
2.8 将tensor移动到GPU上
在Pytorch中,所有对tensor的操作,都是由GPU-specific routines完成的。tensor的device属性来控制tensor在计算机中存放的位置。
我们可以在tensor的构造器中显示的指定tensor存放在GPU上

也可以用 to 方法把一个CPU上的tensor复制到GPU上

这行代码在GPU上创建了一个新的,内容一致的tensor。
在GPU上的tensor的计算,就可以被GPU加速了。同样的,在GPU上的tensor会对应一个新的类型。如 torch.FloatTensor 对应 torch.cuda.FloatTensor.
基本,CPU和GPU上的tensor对应的API都是一样的,这样降低了开发成本。
对于多GPU的电脑,也可以通过0起始的索引显式的指定使用的GPU

指定device后,所有对tensor的操作都会在GPU上执行

要注意的是:points_gpu 在计算完成后不会被移回CPU。上面这行代码,做的事情是:
1 把points复制到GPU
2 在GPU上创建一个新的tensor,用来接收计算结果
3 返回一个指定计算结果的句柄
所以,如果对结果加一个常数,还是在GPU上进行的,而不会返回到CPU
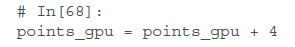
如果想把tensor返回给CPU,需要显式的指定device参数

调用 to方法太麻烦了,我们可以使用简写的 cuda 方法 和 cpu 方法来对tensor进行移动。

但是,使用 to 方法,我们可以通过指定 dtype和device参数,实现同时改变tensor的数据类型和存储位置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号