一起学RISC-V汇编第11讲之内嵌汇编
内嵌汇编(Inline Assembly),允许在高级语言(c或c++)中嵌入汇编语言,从而实现汇编语言和高级语言混合编程。
我之前的一篇学习笔记讲过内嵌汇编,见risc-v GCC内嵌汇编,但是有些地方写得不详细,所以重新写一遍,一部分是copy之前的笔记,另外一部分内容参考《汇编语言编程基础 基于LoongArch》。
1 内嵌汇编示例
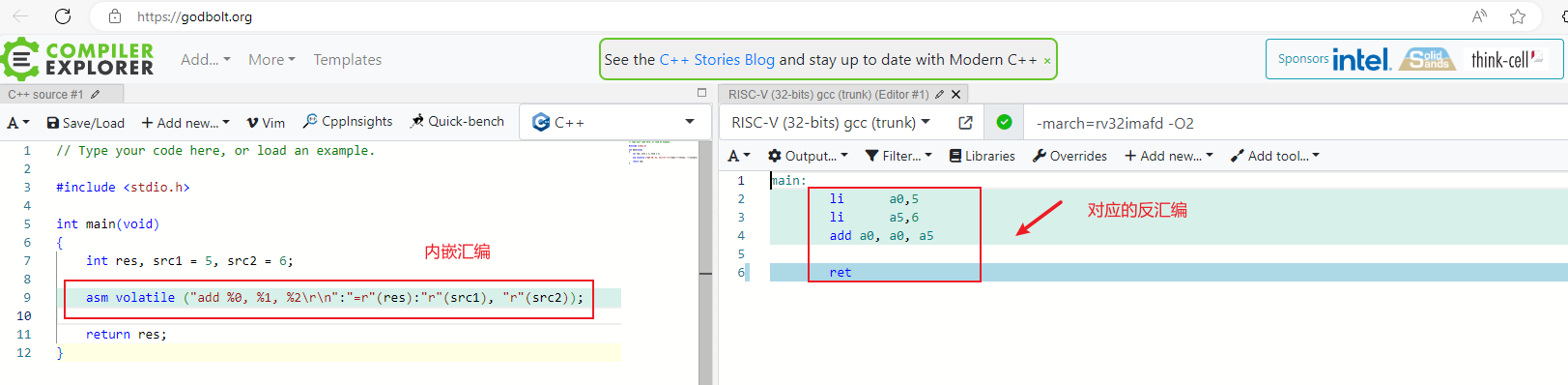
下例中内嵌汇编表示res = src1 + src2,其中res,src1,src2 都是C语言中的变量。
int main(void)
{
int res, src1 = 5, src2 = 6;
asm volatile ("add %0, %1, %2\r\n":"=r"(res):"r"(src1), "r"(src2));
return res;
}
其对应的反汇编如图右所示,可以看出,相对于汇编源程序,内嵌汇编省去了加载到寄存器的过程,也即内嵌汇编将一些分配寄存器的工作交给了GCC编译器完成,操作数可以是寄存器或者C语言变量,从这个方面来看,内嵌汇编比汇编源程序(上一讲内容)要方便。
2 内嵌汇编样式
内嵌汇编样式如下:
asm volatile (
"Instruction_l;\
Instruction 2;\
...\
Instruction_n;"
:"=r"(valuel),
"=r"(value2),
"=r"(valuen)
:"r"(valuel),
"r"(value2),
"r"(valuen)
:"r0","r1",..."rn"
);
其中冒号:将括号中的内容分为4部分(用冒号分开):
asm volatile( 汇编指令列表
∶ 输出操作数(非必需)
∶ 输入操作数(非必需)
∶ 破坏描述部分(非必需));
2.1 模版关键字
关键字 asm volatile或(asm volatile),asm 表示是内嵌汇编操作,必需的关键字,用于通知编译器括号中的内容为内嵌汇编,需要特殊处理, volatile是可选的关键字,使用volatile表示gcc不进行任何优化。
2.2 汇编指令列表
要嵌入的汇编指令,里面包含0条或者多条内嵌汇编指令,每条指令应该被双引号括起来作为字符串,指令以\n 或者;作为分隔符。
对于0条汇编指令的asm(""),编译器对其不做处理且编译后无任何汇编指令生成。
汇编指令列表的几种样式:
指令列表可以有如下几种样式,指令以\n 或者;作为分隔符。
样式1:每条指令被双引号括起来作为字符串,指令以\n作为分隔符
样式2:每条指令被双引号括起来作为字符串,指令以;作为分隔符
样式3和4用连接符\ 将多行连在一起,所以只需双引号括将整个汇编列表括起来,每条指令还是以\n 或者;作为分隔符
样式1:
"Instruction_l\n"
"Instruction 2\n"
"...\n"
"Instruction_n\n"
样式2:
"Instruction_l;"
"Instruction 2;"
"...;"
"Instruction_n;"
样式3:
"Instruction_l\n\
Instruction 2\n\
...\n\
Instruction_n\n"
样式4:
"Instruction_l;\
Instruction 2;\
...\
Instruction_n;"
如果内嵌汇编中只有汇编指令,不需要操作数,则输出操作数、输入操作数和破坏性描述部分包括:都可以省略。
例如RISC-V中实现死循环,只有汇编指令部分:
asm volatile (
"myloop: \n"
"j myloop \n"
);
注意:如果内嵌汇编中仅使用了后面部分,其前面部分为空,那么前面部分也需要使用“:”分隔。例如下面的示例中,内嵌汇编中有输入操作数但是没有输出操作数和破坏描述,那么其前面的输出操作数的“:”不能省略,其后面的破坏描述可以省略
asm volatile ("add a0, %0, %1\r\n"
:
:"r"(src1), "r"(src2));
从上述例子可以看出,汇编指令部分的操作数,可以是寄存器也可以是占位符。
2.3 输出操作数
其格式如下:
:[out1]"=r"(valuel), [out2]"=r"(value2)...
-
新段由冒号:开头,若有多个输出用逗号,间隔
-
方括号[]中的符号名用于将内联汇编程序中使用的操作数。如[out1]"=r"(valuel) 输出是valuel,汇编代码中可以用%[out1]指代。除了
%[name]中明确的符号命名指定外,还可以使用操作数索引%num的方式进行隐含指定。"数字"从0开始,依次表示输出操作数和输入操作数。从GCC的3.1版本后,内嵌汇编支持如下两种写法:
- 有名操作数%[name]
- 操作数索引%num,操作数索引
%num也即占位符。
下例中这两种写法是等价的:
// 操作数索引%num,即占位符 asm volatile ("add %0, %1, %2\r\n" : "=r"(res) :"r"(src1), "r"(src2)); // 有名操作数%[name] asm volatile ("add %[out], %[in1], %[in2]\r\n" : [out]"=r"(res): [in1]"r"(src1), [in2]"r"(src2)); // 混合,注意例子中只给第0个操作数res取了名字。后面的第1个操作数和第2个操作数在使用时还是序列号形式%1、%2。 asm volatile ("add %[out], %1, %2\r\n" : [out]"=r"(res): "r"(src1), "r"(src2)); -
双引号"=r" 字母r表示使用编译器自动分配的寄存器来存储该操作数变量。
-
圆括号()中的C/C+变量或者表达式。
2.4 输入操作数
与输出操作数格式相同,差别是没有“=”约束
约束字符:
约束字符就是放在输入操作数和输出操作数前面的修饰符,用以说明操作数的类型与读写权限,常用的约束字符见下表:
| 常见constraints | 含义 |
|---|---|
| = | “=”修饰输出操作数,表示该操作为可写,先前的值将被丢弃 |
| + | “+”修饰输出操作数,表示该操作为可读可写 |
| m | 内存操作数,用于访存指令的地址加载和存储,常用于修饰C语言中指针类型 |
| r | 寄存器操作数,表示整形变量,用于修饰C语言中的(short int long等类型) |
| I | 大写的i,立即数(整数),有符号的12位常量。 |
| l | 小写的l,有符号的16位常量,当常数操作数大于12位但是小于16位时,可以考虑使用此约束符。 |
| f | 浮点寄存器操作数,用于修饰C语言中浮点变量(float或double类型) |
| F | 立即数(浮点,包括单精度与双精度浮点) |
| K | 表示操作数是无符号的12位常量 |
| J | 表示操作数的整数0 |
| G | 表示操作数是浮点0 |
| & | 表示使用该操作数的内存地址,且可被修改 |
2.5 破坏描述部分
内嵌汇编中的破坏描述部分用于声明那些在汇编指令部分有写操作的寄存器或内存,用于通知编译器这些寄存器或内存在此内嵌汇编中会被破坏(被写),需要提前做好上栈保存,并在内嵌汇编中指令完成之后做好旧值恢复。破坏描述部分有两种声明方式:声明寄存器和声明memory。
- 声明寄存器:
新的段用:开头,若有多个寄存器用逗号,间隔,在汇编代码中,我们用到了一些寄存器,需要告知GCC不再信任这些寄存器的值(输入输出操作数指定的寄存器外,这部分由编译器自动分配回收)
通常内嵌汇编程序中多使用C语言变量,而变量所关联的寄存器由编译器根据整个函数的上下文来分配,分配的结果肯定是未被使用的或者已经做好上栈保存的。但是汇编指令部分还可以直接使用寄存器,并可对其做修改(写操作)。如果在破坏描述部分不对使用的寄存器做声明,那么编译器在编译内嵌汇编时就不会做任何的检查和保护,可能会因为某个寄存器旧值未做保存而被修改,导致程序出错和致命异常。
建议:对所有被修改的寄存器,即写操作寄存器在破坏描述部分做声明。而所用的C语言变量则不需要声明
- 声明memory:
破坏描述memory的功能可描述为:通知编译器,asm中可能对操作数做了修改(写操作),所以在asm前后不要对访存相关的语句做任何的值假设(优化),而是要实时刷新内存,即要把寄存器数据写入内存或从内存重新读取最新数据,以便获取内存中的最新值。
3 内嵌汇编使用示例
有时候需要我们写内嵌汇编,比较快的方法是:直接从反汇编开始,然后按照内嵌汇编格式要求,改为内嵌汇编。
以下是一个Riscv平台累加和的例子,展示C语言->汇编->内嵌汇编的转换。
原始c代码:
// demo_macc.c
#include <stdio.h>
#include <stdint.h>
int32_t c_macc(const int32_t *pA, const int32_t *pB, int32_t colCnt)
{
int32_t sum = 0;
while (colCnt)
{
sum += *(pA++) * *(pB++);
colCnt--;
}
/* return the new output pointer with offset */
return sum;
}
void main(void)
{
int32_t a[10], b[10];
int32_t sum1;、
for (int i = 0; i < 10; i++) {
a[i] = i;
b[i] = i;
}
sum1 = c_macc(a, b, 10);
printf("sum1 = %d \r\n", sum1);
}
汇编源程序:
将要改写的函数c_macc,放到一个单独文件里,改一个函数名asm_macc,然后反汇编,得到汇编源文件。
// asm_macc.c
#include <stdint.h>
int32_t asm_macc(const int32_t *pA, const int32_t *pB, int32_t colCnt)
{
int32_t sum = 0;
while (colCnt)
{
sum += *(pA++) * *(pB++);
colCnt--;
}
/* return the new output pointer with offset */
return sum;
}
反汇编:
riscv64-unknown-linux-gnu-gcc -S -O2 asm_macc.c -o asm_macc.s
这样我们得到了汇编源程序:
.file "asm_macc.c"
.option nopic
.attribute arch, "rv64i2p0_m2p0_a2p0"
.attribute unaligned_access, 0
.attribute stack_align, 16
.text
.align 2
.globl asm_macc
.type asm_macc, @function
asm_macc:
.LFB0:
.cfi_startproc
mv a5,a0
beq a2,zero,.L4
slli a4,a2,32
srli a2,a4,30
add a2,a0,a2
li a0,0
.L3:
lw a3,0(a5)
lw a4,0(a1)
mulw a4,a4,a3
addi a5,a5,4
addi a1,a1,4
addw a0,a4,a0
bne a5,a2,.L3
ret
.L4:
li a0,0
ret
.cfi_endproc
.LFE0:
.size asm_macc, .-asm_macc
.section .note.GNU-stack,"",@progbits
然后可以在主程序中添加测试代码:
#include <stdio.h>
#include <stdint.h>
int32_t c_macc(const int32_t *pA, const int32_t *pB, int32_t colCnt)
{
int32_t sum = 0;
while (colCnt)
{
sum += *(pA++) * *(pB++);
colCnt--;
}
/* return the new output pointer with offset */
return sum;
}
extern int32_t asm_macc(const int32_t *pA, const int32_t *pB, int32_t colCnt);
void main(void)
{
int32_t a[10], b[10];
int32_t sum1, sum2;
for (int i = 0; i < 10; i++) {
a[i] = i;
b[i] = i;
}
sum1 = c_macc(a, b, 10);
sum2 = asm_macc(a, b, 10);
printf("sum1 = %d, sum2 = %d\r\n", sum1, sum2);
}
编译:
$ riscv64-unknown-linux-gnu-gcc -O2 -static demo_macc.c asm_macc.s -o demo_macc
在risc-v linux环境中执行,log如下:
sum1 = 285, sum2 = 285
内嵌汇编版本:
这里直接将汇编源程序改造为内嵌汇编,这样比较方便,版本如下:
int32_t inline_macc(const int32_t *pA, const int32_t *pB, int32_t colCnt)
{
int32_t sum = 0;
asm volatile(
" mv a5,%1\n"
" beq %3,zero,.L4%=\n"
" slli a4,%3,32\n"
" srli %3,a4,30\n"
" add %3,%1,%3\n"
" li %1,0\n"
".L3%=:\n"
" lw a3,0(a5)\n"
" lw a4,0(%2)\n"
" mulw a4,a4,a3\n"
" addi a5,a5,4\n"
" addi %2,%2,4\n"
" addw %1,a4,%1\n"
" bne a5,%3,.L3%=\n"
" j .RET%=\n"
".L4%=:\n"
" li %1,0\n"
".RET%=:\n"
"mv %0, %1"
:"=r"(sum)
:"r"(pA), "r"(pB), "r"(colCnt)
: "a3","a4","a5"
);
return sum;
}
对比内嵌汇编版本以及汇编源程序,可见内嵌汇编做了以下几点修改:
- 将指令全部用双引号括起来,指令以\n 或者;作为分隔符;
- 将标签 .L4 全部改为.L4%=,程序员在内嵌汇编中使用
label%=时,它告诉汇编器生成一个唯一的标签,这个标签可以用于标记代码中的特定位置,而且不会与其他标签冲突。这对于在内嵌汇编中定义局部标签或符号非常有用,因为它可以避免命名冲突并简化代码管理; - 内嵌汇编中不需要ret返回,所以需要对这部分进行改造,将结果存入指定位置;
- 入参要正确替换(返回值放到%0,a0-->%1, a1-->%2, a2-->%3),破坏性描述部分写被修改的寄存器。
最终整个用例代码如下:
#include <stdio.h>
#include <stdint.h>
int32_t c_macc(const int32_t *pA, const int32_t *pB, int32_t colCnt)
{
int32_t sum = 0;
while (colCnt)
{
sum += *(pA++) * *(pB++);
colCnt--;
}
/* return the new output pointer with offset */
return sum;
}
extern int32_t asm_macc(const int32_t *pA, const int32_t *pB, int32_t colCnt);
int32_t inline_macc(const int32_t *pA, const int32_t *pB, int32_t colCnt)
{
int32_t sum = 0;
asm volatile(
"mv a5,%1\n"
"beq %3,zero,.L4%=\n"
"slli a4,%3,32\n"
"srli %3,a4,30\n"
"add %3,%1,%3\n"
"li %1,0\n"
".L3%=:\n"
"lw a3,0(a5)\n"
"lw a4,0(%2)\n"
"mulw a4,a4,a3\n"
"addi a5,a5,4\n"
"addi %2,%2,4\n"
"addw %1,a4,%1\n"
"bne a5,%3,.L3%=\n"
"j .RET%=\n"
".L4%=:\n"
"li %1,0\n"
".RET%=:\n"
"mv %0, %1"
:"=r"(sum)
:"r"(pA), "r"(pB), "r"(colCnt)
:"a3","a4","a5"
);
return sum;
}
void main(void)
{
int32_t a[10], b[10];
int32_t sum1, sum2, sum3;
for (int i = 0; i < 10; i++) {
a[i] = i;
b[i] = i;
}
sum1 = c_macc(a, b, 10);
sum2 = asm_macc(a, b, 10);
sum3 = inline_macc(a, b, 10);
printf("sum1 = %d, sum2 = %d, sum3 = %d\r\n", sum1, sum2, sum3);
}
编译:
$ riscv64-unknown-linux-gnu-gcc -O2 -static demo_macc.c asm_macc.s -o demo_macc
运行结果如下:
sum1 = 285, sum2 = 285, sum3 = 285
可见这几种写法是等价的
参考:
-
《汇编语言编程基础 基于LoongArch》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号