python爬取代理ip
要写爬虫爬取大量的数据,就会面临ip被封的问题,虽然可以通过设置延时的方法来延缓对网站的访问,但是一旦访问次数过多仍然会面临ip被封的风险,这时我们就需要用到动态的ip地址来隐藏真实的ip信息,如果做爬虫项目,建议选取一些平台提供的动态ip服务,引用api即可。目前国内有很多提供动态ip的平台,普遍价格不菲,而对于只想跑个小项目用来学习的话可以参考下本篇文章。
简述###
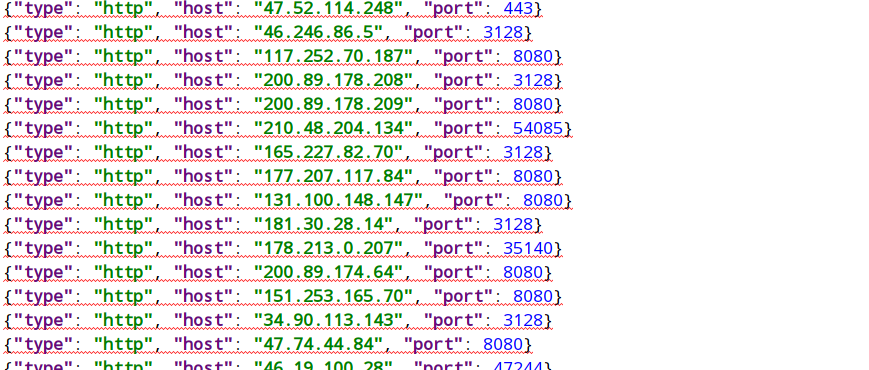
本篇使用简单的爬虫程序来爬取免费ip网站的ip信息并生成json文档,存储可用的ip地址,写其它爬取项目的时候可以从生成的json文档中提取ip地址使用,为了确保使用的ip地址的有效性,建议对json文档中的ip现爬现用,并且在爬取时对ip有效性的时间进行筛选,只爬取时长较长、可用的ip地址存储。
实现###
使用平台https://www.xicidaili.com/nn/来作为数据源,通过对http://www.baidu.com/的相应来判断ip的可使用性。引用lxml模块来对网页数据进行提取,当然也可以使用re模块来进行匹配提取,这里只使用lxml模块对数据进行提取。
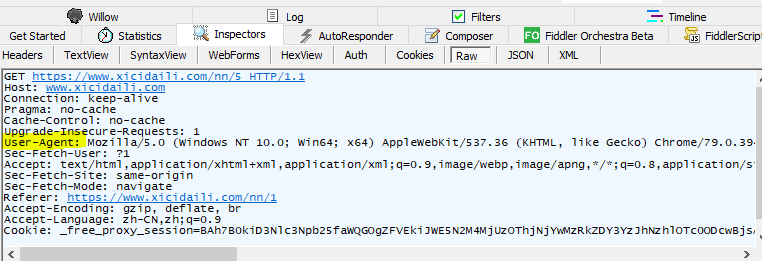
访问https://www.xicidaili.com/nn/数据源,并且启动Fiddler对浏览器数据进行监听,我这里浏览器采用的是Proxy SwitchyOmega插件来配合Fiddler进行使用,在Fiddler找到/nn/*数据查看User-Agent信息并复制下来作为我们访问的头文件。如图:
引入模块
import requests
from lxml import etree
import time
import json
获取所有数据
def get_all_proxy(page):
url = 'https://www.xicidaili.com/nn/%s'%page
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
response = requests.get(url, headers=headers)
html_ele = etree.HTML(response.text)
ip_eles = html_ele.xpath('//table[@id="ip_list"]/tr/td[2]/text()')
port_ele = html_ele.xpath('//table[@id="ip_list"]/tr/td[3]/text()')
print(ip_eles)
proxy_list = []
for i in range(0,len(ip_eles)):
check_all_proxy(ip_eles[i],port_ele[i])
return proxy_list
对数据进行筛选:
def check_all_proxy(host,port):
type = 'http'
proxies = {}
proxy_str = "%s://@%s:%s" % (type, host, port)
valid_proxy_list = []
url = 'http://www.baidu.com/'
proxy_dict = {
'http': proxy_str,
'https': proxy_str
}
try:
start_time = time.time()
response = requests.get(url, proxies=proxy_dict, timeout=5)
if response.status_code == 200:
end_time = time.time()
print('代理可用:' + proxy_str)
print('耗时:' + str(end_time - start_time))
proxies['type'] = type
proxies['host'] = host
proxies['port'] = port
proxiesJson = json.dumps(proxies)
with open('verified_y.json', 'a+') as f:
f.write(proxiesJson + '\n')
print("已写入:%s" % proxy_str)
valid_proxy_list.append(proxy_str)
else:
print('代理超时')
except:
print('代理不可用--------------->'+proxy_str)
运行程序:
if __name__ == '__main__':
for i in range(1,11): #选取前十页数据使用
proxy_list = get_all_proxy(i)
time.sleep(20)
print(valid_proxy_list)
生成的json文件: