《统计学习方法》笔记
《统计学习方法》笔记
书籍ISBN:978-7-302-27595-4
第3章 k近邻法
P37 3.1节 k近邻算法
k近邻算法简单、直观:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把该输入实例分为这个类。算法描述如下:
输入:训练数据集

其中xi是n维实数空间上的实例特征向量。yi∈{c1, c2,..., ck}为实例的类别,i = 1, 2,..., N;新输入的实例特征向量x。
输出:实例x所属的类y。
(1)根据给定的距离度量,在训练集T中找出与x最邻近的k个点,涵盖这k个点的x的邻域记做Nk(x);
(2)在Nk(x)中根据分类决策规则(比如多数表决)决定x的类别y:
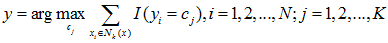
其中I为指示函数,比如在多数表决的规则下,yi=cj时I为1,否则为0。
k近邻法没有显示的学习过程。
P39 3.2.2 距离度量
特征空间中两个实例点的距离是两个实例点相似程度的反映。k近邻模型的特征空间一般是n维实数向量空间,使用的距离一般是欧氏距离,但也可以是其他距离,如更一般的Lp距离(Lp distance)或Minkowski距离(Minkowski distance)。
设特征空间X是n维实数向量空间,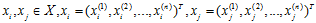 ,
,
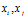 的Lp距离定义为:
的Lp距离定义为:

这里的p >= 1。当p = 2时,称为欧式距离
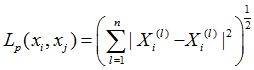
当p = 1时,称为曼哈顿距离(Manhattan distance)

当 时,它是各个坐标距离的最大值,即
时,它是各个坐标距离的最大值,即

下图给出了在二维空间中p取不同值时,与原点的Lp距离为1的点集的图形。

第4章 朴素贝叶斯法
P47 4.1节 基本方法
设输入空间A为n维向量的集合,输出空间为类标记集合B={c1, c2,..., ck},输入为特征向量x∈A,输出为类标记y∈B。X是定义在输入空间A上的随机向量,Y是定义在输出空间B上的随机变量。P(X, Y)是X和Y的联合概率分布,训练数据集
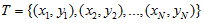
由P(X, Y)独立同分布产生。
朴素贝叶斯法通过训练数据集学习联合概率分布P(X, Y)。具体的,学习以下先验概率分布及条件概率分布。其中的先验概率分布:

条件概率分布:

于是学习到联合概率分布P(X, Y)。
条件概率分布 有指数量级的参数,对其估计在实际上是不可行的。假设
有指数量级的参数,对其估计在实际上是不可行的。假设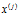 可取值有
可取值有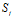 个,
个,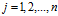 ,Y可取值有K个,那么参数个数为
,Y可取值有K个,那么参数个数为
朴素贝叶斯法对条件概率分布坐了条件独立性的假设,由于这是一个较强的假设,朴素贝叶斯法也由此得名。具体地,条件独立性假设是
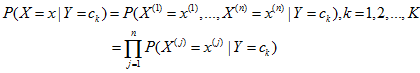
朴素贝叶斯法实际上学习到生成数据的机制,所以属于生成模型。条件独立假设等于是说用于分类的特征在类确定的条件下都是条件独立的。这一假设使朴素贝叶斯法变得简单,但有时会牺牲一定的分类准确率。使用朴素贝叶斯法分类时,对给定的输入x,通过学习到的模型计算后验概率分布,并将后验概率最大的类作为x的类输出。后验概率计算根据贝叶斯定理进行:
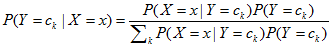
注意到右边的分母对于所有的ck都是相同的。于是,朴素贝叶斯分类器可以表示为:
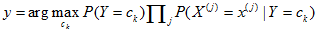
第5章决策树
5.2节特征选择
P60 信息增益
在信息论与概率统计中,熵(Entropy)是表示随机变量不确定性的度量。设X是一个取有限个值的离散随机变量,其概率分布为
P(X = xi) = pi, i = 1, 2, ..., n
则随机变量X的熵的定义为

条件熵H(Y|X)表示再一直随机变量X的条件下,随机变量Y的不确定性。随机变量X给定的条件下随机变量Y的条件熵(Conditional entropy)定义为X给定的条件下Y的条件概率分布的熵对X的数学期望
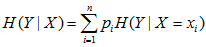
在这里,如果有0概率,令0log0 = 0。
当熵和条件熵由数据估计(特别是极大似然估计)得到时,所对应的熵与条件熵分别称为经验熵(Empirical entropy)和经验条件熵(Empirical conditional entropy).
信息增益(Information gain)表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。特征A对训练数据集D的信息增益g(D, A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差。
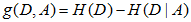
按照例5.2中的叙述,在进行特征选择时,计算得到多个特征的信息增益值之后,选取信息增益值最大的特征,作为最优特征。
信息增益值的大小是相对于训练数据集而言的,并没有绝对意义。继而出现了信息增益比(Information gain ratio):特征A对训练数据集D的信息增益比gR(D, A)定义为其信息增益g(D, A)与训练数据集D的经验熵H(D)之比:

5.3节决策树的生成
P63 ID3算法
ID3算法的核心是在决策树各个结点上应用信息增益准则特征选择,递归地构建决策树,具体方法是:从根结点开始,对节点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子结点;再对子结点递归地调用以上方法构建决策树;知道所有特征的信息增益小于某个阈值,或者没有特征可以选择为止。
ID3相当于用极大似然法进行概率模型的选择。但是由于算法只有树的生成,所以该算法生成的树容易产生过拟合。
P65 C4.5的生成算法
C4.5在生成的过程中,用信息增益比来特征选择。算法描述如下:
输入:训练数据集D,特征集A,阈值ε
输出:决策树T
(1)如果D中所有实力属于同一类Ck,则置T为单结点树,并将Ck作为该结点的类,返回T;
(2)如果A=空集,则置T为单结点树,并将D中实例数最大的类Ck作为该结点的类,返回T;
(3)否则,计算出A中各特征对D的信息增益比,选择信息增益比最大的特征Ag;
(4)如果Ag的信息增益比小于阈值ε,则置T为单结点树,并将D中实例数最大的类Ck作为该结点的类,返回T;
(5)否则,对Ag的每一可能值ai,依Ag=ai将D分割为子集若干非空Di,将Di中实例数最大的类作为标记,构建子结点i,由结点及其子结点构成树T,返回T;
(6)对结点i,以Di为训练集,以A-{Ag}为特征集,递归的调用(1)-(5),得到子树Ti,返回Ti。
第6章逻辑斯谛回归与最大熵模型
6.2节最大熵模型(Maximum entropy model)
P80 最大熵原理
最大熵原理是概率模型学习的一个准则。最大熵原理认为,学习概率模型时,在所有可能的概率模型中,熵最大的模型是最好的模型。通常用约束条件来确定概率模型的集合,所以最大熵原理也可以表述为在满足约束条件的模型集合中选取熵最大的模型。
假设离散随机变量X的概率分布是P(X),则其熵是
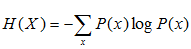
熵满足下列不等式:
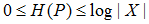
式中,|X|是X的取值个数,当且仅当X的分布是均匀分布时右边的等号成立。这就是说,当X服从均匀分布时,熵最大。直观地,最大熵原理认为要选择的概率模型首先必须满足已有的事实,即约束条件。在没有更多信息的情况下,那些不确定的部分都是"等可能的"。最大熵原理通过熵的最大化来表示等可能性。"等可能"不容易操作,而熵则是一个可优化的数值指标。
第7章支持向量机
P95 线性可分支持向量机
考虑一个二分类问题,假设输入空间与特征空间为两个不同的空间,输入空间为欧式空间或者离散空间,特征空间为欧氏空间或希尔伯特空间,线性支持向量机假设两个空间内元素一一对应,而非线性支持向量机利用一个从输入空间到特征空间的非线性映射将输入映射为特征向量。所以输入都由输入空间转化为特征空间,支持向量机的学习是在特征空间进行的。
假设给定一个特征空间上的训练数据集
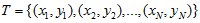
其中输入空间A是n维实数空间,xi∈A,输出空间B为{-1, +1},yi∈B。yi是xi的类标记,当yi=+1时,xi为正例,反之为负例。
学习的目标是在特征空间中找到一个分离超平面,能将实例分到不同类。分离超平面对应于方程
w·x+b=0,由法向量与截距b决定,可用(w, b)来表示。一般的,当训练数据集线性可分时,存在无穷个分离超平面可将两类数据正确分开。感知机利用误分类最小的策略,求得分离超平面,不过这时解有无穷多个,线性可分支持向量机利用间隔最大化求最优分离超平面,这时解唯一。这时学习得到的分离超平面为
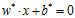
相应的分类决策函数就是
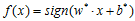
称为线性可分支持向量机。在二维特征空间中,线性可分支持向量机对应着将两类数据正确划分并且间隔最大的直线。
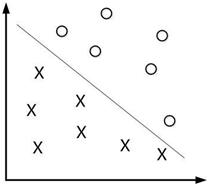
P102 支持向量和间隔边界
在线性可分情况下,训练数据集的样本点中与分离超平面距离最近的样本点的实例称为支持向量。
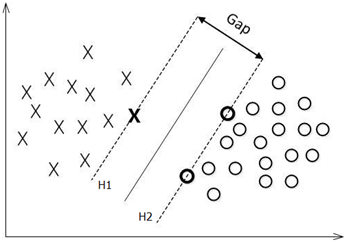
注意到H1和H2平行,没有实例点落在他们中间,在H1和H2上的点,就是支持向量。H1与H2之间的距离称为间隔,间隔等于 。H1和H2称为间隔边界。
。H1和H2称为间隔边界。
在决定分离超平面时只有支持向量起作用,而其他实例点并不起作用,支持向量的个数一般很少,所以支持向量机由很少的"重要的"训练样本确定。
7.3节非线性支持向量机与核函数
P115 核技巧
非线性分类问题是指通过利用非线性模型才能很好地进行分类的问题
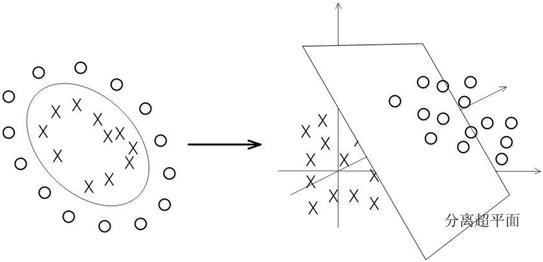
如果输入空间是n维实数空间,且能用此空间中的一个超曲面将正负例正确分开,则称这个问题为非线性可分问题。非线性问题不好求解,可以对输入空间进行一个非线性变换,将非线性问题变换为线性问题。例如将左图的超曲面,变换成右图的超平面
第9章 EM算法及其推广
P155 9.1节 EM算法的引入
概率模型又是既含有观测变量(Observable variable),又含有隐变量或潜在变量(Latent variable)。EM算法就是含有隐变量的概率模型参数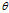 的极大似然估计法。将观测数据表示为
的极大似然估计法。将观测数据表示为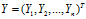 ,未观测数据表示为
,未观测数据表示为 ,则观测数据的似然函数为:
,则观测数据的似然函数为:

对参数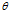 的最大似然估计为:
的最大似然估计为:
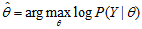
这个问题没有解析解,只有通过迭代的方法求解,EM算法就是可以用于求解这个问题的一种迭代算法。下面是算法描述。
输入:观测变量数据Y,隐变量数据Z,联合分布P(Y,Z| ),条件分布P(Z|Y,
),条件分布P(Z|Y,  );
);
输出:模型参数
(1)选择参数的初值 ,开始迭代;
,开始迭代;
(2)E步:记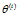 为第i次迭代参数
为第i次迭代参数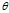 的估计值,在第i+1次迭代的E步中,计算
的估计值,在第i+1次迭代的E步中,计算
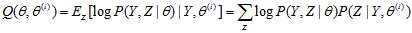
这里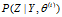 是在给定观测数据Y和当前的参数估计
是在给定观测数据Y和当前的参数估计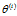 下隐变量数据Z的条件概率分布;
下隐变量数据Z的条件概率分布;
(3)M步:求使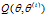 极大化的
极大化的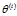 ,确定第i+1次迭代的参数的估计值
,确定第i+1次迭代的参数的估计值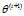 。
。

(4)重复第(2)步和第(3)步,直到收敛。
EM算法的核心是Q函数。完全数据的对数似然函数 关于在给定观测数据Y和当前参数
关于在给定观测数据Y和当前参数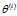 下对为观测数据Z的条件概率分布
下对为观测数据Z的条件概率分布 的期望称为Q函数,公式见上。
的期望称为Q函数,公式见上。
P162 EM算法的收敛性
EM算法的收敛性包含关于对数似然函数序列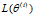 的收敛性和关于参数估计序列的收敛性
的收敛性和关于参数估计序列的收敛性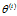 两层意思,前者不蕴涵后者。在大多数情况下,这两者都是收敛的。但是只能保证参数估计序列收敛到对数似然函数序列的稳定点,不能保证收敛到极大值点。所以在应用中,初值的选择变得非常重要,选择不同的初值可能得到不同的参数估计值。常用的办法是选取几个不同的初值进行迭代,然后对得到的各个估计值加以比较,从中选择最好的。
两层意思,前者不蕴涵后者。在大多数情况下,这两者都是收敛的。但是只能保证参数估计序列收敛到对数似然函数序列的稳定点,不能保证收敛到极大值点。所以在应用中,初值的选择变得非常重要,选择不同的初值可能得到不同的参数估计值。常用的办法是选取几个不同的初值进行迭代,然后对得到的各个估计值加以比较,从中选择最好的。
第10章 隐马尔可夫模型
P171 10.1节 隐马尔可夫模型
隐马尔可夫模型是关于时序的概率模型,描述一个由隐藏的马尔科夫链随机生成的不可观测的状态随机序列,再由各个状态生成一个由观测而产生观测随机序列的过程。隐藏马尔科夫链随机生成的状态序列,称为状态序列(State sequence);每个状态生成一个观测,而由此产生的观测随机序列,成为观测序列(Observation sequence)。序列的每一个位置又可以看作是一个时刻。
下面是隐马尔科夫模型的形式化定义:
假设Q是所有可能的状态的集合,V是所有可能的观测的集合,N是可能的状态数,M是可能的观测数。

I是长度为T的状态序列,O是对应的观测序列。

A是状态转移概率矩阵,描述t时刻处于状态qi的条件下在t+1时刻转移到状态qj的概率:
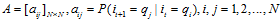
B是观测概率矩阵,描述t时刻处于状态qi的条件下,生成观测vk的概率:
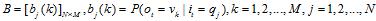
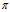 是初始状态概率向量,描述时刻t=1时,处于状态qi的概率
是初始状态概率向量,描述时刻t=1时,处于状态qi的概率
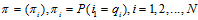
隐马尔科夫模型由初始状态概率向量 、状态转移概率矩阵A和观测概率矩阵B决定。
、状态转移概率矩阵A和观测概率矩阵B决定。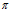 和A决定状态序列,B决定观测序列。A,B,
和A决定状态序列,B决定观测序列。A,B,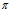 称为隐马尔可夫模型的三要素。
称为隐马尔可夫模型的三要素。
从定义可知,隐马尔可夫模型作了两个基本假设:
(1)齐次马尔科夫性假设,即假设隐藏的马尔科夫链在任意时刻t的状态只依赖于其前一时刻的状态,与其他时刻的状态及观测无关,也与时刻t无关。
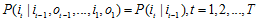
(2)观测独立性假设,即假设任意时刻的观测只依赖于该时刻的马尔科夫链的状态,与其他观测状态无关。

第12章统计学习方法总结
|
方法 |
适用问题 |
模型特点 |
模型类型 |
学习策略 |
损失函数 |
学习算法 |
|
感知机 |
二分类 |
分离超平面 |
判别模型 |
极小化误分点到超平面距离 |
误分点到超平面的距离 |
随机梯度下降 |
|
K近邻法 |
多分类 回归 |
特征空间 样本点 |
判别模型 |
- |
- |
- |
|
朴素贝叶斯法 |
多分类 |
特征与类别的联合概率分布 条件独立假设 |
生成模型 |
极大似然估计,极大后验概率估计 |
对数似然损失 |
概率计算公式 EM算法 |
|
决策树 |
多分类 回归 |
分类树 回归树 |
判别模型 |
正则化的极大似然估计 |
对数似然损失 |
特征选择,生成,剪枝 |
|
逻辑斯蒂回归与最大熵模型 |
多分类 |
特征条件下类别的的条件概率分布 对数线性模型 |
判别模型 |
极大似然估计,正则化的极大似然估计 |
逻辑斯蒂损失 |
改进的迭代尺度算法 梯度下降 拟牛顿法 |
|
支持向量机 |
二分类 |
分离超平面 核技巧 |
判别模型 |
极小化正则化合页损失,软间隔最大化 |
合页损失 |
序列最小最优化算法(SMO) |
|
提升方法 |
二分类 |
弱分类器线性组合 |
判别模型 |
极小化假发模型的指数损失 |
指数损失 |
前向分步加法算法 |
|
EM算法 |
概率模型参数估计 |
含隐变量概率模型 |
一般方法,无具体模型 |
极大似然估计,极大后验概率估计 |
对数似然损失 |
迭代算法 |
|
隐马尔可夫模型 |
标注 |
观测序列与状态序列的联合概率分布模型 |
生成模型 |
极大似然估计,极大后验概率估计 |
对数似然损失 |
概率计算公式 EM算法 |
|
条件随机场 |
标注 |
状态序列条件下观测序列的条件概率分布,对数线性模型 |
判别模型 |
极大似然估计,正则化极大似然估计 |
对数似然损失 |
改进的迭代尺度算法 梯度下降 拟牛顿法 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号