dic', show_dic),
]
views.py
def index(env):
return 'index'
def login(env):
return 'login'
def new_url(env):
# 读取并把 new_url 文件返回给客户端(浏览器)
with open(r'templates/new_url.html', 'rb') as f:
html_data = f.read()
return html_data
def get_time(env):
# 读取并把 get_time 文件返回给客户端(浏览器)
with open(r'templates/get_time.html', 'rb') as f:
html_data = f.read().decode('utf-8')
import time
html_data = html_data.replace('put_time_here', time.strftime("%Y-%m-%d %X"))
return html_data
def show_dic(env):
user = {
"username": "jason",
"age": 18,
}
with open(r'templates/show_dic.html', 'rb') as f:
html_data = f.read()
# 使用 jinja2 的模板语法来将数据渲染到页面上(替换占位符)
from jinja2 import Template
tmp = Template(html_data)
res = tmp.render(dic=user) # 将字典 user 传递给前端页面,前端页面通过变量名 dic 就能够获取到该字典
return res
templates/show_dic.html 写页面
jinja2 给字典扩展了点语法支持({{ dic.username }})
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>Nice to meet you~ i'm {{ dic.username }} , and i'm {{ dic.age }} years old.</h1>
<p>username: {{ dic['username']}}</p>
<p>age: {{ dic.get('age')}}</p>
</body>
</html>
重启服务器并打开浏览器访问 http://127.0.0.1:8080/show_dic
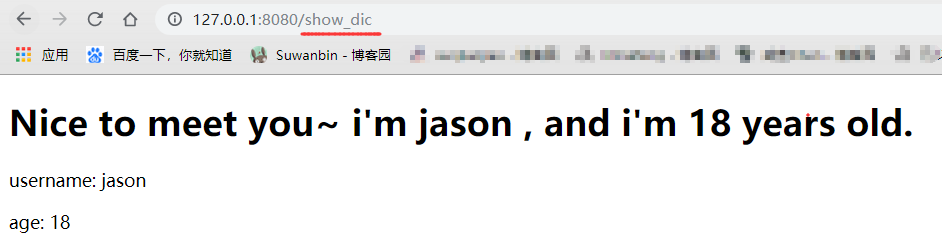
为什么说动态?
如果你改变了字典里的值,那么请求这个页面,显示的数据也会跟着改变(注意这个字典一般都是其他地方获取过来的)
模板语法(贴近python语法): 前端也能够使用后端的一些语法操作后端传入的数据
{{data.password}} # jinja2 多给字典做了 点语法支持
... 其他的语法,写法
for 循环
{%for user_dict in user_list%}
<tr>
<td>{{user_dict.id}}</td>
<td>{{user_dict.name}}</td>
<td>{{user_dict.password}}</td>
</tr>
{%endfor%}
进阶案例--渲染数据库数据到页面
思路
pymsql 从数据库取数据(指定成 列表套字典 的格式(DictCursor))
后台 python 代码处理数据
交由 jinja2 模块语法渲染到 html 页面上
数据条数不定怎么办?
有多少条记录就显示多少条呗...循环?
表格格式先写好,然后循环渲染数据到标签上(特定语法表示循环)
数据准备
创建数据库 django_test_db,然后执行如下 SQL 命令
/*
Navicat MySQL Data Transfer
Source Server : localhost-E
Source Server Type : MySQL
Source Server Version : 50645
Source Host : localhost:3306
Source Schema : django_test_db
Target Server Type : MySQL
Target Server Version : 50645
File Encoding : 65001
Date: 15/09/2019 00:41:09
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for user_info
-- ----------------------------
DROP TABLE IF EXISTS `user_info`;
CREATE TABLE `user_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`password` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
-- ----------------------------
-- Records of user_info
-- ----------------------------
INSERT INTO `user_info` VALUES (1, 'jason', '123');
INSERT INTO `user_info` VALUES (2, 'tank', '123');
INSERT INTO `user_info` VALUES (3, 'jerry', '123');
INSERT INTO `user_info` VALUES (4, 'egon', '456');
SET FOREIGN_KEY_CHECKS = 1;
配路由与视图函数
urls.py
from views import *
urls = [
('/index', index),
('/login', login),
('/new_url', new_url),
('/get_time', get_time),
('/show_dic', show_dic),
('/get_users', get_users),
]
views.py
def index(env):
return 'index'
def login(env):
return 'login'
def new_url(env):
# 读取并把 new_url 文件返回给客户端(浏览器)
with open(r'templates/new_url.html', 'rb') as f:
html_data = f.read()
return html_data
def get_time(env):
# 读取并把 get_time 文件返回给客户端(浏览器)
with open(r'templates/get_time.html', 'rb') as f:
html_data = f.read().decode('utf-8')
import time
html_data = html_data.replace('put_time_here', time.strftime("%Y-%m-%d %X"))
return html_data
def show_dic(env):
user = {
"username": "jason",
"age": 18,
}
with open(r'templates/show_dic.html', 'rb') as f:
html_data = f.read()
# 使用 jinja2 的模板语法来将数据渲染到页面上(替换占位符)
from jinja2 import Template
tmp = Template(html_data)
res = tmp.render(dic=user) # 将字典 user 传递给前端页面,前端页面通过变量名 dic 就能够获取到该字典
return res
# 先写个空函数在这里占位置,去把 pymysql 查数据的写了再过来完善
def get_users(env):
# 从数据库取到数据
import op_mysql
user_list = op_mysql.get_users()
with open(r'templates/get_users.html', 'r', encoding='utf-8') as f:
html_data = f.read()
from jinja2 import Template # 其实这个引入应该放在页面最上方去的,但为了渐进式演示代码推进过程,就放在这里了
tmp = Template(html_data)
res = tmp.render(user_list=user_list)
return res
**op_mysql.py **如果你的配置不一样要自己改过来
import pymysql
def get_cursor():
server = pymysql.connect(
# 根据自己电脑上 mysql 的情况配置这一块的内容
host='127.0.0.1',
port=3306,
user='root',
password='000000',
charset='utf8', # 千万注意这里是 utf8 !
database='django_test_db',
autocommit=True
)
cursor = server.cursor(pymysql.cursors.DictCursor)
return cursor
def get_users():
cursor = get_cursor() # 连接数据库
sql = "select * from user_info" # 把用户的所有信息查出来(一般不会把密码放回给前端的,这里只是为了做演示)
affect_rows = cursor.execute(sql)
user_list = cursor.fetchall()
return user_list
templates/get_users.html 用户信息展示页面
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<!-- 引入jquery bootstrap 文件的 CDN -->
<script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.min.js"></script>
<link href="https://cdn.bootcss.com/twitter-bootstrap/3.4.1/css/bootstrap.min.css" rel="stylesheet">
<script src="https://cdn.bootcss.com/twitter-bootstrap/3.4.1/js/bootstrap.min.js"></script>
</head>
<body>
<div class="container">
<div class="row">
<div class="col-md-8 col-md-offset-2">
<h2 class="text-center">用户数据展示</h2>
<table class="table table-hover table-bordered table-striped">
<thead>
<tr>
<th>id</th>
<th>username</th>
<th>password</th>
</tr>
</thead>
<tbody>
<!-- jinja2 的模版语法(for循环) -->
{%for user_dict in user_list%}
<tr>
<td>{{user_dict.id}}</td>
<td>{{user_dict.username}}</td>
<td>{{user_dict.password}}</td>
</tr>
{%endfor%}
</tbody>
</table>
</div>
</div>
</div>
</body>
</html>
用浏览器访问 http://127.0.0.1:8080/get_users,重启服务器,在切回浏览器即可看到页面效果
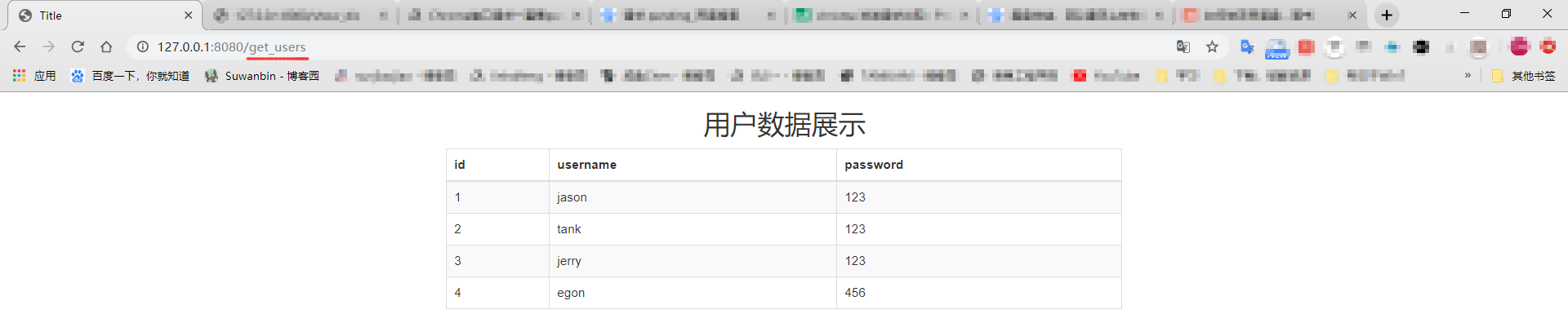
推导流程与小总结
1.纯手撸web框架
1.手动书写socket代码
2.手动处理http数据
2.基于wsgiref模块帮助我们处理scoket以及http数据(顶掉上面的歩鄹)
wsgiref模块
1.请求来的时候 解析http数据帮你打包成一个字典传输给你 便于你操作各项数据
2.响应走的时候 自动帮你把数据再打包成符合http协议格式的样子 再返回给前端
3.封装路由与视图函数对应关系 以及视图函数文件 网站用到的所有的html文件全部放在了templates文件夹下
1.urls.py 路由与视图函数对应关系
2.views.py 视图函数 (视图函数不单单指函数 也可以是类)
3.templates 模板文件夹
4.基于jinja2实现模板的渲染
模板的渲染
后端生成好数据 通过某种方式传递给前端页面使用(前端页面可以基于模板语法更加快捷简便使用后端传过来的数据)
流程图
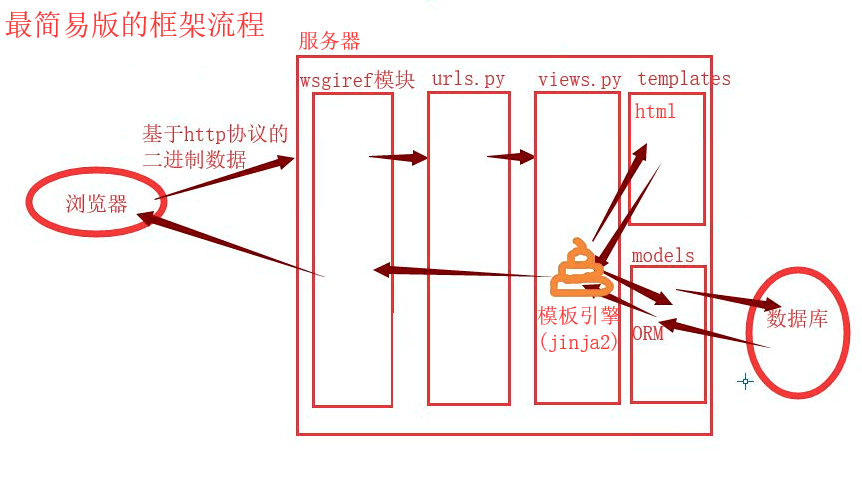
小扩展
在不知道是要 encode 还是 decode 的时候,可以用一下方法
二进制数据对应的肯定是 decode 解码 成字符串呀
字符串对应的肯定是 encode 编码成二进制数据呀
数据类型转换技巧(处理编码)(数据 + encoding)
# 转成 bytes 类型
bytes(data, encoding='utf-8')
# 转成 str 类型
str(data, encoding='utf-8')
python三大Web主流框架分析对比
Django
大而全,自带的功能特别特别多,就类似于航空母舰
缺点:有时过于笨重(小项目很多用不到)
Flask
短小精悍,自带的功能特别少,全都是依赖于第三方组件(模块)
第三方组件特别多 --> 如果把所有的第三方组件加起来,完全可以盖过django
缺点:比较受限于第三方的开发者(可能有bug等)
Tornado
天生的异步非阻塞框架,速度特别快,能够抗住高并发
可以开发游戏服务器(但开发游戏,还是 C 和C++用的多,执行效率更快)
手撸三大部分在框架中的情况对比
前面的手撸推导过程,整个框架过程大致可以分为以下三部分
A:socket处理请求的接收与响应的发送
B:路由与视图函数
C:模板语法给动态页面渲染数据
Django
A:用的别人的 wsgiref 模块
B:自带路由与视图函数文件
C:自带一套模板语法
Flask
A:用的别人的werkzeug 模块(基于 wsgiref 封装的)
B:自带路由与视图函数文件
C:用的别人的jinja2
Tornado
A,B,C全都有自己的实现
Django的下载安装基本使用
参见我的另一篇博客:Django-下载安装-配置-创建django项目-三板斧简单使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号