
使用神经网络做二分类预测
不想整理代码了。先给个结果图:
train 0 loss: 1838.0616 train 100 loss: 1441.5283 train 200 loss: 1299.4546 train 300 loss: 934.36536 train 400 loss: 506.06702 train 500 loss: 322.9782 train 600 loss: 271.5825 train 700 loss: 360.091 train 800 loss: 237.25177 train 900 loss: 332.97592 train 1000 loss: 117.5983 train 1100 loss: 173.39397 train 1200 loss: 51.26674 train 1300 loss: 82.82826 train 1400 loss: 74.705734 train 1500 loss: 113.63321 train 1600 loss: 71.29809 train 1700 loss: 38.41456 train 1800 loss: 82.75247 train 1900 loss: 44.553272 test 0,accuracy:0.953125,auc: (0.0, 0.9708618) test 1,accuracy:0.9375,auc: (0.9708618, 0.96028894) test 2,accuracy:0.9609375,auc: (0.96028894, 0.9594982) test 3,accuracy:0.953125,auc: (0.9594982, 0.96195656) test 4,accuracy:0.9375,auc: (0.96195656, 0.9627208)
loss这么大,结果这么准确。我也搞不懂是怎么肥事呀。
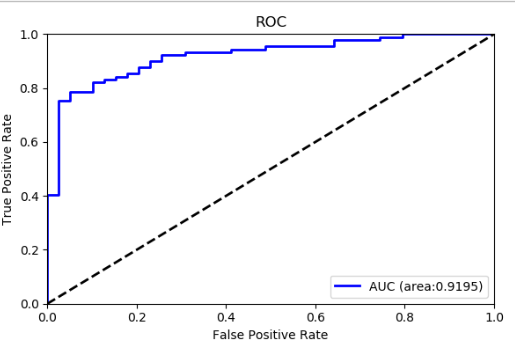
AUC也没什么问题。暂时认为是好的吧。
下面是源码dataUtil用来对数据预处理:


import pandas as pd import numpy as np def load_csv(filename): data=pd.read_csv(filename) data = data.drop(data.columns[39:], axis=1) return data def toInt(y): return int(y) def split_x_y(data): keys=data.keys().tolist() y=data["Label"] keys.remove("Label") x=data[keys] return (x.values,y.values) def max_min_nomalize(X): keys=X.keys().tolist() keys.remove("Index") keys.remove("Label") #keys.remove("Gender") #keys=["BMI","JiGan","ShouSuoYa","ShuZhangYa"] #删掉JiGan为-1的人 #X = X[X["JiGan"].isin([-1.0]) == False] for key in keys: #normalize_col=(X[key]-(X[key].max()+X[key].min())/2)/(X[key].max()-X[key].min()) #测试1:用mean来normolize normalize_col = (X[key] - X[key].mean()) / (X[key].max() - X[key].min()) X = X.drop(key, axis=1) X[key]=normalize_col return X if __name__=="__main__": pd.set_option('display.max_rows', 500) pd.set_option('display.max_columns', 500) pd.set_option('display.width', 500) data=load_csv("./data/patient_data.csv") #print(data.head()) print(data.info()) print(data.describe()) print(data.count()) #print(data["Label"].value_counts()) #data=data[data["JiGan"].isin([-1.0])==False] # print(data) #print(data) #print(data.describe()) #x=max_min_nomalize(data) # for key in data.keys().tolist(): # print("********************************************************{}**********************************".format(key)) # print(data[key].value_counts()) #data=load_csv("F:\workspaces\pycharm\Patient\data\patient_data.csv") #data=max_min_nomalize(data) #print(data.head())
然后是dnnModel用来构建模型:
import tensorflow as tf import numpy as np from sklearn.metrics import roc_auc_score, roc_curve import matplotlib.pyplot as plt from tensorflow.contrib import layers class dnnModel(): def __init__(self,x_train,y_train,x_test,y_test,learn_rate): self.epoch=0 self.learn_rate=learn_rate self.h1_dimen=500 self.h2_dimen=500 self.load_data2(x_train,y_train,x_test,y_test) #self.load_data(x_train, y_train) def load_data2(self,x_train,y_train,x_test,y_test): self.x_datas=x_train self.y_datas=y_train self.x_datas_test=x_test self.y_datas_test=y_test self.num_datas=self.y_datas.shape[0] self.num_datas_test=self.y_datas_test.shape[0] self.input_dimen=self.x_datas.shape[1] self.output_dimen = self.y_datas.shape[1] self.shullf() def load_data(self,x,y): datas_len=x.shape[0] self.x_datas=x[0:datas_len*8//10] self.y_datas=y[0:datas_len*8//10] self.x_datas_test=x[datas_len*8//10:] self.y_datas_test=y[datas_len*8//10:] self.num_datas=self.y_datas.shape[0] self.num_datas_test=self.y_datas_test.shape[0] self.input_dimen=self.x_datas.shape[1] self.output_dimen = self.y_datas.shape[1] self.shullf() #self.output_dimen = 1 def shullf(self): perm=np.arange(self.num_datas) np.random.shuffle(perm) self.x_datas=self.x_datas[perm] self.y_datas=self.y_datas[perm] perm=np.arange(self.num_datas_test) np.random.shuffle(perm) self.x_datas_test=self.x_datas_test[perm] self.y_datas_test=self.y_datas_test[perm] def weight_variable(self,shape,reg=True): init=tf.random_normal(shape=shape,dtype=tf.float32) if reg: if reg == True: regularizer = layers.l2_regularizer(0.05) else: regularizer = None return tf.Variable(init) def bias_variable(self,shape): init=tf.constant(0.1,dtype=tf.float32,shape=shape) return tf.Variable(init) def next_batch(self,batchsize): start=self.epoch self.epoch+=batchsize if self.epoch>self.num_datas: perm=np.arange(self.num_datas) np.random.shuffle(perm) self.x_datas=self.x_datas[perm] self.y_datas=self.y_datas[perm] self.epoch=batchsize start=0 end=self.epoch return self.x_datas[start:end],self.y_datas[start:end] def add_layer(self,x,input_dimen,output_dimen,name,relu=True): with tf.name_scope(name): weight = self.weight_variable([input_dimen, output_dimen]) bias = self.bias_variable([output_dimen]) tf.summary.histogram(name+"/weight",weight) tf.summary.histogram(name+"/bias",bias) if relu: return tf.nn.relu(tf.matmul(x,weight)+bias) else: return tf.matmul(x,weight)+bias def constructDnn(self,input_x): #输入层 input_layer=self.add_layer(input_x,self.input_dimen,500,name="input_layer",relu=True) #一个隐藏层 h1=self.add_layer(input_layer,500,500,relu=True,name="hidden_layer1") h1_drop=tf.nn.dropout(h1,keep_prob=0.7) #在增加一个隐藏层 h2=self.add_layer(h1_drop,500,1024,relu=True,name="hidden_layer2") h2_drop=tf.nn.dropout(h2,keep_prob=0.8) # 在增加一个隐藏层 # h3 = self.add_layer(h2_drop, 500, 500, relu=True, name="hidden_layer2") # h3_drop = tf.nn.dropout(h3, keep_prob=0.8) #输出层 output_layer=self.add_layer(h2_drop,1024,self.output_dimen,"output_layer",relu=False) tf.summary.histogram('/outputs', output_layer) return output_layer def train(self,maxTrainTimes,batchsize): X=tf.placeholder(dtype=tf.float32,shape=[None,self.input_dimen]) Y=tf.placeholder(dtype=tf.float32,shape=[None,self.output_dimen]) y_pre=self.constructDnn(X) entropy=tf.nn.softmax_cross_entropy_with_logits(logits=y_pre,labels=Y) #entropy=-tf.reduce_sum(Y*tf.log(tf.nn.softmax(y_pre))) loss = tf.reduce_mean(entropy) optimizer=tf.train.AdamOptimizer(self.learn_rate).minimize(loss) with tf.name_scope("evl"): correct=tf.equal(tf.argmax(y_pre,1),tf.argmax(Y,1)) accuracy=tf.reduce_mean(tf.cast(correct,dtype=tf.float32)) a = tf.cast(tf.argmax(y_pre, 1), tf.float32) b = tf.cast(tf.argmax(Y, 1), tf.float32) auc = tf.contrib.metrics.streaming_auc(a, b) tf.summary.scalar("loss", loss) tf.summary.scalar("accuracy", accuracy) #tf.summary.scalar("auc", auc) merged_summary_op = tf.summary.merge_all() summary_writer = tf.summary.FileWriter('./tmp/mnist_logs') with tf.Session() as sess: sess.run(tf.global_variables_initializer()) sess.run(tf.initialize_local_variables()) summary_writer.add_graph(sess.graph) for i in range(maxTrainTimes): x_train,y_train=self.next_batch(batchsize) sess.run(optimizer,feed_dict={X:x_train,Y:y_train}) #print(sess.run(y_pre,feed_dict={X:x_train,Y:y_train})) #print(sess.run(entropy, feed_dict={X: x_train, Y: y_train})) if i%100==0: print("train {} loss:".format(i),sess.run(loss,feed_dict={X:x_train,Y:y_train})) s = sess.run(merged_summary_op, feed_dict={X:x_train,Y:y_train}) summary_writer.add_summary(s, i) testTime=self.num_datas_test//batchsize for i in range(testTime): x_train, y_train = self.next_batch(batchsize) testAcc=sess.run(accuracy, feed_dict={X: x_train, Y: y_train}) testAuc=sess.run(auc,feed_dict={X: x_train, Y: y_train}) y_pred_pro = sess.run(y_pre,feed_dict={X: x_train, Y: y_train}) y_scores = np.array(y_pred_pro) auc_value = roc_auc_score(y_train, y_scores) a=np.array(y_train)[:,1] b=y_scores[:,1] fpr, tpr, thresholds = roc_curve(a,b , pos_label=1.0) plt.figure(figsize=(6, 4)) plt.plot(fpr, tpr, color='blue', linewidth=2, label='AUC (area:%0.4f)' % auc_value) plt.plot([0, 1], [0, 1], color='black', linewidth=2, linestyle='--') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.0]) plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('ROC') plt.legend(loc="lower right") plt.show() print("test {},accuracy:{},auc: {}".format(i,testAcc,testAuc)) def svm_train(self,maxTrainTimes,batchsize): # 初始化feedin x_data = tf.placeholder(shape=[None, self.input_dimen], dtype=tf.float32) y_target = tf.placeholder(shape=[None,1], dtype=tf.float32) # 创建变量 A = tf.Variable(tf.random_normal(shape=[self.input_dimen, 1])) b = tf.Variable(tf.random_normal(shape=[1, 1])) # 定义线性模型 model_output = tf.subtract(tf.matmul(x_data, A), b) # Declare vector L2 'norm' function squared l2_norm = tf.reduce_sum(tf.square(A)) # Loss = max(0, 1-pred*actual) + alpha * L2_norm(A)^2 alpha = tf.constant([0.01]) classification_term = tf.reduce_mean(tf.maximum(0., tf.subtract(1., tf.multiply(model_output, y_target)))) loss = tf.add(classification_term, tf.multiply(alpha, l2_norm)) my_opt = tf.train.GradientDescentOptimizer(0.01) train_step = my_opt.minimize(loss) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for i in range(maxTrainTimes): train_x,train_y=self.next_batch(batchsize) train_y=train_y.reshape([-1,1]) sess.run(train_step, feed_dict={x_data: train_x, y_target: train_y}) if i%100==0: print("loss in train step {}: {}".format(i,sess.run(loss,feed_dict={x_data: train_x, y_target: train_y})))
最后是程序入口,读取数据,喂给神经网络:
import dataUtil import dnnModel import tensorflow as tf import numpy as np import numpy as np import tensorflow as tf def one_hot(labels,class_num): labels=changeToint(labels) b = tf.one_hot(labels, class_num, 1, 0) with tf.Session() as sess: return sess.run(b) def changeToint(list): a=range(len(list)) for i in range(len(list)): #print("now in {},and total is {}".format(i,len(list))) if (int(list[i]))==0 : list[i]=int(0) else: list[i]=int(1) #print(i,list[i]) return list def select_x_y(x,y): #return x,y,x,y #选择2 4的数据 x_train_selected=[] y_train_selected=[] x_test_selected=[] y_test_selected=[] for i in range(x.shape[0]): item=x[i] if item[0]>20000 and item[0]<30000: x_train_selected.append(x[i,1:]) y_train_selected.append(y[i]) elif item[0]>40000: x_train_selected.append(x[i,1:]) y_train_selected.append(y[i]) else: x_test_selected.append(x[i,1:]) y_test_selected.append(y[i]) return np.array(x_train_selected),np.array(y_train_selected),np.array(x_test_selected),np.array(y_test_selected) if __name__=="__main__": data=dataUtil.load_csv("F:\workspaces\pycharm\Patient\data\patient_data.csv") #for key in data.keys().tolist(): # print(data.info()) # print(data["ShuZhangYa"].count()) x,y=dataUtil.split_x_y(dataUtil.max_min_nomalize(data)) y=one_hot(y,2) #y=changeToint(y).reshape([-1,1]) #print(y) x_train,y_train,x_test,y_test=select_x_y(x,y) #from tensorflow.examples.tutorials.mnist import input_data #MNIST = input_data.read_data_sets("mnist", one_hot=True) #mydnn=dnnModel.dnnModel(MNIST.train.images,MNIST.train.labels,0.1) #mydnn = dnnModel.dnnModel(x,changeToint(y).reshape([-1,1]),0.1) mydnn = dnnModel.dnnModel(x_train,y_train,x_test,y_test, 0.001) #mydnn.svm_train(1000,50) mydnn.train(2000,128)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号