浏览器渲染原理 记录备份
解析HTML以构建DOM树 —— 构建render树 —— 布局render树 —— 绘制render树
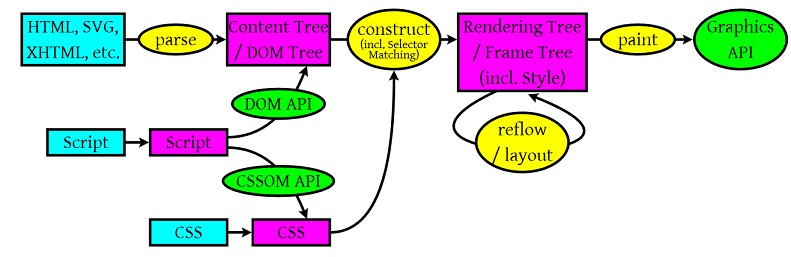
1、构建DOM树(parse):渲染引擎解析HTML文档,首先将标签转换成DOM树中的DOM node(包括js生成的标签)生成内容树(Content Tree/DOM Tree);
2、构建渲染树(construct):解析对应的CSS样式文件信息(包括js生成的样式和外部css文件),而这些文件信息以及HTML中可见的指令(如<b></b>),构建渲染树(Rendering Tree/Frame Tree);
3、布局渲染树(reflow/layout):从根节点递归调用,计算每一个元素的大小、位置等,给出每个节点所应该在屏幕上出现的精确坐标;每当一个新元素加入到这个dom树当中,浏览器便会通过css引擎查遍css样式表,找到符合该元素的样式规则应用到这个元素上。
4、绘制渲染树(paint/repaint):遍历渲染树,使用UI后端层来绘制每个节点。
1) 浏览器会解析三个东西
* 一个 HTML/SVG/XHTML,解析这三种文件会产生一个DOM Tree
* CSS,解析CSS会产生CSS规则树
* JavaScript 脚本,主要是通过 DOM API 和 CSSOM API来操作 DOM Tree 和 CSS Rule Tree
当浏览器获得一个HTML文件时,会自上而下加载,并在加载过程中进行渲染。
* 浏览器会将HTML解析成一个DOM树,DOM的构建过程是一个深度遍历的过程:当前节点的所有子节点都构建好后才会去构建当前节点的下一个兄弟节点。
* 将CSS解析成 CSS Rule tree。
2) 解析完成后,浏览器引擎会通过 DOM Tree(构建DOM树) 和CSS Rule Tree(css 渲染树) 来构造 Rendering Tree(布局渲染树)。

注意:
* Rendering Tree 渲染树并不等同于 DOM Tree,因为一些像 Header 或 display:none 的东西就没必要放在渲染树中。
* CSS 的Rule Tree 主要是为了完成匹配并把CSS Rule附加上 Rendering Tree 上的每个 Element,也就是 DOM 节点,也就是所谓的 Frame。
* 有了Render Tree,浏览器已经能知道网页中有哪些节点、各个节点的CSS定义以及它们的从属关系。
* 然后,计算每个 Frame(也就是每个Element)的位置,这又叫 layout 和 reflow 过程。
3) 最后通过调用操作系统Native GUI的API 绘制 绘制
即遍历render树,并使用UI后端层绘制每个节点
注:display:none 会触发 reflow,而 visibility:hidden 只会触发 repaint,因为没有发现位置变化
注意 :布局渲染树中
重绘(repaint或redraw):当盒子的位置、大小以及其他属性,例如颜色、字体大小等都确定下来之后,浏览器便把这些原色都按照各自的特性绘制一遍,将内容呈现在页面上。
重绘是指一个元素外观的改变所触发的浏览器行为,浏览器会根据元素的新属性重新绘制,使元素呈现新的外观。
触发重绘的条件:改变元素外观属性。如:color,background-color等。
注意:table及其内部元素可能需要多次计算才能确定好其在渲染树中节点的属性值,比同等元素要多花两倍时间,这就是我们尽量避免使用table布局页面的原因之一。
重排(重构/回流/reflow):当渲染树中的一部分(或全部)因为元素的规模尺寸,布局,隐藏等改变而需要重新构建, 这就称为回流(reflow)。每个页面至少需要一次回流,就是在页面第一次加载的时候。
重绘和重排的关系:在回流的时候,浏览器会使渲染树中受到影响的部分失效,并重新构造这部分渲染树,完成回流后,浏览器会重新绘制受影响的部分到屏幕中,该过程称为重绘。
所以,重排必定会引发重绘,但重绘不一定会引发重排。
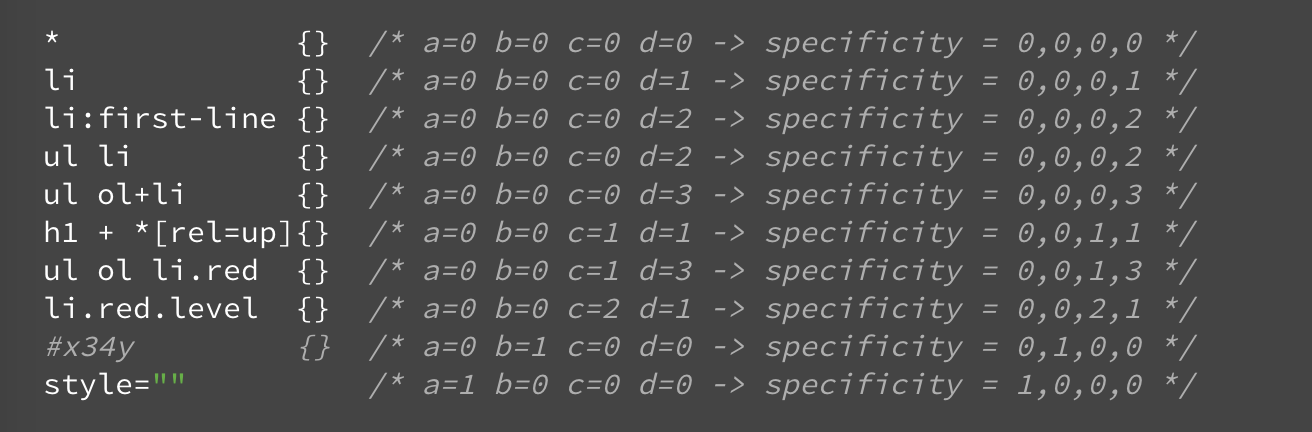
下面讲下 css 匹配规则 如 #nav li {},
CSS 匹配DOM Tree 主要是从右到左解析CSS 的 Selector。所以#nav li 我们以为这是一条很简单的规则,很容易就能匹配到想要的元素,但是CSS会先去找所有的li 元素,然后再去确定它的父元素是不是#nav。
在开始前,我们必须了解一个真相:为什么排版引擎解析 CSS 选择器时一定要从右往左析?
1.HTML 经过解析生成 DOM Tree(这个我们比较熟悉);而在 CSS 解析完毕后,需要将解析的结果与 DOM Tree 的内容一起进行分析建立一棵 Render Tree,最终用来进行绘图。Render Tree 中的元素(WebKit 中称为「renderers」,Firefox 下为「frames」)与 DOM 元素相对应,但非一一对应:一个 DOM 元素可能会对应多个 renderer,如文本折行后,不同的「行」会成为 render tree 种不同的 renderer。也有的 DOM 元素被 Render Tree 完全无视,比如 display:none 的元素。
2.在建立 Render Tree 时(WebKit 中的「Attachment」过程),浏览器就要为每个 DOM Tree 中的元素根据 CSS 的解析结果(Style Rules)来确定生成怎样的 renderer。对于每个 DOM 元素,必须在所有 Style Rules 中找到符合的 selector 并将对应的规则进行合并。选择器的「解析」实际是在这里执行的,在遍历 DOM Tree 时,从 Style Rules 中去寻找对应的 selector。
3.因为所有样式规则可能数量很大,而且绝大多数不会匹配到当前的 DOM 元素(因为数量很大所以一般会建立规则索引树),所以有一个快速的方法来判断「这个 selector 不匹配当前元素」就是极其重要的。
4.如果正向解析,例如「div div p em」,我们首先就要检查当前元素到 html 的整条路径,找到最上层的 div,再往下找,如果遇到不匹配就必须回到最上层那个 div,往下再去匹配选择器中的第一个 div,回溯若干次才能确定匹配与否,效率很低。
5.逆向匹配则不同,如果当前的 DOM 元素是 div,而不是 selector 最后的 em,那只要一步就能排除。只有在匹配时,才会不断向上找父节点进行验证。
6.但因为匹配的情况远远低于不匹配的情况,所以逆向匹配带来的优势是巨大的。同时我们也能够看出,在选择器结尾加上「*」就大大降低了这种优势,这也就是很多优化原则提到的尽量避免在选择器末尾添加通配符的原因。
简单的来说浏览器从右到左进行查找的好处是为了尽早过滤掉一些无关的样式规则和元素 css权重如下
http://stevesouders.com/efws/css-selectors/baseline.php css选择器测试
导致重排 回流 reflow
clientWidth、clientHeight、clientTop、clientLeft
offsetWidth、offsetHeight、offsetTop、offsetLeft
scrollWidth、scrollHeight、scrollTop、scrollLeft
scrollIntoView()、scrollIntoViewIfNeeded()
getComputedStyle()
getBoundingClientRect()
scrollTo()
还有display:none 到block
css 分层展示
这是由 z-index CSS 属性指定的。它代表了框的第三个维度,也就是沿“z 轴”方向的位置。
这些框分散到多个堆栈(称为堆栈上下文)中。在每一个堆栈中,会首先绘制后面的元素,然后在顶部绘制前面的元素,以便更靠近用户。如果出现重叠,新绘制的元素就会覆盖之前的元素。
堆栈是按照 z-index 属性进行排序的。具有“z-index”属性的框形成了本地堆栈。视口具有外部堆栈。
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>

1. 用户输入网址(假设是个html页面,并且是第一次访问),浏览器向服务器发出请求,服务器返回html文件;
2. 浏览器开始载入html代码,发现<head>标签内有一个<link>标签引用外部CSS文件;
3. 浏览器又发出CSS文件的请求,服务器返回这个CSS文件;
4. 浏览器继续载入html中<body>部分的代码,并且CSS文件已经拿到手了,可以开始渲染页面了;
5. 浏览器在代码中发现一个<img>标签引用了一张图片,向服务器发出请求。此时浏览器不会等到图片下载完,而是继续渲染后面的代码;
6. 服务器返回图片文件,由于图片占用了一定面积,影响了后面段落的排布,因此浏览器需要回过头来重新渲染这部分代码;
7. 浏览器发现了一个包含一行Javascript代码的<script>标签,赶快运行它;
8. Javascript脚本执行了这条语句,它命令浏览器隐藏掉代码中的某个<div> (style.display=”none”)。突然少了这么一个元素,浏览器不得不重新渲染这部分代码;
9. 终于等到了</html>的到来,浏览器泪流满面……
10. 等等,还没完,用户点了一下界面中的“换肤”按钮,Javascript让浏览器换了一下<link>标签的CSS路径;
11. 浏览器召集了在座的各位<div><span><ul><li>们,“大伙儿收拾收拾行李,咱得重新来过……”,浏览器向服务器请求了新的CSS文件,重新渲染页面。
参考
https://www.cnblogs.com/yc-755909659/p/6599553.html
How Browsers Work 这篇文章
浏览器的工作原理:现代网络浏览器幕后揭秘 - HTML5 Rockswww.html5rocks.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号