Oracle 基本语句
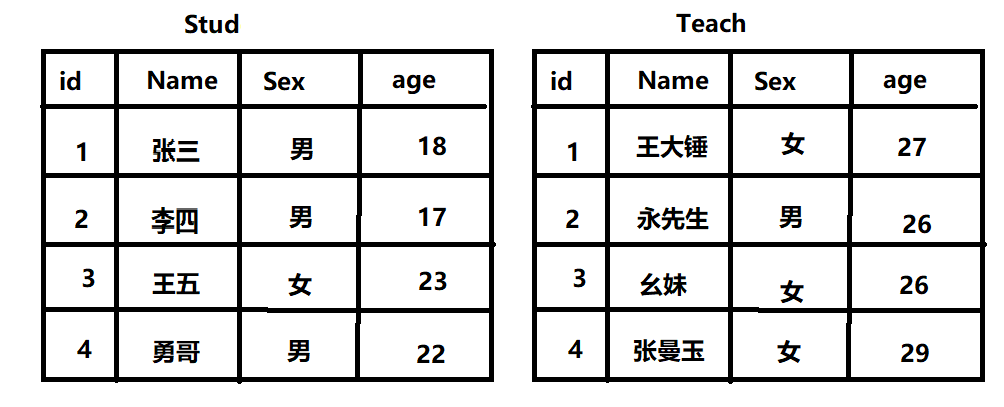
现在这里有两张表,表明分别叫【Stud】和【Teach】:
1):从数据库中查询出Stud表、
select * from Stud;--{注释:select 查询条件关键字;* 代表查询表的全部字段;Stud 需要查询的表名称}
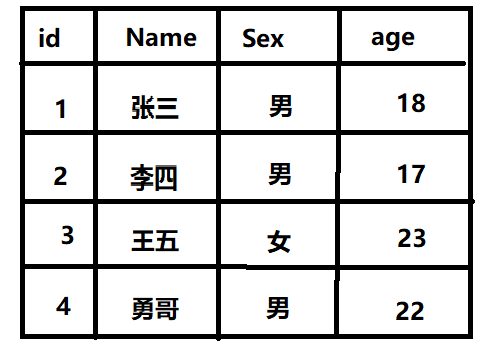
2):从数据库中查询出Stud表中【id为4】角色、
select * from Stud where id='4';--{注释:where 在SQL中的条件关键字 后面跟条件属性} 结果👇

3):修改Stud表中王五的性别为男、
update Stud set Sex='男' where age='23' --{注释: 首先我们得找到自己所要修改的字段 条件咱们可以在表中随便找一个不变的值} 结果👇

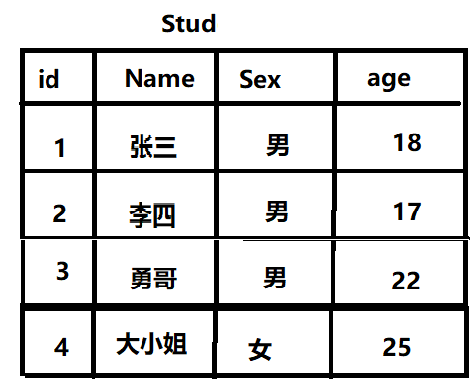
4):给Stud表中添加一个角色为 大小姐 年龄为25岁 性别为女、
insert into Stud (Name,Sex,age) values('大小姐','女','25') --{注释:insert into为添加语句关键字(插入) 后面跟插入的表明 以及字段 后面输入对应的值} 结果👇

5):删除Stud表中角色为王五的人、
delete from Stud where name = '王五' --{注释:在此语句中delete为删除语句关键字 后面需跟表明 及其需要执行的条件} 结果👇
6):清空Stud表中所有数据、
delete from Stud --{注释:此为清空并非删除!!!!!!} 结果👇

7):删除Stud表、
drop table Stud --{注释:drop为删除表关键字 后面需跟表(table) 表名} 结果👇
表已删除:无法展示。
8):SQL建表、
Oracle_SQL创建数据表:举例:
create table TPRG_TaXinXi(
你好原件 varchar(200),
我好报告编号 VARCHAR(500),
大家好日期 VARCHAR(100),
才是真的好原件 varchar(200)
);
9):Oracle创建序列、
CREATE SEQUENCE 序列名称
INCREMENT BY 1 --每次增加值
START WITH 1000 --起始值
NOMAXVALUE --最大值
NOCYCLE
CACHE 10;
10):删除序列:
DROP SEQUENCE 序列名称
11):查询序列:
select 序列名称.NEXTVAL from dual;
12):给已有数据的表中添加ID主键:
update TPRG_TF_FILE_LIST set ID=rownum commit;
13):case when:
select case when STATE = 1 then '新进查核' when STATE = 2 then '地市审核' when STATE = 3 then '省公司审' else '结束' end STATE from 表名;
14):随机取几条数据:
select * from (select * from di.zd_rms_sascn where 地市ID = '610000' order by dbms_random.value) where rownum<= 5
15):循环插入:
declare begin for TEL in (select 手机号 from TPRG_YLZZHHY_RYGL where STATE='1' group by 手机号) loop insert into TPRG_YLRWZD_SZ(ID, 站址编码, 待办人员, 管理区域, 录入日期, 地市编号, STATE, 录入时间) select YLRWZD.NEXTVAL, 站址编码, TEL.手机号, 管理区域, to_char(sysdate,'yyyyMM'), 地市ID, 1, sysdate from (select * from di.zd_rms_station where 地市ID = '610800' order by dbms_random.value) where rownum <= 5 ;commit; end loop; end;
16):去重取最新:
SELECT * FROM (SELECT T.*, ROW_NUMBER ( ) OVER ( PARTITION BY T.站址编码 ORDER BY T.PICI DESC ) RW FROM fact_weusu_dfsdyj_bmsd T ) FI WHERE FI.RW = 1 and STATE = 1
17):排序(由小到大):
select * from 表名 order by to_number(ID) Asc
18):排序(由大到小):
select * from 表名 order by to_number(ID) desc
19):排序(取几条数据):
select * from ( select * from 表名 order by ID desc ) where rownum=1
补充:每个区域随机取20条数据
select * from ( select t.*,row_number() over(partition by t.区域 order by 区域 DESC) rn from (select * from TPRG_DsnFssseiBaosH where STATE = '10') t )where rn<=20;
20):日期字符串转格式:
将字符串:2023-03-15 16:59:53 <==> 202303
select replace(substr(日期,1,7),'-','') from TPRG_JDBCF_JCDB;
21):数据库根据范围查询:
select * from TPRG_YLRNIHAO_SZ where 录入日期 between '202303' and '202304' order by 录入日期;
22):查询当前年月至上年12月:
select substr(MONTH,1,4) ||'-'|| substr(MONTH,5,6) 月份 from ( SELECT to_number(TO_CHAR(add_months(trunc(sysdate, 'MM'), -(ROWNUM - 0)), 'yyyyMM')) month FROM DUAL CONNECT BY ROWNUM <= (select months_between(trunc(sysdate, 'MM'), trunc(sysdate, 'yyyy')) + 1 from dual) )
备注:dual 表上面数字代表从当年几月开始往后推,后面的自己调节即可;
23):查询今天数据:
SELECT COUNT(1) FROM T_CALL_RECORDSSSDS WHERE TO_CHAR(T_RKSJ,'YYYY-MM-DD')=TO_CHAR(SYSDATE,'YYYY-MM-DD');
24):查询昨天数据:
SELECT COUNT(1) FROM dual WHERE TO_CHAR(T_RKSJ,'YYYY-MM-DD')=TO_CHAR(SYSDATE-1,'YYYY-MM-DD');
25):查询本周数据:
SELECT COUNT(1) FROM dual WHERE T_RKSJ >= TRUNC(NEXT_DAY(SYSDATE-8,1)+1) AND T_RKSJ < TRUNC(NEXT_DAY(SYSDATE-8,1)+7)+1;
26):查询上周数据:
SELECT COUNT(1) FROM dual WHERE T_RKSJ >= TRUNC(NEXT_DAY(SYSDATE-8,1)-6) AND T_RKSJ < TRUNC(NEXT_DAY(SYSDATE-8,1)+1);
27):查询上月数据:
SELECT COUNT(1) FROM dual WHERE TO_CHAR(T_RKSJ,'YYYY-MM')=TO_CHAR(ADD_MONTHS(SYSDATE,-1),'YYYY-MM');
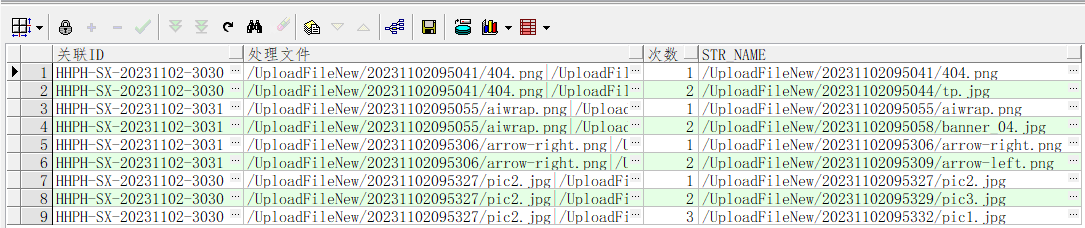
28):根据‘|’进行文件分割
select distinct 关联ID, s.处理文件, level 次数, regexp_substr(s.处理文件, '[^|]+',1,level) as str_name from TPRG_XIAN_HSSSSHPH_LIST s connect by level <= length(regexp_replace(s.处理文件,'[^|]+',''))+1 order by s.处理文件,2;
附图:表截图(原表)

附图:处理后(结果)
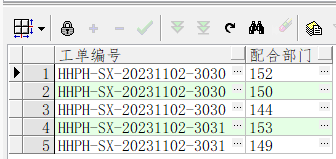
29):根据‘,’进行文件分割
select 工单编号, regexp_substr(t1.配合部门, '[^,]+', 1, level) 配合部门 from TPRG_XIAN_HHPTRSDFH t1 connect by t1.ID = prior t1.ID and prior dbms_random.value is not null and level <= length(t1.配合部门) - length(regexp_replace(t1.配合部门, ',', '')) + 1;
附图:表截图(原表)

附图:处理后(结果)
30):截取字符串:
select substr(字段名称, 截取开始位置, 截取结束位置) from 表名称; select substr('Hello World', 1,3) from dual;
31):去除字段空格与换行:(补充:去除单引号)
update 表明 set 字段A=replace(replace(字段A,' ',''),chr(10),'') where 1 = 1;
补充:select REPLACE(字段A, '''', '')字段A from 表名;
32):查表建表:
create table 新表名 as select 11,22,33 from dual;
33):Oracle模糊匹配:
SELECT T2.列名,T1.列名 FROM 主表 T1, 匹配表 T2 WHERE T1.匹配列 LIKE CONCAT('%',concat(T2.匹配列,'%'));
34):Oracle计算时间差:
select TO_NUMBER(TO_DATE('2018-6-5','yyyy-mm-dd hh24:mi:ss')- TO_DATE('2018-5-31','yyyy-mm-dd hh24:mi:ss')) 相差天数 from dual;
35):查询某字段含有数字的数据:
select * from dual where regexp_substr(字段名称,'[0-9]+') is not null;
36):查询某字段含有字母的数据:
select * from dual where regexp_like(字段名称, '[a-zA-Z]');
37):查询重复字段(单字段):
select 站址编码, count(*) from TPRG_YLRWZD_SZ group by 站址编码 having count(*) > 1
select 重复字段A, count(*) from 表 group by 重复字段A having count(*) > 1
38):查询重复字段(多字段):
select 站址编码, user_name, count(*) from TPRG_YLRWZD_SZ group by 站址编码, user_name having count(*) > 1
select 重复字段A, 重复字段B, count(*) from 表 group by 重复字段A, 重复字段B having count(*) > 1
39):Oracle 除法计算:
select decode(B,0,0,9/3) result from dual; --当B=0时,返回0,否则才返回9/3的结果给result
40):去除字段内回车/换行/空格/制表符等:
--去除字段内回车/换行/空格/制表符等 SELECT REGEXP_REPLACE('nihao nihsoa s sd ', '[[:space:]]', '') AS test FROM dual; --去除字段内回车/换行/空格 SELECT REPLACE(REPLACE(REPLACE('nihao nihsoa s sd ', ' ', ''), CHR(10), ''), CHR(13), '') AS test FROM dual;
41):竖表转横表(Oracle):
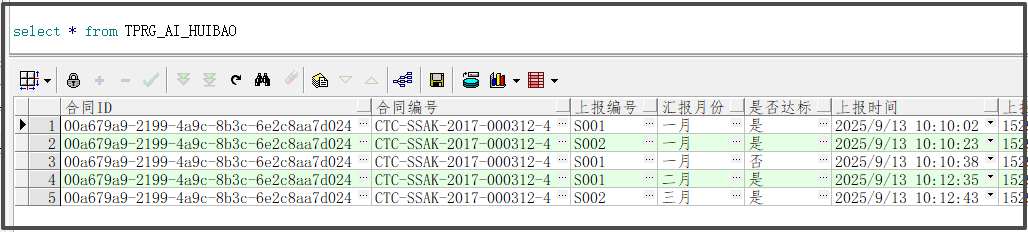

--原表数据(竖着排的数据) select * from TPRG_AI_HUIBAO; --去重后的数据 SELECT * FROM (SELECT T.*, ROW_NUMBER ( ) OVER ( PARTITION BY T.合同ID, T.合同编号, T.上报编号, T.汇报月份 ORDER BY T.上报时间 DESC ) RW FROM TPRG_AI_HUIBAO T ) FI WHERE FI.RW = 1; --处理后的数据(横着排的数据) SELECT 合同ID, 合同编号, 上报编号, MAX(CASE WHEN 汇报月份 = '一月' THEN 是否达标 END) AS 一月是否达标,MAX(CASE WHEN 汇报月份 = '二月' THEN 是否达标 END) AS 二月是否达标,MAX(CASE WHEN 汇报月份 = '三月' THEN 是否达标 END) AS 三月是否达标, MAX(CASE WHEN 汇报月份 = '四月' THEN 是否达标 END) AS 四月是否达标,MAX(CASE WHEN 汇报月份 = '五月' THEN 是否达标 END) AS 五月是否达标,MAX(CASE WHEN 汇报月份 = '六月' THEN 是否达标 END) AS 六月是否达标, MAX(CASE WHEN 汇报月份 = '七月' THEN 是否达标 END) AS 七月是否达标,MAX(CASE WHEN 汇报月份 = '八月' THEN 是否达标 END) AS 八月是否达标,MAX(CASE WHEN 汇报月份 = '九月' THEN 是否达标 END) AS 九月是否达标, MAX(CASE WHEN 汇报月份 = '十月' THEN 是否达标 END) AS 十月是否达标,MAX(CASE WHEN 汇报月份 = '十一月' THEN 是否达标 END) AS 十一月是否达标,MAX(CASE WHEN 汇报月份 = '十二月' THEN 是否达标 END) AS 十二月是否达标 FROM (SELECT * FROM (SELECT T.*, ROW_NUMBER ( ) OVER ( PARTITION BY T.合同ID, T.合同编号, T.上报编号, T.汇报月份 ORDER BY T.上报时间 DESC ) RW FROM TPRG_AI_HUIBAO T ) FI WHERE FI.RW = 1) GROUP BY 合同ID,合同编号,上报编号;
42):横表转竖表(Oracle):

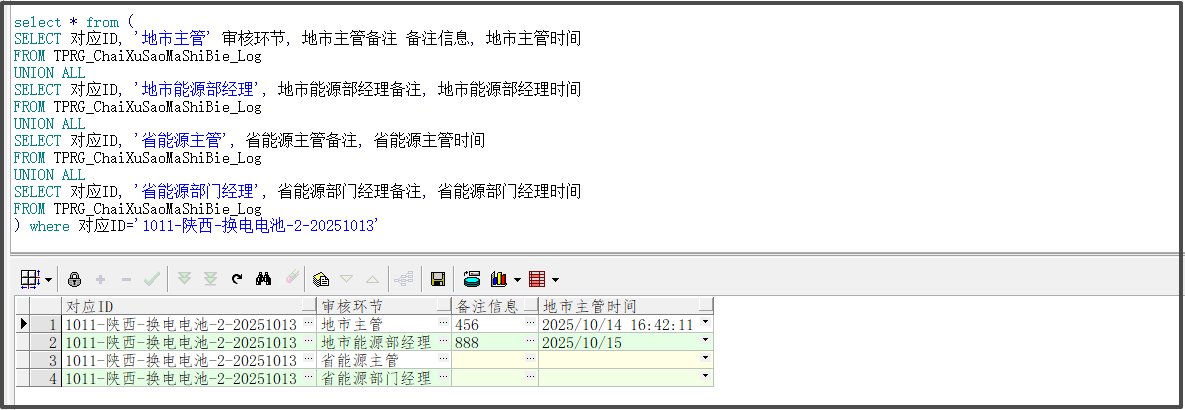
--原表数据 select * from TPRG_ChaiXuSaoMaShiBie_Log where 对应ID='1011-陕西-换电电池-2-20251013' --转后的数据 select * from ( SELECT 对应ID, '地市主管' 审核环节, 地市主管备注 备注信息, 地市主管时间 FROM TPRG_ChaiXuSaoMaShiBie_Log UNION ALL SELECT 对应ID, '地市能源部经理', 地市能源部经理备注, 地市能源部经理时间 FROM TPRG_ChaiXuSaoMaShiBie_Log UNION ALL SELECT 对应ID, '省能源主管', 省能源主管备注, 省能源主管时间 FROM TPRG_ChaiXuSaoMaShiBie_Log UNION ALL SELECT 对应ID, '省能源部门经理', 省能源部门经理备注, 省能源部门经理时间 FROM TPRG_ChaiXuSaoMaShiBie_Log ) where 对应ID='1011-陕西-换电电池-2-20251013'
争取摘到月亮,即使会坠落。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号