Python re标准库
re模块包含对正则表达式的支持。
一、什么是正则表达式
正则表达式是可以匹配文本片段的模式。最简单的正则表达是就是普通字符串,可以匹配其自身。你可以用这种匹配行为搜索文本中的模式,或者用计算后的值替换特定模式,或者将文本进行分段。
1、通配符
点号(.)可以匹配任何字符(除了换行符),但点号只能匹配一个字符,而不是零个或多个;
如.ython可以匹配字符串‘python’或‘jython’,或‘+ython’等等,但是不会匹配‘cpython’或‘ython’;
因为它可以匹配除换行符外的任何单个字符,所以点号就称为通配符。
注:点号是特殊字符,需对它进行转义。可以加上反斜线“cnblogs\\.com”或者使用原始字符串“r'cnblogs\.com'”;
2、字符集
可以使用中括号括住字符串来创建字符集。字符集可以匹配它所包括的任意字符;
如‘[pj]ython’可以匹配python或jython;比如‘[a-z]’可以匹配a到z的任意一个字符;
也可以通过一个接一个的方式将范围联合起来使用,比如‘[a-zA-Z0-9]’可以匹配任意一个小写或大写字母或0到9的数字;
可以在开头使用‘^’反转字符集,匹配除字符集外的其它字符;如‘[^abc]’可以匹配任何除了a\b\c之外的字符。
3、选择符和子模式
管道符号(|)可以用于选择项;如匹配python和perl,可以写成‘python|perl’
当只是模式的一部分进行选择时,可以使用圆括号括起需要的部分,或称为子模式。如匹配python和perl,可以写成‘p(ython|erl)’
4、可选项和重复子模式
在子模式后面加上句号,它就变成了可选项,即表示子模式可以出现一次或者根本不出现。
如r'(http://)?(www\.)?python\.org'只能匹配到下列字符串,而不会匹配其它的:
http://python.org
http://www.python.org
www.python.org
python.org
上述例子,值得注意的是:
(1)对www.和python.org之间的点号进行了转义,防止它被作为通配符使用;
(2)使用原始字符串“r”减少所需反斜线的数量;
(3)每个可选子模式都用圆括号括起;
(4)可选子模式出现与否均可,而且互相独立;
使用下面这些运算符允许子模式重复多次:
- (pattern)*:允许模式重复0次或多次;
- (pattern)+:允许模式重复1次或多次;
- (pattern){m,n}:允许模式重复m~n次;
例如,r'w*\.python\.org'会匹配'www.python.org',也会匹配'.python.org’;
5、字符串的开始和结尾
如果想在字符串的开头而不是其他位置匹配,可以使用脱字符(^)标记开始;
如‘^ht+p’会匹配‘http://python.org’或'htttp://python.org',但不匹配‘www.http.org’;
使用美元符号($)标志字符串结尾。
二、re模块的内容
re模块包含一些有用的操作正则表达式的函数:
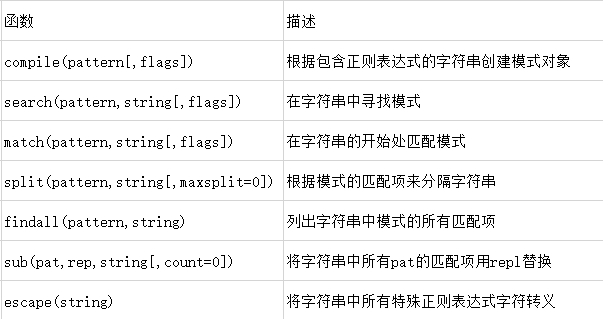
函数re.compile将正则表达式(以字符串书写的)转换为模式对象,可以实现更有效率的匹配。如果调用search或者match函数的时候使用字符串表示的正则表达式,它们也会在内部将字符串转换为正则表达式对象。 使用compile完成一次转换后,在每次使用模式的时候就不用进行转换。
函数re.search会在给定字符串中寻找第一个匹配给定正则表达式的子字符串。一旦找到子字符串,函数就会返回MathObject(值为True),否则返回None(值为False)。
函数re.match会在给定字符串的开头匹配正则表达式。如match('p','python')返回真,而re.match('p','www.python')则返回假。
函数re.split会根据模式的匹配项来分隔字符串。参数maxsplit表示字符串最多可以分隔的次数:
import re text = 'a,b,,,,c d'
#
#正则表达式中,匹配逗号和空格 listvalue = re.split('[, ]+',text) print(listvalue) #['a', 'b', 'c', 'd'] print(re.split('o(o)','foobar')) #['f', 'o', 'bar'] print(re.split('[, ]+',text,maxsplit=1)) #['a', 'b,,,,c d']
函数re.findall以列表形式返回给定模式的所有匹配项。
pat = '[a-zA-Z]' text2 = '"aq," bp,,,,ct rd' print(re.findall(pat,text2)) #['a', 'q', 'b', 'p', 'c', 't', 'r', 'd']
函数re.sub的作用在于:使用给定的替换内容将匹配模式的子字符串(最左端并且非重叠的子字符串)替换掉。
pat3 = '{name}' text3 = 'Dear {name}' print(re.sub(pat3, 'Jame', text3)) #Dear Jame
函数re.escape可以对字符串中所有可能被解释为正则运算符的字符进行转义。
print(re.escape('www.python.org')) #www\.python\.org
三、匹配对象和组
re模块函数能找到匹配项时,它们会返回MathObject对象,这些对象包括匹配模式的子字符串的信息,它们还包含了哪个模式匹配了子字符串哪部分的信息,这些部分叫做组(group)。
即组就是放置在圆括号内的子模式。组的序号取决于它左侧的括号数。组0就是整个模式。
如在下面的模式中:‘there (was a (wee) (cooper)) who (lived in fyfe)’,包含下面这些组:
0 there was a wee cooper who lived in fyfe
1 was a wee cooper
2 wee
3 cooper
4 lived in fyfe
注:这里要区分前面提到的字符集,字符集两边是用中括号括起的,而组是用原括号括起的。
如r'www\.(.+)\.com$' 可以匹配'www.python.com';组0就是‘www.python.com’,组1就是python。
re匹配对象存在以下重要方法:

上诉方法中,[group1]指的是组号。如果没有给定组号,则默认为组0.
m = re.match(r'www\.(.*)\..{3}', 'www.python.org') print(m.group(1)) #python print(m.start(1)) #4 print(m.end(1)) #10 print(m.span(1)) #(4, 10)
重复运算符的匹配是贪婪的,即它会尽可能多的匹配。
在重复运算符后面加上一个问号可以变为非贪婪的。
pat4 = r'\*\*(.+?)\*\*' pat5 = r'\*\*(.+)\*\*' print(re.sub(pat4,r'<em>\1</em>','**this** is **it**!')) #<em>this</em> is <em>it</em>! print(re.sub(pat5,r'<em>\1</em>','**this** is **it**!')) #<em>this** is **it</em>!
这里用+?运算符代替了+,意味着模式也会像之前那样对一个或者多个通配符进行匹配,但是它会进行尽可能少的匹配,因为它是非贪婪的。
让正则表达式变得更加易读的方式是在re函数中使用VERBOSE标志:
em_pat = re.compile(r''' \* #匹配的第一个字符是星号 \* #匹配的第二个字符是星号,这里前面斜杠是转义 ( #匹配组左侧圆括号 . #匹配任意字符 + #任意字符可以是1个或多个 ) #匹配组右侧括号 \*\* #匹配的字符后面跟着两个星号 ''',re.VERBOSE) print(re.sub(em_pat,r'<em>\1</em>','**this** is **it**!')) #<em>this** is **it</em>!
四、实例
文件中存在以下文字:
From foo@bar.baz Thu Dec
Subjec:Re:Span
From:Foo fie <foo@bar.baz>
to:Magnus <magnus@bozz.floop>
现在要从文件中找出是谁发送的邮件,我们可以在‘From:Foo fie <foo@bar.baz>’中找到发件人Foo fie.实现查找:
pat6 = re.compile('From:(.*) <.*?>$') for line in fileinput.input(): m = pat6.match(line) if m:print m.group(1)
本文主要摘自《Python基础教程》一书
持续学习中,,,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号