go grpc: connection reset by peer 的一种解决方案
最近添哥一直反映,他手下的设备以grpc stream的方式向我服务端发送数据。偶然会收到错误。现象如下:
- 连接已经建立了一段时间,正常使用。
- 突然client.Send 返回 eof。
- 客户端有报错:connection reset by peer
- 在服务端找到错误:context canceled
这里不得不提一下,客户端上报到服务的网络环境并不是很好,而且服务端每个进程有数十万个协程在运行,处理上十万条grpc stream。
选取了几个设备在服务端与客户端tcpdump,通过七七四十九天,终于捕获到了异常时的抓包。
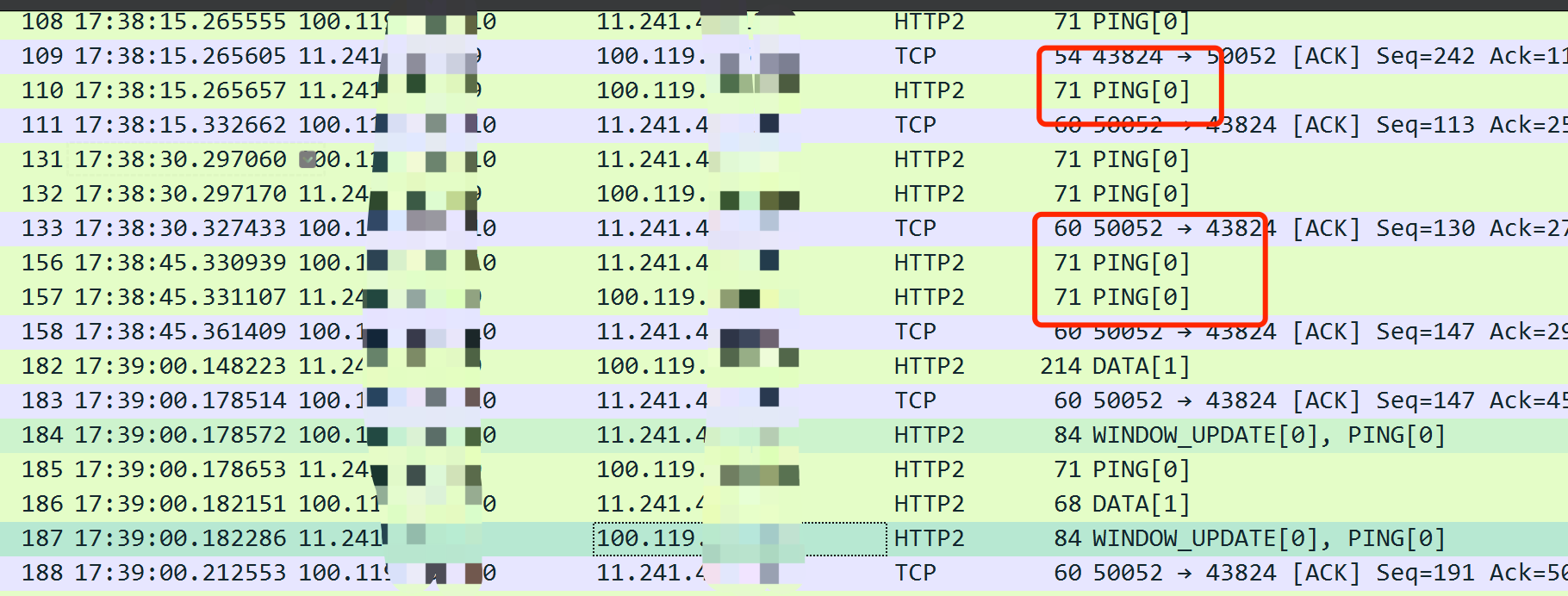
现象:
- 正常情况下,服务端客户端定期互Ping。
- 当异常时,在服务端/客户端的抓包会发现Ping包未回。很快连接断开。
猜测和grpc keepalive功能有关。
grpc server keepalive配置
原始配置
var keepAliveArgs = keepalive.ServerParameters{
Time: 60 * time.Second,
Timeout: 5 * time.Second,
}
s := grpc.NewServer(
grpc.KeepaliveParams(keepAliveArgs).....)
为了防止客户端断连后资源泄漏,grpc的服务端一般会配置keepalive,每隔一段时间就向空闲的client发送ping包,并计算回包的时间。当ping没有回应。则认为连接已失败(比如被墙),此时在服务端会关闭这个连接并配置svr.Context()为done。
上面的配置代表,每60S向客户端检测一次,如果ping的包没有在5秒内回,则断开连接。此时就会出现上述的异常事件。
原因分析
为了弄清keepalive的逻辑,查看源码grpc/internal/transport/http2_server.go
grpc ping发包逻辑
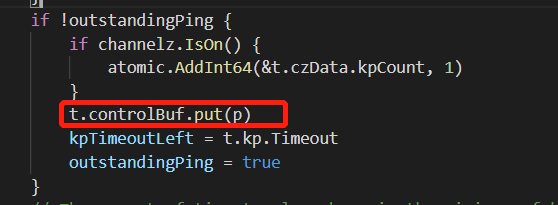
每隔预设的时间,就会发一个包。并将kpTimeoutLeft置为keepalive.Timeout。
发包之后逻辑
- 检测是否在kpTimeoutLeft为0前收到了任何数据(不仅是ping的回包)。
- 此时outstandingPing为true,所以不会再有新的ping被发出。这是最坑的一点设计。合理的设计应该允许重试几次,以重试后能收到包为准。
- 不停的去sleep,并去减小kpTimeoutLeft。
- 当kpTimeoutLeft<0,连接关闭。
![]()
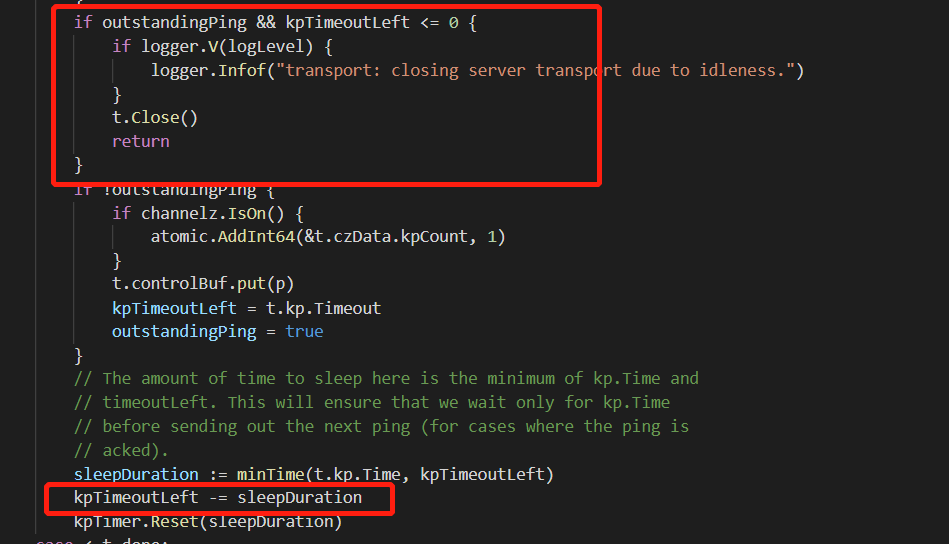
预期外断联原因
可能是因为网络抖动或者grpc server忙不过来,使得某次的ping包被丢弃或未及时处理。造成了连接被错误的切断。
解决
一开始,想要找一找有没有retry之类的配置。不要仅丢弃一次就把连接切断,但没找到。这时,添哥突发奇想,将Timeout的时间延长。于是,keepalive的配置变成了这样:
var keepAliveArgs = keepalive.ServerParameters{
Time: 30 * time.Second,
Timeout: 90 * time.Second,
}
在这个配置下,为ping之后给了更长的反应时间,根据grpc的源码,90秒内如果有任意的数据被接收(包含收到客户端发来的消息)。连接都不会被切断。但假如客户端一直没有数据回发,猜想应该还是会把连接切断。因为ping在没有收到回消息的时候不会再进行下一次ping。
通过查看注释也能应证代码的实现:
// After having pinged for keepalive check, the server waits for a duration
// of Timeout and if no activity is seen even after that the connection is
// closed.
Timeout time.Duration // The current default value is 20 seconds.
只要在ping后timeout内有activity,连接就不会中断。还好这个业务client和server交互很频繁,在90秒内一般会有数据的交互。
立马变更,困扰我们很久的问题,用一种不是很优雅的方式解决了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号