数据库视图、存储方式&常见函数
一、数据库视图
1.视图定义
关系型数据库中的数据是由一张一张的二维关系表所组成,简单的单表查询只需要遍历一个表,而复杂的多表查询需要将多个表连接起来进行查询任务。对于复杂的查询事件,每次查询都需要编写SQL代码效率低下。为了解决这个问题,数据库提供了视图(view)功能。
2.视图特点
a) 视图的列可以来自不同的表,是表的抽象和在逻辑意义上建立的新关系;
b) 视图是由基本表(实表)基础上产生表(虚拟表);
c) 视图的删除与创建不会影响到基本表;
d) 对视图内容的增加、删除、修改会影响到基本表;
e) 当视图来自多个基本表时不允许添加删除数据(数据库禁止)。
3.创建视图
a) 手动创建
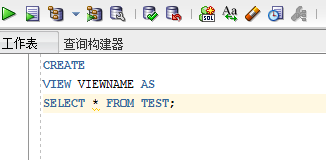
通过SQL语句创建视图
CREATE
VIEW view_name AS
SELECT
*
FROM
sys_user ; (数据库相关字段查询)
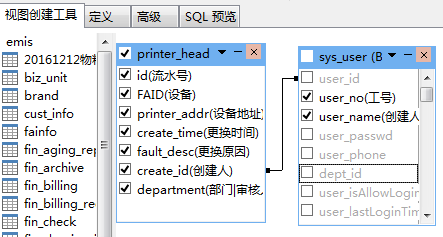
b) 数据库管理软件
通过数据库管理软件相应功能实现,快速配置视图。
1.视图的常见用法
视图功能是为了处理关于数据查询时例如表连接、子查询等逻辑非常复杂,编写语句比较多的时候,尤其当这种查询需要重复使用时,则不会次次都能编写正确,从而降低了数据库的实用性。
在部分表中,表中的部分字段并不是对所有用户开放。但是可能存在疏忽在查询中将这些字段写入,从而让所有能查看此查询的人看见这些非开放字段。
在实际开发中,开发者并不是需要看到所有数据,从而提高数据库的安全性。
视图的使用方法和数据表的使用方法在查询方面是一样的,但是视图如果包含了多张表的查询结果那不允许进行插入和删除数据。
2.视图功能小结
视图相对于普通数据表而言具有以下几个优势:
简单:使用视图的用户完全不需要关心视图中的数据是通过什么查询得到的,视图中的数据对用户来说已经是过滤好的符合条件的结果集;
安全:使用视图的用户只能访问他们被允许查询的结果集,对表的权限管理并不能限制到某个行或某个列,但是通过视图就可以简答地实现;
数据独立:一旦视图的结构确定了,可以屏蔽表结构变化对用户的影响,原表增加列对视图没有影响;源表修改列名,则可以通过修改视图来解决,不会造成对访问者的影响。
相比普通数据表也存在如下限制
不能在视图上创建索引;
在视图的FROM子句中不能使用子查询;
以下情形中的视图是不可更新的(更新是指对基表中的数据进行更新,并不是指基表中数据修改后,视图中的数据不进行更新或是不能对视图的定义进行修改):
①包含以下关键字的SQL语句:聚合函数(SUM、MIN、MAX、COUNT等)、DISTINCT、GROUP BY、HAVING、UNION或UNION ALL;
②常量视图;
③SELECT中包含子查询;
④JOIN;
⑤FROM一个不能更新的视图;
⑥WHERE子句的子查询引用了FROM子句中的表。
一、数据库存储过程
- 存储过程定义
SQL语句需要先编译然后执行,而存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数)来调用执行它
存储过程是可编程的函数,在数据库中创建并保存,可以由SQL语句和控制结构组成。当想要在不同的应用程序或平台上执行相同的函数,或者封装特定功能时,存储过程是非常有用的。数据库中的存储过程可以看做是对编程中面向对象方法的模拟,它允许控制数据的访问方式。
存储过程在使用方面具有以下优点:
①增强SQL语言的功能和灵活性:存储过程可以用控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
②标准组件式编程:存储过程被创建后,可以在程序中被多次调用,而不必重新编写该存储过程的SQL语句。而且数据库专业人员可以随时对存储过程进行修改,对应用程序源代码毫无影响。
③较快的执行速度:如果某一操作包含大量的Transaction-SQL代码或分别被多次执行,那么存储过程要比批处理的执行速度快很多。因为存储过程是预编译的。在首次运行一个存储过程时查询,优化器对其进行分析优化,并且给出最终被存储在系统表中的执行计划。而批处理的Transaction-SQL语句在每次运行时都要进行编译和优化,速度相对要慢一些。
④减少网络流量:针对同一个数据库对象的操作(如查询、修改),如果这一操作所涉及的Transaction-SQL语句被组织进存储过程,那么当在客户计算机上调用该存储过程时,网络中传送的只是该调用语句,从而大大减少网络流量并降低了网络负载。
⑤作为一种安全机制来充分利用:通过对执行某一存储过程的权限进行限制,能够实现对相应的数据的访问权限的限制,避免了非授权用户对数据的访问,保证了数据的安全。
- 存储过程创建
MySql存储过程的创建SQL代码如下
DELIMITER //
CREATE PROCEDURE myProcName(IN|OUT|INOUT s int)
BEGIN
SELECT *,s FROM view1;
UPDATE view1 SET department = 'null' WHERE id = 6;
SELECT *,s+1 FROM view1;
END
//
DELIMITER ;
DELIMITER //…//DELIMITER : MySQL默认以";"为分隔符,如果没有声明分割符,则编译器会把存储过程当成SQL语句进行处理,因此编译过程会报错,所以要事先用“DELIMITER //”声明当前段分隔符,让编译器把两个"//"之间的内容当做存储过程的代码,不会执行这些代码;“DELIMITER ;”的意为把分隔符还原
myProcName:自定义过程名称,如果有多个参数则用‘,’进行分割;
IN:参数值必须在调用存储过程时被指定,在存储过程中修改该参数的值不能被返回,为默认值;
OUT:该值在存储过程内部被改变时,可以返回,指定该参数但是不会被调用(可以用来改变某个参数的值);
INOUT:调用时指定,并可被改变和返回;
BEGIN…END:过程体用于存储存储过程执行SQL代码部分;
MySql存储过程使用
CALL myProcName(参数1…);
Oracle存储过程的创建SQL代码如下
CREATE [OR REPLACE] PROCEDURE procedure_name
[(parameter1[model] datatype1, parameter2 [model] datatype2..)]
IS[AS]
BEGIN
PL/SQL;
END [procedure_name];
Oracle存储过程使用
CALL procedure_name()
如果没有指定参数的话,数据传递的顺序不能改变PROCEDURENAME (aaa, eee);
Oracle 存储过程
create or replace PROCEDURE TESTPROCEDURE2(
NAME1 IN VARCHAR2
) AS
BEGIN
INSERT INTO TEST VALUES(2,NAME1);
END TESTPROCEDURE2;
注:值的注意的是Oracle数据库中begin end块中只能添加insert、update、delete之类的,不能添加纯粹的select语句,添加select语句的情况通常是为了某些参数的取值
- 存储过程小结:
①存储过程是用于特定操作的pl/sql语句块
②存储过程是预编译过的,经优化后存储在sql内存中,使用时无需再次编译,提高了使用效率;
③存储过程的代码直接存放在数据库中,一般直接通过存储过程的名称调用,减少了网络流量,加快了系统执行效率; - 存储过程&函数:
①一般来说,存储过程实现的功能要复杂一点,而函数的实现的功能针对性比较强。
②对于存储过程来说可以返回参数(output),而函数只能返回值或者表对象。
③存储过程一般是作为一个独立的部分来执行,而函数可以作为查询语句的一个部分来调用,由于函数可以返回一个表对象,因此它可以在查询语句中位于FROM关键字的后面。
一、常见函数详情
- SUM函数
计算数据列的和
SELECT SUM(column_name) FROM table_name
column_name:要处理的字段
注:合计函数 (比如 SUM) 常常需要添加 GROUP BY 语句
- AVG()函数
计算数据列的平均值,NULL值不在计算范围内
SELECT AVG(column_name) FROM table_name
column_name:要处理的字段
- COUNT()函数
返回匹配指定条件的行数
SELECT COUNT(column_name) FROM table_name WHERE column_name = ?
column_name:要处理的字段
- DISTINCT关键字
显示不同的数据
SELECT DISTINCT * FROM table_name
- FIRST()函数
返回指定的字段中第一个记录的值
SELECT FIRST(column_name) FROM table_name
column_name:要处理的字段
- LAST()函数
返回指定的字段中最后一个记录的值
SELECT LAST(column_name) FROM table_name
column_name:要处理的字段
- MAX()函数
返回一列中的最大值。NULL 值不包括在计算中
SELECT MAX(column_name) FROM table_name
column_name:要处理的字段
注:MIN 和 MAX 也可用于文本列,以获得按字母顺序排列的最高或最低值
- MIN()函数
返回一列中的最小值。NULL 值不包括在计算中
SELECT MIN(column_name) FROM table_name
column_name:要处理的字段
注:MIN 和 MAX 也可用于文本列,以获得按字母顺序排列的最高或最低值
- GROUP BY语句
用于结合合计函数,根据一个或多个列对结果集进行分组
GROUP BY column_name
column_name:要处理的字段
注:合计函数 (比如 SUM) 常常需要添加 GROUP BY 语句
- HAVING子句
HAVING子句为了处理WHERE 关键字无法与合计函数一起使用的情况
例如:
SELECT * FROM emis. server_insp WHERE name = ‘tome’ HAVING SUM(money) > 500
- UCAS1E() 函数
用于将指定字段的值全部转换为大写字母
SELECT UCASE(column_name) FROM table_name
column_name:要处理的字段
- LCASE() 函数
用于将指定字段的值全部转换为小写字母
SELECT LCASE(column_name) FROM table_name
column_name:要处理的字段
- MID() 函数
用于从文本字段中提取字符
SELECT MID(column_name,start,length) FROM table_name
column_name:指定字段
start:开始位置,从1开始
length:提取字符长度
- LEN() 函数
返回文本字段中值的长度
SELECT LEN(column_name) FROM table_name
- NOW() 函数
返回当前的日期和时间
SELECT NOW() FROM table_name
CURDATE()函数
以‘YYYY-MM-DD’或YYYYMMDD格式返回今天日期值
CURTIME()函数
以‘HH:MM:SS’或HHMMSS格式返回当前时间值
- FORMAT()函数
用于对字段的显示进行格式化
SELECT FORMAT(column_name,format) FROM table_name
column_name:要处理的字段
format:规定格式
- ABS(X)函数
返回X的绝对值
SELECT ABS(column_name) FROM table_name
column_name:要处理的字段
MOD(N,M)或%
返回N被M除的余数。
SELECT MOD(column_name,M) FROM table_name
column_name:要处理的字段
M: 除数
FLOOR(X)函数
返回不大于X的最大整数值
SELECT FLOOR(X);
X:任意一有理数
CEILING(X)函数
返回不小于X的最小整数值
SELECT CEILING(X)
X:任意一有理数
ROUND()函数
用于把数值字段舍入为指定的小数位数
SELECT ROUND(column_name,decimals) FROM table_name
column_name:要处理的字段
decimals:规定返回的小数位数
- ASCII(str)函数
返回字符串str的最左面字符的ASCII代码值
SELECT ASCLL(str);
str:字符串
- CONCAT(str1,str2,...)函数
返回来自于参数字符串拼接后的字符串
SELECT CONCAT(str1,str2);
str:字符串
- LOCATE(substr,str)函数
返回子串substr在字符串str第一个出现的位置,如果substr不是在str里面,返回0.
SELECT LOCATE(substr,str);
substr: 字符串
str: 字符串
- REVERSE(str)函数
返回颠倒字符顺序的字符串str
SELECT REVERSE(str);
str: 字符串
- DAYOFWEEK(date)函数
返回日期date的星期索引(1=星期天,2=星期一, …7=星期六)。
SELECT DATOFWEEK(NOW());
date: 日期
WEEKDAY(date)函数
返回date的星期索引(0=星期一,1=星期二, ……6= 星期天)。
SELECT DATOFWEEK(NOW());
date: 日期
DAYNAME(date)函数
返回date的星期名字
SELECT DAYNAME(now());
三个函数效果近似
- DAYOFMONTH(date)函数
返回date的月份中的日期,在1到31范围内。
SELECT DAYOFMONTH(now());
DAYOFYEAR(date)函数
返回date在一年中的日数, 在1到366范围内
SELECT DAYOFYEAR(now());
date: 日期
- WEEK(date,first)函数
对于星期天是一周的第一天的地方,有一个单个参数,返回date的周数,范围在0到52。2个参数形式WEEK()允许你指定星期是否开始于星期天或星期一。如果第二个参数是0,星期从星期天开始,如果第二个参数是1,从星期一开始。
SELECT WEEK(now(),1)
MONTH(date)函数
返回date的月份,范围1到12
SELECT MONTH(now());
MONTHNAME(date)函数
返回date的月份名字。
SELECT MONTHNAME(now())
date: 日期
QUARTER(date)函数
返回date一年中的季度,范围1到4
SELECT QUARTER(now());
YEAR(date)函数
返回date的年份,范围在1000到9999。
SELECT YEAR(now());
HOUR(time)函数
返回time的小时,范围是0到23。
MINUTE(time)函数
返回time的分钟,范围是0到59。
SECOND(time)函数
回来time的秒数,范围是0到59。
- DATE_ADD(date,INTERVAL expr type)函数
进行日期增加的操作,可以精确到秒
eg:
SELECT "1997-12-31 23:59:59" + INTERVAL 1 SECOND;
SELECT DATE_ADD("1997-12-31 23:59:59", INTERVAL 1 SECOND);
SELECT DATE_ADD("1998-01-01 00:00:00", INTERVAL 1 DAY);
SELECT DATE_ADD("1998-01-01 00:00:00", INTERVAL 1 MONTH);
SELECT DATE_ADD("1998-01-01 00:00:00", INTERVAL 1 YEAR);
SELECT DATE_ADD("1998-01-01 00:00:00", INTERVAL 1 QUARTER);
SELECT DATE_ADD("1998-01-01 00:00:00", INTERVAL 1 HOUR);
SELECT DATE_ADD("1998-01-01 00:00:00", INTERVAL 1 MINUTE);
DATE_SUB(date,INTERVAL expr type)函数
进行日期减少的操作,可以精确到秒
eg:
SELECT "1997-12-31 23:59:59" + INTERVAL 1 SECOND;
SELECT DATE_ SUB("1997-12-31 23:59:59", INTERVAL 1 SECOND);
SELECT DATE_ SUB("1998-01-01 00:00:00", INTERVAL 1 DAY);
SELECT DATE_ SUB("1998-01-01 00:00:00", INTERVAL 1 MONTH);
SELECT DATE_ SUB("1998-01-01 00:00:00", INTERVAL 1 YEAR);
SELECT DATE_ SUB("1998-01-01 00:00:00", INTERVAL 1 QUARTER);
SELECT DATE_ SUB("1998-01-01 00:00:00", INTERVAL 1 HOUR);
SELECT DATE_ SUB("1998-01-01 00:00:00", INTERVAL 1 MINUTE);
- CASE value [WHEN curValue THEN 代码段] [WHEN curValue THEN 代码段] …. ELSE 代码段END;语句块
返回结果中, value=curValue 则执行代码段,如果没有则执行ELSE后结果,如果ELSE后结果为空,则返回null;
CASE WHEN curValue THEN 代码段 ELSE X END;语句块
一种情况的匹配。如果没有匹配的结果值,则返回结果为ELSE后的结果,如果没有ELSE 部分,则返回值为 NULL - IF(expr1,expr2,expr3)函数
expr1返回类型是true则IF(,,)的expr2,否则则返回expr3. - Strcmp(str1,str2)函数
如果str1>str2返回1,str1=str2反回0,str1<str2返回-1 - VERSION()函数
返回数据库的版本号 - CONNECTION_ID()函数
返回服务器的连接数,也就是到现在为止MySQL服务的连接次数 - DATABASE()函数&SCHEMA()函数
返回当前数据库名。 - USER()函数、SYSTEM_USER()函数、SESSION_USER()函数、CURRENT_USER()函数和CURRENT_USER()函数这几个函数可以返回当前用户的名称。
- CHARSET(str)函数
返回字符串str的字符集,一般情况这个字符集就是系统的默认字符集;
COLLATION(str)函数
返回字符串str的字符排列方式。 - PASSWORD(str)函数
可以对字符串str进行加密。一般情况下,PASSWORD(str)函数主要是用来给用户的密码加密的。 - MD5(str)函数
可以对字符串str进行加密。MD5(str)函数主要对普通的数据进行加密。 - ENCODE(str,pswd_str)函数
可以使用字符串pswd_str来加密字符串str。加密的结果是一个二进制数,必须使用BLOB类型的字段来保存它。
DECODE(crypt_str,pswd_str)函数
可以使用字符串pswd_str来为crypt_str解密。crypt_str是通过ENCODE(str,pswd_str)加密后的二进制数据。字符串pswd_str应该与加密时的字符串pswd_str是相同的。
- CONVERT(s USING cs)函数
将字符串s的字符集变成cs
AI大火腿 :痛苦预示着超脱
本文来自博客园,作者:AI大火腿,转载请注明原文链接:https://www.cnblogs.com/supperlhg/articles/9480203.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号