ubuntu16.04 hbase 安装
1.解压hbase并修改名称
2.配置hbase
修改conf/hbase-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- /** * * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ --> <configuration> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- hbase.rootdir配置的是hdfs地址,ip:port要和hadoop/core-site.xml中的fs.defaultFS保持一致 --> <property> <name>hbase.rootdir</name> <value>hdfs://suphowe:8000/hbase</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>192.168.200.135</value> </property> </configuration>
3.启动hbase
/hbase/bin 目录下
bash start-hbase.sh
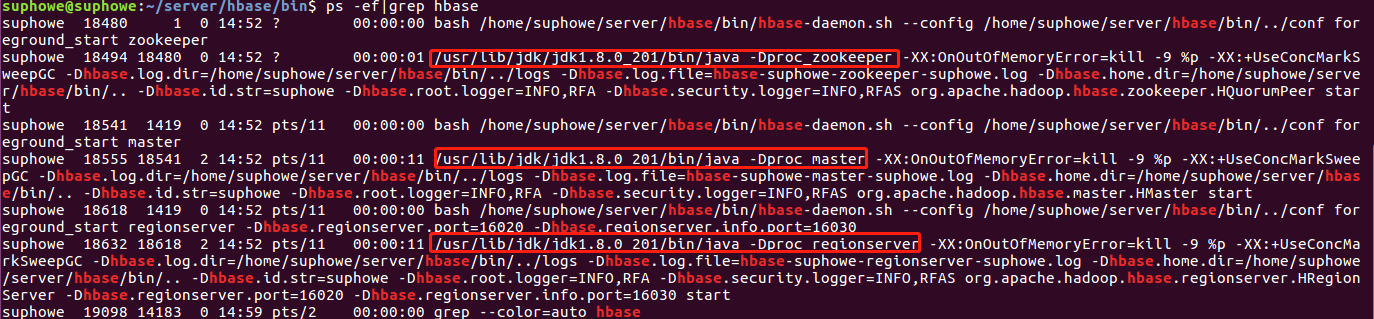
4.出现错误
4.1 未配置JAVA_HOME

在/hbase/config/hbase-env.sh添加
export JAVA_HOME="/usr/lib/jdk/jdk1.8.0_201"
4.2 namenode 格式化两次
出现错误
There are 0 datanode(s) running and no node(s) are excluded in this operation
解决
第一步:关闭hadoop,
第二布:删除文件夹/home/suphowe/server/hadoop_data 下所有内容
第三布:重新执行格式化
./hadoop namenode -format
第四步:重新启动hadoop
sh start-all.sh
bash mr-jobhistory-daemon.sh start historyserver
第五步:重新开启hbase
5.测试
进入hbase
./hbase shell

表操作
查看hbase

建表
create 'table1','info'
create '表名','列族名'

获取表

获取表描述
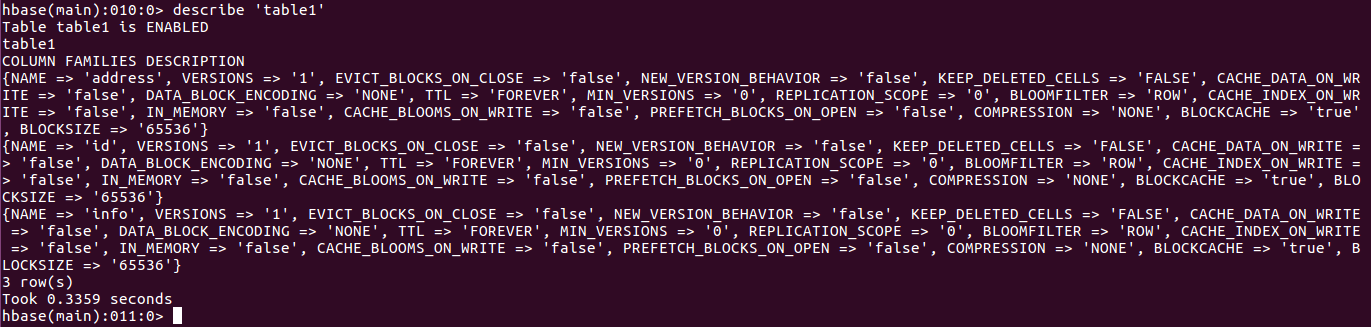
增加列族
alter 'table1', 'info2'
删除一个列族
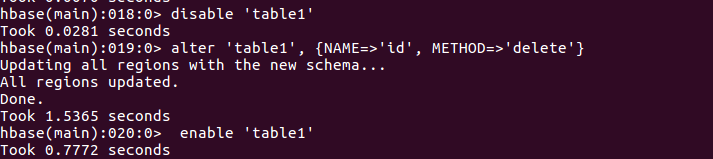
查看表是否存在

判断表是否为‘enable’

删除表
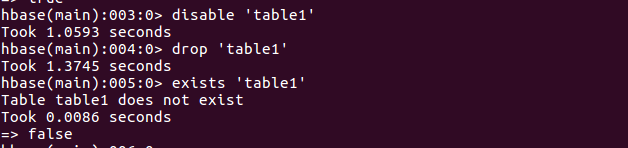
插入数据
put 'table1','0001','info:id','0001' put '表名','行键的名称(字符串类型)','列族:列名(可临时创建)','值',时间戳(可省略,自动创建)

删除数据
--delete 操作并不会马上删除数据,只会将对应的数据打上删除标记(tombstone),只有在合并数据时,数据才会被删除。 --删除列族所有数据,删除 table1表中行键为 0001 的 info 列族的所有数据 delete 'table1', '0001', 'info' --删除 table1表中行键为 0001 的 info 列族 id 的数据 delete 'table1', '0001', 'info:id'
--删除逻辑行
deleteall 'table1', '0001'
获取数据
get 'table1', '0001'

查询全表数据
scan 'table1'

过滤器(相当于sql中的where)
scan '表名', { Filter => "过滤器(比较运算符, '比较器') }
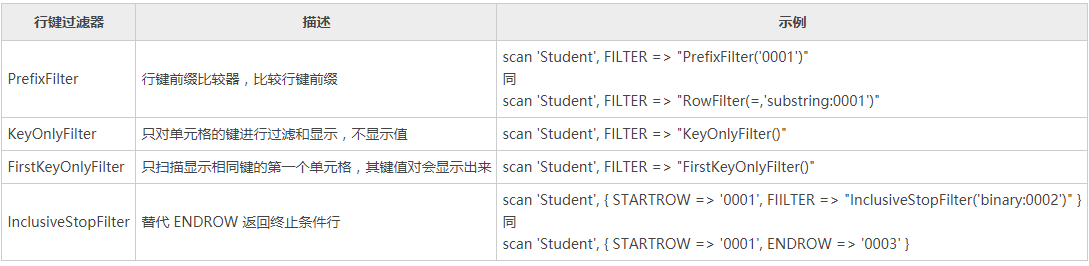
行键过滤器
--匹配0001开头行键
scan 'table1',FILTER=>"RowFilter(=,'substring:0001')"
scan 'table1',FILTER=>"PrefixFilter('0001')"
scan 'table1',FILTER=>"KeyOnlyFilter()"
scan 'table1',FILTER=>"FirstKeyOnlyFilter()"
scan 'table1',{STARTROW=>'0001',FILTER=>"InclusiveStopFilter('binary:0002')"}

列族过滤器

scan 'table1' scan 'table1',FILTER=>"QualifierFilter(=,'substring:id')" scan 'table1',FILTER=>"ColumnPrefixFilter('i')" scan 'table1',FILTER=>"MultipleColumnPrefixFilter('i','d')" scan 'table1',FILTER=>"ColumnRangeFilter('id',true,'d',false)"
值过滤器

scan 'table1', FILTER => "ValueFilter(=,'substring:0001')" scan 'table1', FILTER => "SingleColumnValueFilter('info', 'id', =, 'binary:0001')" scan 'table1', FILTER => "SingleColumnValueExcludeFilter('info', 'id', =, 'binary:0001')"
其他过滤器


 浙公网安备 33010602011771号
浙公网安备 33010602011771号