python字符编码-文件操作
字符编码
字符编码历史及发展
为什么有字符编码
''' 原因:人们想要将数据存入计算机 计算机的能存储的信息都是二进制的数据 内存是基于电工作的,而电信号只有高低频两种,就用01来表示高低电频,所以计算机里存储的数据都是0101这样的二进制数据 '''
各种编码表/标准 的由来
""" 基于上述原因与情况 人们输入的都是我们自己能看懂的语言、字符, 而计算机里存储的却是二进制数据,这样计算机不能读懂了 所以在保存数据的时候有一个转换过程,要有一个对应关系将我们输入的字符转换成计算机能够存储的二进制数据 人输入的字符 >> 对应关系转换(字符编码表)>> 二进制数据 A 0100 0001 B 0100 0010 后来美国发明了ASCII码表,用八位二进制来表示一个英文字符 其实所有的英文字符 + 符合,最多也就在125位左右,用七位二进制就够了,采用八进制是给其他语言做了预留 """
补充:
''' 八位二进制也叫 8bit ---> 0000 0000 常见单位与转换: 8bit = 1Bytes 1024Bytes = 1KB 1024KB = 1MB 1024MB = 1GB 1024GB = 1TB 1024TB = 1PB '''
各国各类编码的出现
""" 看到美国人有字符编码了,我们中国人也要用计算机,但ASCII码又没有中文的对应关系,于是乎就有国人发明了国标码(GBK编码) GBK编码用2Bytes(16个bit,16个0-1)表示一个中文字符,依旧用1Bytes 表示一个英文字符 (最多能表示 65535 个字符) 其他国家也有着同样的想法,都想要计算机能够支持本国语言,所以就先后出现了各种各样的字符编码标准 日本的编码标准:Shift_JIS 韩国的编码标准:EUC-KR """
需要知道的知识点
unicode编码标准
""" 不同的编码显然对应着不同的二进制信息,不利于计算机的通用性,于是出现了一套能够兼容各个国家编码标准的新标准--- Unicode unicode(又称万国码)统一用2Bytes(16 bit) 表示所有字符 特点: 用户在输入的时候无论输入什么字符都能兼容所有国家字符 其他国家编码的数据由硬盘读到内存的时候,unicode与其他各个国家的编码都有对应关系 然而采用2Bytes 也就意味着相比其他编码标准表示同样的数据,它会占用(浪费)更多空间 同时也意味着它会使得IO(input/ output 输入输出)次数增加,使得程序运行效率降低(这一点比占用空间还要致命) """
utf-8编码标准
""" 其实计算机内存中采用的大多都是unicode 编码标准,当将数据存入硬盘的时候,会采用另外一种标准--- utf-8 (unicode tansformation format) uft-8 编码标准会将 unicode中的英文字符由2Bytes 变成 1Bytes unicode中的中文字符由原来的2Bytes 变成3Bytes(很生僻的字可能会4-6个) --> 这不是更慢了吗?根据调查显示,这样其实是提升了效率的 """
根据上面粗略的发展历程,现在主流的计算机采用的都是 内存unicode + 硬盘utf-8 这样的方式
内存和硬盘采用的是不同的编码方式,你需要了解这两个流程
""" 内存中的数据从内存保存到硬盘 内存中的Unicode 格式的二进制数据 >>编码(encode)>> 硬盘中 utf-8 格式的二进制数据 硬盘中的数据由硬盘读到内存 硬盘中的utf-8 格式的二进制数据 >>解码(decode)>> 内存中 unicode 格式的二进制数据 """
打开文件是乱码的案例
""" 打开notepad++ 编辑器,在里面输入一些内容 ---> 在用户保存或者软件自动保存之前,这些数据都存在内存之中,用的是Unicode编码 用户点击 或 ctrl + s 触发保存功能,将按照指定的字符编码 把数据保存到硬盘中去(一般软件右下角都会有字符编码可以选择切换) 用户使用notepad++ 打开文件刚刚写好的文件 ---> 会按照保存时指定的字符编码读取文件 此时用户切换右下角的字符编码,改成其他标准 ---> 按照新标准去解析内容时就会出现乱码,因为新标准中找不到内容所对应的的信息(编码没对上) """
怎样避免乱码
""" 保存和打开的编码标准一致 文本文件以什么编码标准编的就以什么编码标准解 """
python2.x 和 python3.x 两个版本解释器采用的编码方式不同
""" python 解释器用的编码标准 python 2.x 用ASCII 码标准,在开发python2 解释器的时候, unicode 还没有盛行 python 3.x 则直接采用了比较流行的UTF-8 编码标准 也可以通过文件头的方式指定编码标准 # -*- coding:utf-8 -*- 即 # coding:utf-8 , 前面的写法仅仅是为了好看(这个# 不是注释的意思) # -*- coding:gbk -*- 告诉解释器以GBK的编码识别 也可以在代码中指定某些字符串的编码标准 python2.x 中:手动指定u ,unicode编码 x = u'上' print type(x) # <type 'unicode'> python3,x 中:直接把所有的字符串都存成 unicode x = u'上' print(type(x)) # <class 'str'> windows 终端的编码标准 ---> GBK pycharm 编辑器默认编码标准 ---> UTF-8 """

编码解码概念及写法
""" python 提供的两种处理字符编码的函数 encode 编码,指定编码标准 x = '上' print(x.encode('utf-8')) # b'\xe4\xb8\x8a' # bytes 类型,也叫字节串类型,把它当成二进制数据即可 x = 'a' print(x.encode('utf-8')) # b'a' decode 解码,指定解码标准 x = '上' res = x.encode('utf-8') # 将unicode编码(我暂时也没想明白,可以看看这篇博客:https://www.cnblogs.com/-qing-/p/10934261.html)成可以存储和传输的 utf-8 的二进制数据 可以存也可以发 print(res) # b'\xe4\xb8\x8a' # bytes 类型,也叫字节串类型,把它当成二进制数据即可 res2 = res.decode('utf-8') # 将硬盘中的utf-8 格式的二进制数据解码成unicode 格式的二进制数据 print(res2) # 上 """
另一种写法
x = '上' res1 = bytes(x, encoding='utf-8') print(res1) print(str(res1, encoding='utf-8')) # b'\xe4\xb8\x8a' # 上
扩展小案例
""" 你a他 --- utf-8 1Bytes|1Bytes|1Bytes |1Bytes |1Bytes|1Bytes|1Bytes 你 a 他 1+7bit 第一个是标识位,标识这个数据要占几个bytes, 然后就读几个 utf-8 编码标准中一个中文占 3个Bytes """
文件操作
文件是 # 操作系统提供给用户操作复杂硬件(硬盘)的简易接口 , # 人们或者程序需要永久地保存数据所以要操作文件
怎么操作文件
通过 python 的内置函数 open() 即可拿到文件对象( f(文件句柄) = open(r'文件路径及文件名', '模式(读写)', encoding='编码方式') )
r(即 real) 是字符串的修饰符,忽略字符串的转义,将传入的文件路径仅当做字符串看待(里面的转义字符也当成普通字符串)
文件对象(文件句柄)操作如下(常见)
''' # 光标位置会随操作而变化 # 移动的单位都是字节或者行 f.name # 返回文件对象的名字(即open 中传的第一个参数) E:\PyCharm 2019.1.3\ProjectFile\file_test.txt file_test.txt
f.close() # 关闭文件对象并解除占用,一般打开了文件都要记得关闭
f.tell() # 返回当前光标在文件中的位置(第几字节,read等方法会将光标后移) # 光标:很多操作(读写)都会改变光标的位置,文件的读写操作基本都是基于光标开始的
f.seek() # 指定光标在文件的位置,第一个参数是偏移量(字节数为单位),第二个参数有三个可选值(0, 1,2)默认值为 0。给offset参数一个定义,表示要从哪个位置开始偏移; # 0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。
f.truncate() # 不指定参数是指从当前位置开始截断 之前未测试出效果是因为使用的是a模式,光标在文件末尾 我又没有将光标移动到文件开头,在文件末尾截断,当然啥变化也没有, 把光标移动到文件开头就可以看到效果了(f.seek(0, 0) 再f.truncate() 就会把这个文件内容都删掉)) 指定参数是从开头到参数所指字节处之后的数据全部截断(删除)
f.flush() # 用来刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区。 一般情况下,文件关闭后会自动刷新缓冲区,但有时你需要在关闭前刷新它,这时就可以使用 flush() 方法。 提前使用这个方法可以避免在程序运行中因断电时而丢失数据(调用f.flush() 之前的数据都刷到硬盘上了) # 其他方法根据模式来分类讲解 '''
模式及部分模式下可用方法(这一块复制到pycharm里面去看可能会好点)
''' 模式 描述 基础模式 r 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 注意点:在打开文件的时候,文件必须事先存在,如果文件不存在,直接报错 读完一次之后,文件的光标已经在文件末尾了,再读就没有内容可读了 方法:read()、readline()、readlines()、for in 文件对象 如果是b模式下,最好给读出来的数据后面加上 decode参数(f.read(10).decode('utf-8')),转换成能看懂的 read():读文件,一次性将文件内容全部读出(太大的文件会直接造成内存溢出) rb 模式(.read())读文件时候可以直接返回二进制 readline():只读文件一行内容 原理也是光标移动,到末尾就读不出来了 可以代替 f.read(),一行一行的读取,节省内存空间,解决大文件一次性读取的问题 readlines():返回的是一个列表,列表中的一个个元素对应的是文件的一行行内容 一次性读取(文件大会很占内存),差不多可以理解成read 高级版,转成list了 for in 文件对象:同 readline() 一行一行读 文件对象f 可以被for 循环,每for 循环一次读一行内容 可以代替 f.read() 优化,节省内存空间,可以解决大文件一次性读取的问题(但一行的数据量太大也起不到太大效果) w 打开一个文件只用于写入。 如果该文件已存在则打开文件,并清空内容从开头开始编辑。如果该文件不存在,创建新文件。 注意点:一定要慎用,一运行就会把文件里的内容清空,当文件存在的情况下会先清空文件内容再写入 文件不存在的情况下会自动创建该文件 方法:write()、writelines() write():不会自动给换行,可以用 \r 或 \n 换行(只写一个就行了,两个都能换行) writelines():基于列表可以一次性写入多行 等价于 for i in 列表,多次write a 打开一个文件用于追加。如果该文件已存在,光标会移到文件末尾,新的内容会追加到已有内容之后。 如果该文件不存在,创建新文件进行写入。 注意点:当文件不存在的情况下,自动创建该文件 当文件存在的情况下,不清空文件内容,文件的光标会移到文件的最后(所以a模式直接读取是读取不到内容的) 方法:同w 模式 t 文本模式 (默认),含有该模式时需要指定encoding 编码标准,如果不指定就是操作系统默认编码标准。 b 二进制模式(一般处理除文本文件之外的文件格式都需要指定这个模式) 注意点:含有该模式时不能指定encoding 编码标准,否则会直接报错 x 写模式,新建一个文件,如果该文件已存在则会报错。 + 打开一个文件进行更新(可读可写)。 U 通用换行模式(不推荐)。 组合模式 a+ 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。 文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 w+ 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。 如果该文件不存在,创建新文件。 r+ 打开一个文件用于读写。文件指针将会放在文件的开头。 ab、ab+ 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。 也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 rb、rb+ 以二进制格式与只读模式打开一个文件,光标将会放在文件的开头,一般用于非文本文件,如图片等。 wb、wb+ 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。 如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 判断该文件对象是否可读可写的方法 .readable():是否可读,返回值布尔类型 .writable():是否可写,返回值布尔类型 '''
关闭文件对象,接收它的变量会怎么样 # f.close()之后变量依旧存在,但是还想接着用 f.文件操作就会报错
with上下文操作# 使用with 上下文操作可以省去 f.close 操作,代码块运行完会自动执行 f.close # 具体用法看下面的操作案例即可
检测文件变化(文件末尾改动版)
with open(r'test01.txt', 'rb') as f: # 先将光标移到文件末尾 f.seek(0, 2) while True: res = f.readline() # 查看当前光标移动了多少位(字节) # print(f.tell()) if res: # 有值说明文件被修改了 print(f"新增内容为:{res.decode('utf-8')}") else: # 说明没有被操作 pass
利用b 模式拷贝视频文件
# 拷贝文件小案例(b 模式用在非文本文件的情况下比较合适) # 文件后缀指定让操作系统可以直接识别 with open(r'用户体验如何驱动产品设计.mp4', mode='rb') as file,\ open(r'用户体验如何驱动产品设计.mp4_copy.mp4', mode='wb') as new_file: for line in file: new_file.write(line) print('copy finished!')
通过seek在指定位置添加内容
test.txt 文件内容如下
你追我
你追到我
我就让你嘿嘿嘿
代码如下
with open(r'test.txt', 'r+', encoding='utf-8') as f: # 在追和我中间加个h f.seek(6, 0) f.write('h') # 乱码了,因为英文字符只占1 个字节,而硬盘的原理是旋转,所以添加内容其实是覆盖,而覆盖到后面的字节,导至汉字的三个字节被占掉一个,在关系对照表中找不到对应的内容就乱码了 # 你追h�� # 你追到我 # 我就让你嘿嘿嘿
修改文件内容(两种方式及一个错误案例)
修改文件内容
修改文件内容.txt 文件内容如下
jason 横行霸道,但是就喜欢他这样
jason 横行霸道,但是就喜欢他这样
这样
代码如下
# 下面的方法不是真的修改------不同长度有错误 with open(r'E:\PyCharm 2019.1.3\ProjectFile\day08test\修改内容.txt', 'r+', encoding='utf-8') as file: # res = '' # for line in file: # if 'egon' in line: # res += line.replace('egon', 'jason') res = file.read() # res = res.replace('egon', 'jason') res = res.replace('jason', 'egon') # r+ 模式修改,如果替换的字节数不同,会出现问题 # egon 横行霸道,但是就喜欢他这样 # egon 横行霸道,但是就喜欢他这样 # 这样 file.seek(0, 0) file.write(res) # 方式1:先r模式读出来改,再w模式写 # 缺陷:当文件过大的情况下,可能会造成文件溢出 # 优点:任何时候,硬盘上只有一个文件,不会过多占用硬盘空间 with open(r'E:\PyCharm 2019.1.3\ProjectFile\day08test\修改内容.txt', 'r', encoding='utf-8') as file: res = file.read() res = res.replace('jason', 'egon') with open(r'E:\PyCharm 2019.1.3\ProjectFile\day08test\修改内容.txt', 'w', encoding='utf-8') as file: file.write(res) # 方式2:创建一个新的文件 # 循环读取老文件内容到内存进行修改,然后将修改好的内容写到新文件中 # 将老文件删除,将新文件的名字改成老文件 # 优点:内存中始终只有一行内容,不占内存 # 缺点:在某一时刻,硬盘中会同时存在两个文件(时间很短),会占用硬盘空间 import os # 引用os模块,使用他里面的remove 和 rename方法 with open(r'E:\PyCharm 2019.1.3\ProjectFile\day08test\修改内容.txt', 'r', encoding='utf-8') as read_f,\ open(r'E:\PyCharm 2019.1.3\ProjectFile\day08test\修改内容-swap.txt', 'a', encoding='utf-8') as write_f: for line in read_f: write_f.write(line.replace('jason', 'egon')) os.remove(r'E:\PyCharm 2019.1.3\ProjectFile\day08test\修改内容.txt') os.rename(r'E:\PyCharm 2019.1.3\ProjectFile\day08test\修改内容-swap.txt', 'E:\PyCharm 2019.1.3\ProjectFile\day08test\修改内容.txt')
文件操作个人小结
# 文件操作一般就是读文件、写文件,不会对同一个文件又读又写的的 # 因为数据想理论永久存储都是放在硬盘上的,而硬盘的原理就是高速旋转读写数据,所以修改文件基本都是覆盖或者文件替换 # 硬盘数据删除原理,根据标志位(叫自由态)来确定是否可存(避免覆盖),改了标志位就代表可以存数据 # a模式就是固定的末尾添加,不论控制光标在哪儿都只能在文件末尾追加信息 # seek方法移动光标,在t模式下很受限,第二个参数只有 0 这个选项值可以用(b模式下0 1 2都可以用) # read在b模式和r 模式下所加参数的意义不同(r模式以字符为单位,b模式以字节为单位) # 在utf-8编码标准下,中文是3个字节,英文是1个字节,所以seek、read等移动光标时要注意单位 # s = "测试ee" # print(len(s.encode('utf-8'))) # 这样可以获取到字符串所占的字节数长度 # 8 # b模式下read出来的数据不要忘了加上 decode解码,b模式编码后的数据看不懂,要转成utf-8的才有可读性 # a+模式下直接read系列方法会读不出来数据,因为此时光标在文件的末尾,读不出来数据 # 其实相对路径可能较绝对路径会好一点,比如你把整个项目从D盘移动到了E盘,如果是绝对路径,那么项目运行到文件操作这里可能就会报错了,而相对路径还是没变,就不会有这个问题 # r'' 前面的r 是字符串中的修饰符,除此之外还有b u
个人扩展小案例


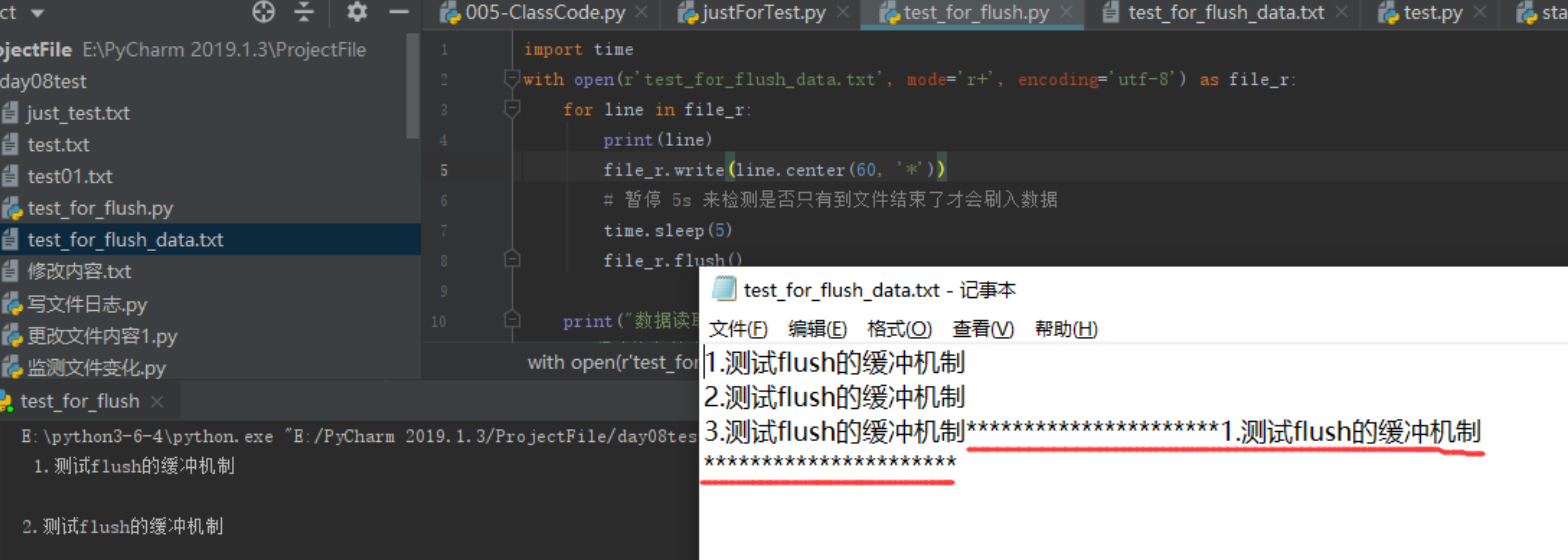
''' test_for_flush_data.txt 文件初始内容如下: 1.测试flush的缓冲机制 2.测试flush的缓冲机制 3.测试flush的缓冲机制 ''' import time with open(r'test_for_flush_data.txt', mode='r+', encoding='utf-8') as file_r: for line in file_r: print(line) file_r.write(line.center(60, '*')) # 暂停 5s 来检测是否只有到文件结束了才会刷入数据 time.sleep(5) print("数据读取完毕!") print('程序执行结束')
没有调用flush的情况下,程序执行完了才写入(个人思考延伸: # 存入多个用户数据,程序未执行结束,未刷入硬盘,即未默认调用flush,数据就还没到硬盘中去,此时用刚写入的用户数据登录可能就会出问题,因为他还不存在 )

调用flush, 会在文件操作结束之前就已将部分数据刷入硬盘
统计python代码行数
def statistic_lines(filepath): ''' 单文件统计代码行数、注释行数、空行行数 填写倒数第三行的文件路径 :param filepath: :return: ''' content_raw = 0 comment_raw = 0 pure_blank_raw = 0 is_block_comment = False is_block_str = False with open(filepath, mode='rt', encoding='utf-8') as file: if not file.readable(): print("您的文件不存在,请您仔细核对路径是否有误!") else: for line in file: line = line.strip() is_content_flag = False # 要排除掉那些非内容的行 # 考虑过滤掉块状字符串定义 = ''' = """ =''' =""" if "= '''" in line or "='''" in line or '= """' in line or '="""' in line: # 第一行注释进来了。。。。 is_block_str = True # 包含 ''' 或 """ ,但又不是注释的 ---> 块状字符串定义结束 # 换行符也占字节数 --> """ --> 4~5个字符 elif ("'''" in line or '"""' in line) and len(line) > 5: is_block_str = False # 块注释,要过滤中间的内容 if line.startswith("'''") or line.startswith('"""') or is_block_comment: if not is_block_comment: # 排除字符串定义与块定义弄混 if is_block_str: is_content_flag = True is_block_str = False else: is_block_comment = True comment_raw += 1 else: if line.startswith("'''") or line.startswith('"""'): is_block_comment = False comment_raw += 1 elif line.startswith("#"): comment_raw += 1 # 过滤空行,tab不知道能不能处理 elif len(line) == 0: pure_blank_raw += 1 else: is_content_flag = True if is_content_flag: content_raw += 1 # print(line, end='') print(f"\n您的文件总共有{content_raw + comment_raw + pure_blank_raw + 1}行,其中共有注释{comment_raw}行,纯空行{pure_blank_raw + 1}行(注释内的排除在外),内容{content_raw} 行。") # 最后一行的空行不计入(测试结果做了+1 处理),空格与tab 编辑器默认不保留(写了保存,然后还是没有) # file_path = r'statistics_file_raws.py' # file_path = r'test.py' # file_path = r'test2222.py' # file_path = r'calss_test.py' file_path = r'2019-7-8-practise.py' # 如果用 a 或 w 模式,不存在的文件就会自动创建 statistic_lines(file_path) # 您的文件总共有120行,其中共有注释18行,纯空行18行(注释内的排除在外),内容84 行。
已知bug:(是时候考验一下你的实力了)
print(""" 像这样的就会引发数据统计大量不准确... 后面的都默认成注释了。。。 其实可以在判断注释的时候 startswith 和 endswith 都是 \""" ''' 才作为注释,但不想局限死,况且不是真正产品,在上面浪费太多时间不好(\为了防止结束字符串) """)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号