ubuntu16.04下 hadoop 伪分布式 安装及环境配置
本文在安装hadoop之前已安装配置jdk1.8 环境
hadoop下载
下载地址:
https://www-us.apache.org/dist/hadoop/common/stable/

修改主机
1.获取主机IP
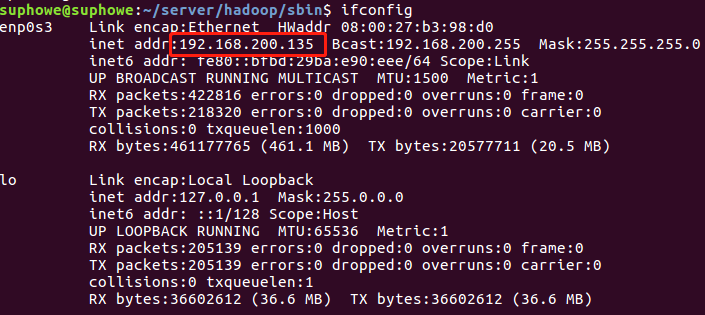
2.修改hostname
vim /etc/hostname
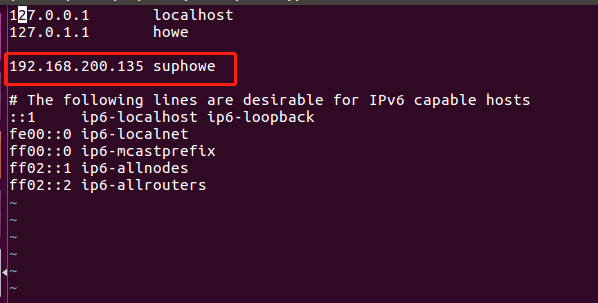
3.修改地址映射
vim /etc/hosts
4.修改ssh localhost免密登陆
4.1安装 rsync 和 ssh
rsync: rsync是linux系统下的数据镜像备份工具。使用快速增量备份工具Remote Sync可以远程同步,支持本地复制,或者与其他SSH、rsync主机同步
ssh(安全外壳协议): Secure Shell的缩写,SSH 为建立在应用层基础上的安全协议;专为远程登陆会话和其他网络服务提供安全性的协议
sudo apt-get install ssh rsync
4.2配置ssh免密登陆
4.2.1 新建.ssh文件夹
mkdir ~/.ssh/
chmod 700 ~/.ssh/
4.2.2 生成密钥
ssh-keygen -t rsa
4.2.3 拷贝并授权
cd ~/.ssh/ cp id_rsa.pub authorized_keys chmod 600 authorized_keys
4.2.4 测试
ssh localhost
hadoop安装
1.hadoop解压
创建文件夹hadoop,解压tar包
tar -xvf hadoop-3.2.1.tar.gz
2.hadoop伪分布式配置
伪分布式进行配置:用一个机器同时运行NameNode,SecondaryNameNode, DataNode, JobTracker, TaskTracker 5个任务
3.1 修改core-site.xml
core-site.xml 在目录 ./hadoop-3.2.1/etc/hadoop 下
修改为:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://suphowe:8000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
3.2 修改 mapred-site.xml
mapred-site.xml 在目录 ./hadoop-3.2.1/etc/hadoop 下
修改为:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>Execution framework set to Hadoop YARN.</description>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/tmp/hadoop-yarn/staging</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>suphowe:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>suphowe:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate</value>
</property>
<property>
<name>mapreduce.jobhistory.joblist.cache.size</name>
<value>1000</value>
</property>
<property>
<name>mapreduce.tasktracker.map.tasks.maximum</name>
<value>8</value>
</property>
<property>
<name>mapreduce.tasktracker.reduce.tasks.maximum</name>
<value>8</value>
</property>
<property>
<name>mapreduce.jobtracker.maxtasks.perjob</name>
<value>5</value>
<description>The maximum number of tasks for a single job.A value of -1 indicates that there is no maximum.</description>
</property>
</configuration>
3.4 修改 yarn-site.xml
yarn-site.xml 在目录 ./hadoop-3.2.1/etc/hadoop 下
修改为:
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.200.135</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.200.135:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>864000</value>
</property>
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>86400</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/YarnApp/Logs</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://127.0.0.1:19888/jobhistory/logs/</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/apache/tmp/</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>5000</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4.1</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
3.3 修改 hdfs-site.xml
hdfs-site.xml 在目录 ./hadoop-3.2.1/etc/hadoop 下
修改为:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/suphowe/server/hadoop_data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/suphowe/server/hadoop_data/dfs/data</value>
</property>
<property>
<name>dfs.datanode.fsdataset.volume.choosing.policy</name>
<value>org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>suphowe:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>suphowe:8001</value>
</property>
</configuration>
3.4 修改hadoop-env.sh
hadoop-env.sh 在目录 ./hadoop-3.2.1/etc/hadoop 下
添加 jdk运行环境
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_201
4.启动hadoop
4.1.格式化NameNode
在 ./hadoop/hadoop-3.2.1/bin 目录下执行
./hadoop namenode -format
4.2.启动所有节点,包括NameNode,SecondaryNameNode, JobTracker, TaskTracker, DataNode
在 ./hadoop/hadoop-3.2.1/sbin 目录下执行
sh start-all.sh
4.3.启动jobhistory
在./hadoop-3.2.1/sbin 目录下执行
bash mr-jobhistory-daemon.sh start historyserver
5.测试
5.1.将 /hadoop/hadoop-3.2.1 目录下 README.txt 文件拷贝到 /hadoop/hadoop-3.2.1/bin 目录下
cp README.txt ./bin/
5.2.创建hdfs目录
./hadoop fs -mkdir -p /test/data
5.3.将文件上传到Hadoop的分布式文件系统HDFS,重命名为test.txt
./hadoop fs -put README.txt /test/data/readme.txt
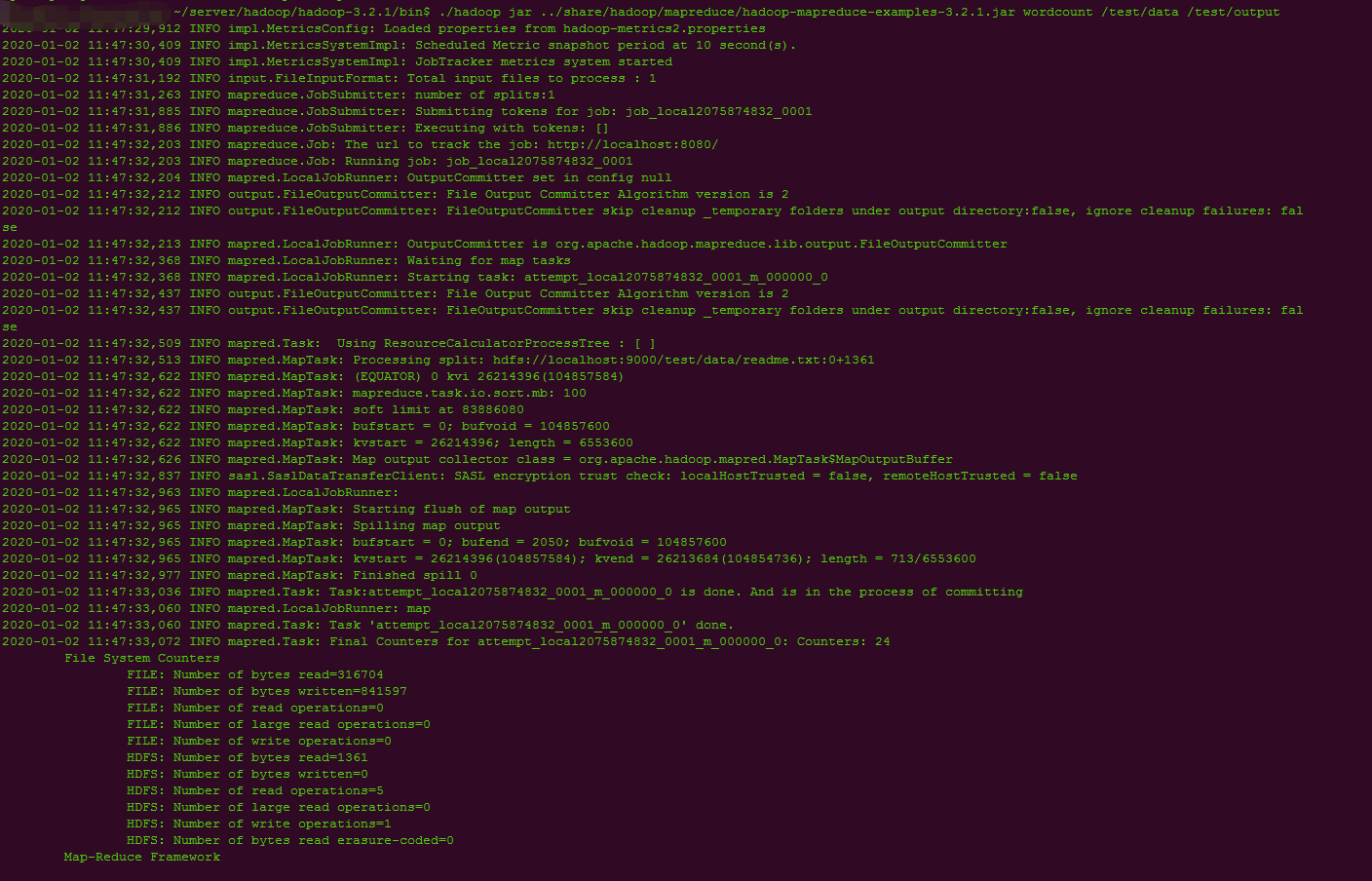
5.4.测试mapreduce
./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /test/data /test/output
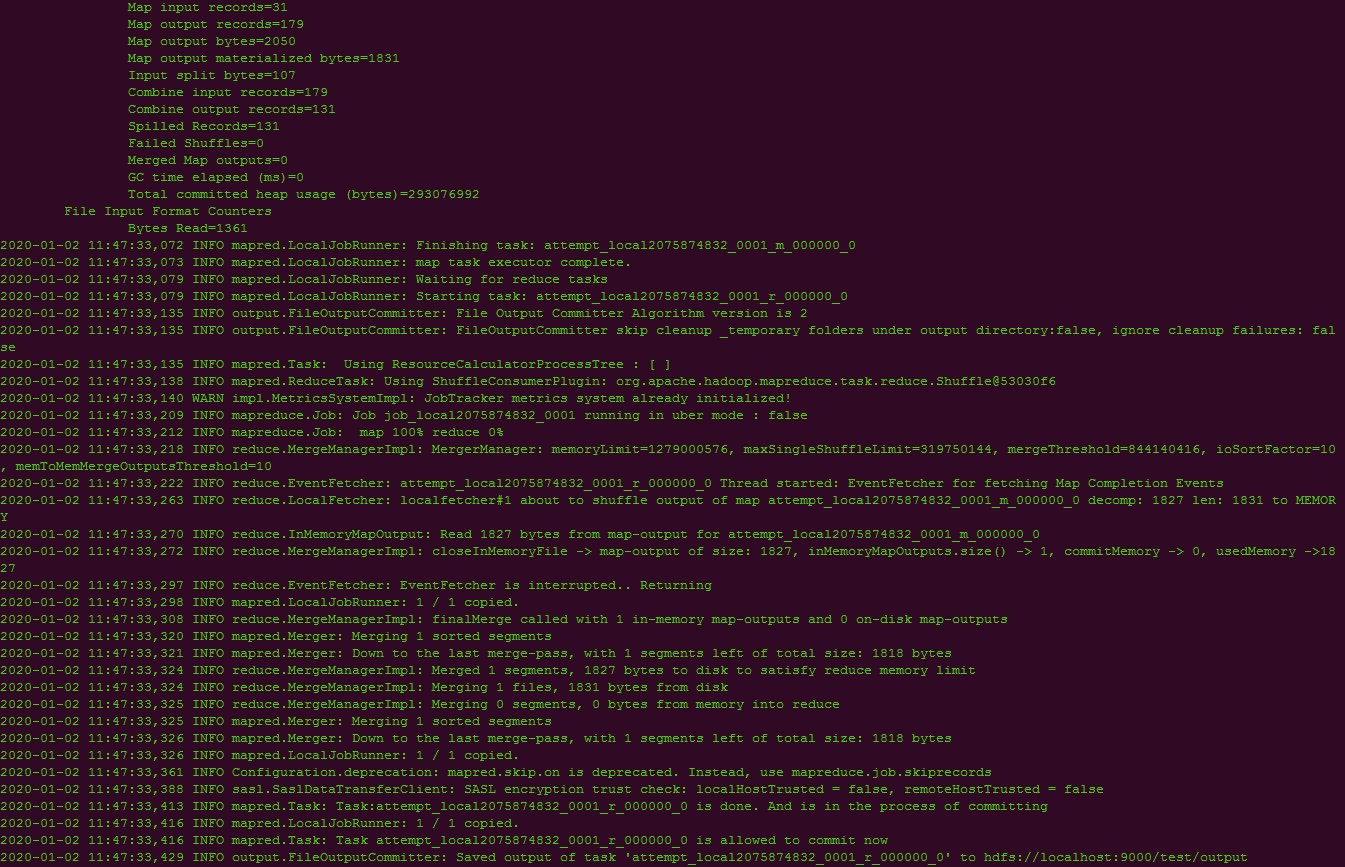
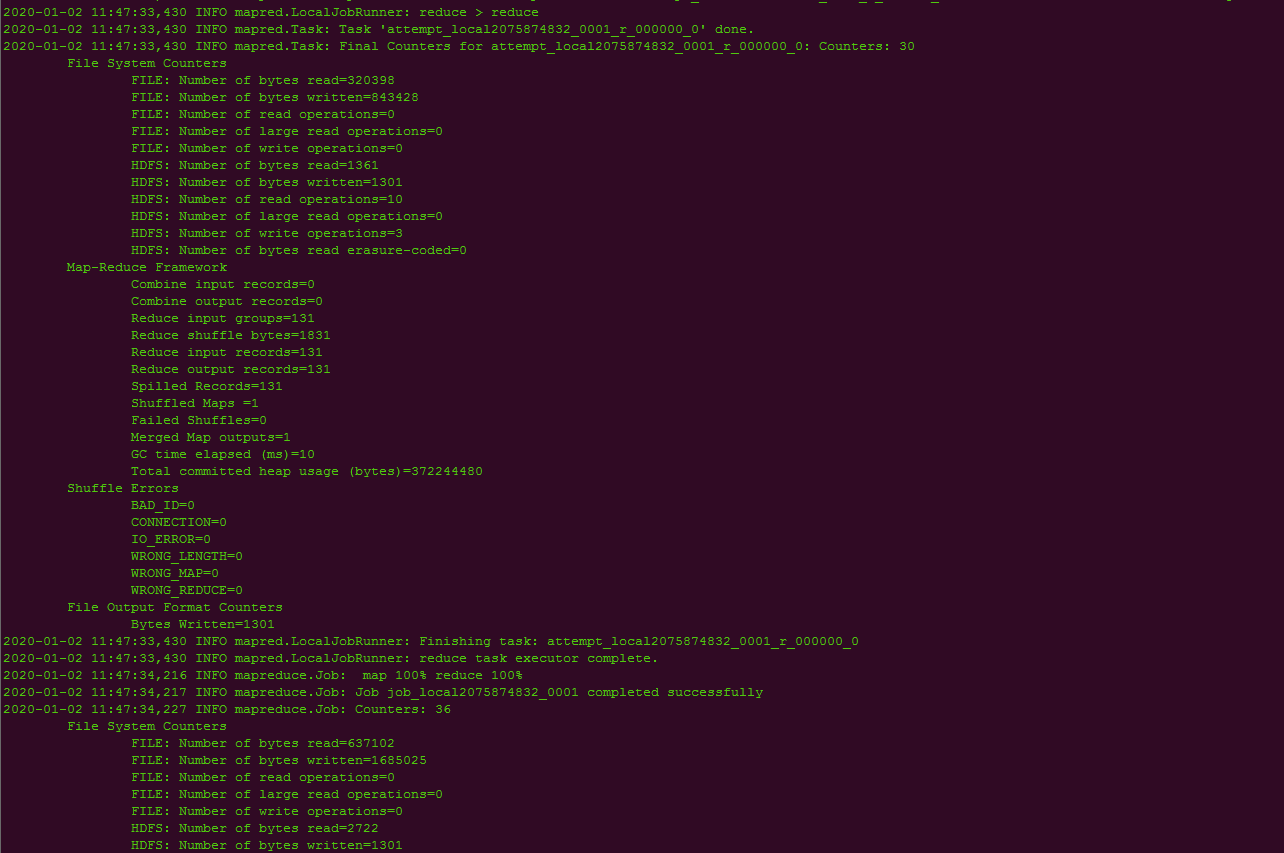
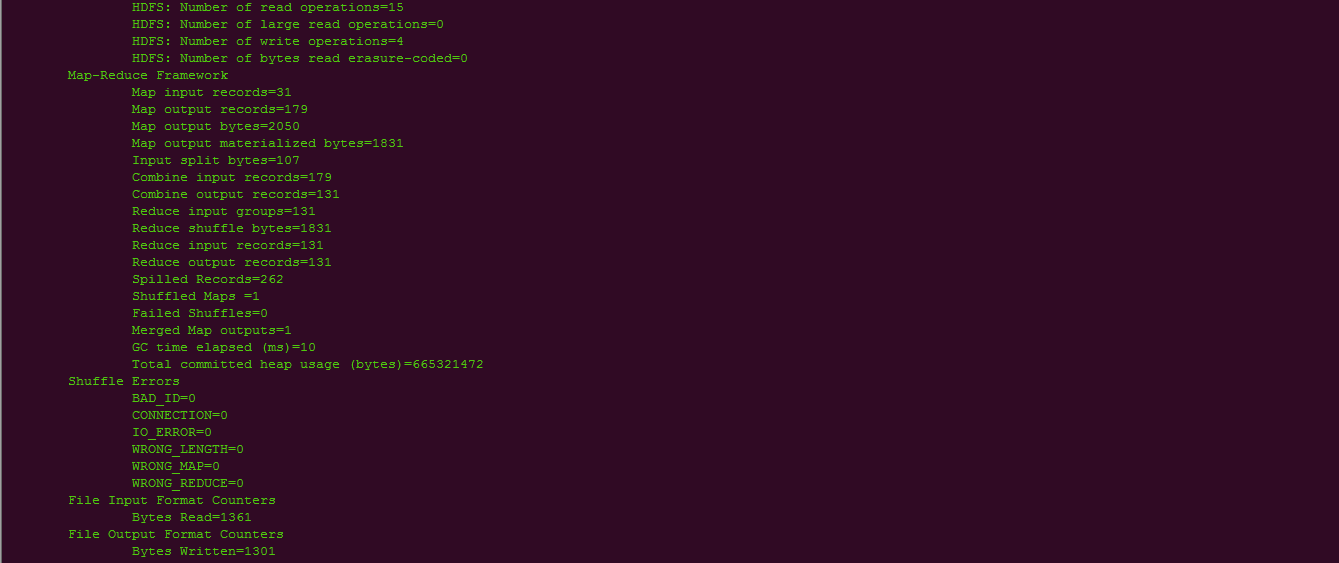
5.5.查看结果
./hadoop fs -cat /test/output/*
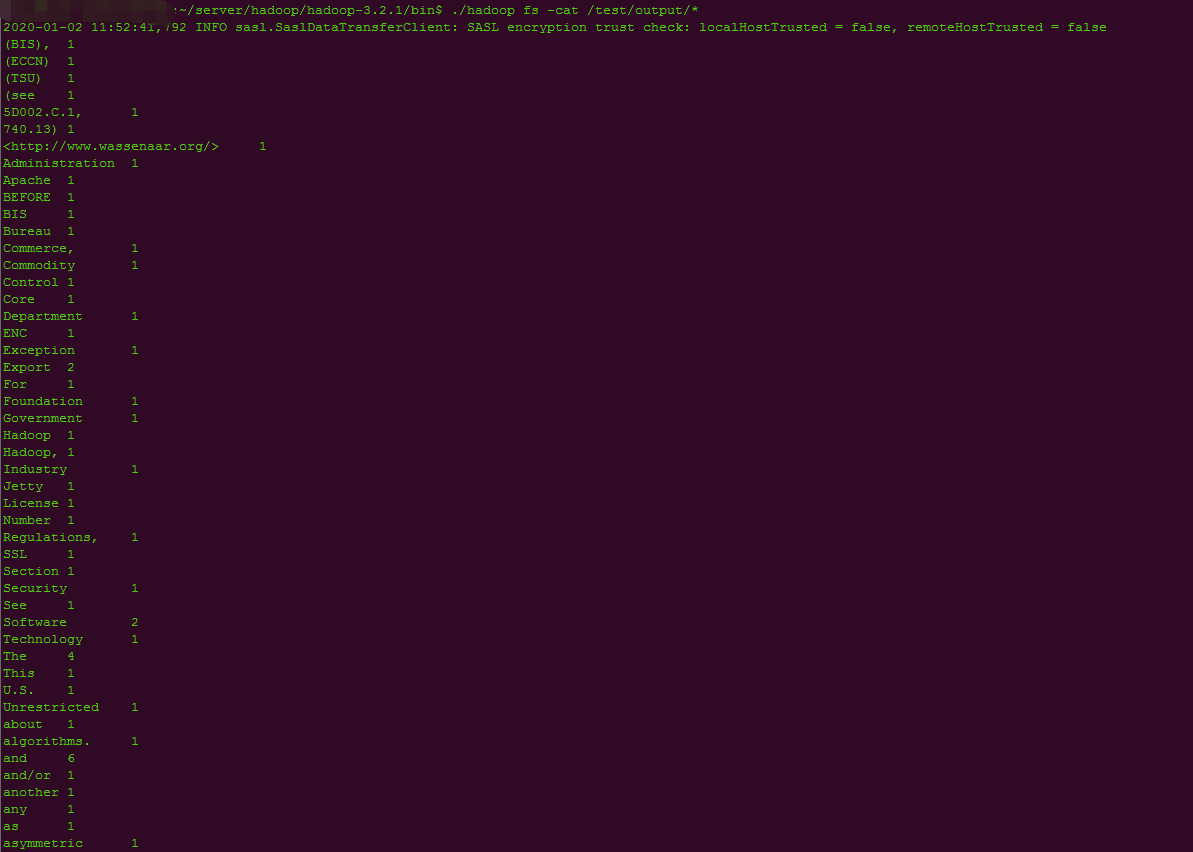
6.界面查看
6.1 在http://192.168.200.135:8088/cluster看下yarn管理的集群资源情况(因为在yarn-site.xml中我们配置了yarn.resourcemanager.webapp.address是192.168.200.135:8088

6.2 在http://192.168.200.135:19888/jobhistory看下map-reduce任务的执行历史情况(因为在mapred-site.xml中我们配置了mapreduce.jobhistory.webapp.address是192.168.200.135:19888)
6.3 在http://192.168.200.135:50070/dfshealth.html看下namenode的存储系统情况(因为在hdfs-site.xml中我们配置了dfs.namenode.http-address是192.168.200.135:50070)

6.4 查看文件
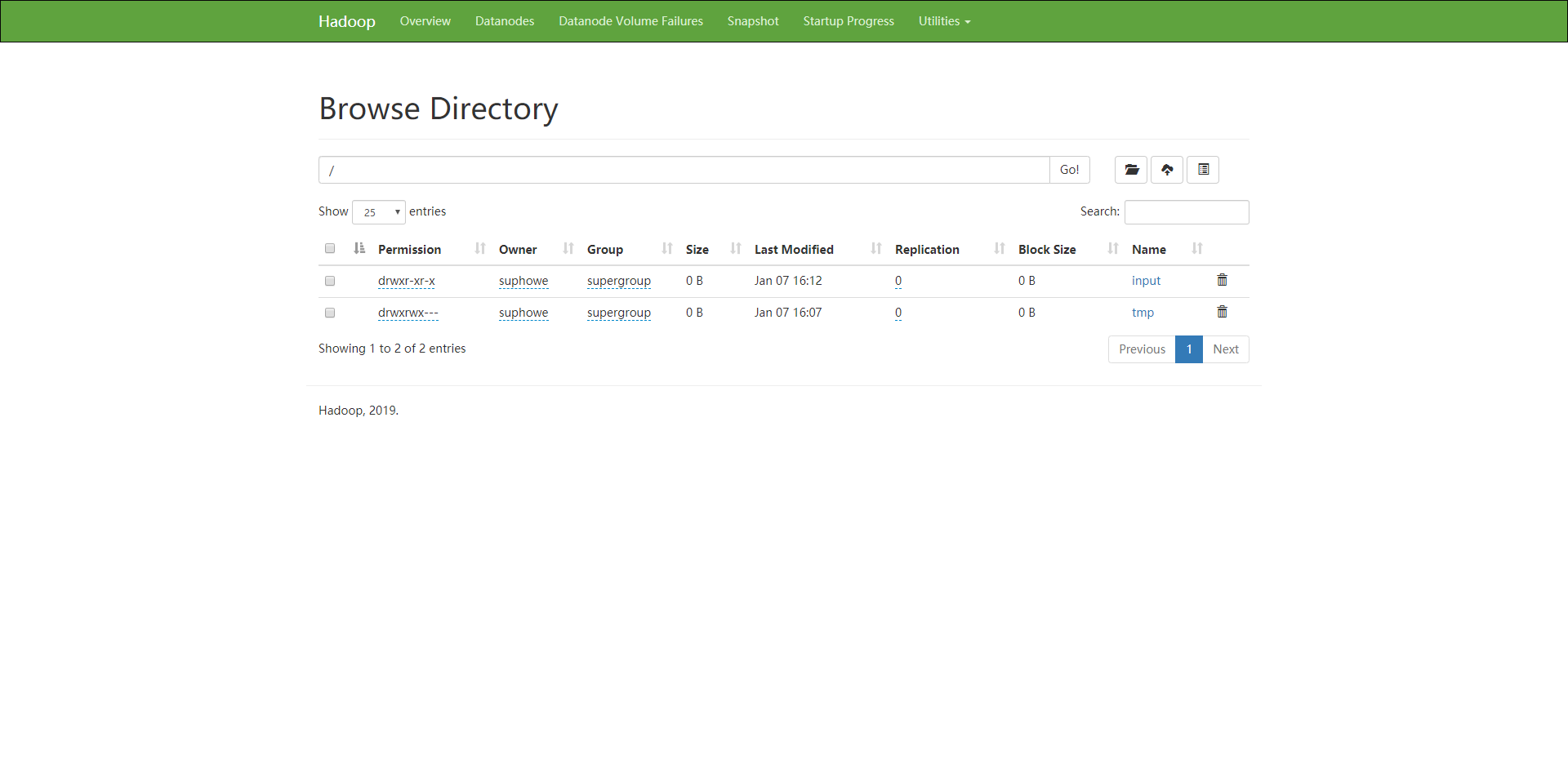
7.错误处理
1. 执行报错 start-all.sh: 22: start-all.sh: Syntax error: "(" unexpected
bash start-all.sh

2. root 用户启动报错
2.1 错误 ERROR: Attempting to operate on hdfs namenode as root
在start-dfs.sh,stop-dfs.sh 中添加
#!/usr/bin/env bash HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
2.2 错误 ERROR: Attempting to operate on yarn resourcemanager as root
在 start-yarn.sh,stop-yarn.sh 中添加
#!/usr/bin/env bash YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
2.3 http://127.0.0.1:19888/jobhistory 访问失败
在./hadoop-3.2.1/sbin 目录下执行
bash mr-jobhistory-daemon.sh start historyserver

7.部署完成
8.问题处理
8.1 hadoop: command not found
hadoop 的环境未加入到path
修改 /etc/profile
加入
export PATH=$PATH:$/home/user/server/hadoop/hadoop-3.2.1/bin:$PATH
source /etc/profile

 浙公网安备 33010602011771号
浙公网安备 33010602011771号