Python爬取图片
Python爬取图片
目标链接:https://pic.netbian.com/4kfengjing/
思路:先通过首页的源码分析提取到子页面的链接,然后通过子页面的链接的源码来提取到图片的下载链接,我们再访问那个下载链接将他转为字节写入文件就可以生成图片
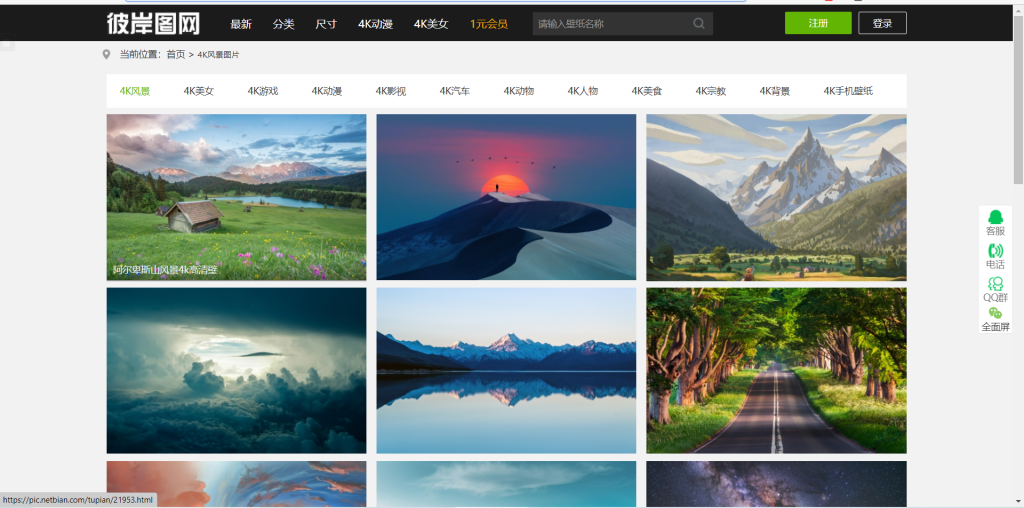
查看网页源码找到我们想要的地方

通过源码可以看出每一个.HTML的地方就是一个图片的链接
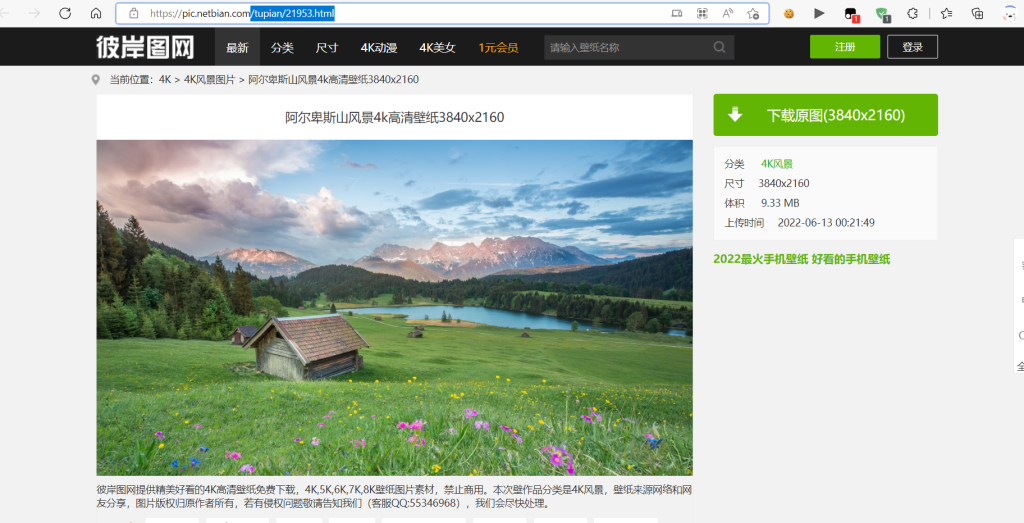
这里我们就可以拼接链接了
url="https://pic.netbian.com/"#这个是大的链接
uul="/tupian/21953.html"
new=url+uul..strip("/")#去除多余的一个反斜杠就可以拼接成新的一个链接了
new="https://pic.netbian.com/tupian/21953.html"

这里面可以找到图片的下载链接
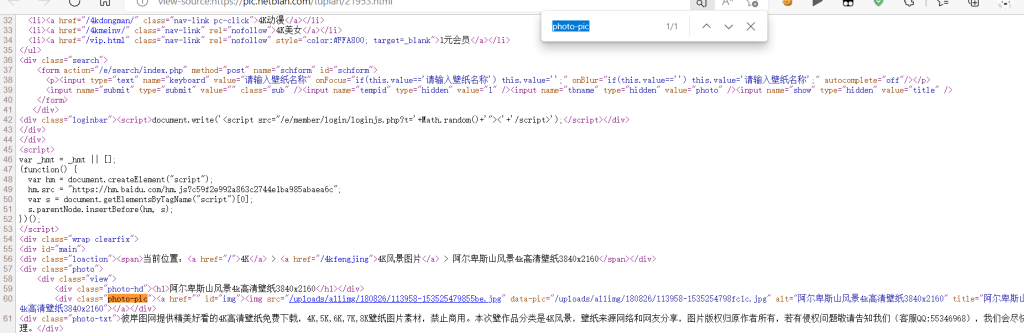
然后定位精准一点就可以找到图片下载位置了,这里我们需要提取的是第一个因为第二个链接图片有点不对劲我也不知道哪里不对劲第二张图链接要小一点
我们可以用正则表达式来匹配提取出链接然后因为这个不全我们再和主页面的url进行拼接就可以得到下载链接
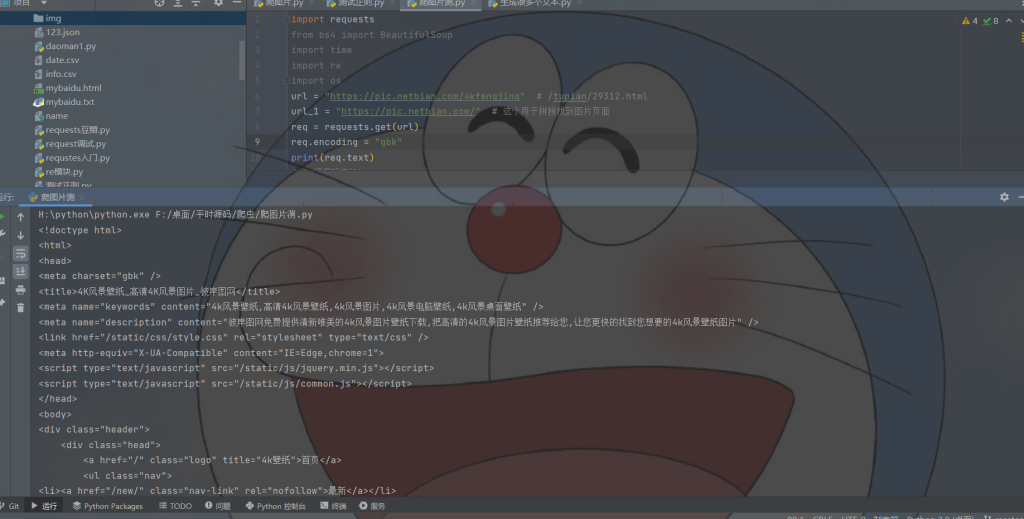
这里可以拿到网页源码
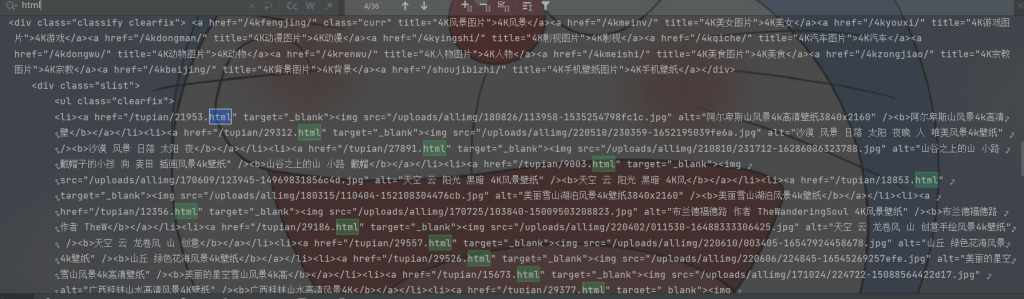
找到各个子页面的链接

定位到位置就可以进行筛选
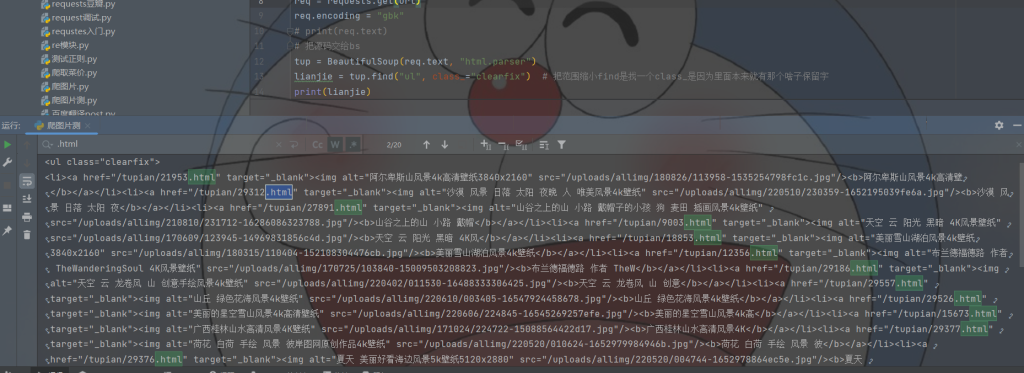
这就是筛选出来的
tup = BeautifulSoup(req.text, "html.parser")#声明是html
lianjie = tup.find("ul", class_="clearfix")#把范围缩小find是找一个class_是因为里面本来就有那个啥子保留字加个下划线就可以避免这个问题

我们再从我们已经提取到的页面中进行再次细分,看源码就可以知道
<a href对应的是一个链接


这样每一个链接都成了一个列表里面的元素我们再进行遍历拼接就可以得到新的链接

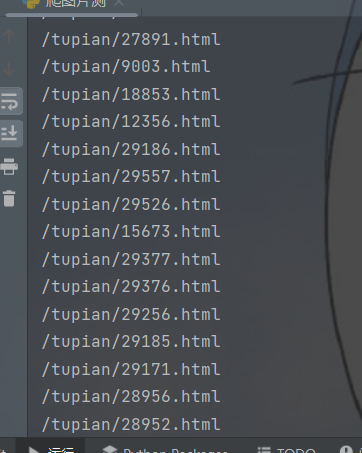
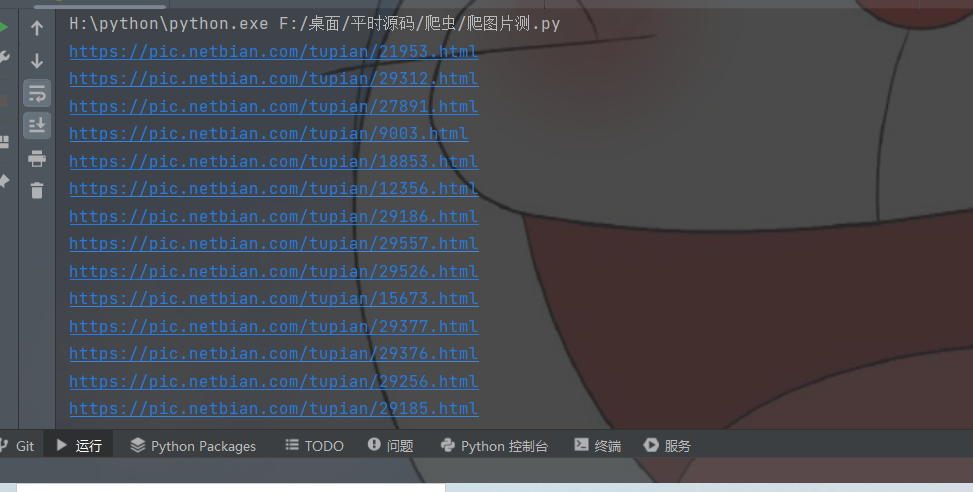
拼接成新的链接我们已经完成了获取子页面的链接然后我们再通过访问子页面的链接然后提取源码的关键字找到下载链接就可以了
req_1 = requests.get(wangye)
req_1.encoding = "gbk"
# time.sleep(100)调试的时候用不然请求过快就会封ip
photo = BeautifulSoup(req_1.text, "html.parser")
photo_1 = photo.find("div", class_="photo-pic") # 找特殊值或者就是只有一个出现的
print(photo_1)#这里拿到了图片的那个位置然后我们可以用find_all缩小范围找到网页
photo_2 = photo_1.find("img") # 拿到img标签位置
photo_3 = str(photo_2)

每一个div中都有一个下载链接

拿到img标签位置
我们就直接用正则表达式匹配到我们要的东西
obj = re.compile(r'<img alt=".*?src="(?P<download>.*?)"', re.S)#意思是img开始中间略过匹配到src然后给它分个组我们之后单独提取出来
xiazai = obj.findall(photo_3)#将他与链接匹配并且转化成数组
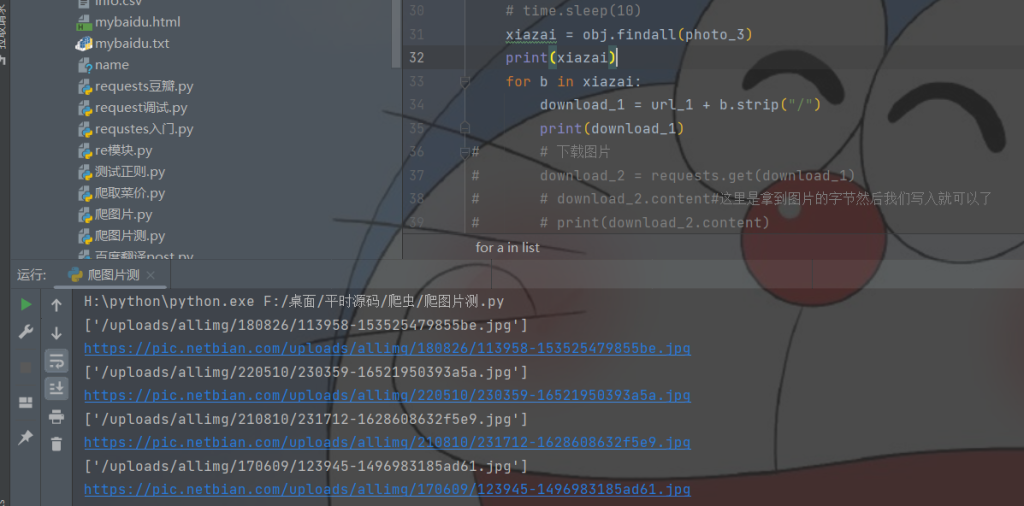
我们从数组中遍历出来拼接就是下载链接
下载链接
for b in xiazai: download_1 = url_1 + b.strip("/")# # 下载图片 download_2 = requests.get(download_1) # download_2.content#这里是拿到图片的字节然后我们写入就可以了 # print(download_2.content) file_name = download_1.split("/")[-1] # 文件名字 # print(file_name) os.chdir("F:\桌面\平时源码\爬虫\img") with open(file_name, 'wb') as f: f.write(download_2.content) print("下载完成:", file_name, os.getcwd()) time.sleep(10)
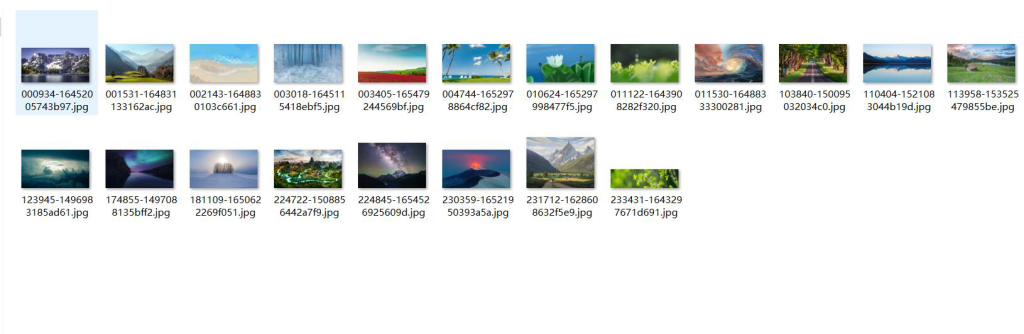
效果图
全部代码
import requests
from bs4 import BeautifulSoup
import time
import re
import os
url="https://pic.netbian.com/4kfengjing"#/tupian/29312.html
url_1="https://pic.netbian.com/"#这个用于拼接找到图片页面
req=requests.get(url)
req.encoding="gbk"
# print(req.text)
#把源码交给bs
tup=BeautifulSoup(req.text,"html.parser")
lianjie=tup.find("ul",class_="clearfix")#把范围缩小find是找一个class_是因为里面本来就有那个啥子保留字
list=lianjie.find_all("a")#通过find_all来提取ul里面的a
obj=re.compile(r'<img alt=".*?src="(?P<download>.*?)"',re.S)
for a in list:
# print(a.get("href"))#这里是通过a.get()找到href里面的链接
wangye=url_1+a.get("href").strip("/")#直接通过get就可以获取链接然后和之前的主链接进行拼接获得新的图片链接
#获取子页面的源代码
req_1=requests.get(wangye)
req_1.encoding="gbk"
# time.sleep(100)调试的时候用不然请求过快就会封ip
photo=BeautifulSoup(req_1.text,"html.parser")
photo_1=photo.find("div",class_="photo-pic")#找特殊值或者就是只有一个出现的
# print(photo_1)#这里拿到了图片的那个位置然后我们可以用find_all缩小范围
photo_2=photo_1.find("img")#拿到img标签位置
photo_3=str(photo_2)
xiazai=obj.findall(photo_3)
for b in xiazai:
download_1=url_1+b.strip("/")
print(download_1)
#下载图片
download_2=requests.get(download_1)
# download_2.content#这里是拿到图片的字节然后我们写入就可以了
# print(download_2.content)
file_name=download_1.split("/")[-1]#文件名字
# print(file_name)
os.chdir("F:\桌面\平时源码\爬虫\img")
with open(file_name,'wb') as f:
f.write(download_2.content)
print("下载完成:",file_name,os.getcwd())
time.sleep(10)
re模块
re模块是处理正则表达式的一个模块
1.正则表达式常用符号
(1).一般字符
| 字符 | 含义 |
|---|---|
| . | 匹配任意单个字符(不包括换行符\n) |
| \ | 转义字符(把有特殊含义的字符转换成字面意思) |
| […] | 字符集。对应字符计中的任意字符 |
(2).预定字符集
| 字符 | 含义 |
|---|---|
| \d | 匹配一个数字字符。等价于[0-9] |
| \D | 匹配一个非数字字符。等价于[^0-9 ] |
| \s | 匹配任何空白字符,包括空格、换页符等。[\f\n\r\t\v] |
| \S | 匹配任何非空白字符。 |
| \w | 匹配包括下划线的任何单词字符。等价于[A-Za-z0-9] |
| \W | 匹配任何非单词字符 |
(3).数量词
| 字符 | 含义 |
|---|---|
| * | 匹配前一个字符0或无限次 |
| + | 匹配前一个字符1或无限次 |
| ? | 匹配前一个字符0或1次 |
| 匹配前一个字符m次 | |
| 匹配前一个字符m至n次 |
(4).边界匹配
| 字符 | 含义 |
|---|---|
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
| \A | 仅匹配字符串开头 |
| \Z | 仅匹配字符串结尾 |
2.re模块及其方法
(1).search函数
re模块的search()函数匹配并提取第一个符合规律的内容,返回一个正则表达式对象。
语法为:
re.match(pattern, string, flags=0)
- pattern:要匹配的正则表达式
- srting:要匹配的字符串
- flag:用于控制正则表达式的匹配方式,如:是否区分大小写多行匹配等。
只要在a这个表达式中匹配到了[0-9],便返回匹配的字符串
import re
a = 'one1two2three3'
infos = re.search('\d+',a)
print(infos.group()) #group方法获取信息
(2).sub()函数
re模块提供了sub()函数用于替换字符串中的匹配项
语法为:
re.sub(pattern, repl, string, count=0, flags=0)
- pattern:要匹配的正则表达式
- repl:为替换的字符串
- string:为要被查找到替换的原始字符串
- counts:为模式匹配后替换的最大次数,默认0表示所有的匹配。
- flag:用于控制正则表达式的匹配方式,如:是否区分大小写多行匹配等。
(3).findall()函数
findall()函数匹配所有符合规律的内容,并以列表的形式返回结果,例如上文中的’one1two2three3’,通过search()函数只能匹配到第一个符合规律的结果,通过findall可以返回字符串所有的数字。
(4).re模块修饰符
| 修饰符 | 描述 |
|---|---|
| re.l | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响^和$ |
| re.S | 使匹配包括换行在内的所有字符 |
| re.U | 根据Unicod字符集解析字符。这个标志影响\w,\W,\b,\B |
| re.X | 通过给予你更灵活的格式一边你将正则表达式写得更利于理解 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号