
标签(空格分隔): requests
环境配置
- pip install requests
get请求:
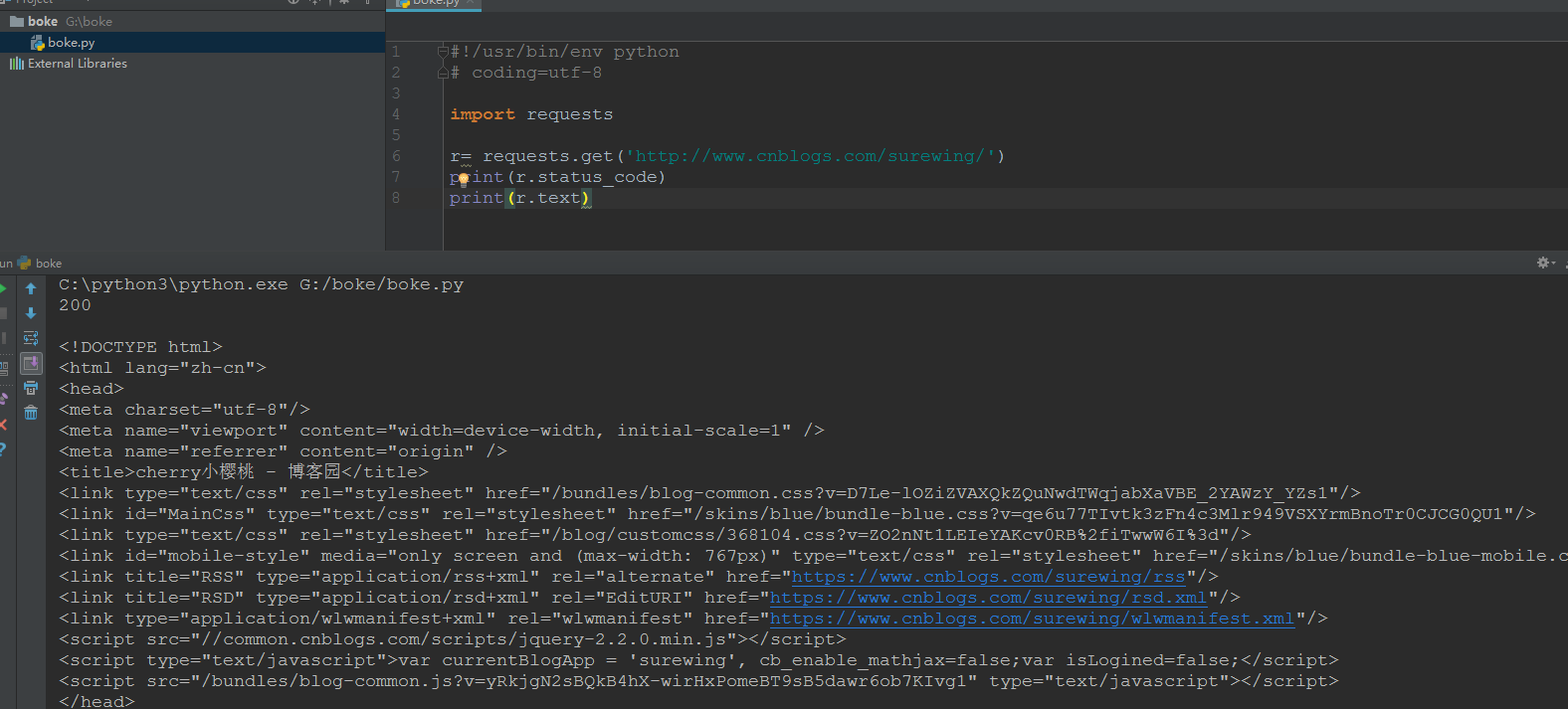
1.导入requests后,用get方法就能直接访问url地址,如:http://www.cnblogs.com/surewing/,看起来是不是很酷
2.这里的r也就是response,请求后的返回值,可以调用response里的status_code方法查看状态码
3.状态码200只能说明这个接口访问的服务器地址是对的,并不能说明功能OK,一般要查看响应的内容,r.text是返回文本信息
params
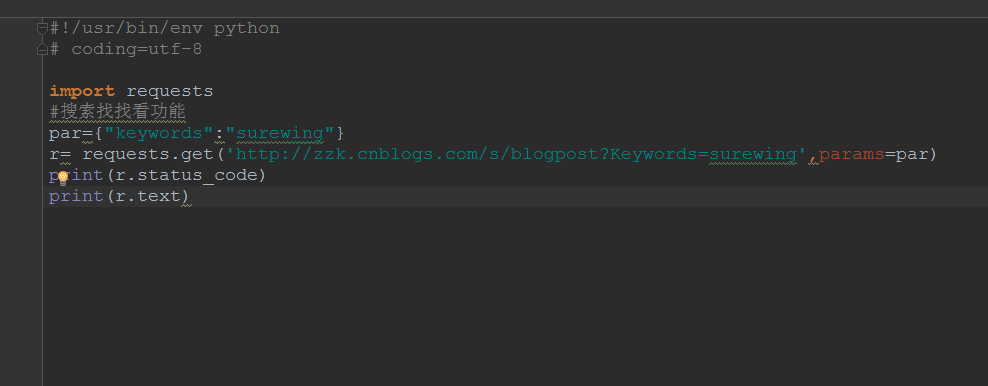
1.再发一个带参数的get请求,如在博客园找找看:surewing,url地址为:http://zzk.cnblogs.com/s/blogpost?Keywords=surewing
2.请求参数:Keywords=surewing,可以以字典的形式传参:{"Keywords": "surewing"}
3.多个参数格式:{"key1": "value1", "key2": "value2", "key3": "value3"}
content
1.我们有时候响应的结果如果有乱码,是需要解码,在fiddler里面就是如此的;
2.在代码里面,他会的内容会自动解码的;
3.content会自动解码 gzip 和deflate压缩
response
1.response的返回内容还有其它更多信息
r.status_code #响应状态码
r.content #字节方式的响应体,会自动为你解码 gzip 和 deflate 压缩
r.headers
以字典对象存储服务器响应头,但是这个字典比较特殊,字典键不区分大小写,若键不存在则返回None
r.json() #Requests中内置的JSON解码器
r.url # 获取url
r.encoding # 编码格式
r.cookies # 获取cookie
r.raw #返回原始响应体
r.text
字符串方式的响应体,会自动根据响应头部的字符编码进行解码
r.raise_for_status() ,#失败请求(非200响应)抛出异常
data和json区分:
在发post请求的时候,有时候body部分要传data参数,有时候body部分又要传json参数,那么问题来了:到底什么时候该传json,什么时候该传data?
1.post请求的body通常有四种类型,最常见的就是json格式了,这个还是很好识别的:

2.用抓包工具查看,首先点开Raw去查看body部分,如下图这种,参数最外面是大括号{ }包起来的,这种已经确诊为json格式了。
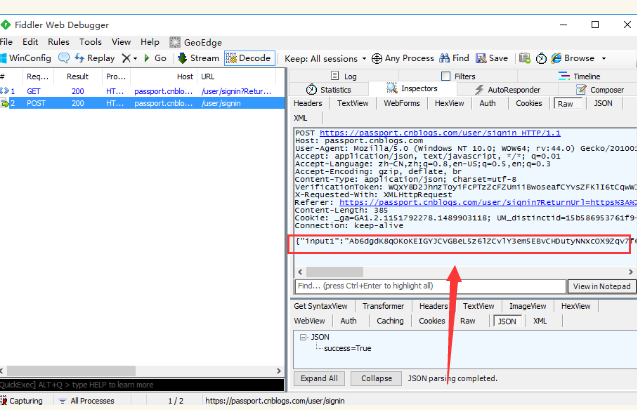
3.再一次确认,可以点开Json这一项查看,点开之后可以看到这里的几组参数是json
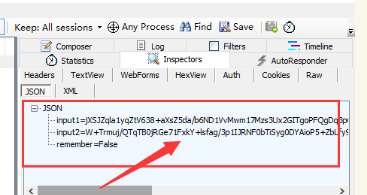
二、识别data参数
1.data参数也就是这种格式:key1=value1&key2=value2...这种格式很明显没有大括号
点开Raw查看,跟上面的json区别还是很大的
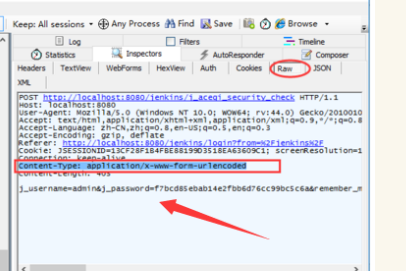
2.因为这个是非json的,所以点开Json这个菜单是不会有解析的数据的,这种数据在WebForms里面查看
3.可以看到这种参数显示在Body部分,左边的Name这项就是key值,右边的Value就是对应的value值,像这种参数转化从python的字典格式就行了
json数据处理
有些post的请求参数是json格式的,需要导入json模块处理;
一般常见的接口返回数据也是json格式的,我们在做判断时候,往往只需要提取其中几个关键的参数就行,这时候就需要json来解析返回的数据。
encode:Encode(python->json)
1.首先说下为什么要encode,python里面bool值是True和False,json里面bool值是true和false,并且区分大小写,这就尴尬了,明明都是bool值。
在python里面写的代码,传到json里,肯定识别不了,所以需要把python的代码经过encode后成为json可识别的数据类型。
2.举个简单例子,下图中dict类型经过json.dumps()后变成str,True变成了true,False变成了fasle
#!/usr/bin/env python
# coding=utf-8
import requests
import json
payload={'wing':True,
"json":False,
'python':'22222345'}
print(type(payload))
#转化为json格式:
data_json = json.dumps(payload)
print(type(data_json))
print(data_json)
执行结果:
<class 'dict'>
<class 'str'>
{"wing": true, "json": false, "python": "22222345"}
decode(json->python)
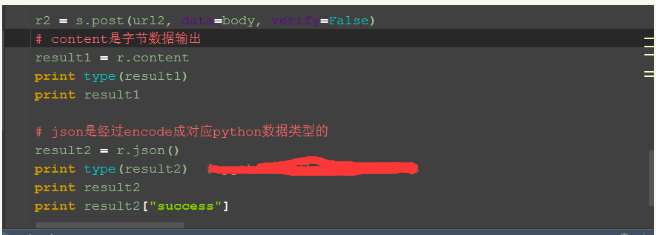
1.如果一个例子的结果:{"success":true},我们其实最想知道的是success这个字段返回的是True还是False
2.如果以content字节输出,返回的是一个字符串:{"success":true},这样获取后面那个结果就不方便了
3.如果经过json解码后,返回的就是一个字典:{u'success': True},这样获取后面那个结果,就用字典的方式去取值:result2["success"]
二、
1.比如打开快递网:http://www.kuaidi.com/,搜索某个单号,判断它的状态是不是已签收
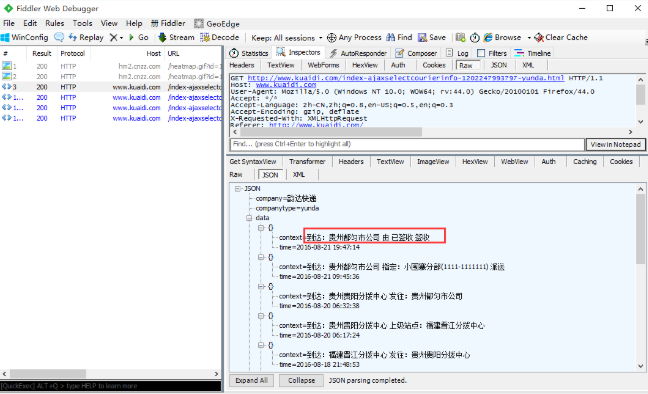
2.代码如下:
#!/usr/bin/env python
# coding=utf-8
import requests
url = "http://www.kuaidi.com/index-ajaxselectcourierinfo-1202247993797-yunda.html"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"}# get方法其它加个User-Agent就可以了
s = requests.session()
r = s.get(url, headers=headers,verify=False)
result = r.json()
data = result["data"]# 获取data里面内容
print(data)
print(data[0])# 获取data里最上面有个
get_result = data[0]['context']# 获取已签收状态
print(get_result)
if u"已签收" in get_result:
print("快递单已签收成功")
else:
print("未签收")
常见网站登录案例参考(github源码下载)
github上常见的一些网站登录案例参考:
1. 知乎:https://github.com/xchaoinfo/fuck-login/tree/master/001 zhihu
2. 126:https://github.com/xchaoinfo/fuck-login/tree/master/002 126
3.微博:https://github.com/xchaoinfo/fuck-login/tree/master/003 weibo.cn其它更多:https://github.com/xchaoinfo/fuck-login

 浙公网安备 33010602011771号
浙公网安备 33010602011771号