解决latex数学公式渲染不正确及行内公式中文渲染乱码问题
问题
之前数学OCR渲染数学公式用的 katex 来渲染,前端解决方案,我们的进行公式编写的时候是需要输入中文的,如:
Fe_{2}O_{3} + 3 C O \stackrel{高温}{=} 2 F e + 3CO_{2}
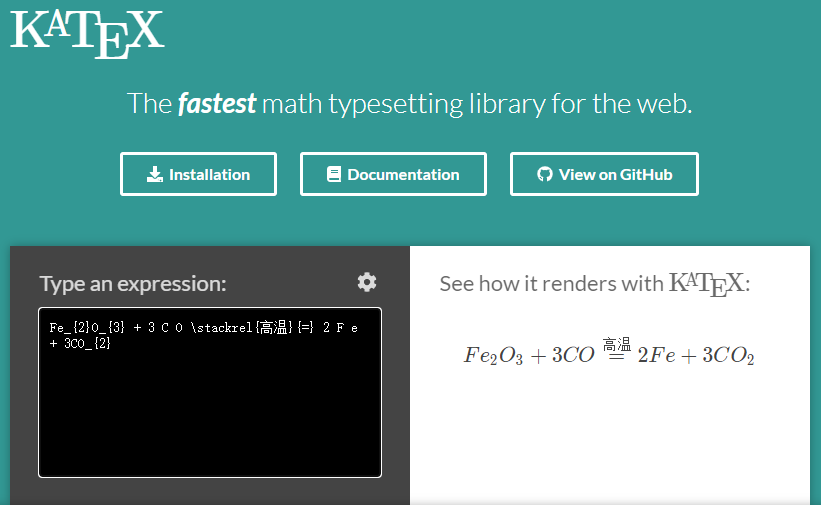
抑或:
c = \sqrt{a^{平方}+b_{xy}^{平方}+e^{x次方}}
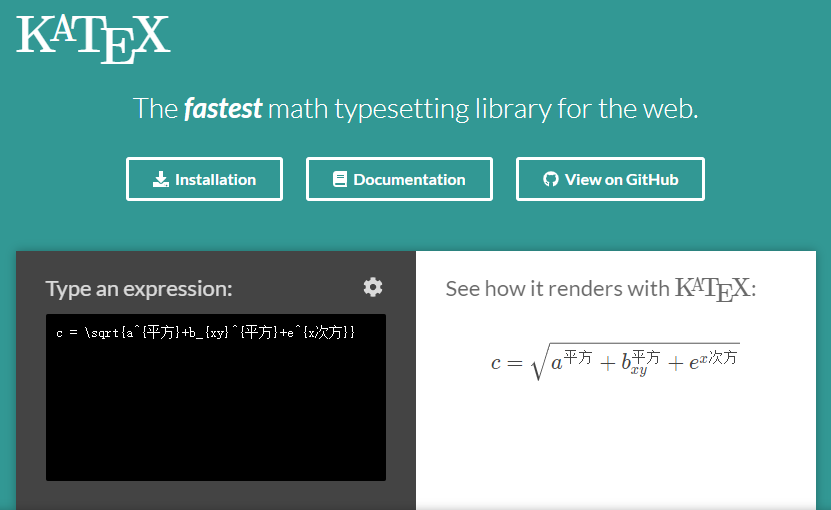
在上篇 解决Latex输出PDF纸张自适应大小及中文无法显示问题,需要支持化学式识别,我们的服务是支持全量的latex语法,所以化学式和数据公式统一使用新服务来进行识别,毕竟katex就是latex的一个快速web数学公式渲染器,现在把两个公式合并一下在我们的服务上渲染一下试试
Fe_{2}O_{3} + 3 C O \stackrel{高温}{=} 2 F e + 3CO_{2}\\c = \sqrt{a^{平方}+b_{xy}^{平方}+e^{x次方}}
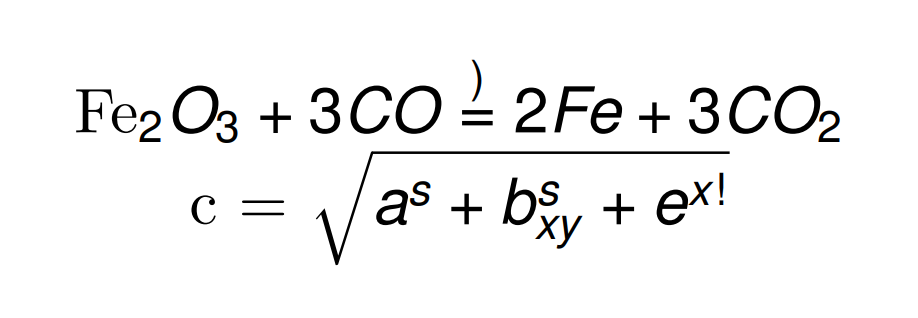
WTF! 中文的问题不是解决了吗?怎么又出问题了, 已经对中文进行了处理,怎么不生效了?
一些例子:
Fe_{2}O_{3} + 3 C O \stackrel{HighTemperature}{=} 2 F e + 3CO_{2}测试中文
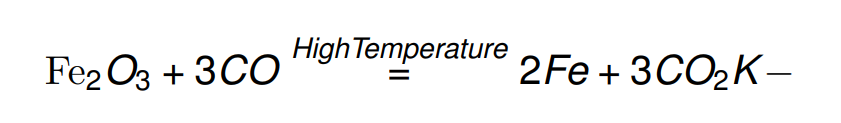
Fe_{2}O_{3} + 3 C O \stackrel{HighTemperature}{=} 2 F e + 3CO_{2}$测试中文
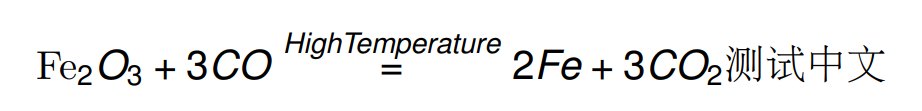
Fe_{2}O_{3} + 3 C O \stackrel{\mbox{高温}}{=} 2 F e + 3CO_{2}

分析
行内公式和行间公式
latex中行内公式和行间公式分别使用 \(** 和 **\)$ 来作为公式的起止符,如果在行内公式显示中文则需要用\mbox{}来包裹中文,这样中文就能在公式中正常显示
之前我们直接在chemfig公式后面直接输入中文,由于chemfig有明显起始判断,我们的中文latex并没有识别为公式的一部分,所以能正常显示,一旦我们在公式内部使用中文,仍然会出现中文无法渲染的问题,不过这个问题在katex下是不存在,应当是katex做了适配
解决办法
方案一:按照标准的latex语法来,用户在输入公式的时候对中文部分自行加入 \mbox{} 或在公式结束位置标记 $结束符,这样行内公式和公式外的中文就能正常显示,合情合理
方案二:由于数学公式没有明显起始标识,所以可以在把传入的字符中所有的连续中文在后台用 \mbox{} 包裹起来,需要在代码中手动截取相应的连续中文并使用mbox包裹即可
解决
毫无疑问,为了保持用户使用的惯性,采取方案二,上代码
def with_mbox(mix_str):
""" 混合字符串自动填充mbox
:param mix_str: chemfig表达式
:return: 自动包裹连续中文的chemfig表达式
"""
flag = False
t = ''
for char in mix_str:
if not flag and is_chinese(char):
flag = True
t += "\\mbox{" + char
elif flag and not is_chinese(char):
t += "}" + char
flag = False
elif is_chinese(char):
t += char
else:
t += char
flag = False
if is_chinese(t[len(t) - 1]):
t += "}"
return t
def is_chinese(check_char):
""" 检查是否中文字符,含中文标点
:param check_char: 字符
:return: True|False
"""
if u'\u4e00' <= check_char <= u'\u9fff' or is_zw_punctuation(check_char):
return True
return False
def is_zw_punctuation(char_arr):
punctuation = """!?。。《》"#$%&'()*+-/:;<=>@[\]^_`{|}~⦅⦆「」、、〃》「」『』【】〔〕〖〗〘〙〚〛〜〝〞〟〰〾〿–—‘'‛“”„‟…‧﹏"""
re_punctuation = "[{}]+".format(punctuation)
result = re.match(re_punctuation, char_arr)
return result is not None
使用前调用一下with_mbox方法 chem_fig = with_mbox(request.json['chemfig']) 完美解决
参考链接
TeX,LaTeX和KaTeX简介:https://blog.csdn.net/wobushisongkeke/article/details/99677578
python 匹配中文字符:https://www.cnblogs.com/iamjqy/p/6824297.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号