Python爬取网站新闻
准备###
本实例使用辅助工具Fiddler抓取网页数据和使用文档查看工具sublime正则过滤(也可使用其它文档编辑工具),python开发工具使用Pycharm编辑
我们选取搜狐网的新闻页面进行爬取,对搜狐新闻以列表的形式显示出来。首先我们打开Fiddler 添加一个Filters,将搜狐网址放入Filters,在浏览器访问搜狐新闻网并刷新,从Fiddler中选中该访问记录,找出请求数据:
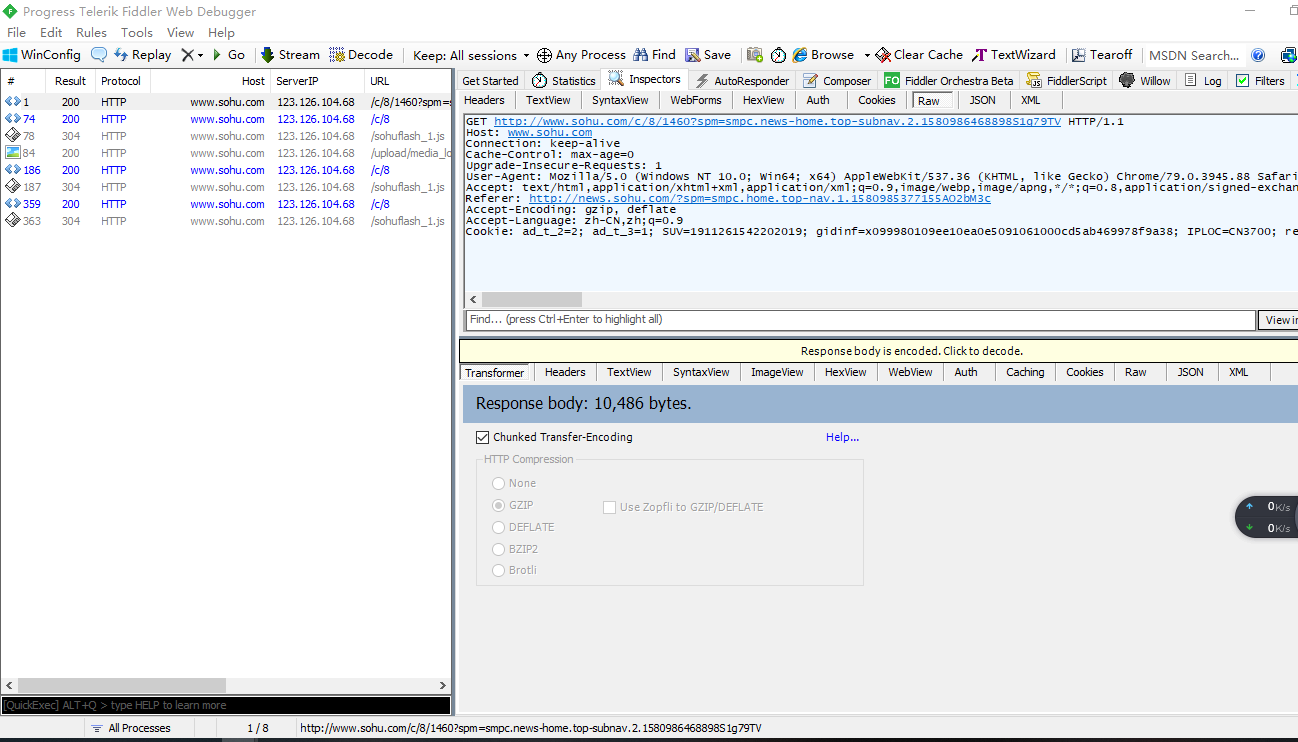
我们将Raw中的内容复制到sublime中:
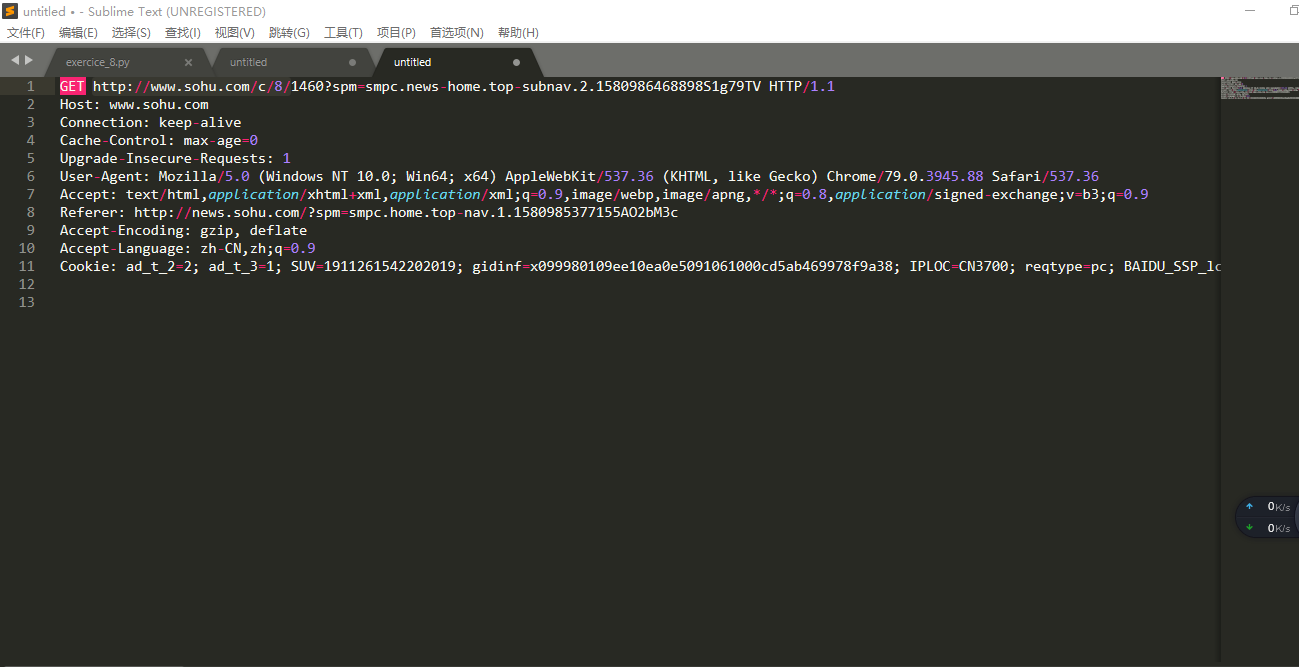
选取User-Agent中的内容
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36' 作为我们访问数据的头文件,并选中http://www.sohu.com/c/8/进行访问,可以查看到新闻页面:
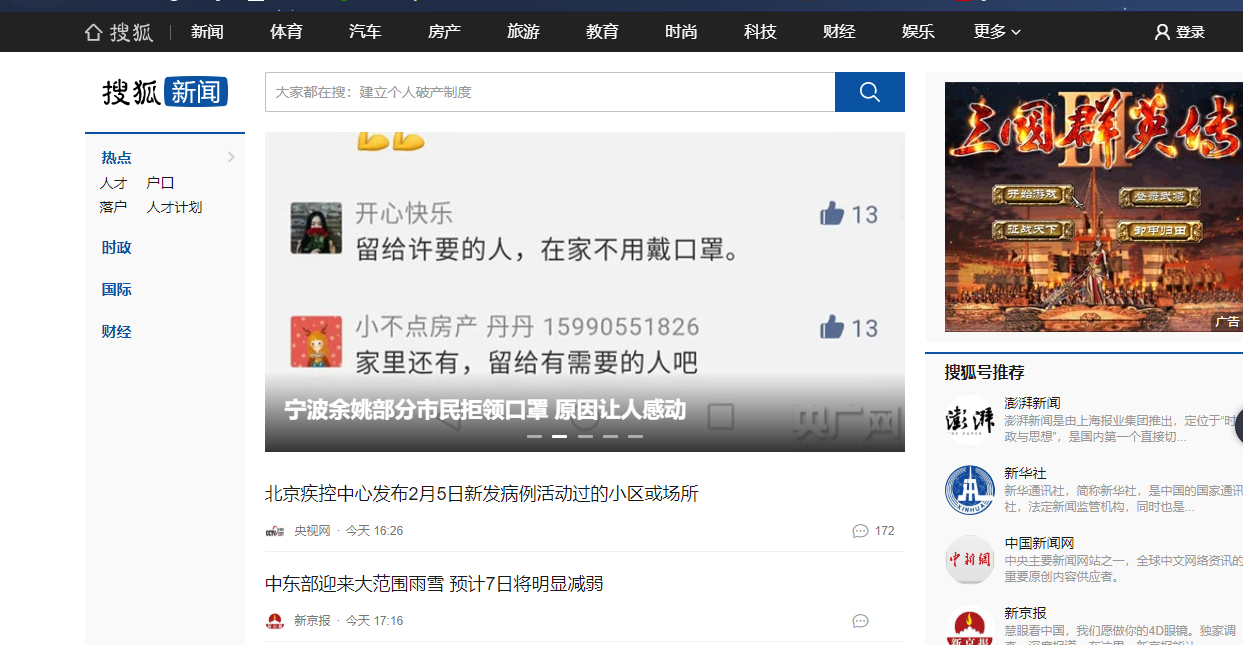
我们将http://www.sohu.com/c/8/作为我们爬取数据的url。
在页面中右击查看页面源代码,查看源代码并复制到sublime中,在sublime中进行查找并输入(点击左下角的正则过滤:.*)target="_blank">(.*)</a></h4>可以查看到新闻标题,我们将target="_blank">(.*)</a></h4>作为正则表达式的匹配内容
程序实现###
class HandleNews(object):
def __init__(self):
self.request = requests.session()
# self.head = 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) ' \
# 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
self.header={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
}
self.newslist = ''
def handle_list(self):
handle_patten=re.compile(r'target="_blank">(.*)</a></h4>')
handle_url='http://www.sohu.com/c/8'
handle_news=self.handle_request(methon='GET',url=handle_url,head=self.header)
self.newslist=re.findall(handle_patten,handle_news)
def handle_request(self,methon,url,head,data=None , info=None):
if methon == 'GET':
handle_respone=self.request.get(url=url,headers=head)
else:
handle_respone=' '
return handle_respone.text
if __name__ == '__main__':
handle=HandleNews()
handle.handle_list()
print(handle.newslist)
其中我们需要引用requests和re模块(用于正则表达式匹配)
import requests import re
运行结果:


