
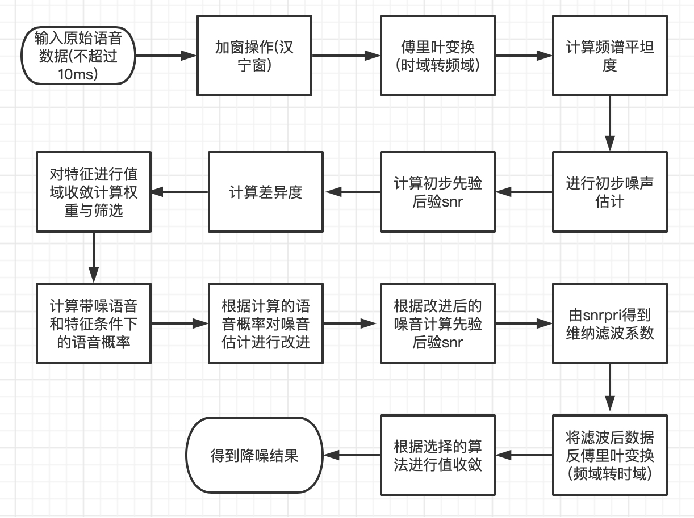
webrtc降噪原理
1.基本原理:
采用维纳滤波器抑制估计出来的噪声
时域与频域状态下:Y = N + S (Y:原始信号,S:纯净声音,N:噪音)
根据中心极限定义,一般认为噪声和语音分布服从均值为0,方差为ui的正态分布
中心思想:从Y中估计噪声N,然后抑制N以得到语音
估计噪声方法: 对似然比函数进行改进,将多个语音/噪声分类特征合并到一个模型中形成一个多特征综合概率密度函数,对输入的每帧频谱进行分析。其可以有效抑制风扇/办公设备等噪声。
2.处理过程
1)加窗
for (i = 0; i < inst->anaLen; i++) { winData[i] = inst->window[i] * inst->dataBuf[i]; energy1 += winData[i] * winData[i]; }
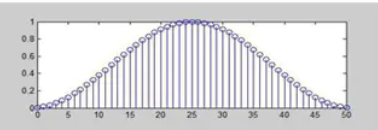
采用hanning窗
汉宁窗公式如下:
![]()
特征:升余弦函数,消去高频干扰和漏能,适用于非周期性的连续信号
图特征如下:
2) 傅里叶变换
采用实傅里叶变换
WebRtc_rdft(inst->anaLen, 1, winData, inst->ip, inst->wfft);
将原始数据进行时域到频域的变换,此处采用蝶形算法进行快速傅里叶变换
得到实部虚部与能量值
magn = sqrt(real*real+imag*imag)
imag[inst->magnLen - 1] = 0; //虚部 real[inst->magnLen - 1] = winData[1]; //实部 magn[inst->magnLen - 1] = (float)(fabs(real[inst->magnLen - 1]) + 1.0f); //增强幅度
fTmp = real[i] * real[i]; fTmp += imag[i] * imag[i]; signalEnergy += fTmp; magn[i] = ((float)sqrt(fTmp)) + 1.0f
3)计算频谱平坦度
频谱平坦度介绍:
属于三个特征集中的一个特征,假设语音比噪音有更多的谐波,语音频谱往往在基频和谐波中出现峰值,噪音则相对比较平坦,即平坦度越高,噪音概率越高。
公式
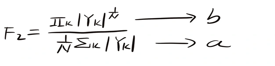
几何平均值/算数平均值
代码为加速计算实现过程如下,采用取Log操作将几何平均值的计算转为加法

代码如下:
为了使特征差异不明显,对结果数据进行了取历史数据的平滑操作
void WebRtcNs_ComputeSpectralFlatness(NSinst_t* inst, float* magnIn) { int i; int shiftLP = 1; //option to remove first bin(s) from spectral measures float avgSpectralFlatnessNum, avgSpectralFlatnessDen, spectralTmp; // comute spectral measures // for flatness 跳过第一个频点,即直流频点Den是denominator(分母)的缩写,avgSpectralFlatnessDen是上述公式分母计算用到的 avgSpectralFlatnessNum = 0.0; avgSpectralFlatnessDen = inst->sumMagn; for (i = 0; i < shiftLP; i++) { avgSpectralFlatnessDen -= magnIn[i]; } // compute log of ratio of the geometric to arithmetic mean: check for log(0) case //TVAG是time-average的缩写,对于能量出现异常的处理。利用前一次平坦度直接取平均返回。 ?? //修正:将本次结果处理为0后返回 for (i = shiftLP; i < inst->magnLen; i++) { if (magnIn[i] > 0.0) { avgSpectralFlatnessNum += (float)log(magnIn[i]); } else { inst->featureData[0] -= SPECT_FL_TAVG * inst->featureData[0]; return; } } //normalize avgSpectralFlatnessDen = avgSpectralFlatnessDen / inst->magnLen; avgSpectralFlatnessNum = avgSpectralFlatnessNum / inst->magnLen; //ratio and inverse log: check for case of log(0) spectralTmp = (float)exp(avgSpectralFlatnessNum) / avgSpectralFlatnessDen; //time-avg update of spectral flatness feature inst->featureData[0] += SPECT_FL_TAVG * (spectralTmp - inst->featureData[0]); // done with flatness feature }
4)噪声初步估计
中心思想:采用分位数估计法
分位数估计的基本思想:通过选择数列中的特定值来进行类别划分
假设噪声在整个频谱中属于能量值较低的部分,对能量值进行排序后取较小的部分
为了方便计算采用对数分位数估计法。
噪声估计过程如下:
调用一次处理函数算一帧,代码中用blockInd标记

分位数估计过程如下:

代码实现过程如下:
对原始能量值取对数,进行对数分位数估计,lquantile存储计算的对数结果。
density为概率密度, 用来更新系数delta
基本思想:设定log(噪声)初始化为8.0 (log(mag)频谱最大值为10),设定0.3的概率密度,对lquantile进行加操作更新,
当大于原始频谱的时候则进行减操作更新,当估计与原始频谱值差距减小的时候则增加概率密度,减少每次对lq的删改操作。
使lq无限逼近原始频谱。
void WebRtcNs_NoiseEstimation(NSinst_t* inst, float* magn, float* noise) { int i, s, offset; float lmagn[HALF_ANAL_BLOCKL], delta; //updates帧计数 if (inst->updates < END_STARTUP_LONG) { inst->updates++; } for (i = 0; i < inst->magnLen; i++) { lmagn[i] = (float)log(magn[i]); } // loop over simultaneous estimates 三阶段估计 计算三次 for (s = 0; s < SIMULT; s++) { offset = s * inst->magnLen; // newquantest(...) for (i = 0; i < inst->magnLen; i++) { // compute delta if (inst->density[offset + i] > 1.0) { delta = FACTOR * (float)1.0 / inst->density[offset + i]; } else { delta = FACTOR; } // update log quantile estimate 自适应中位数估计 if (lmagn[i] > inst->lquantile[offset + i]) { inst->lquantile[offset + i] += QUANTILE * delta / (float)(inst->counter[s] + 1); } else { inst->lquantile[offset + i] -= ((float)1.0 - QUANTILE) * delta / (float)(inst->counter[s] + 1); } // update density estimate if (fabs(lmagn[i] - inst->lquantile[offset + i]) < WIDTH) { inst->density[offset + i] = ((float)inst->counter[s] * inst->density[offset + i] + (float)1.0 / ((float)2.0 * WIDTH)) / (float)(inst->counter[s] + 1); } } // end loop over magnitude spectrum //200帧以上的处理方法 if (inst->counter[s] >= END_STARTUP_LONG) { inst->counter[s] = 0; if (inst->updates >= END_STARTUP_LONG) { for (i = 0; i < inst->magnLen; i++) { inst->quantile[i] = (float)exp(inst->lquantile[offset + i]); } } } inst->counter[s]++; } // end loop over simultaneous estimates // Sequentially update the noise during startup //200帧以内的处理方法 每次更新 if (inst->updates < END_STARTUP_LONG) { // Use the last "s" to get noise during startup that differ from zero. for (i = 0; i < inst->magnLen; i++) { inst->quantile[i] = (float)exp(inst->lquantile[offset + i]); } } for (i = 0; i < inst->magnLen; i++) { noise[i] = inst->quantile[i]; } }
代码实现过程

前200帧时每次更新lq,之后当差距为67的counter中有一个满足200则更新(counter到达200后置零)。
前50帧的模型叠加
计算方法为将分位数估计的噪声与模型估计的噪声进行加权平均
代码如下:
if (inst->blockInd < END_STARTUP_SHORT) { // Estimate White noise 总能量平均值 inst->whiteNoiseLevel += sumMagn / ((float)inst->magnLen) * inst->overdrive; // Estimate Pink noise parameters tmpFloat1 = sum_log_i_square * ((float)(inst->magnLen - kStartBand)); tmpFloat1 -= (sum_log_i * sum_log_i); tmpFloat2 = (sum_log_i_square * sum_log_magn - sum_log_i * sum_log_i_log_magn); tmpFloat3 = tmpFloat2 / tmpFloat1; // Constrain the estimated spectrum to be positive if (tmpFloat3 < 0.0f) { tmpFloat3 = 0.0f; } inst->pinkNoiseNumerator += tmpFloat3; tmpFloat2 = (sum_log_i * sum_log_magn); tmpFloat2 -= ((float)(inst->magnLen - kStartBand)) * sum_log_i_log_magn; tmpFloat3 = tmpFloat2 / tmpFloat1; // Constrain the pink noise power to be in the interval [0, 1]; if (tmpFloat3 < 0.0f) { tmpFloat3 = 0.0f; } if (tmpFloat3 > 1.0f) { tmpFloat3 = 1.0f; } inst->pinkNoiseExp += tmpFloat3; // Calculate frequency independent parts of parametric noise estimate. if (inst->pinkNoiseExp == 0.0f) { // Use white noise estimate parametric_noise = inst->whiteNoiseLevel; } else { // Use pink noise estimate parametric_num = exp(inst->pinkNoiseNumerator / (float)(inst->blockInd + 1)); parametric_num *= (float)(inst->blockInd + 1); parametric_exp = inst->pinkNoiseExp / (float)(inst->blockInd + 1); parametric_noise = parametric_num / pow((float)kStartBand, parametric_exp); } for (i = 0; i < inst->magnLen; i++) { // Estimate the background noise using the white and pink noise parameters if ((inst->pinkNoiseExp > 0.0f) && (i >= kStartBand)) { // Use pink noise estimate parametric_noise = parametric_num / pow((float)i, parametric_exp); } theFilterTmp[i] = (inst->initMagnEst[i] - inst->overdrive * parametric_noise); theFilterTmp[i] /= (inst->initMagnEst[i] + (float)0.0001); // Weight quantile noise with modeled noise noise[i] *= (inst->blockInd); tmpFloat2 = parametric_noise * (END_STARTUP_SHORT - inst->blockInd); noise[i] += (tmpFloat2 / (float)(inst->blockInd + 1)); noise[i] /= END_STARTUP_SHORT; } }
代码推导过程如下
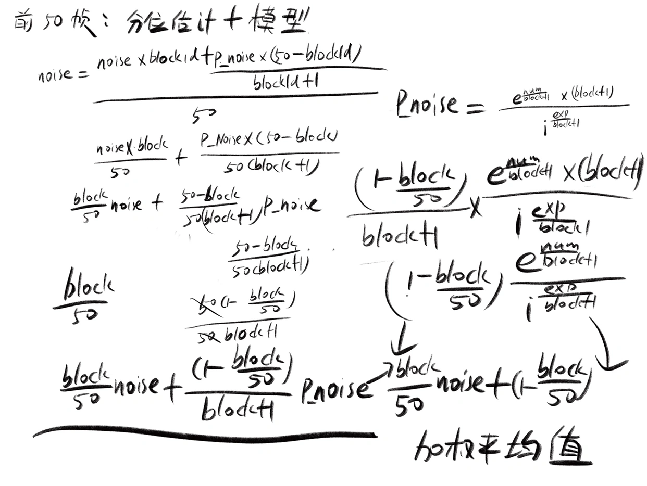
上图与下图对应关系
num为pinkNoiseNumerator
exp为pinkNoiseExp

上图的noise是分位数估计值,p_noise是模型估计值生成逐步衰减的粉红噪声模型,前50帧估计中随着帧数的增大 分位数估计占比逐渐明显
5)snr初步估计
通过上面计算的noise进行初步snr(sound noise ratio)估计
生成先验snr和后验snr
由于声音信号为线性关系,存在Y = N+S(Y:原始信号 N:噪声信号 S:语音信号)
先验snr在应用过程中采用上一帧的先验与本次的后验平滑值
关系和表示如下

代码如下
for (i = 0; i < inst->magnLen; i++) { // post snr snrLocPost[i] = (float)0.0; if (magn[i] > noise[i]) { snrLocPost[i] = magn[i] / (noise[i] + (float)0.0001) - (float)1.0; } // previous post snr // previous estimate: based on previous frame with gain filter previousEstimateStsa[i] = inst->magnPrev[i] / (inst->noisePrev[i] + (float)0.0001) * (inst->smooth[i]); // DD estimate is sum of two terms: current estimate and previous estimate // directed decision update of snrPrior snrLocPrior[i] = DD_PR_SNR * previousEstimateStsa[i] + ((float)1.0 - DD_PR_SNR)* snrLocPost[i]; // post and prior snr needed for step 2 } // end of loop over freqs
6)差异度计算
差异度为特征集中的其中一个
假设噪声频谱比较平坦,对应的差异度较低,用来衡量噪声的可能性
代码如下:
void WebRtcNs_ComputeSpectralDifference(NSinst_t* inst, float* magnIn) { // avgDiffNormMagn = var(magnIn) - cov(magnIn, magnAvgPause)^2 / var(magnAvgPause) int i; float avgPause, avgMagn, covMagnPause, varPause, varMagn, avgDiffNormMagn; avgPause = 0.0; avgMagn = inst->sumMagn; // compute average quantities for (i = 0; i < inst->magnLen; i++) { //conservative smooth noise spectrum from pause frames avgPause += inst->magnAvgPause[i]; } avgPause = avgPause / ((float)inst->magnLen); avgMagn = avgMagn / ((float)inst->magnLen); covMagnPause = 0.0; varPause = 0.0; varMagn = 0.0; // compute variance and covariance quantities //covMagnPause 协方差 varPause varMagn 各自的方差 for (i = 0; i < inst->magnLen; i++) { covMagnPause += (magnIn[i] - avgMagn) * (inst->magnAvgPause[i] - avgPause); varPause += (inst->magnAvgPause[i] - avgPause) * (inst->magnAvgPause[i] - avgPause); varMagn += (magnIn[i] - avgMagn) * (magnIn[i] - avgMagn); } covMagnPause = covMagnPause / ((float)inst->magnLen); varPause = varPause / ((float)inst->magnLen); varMagn = varMagn / ((float)inst->magnLen); // update of average magnitude spectrum inst->featureData[6] += inst->signalEnergy; //通过决定系数计算差异性 avgDiffNormMagn = varMagn - (covMagnPause * covMagnPause) / (varPause + (float)0.0001); // normalize and compute time-avg update of difference feature avgDiffNormMagn = (float)(avgDiffNormMagn / (inst->featureData[5] + (float)0.0001)); inst->featureData[4] += SPECT_DIFF_TAVG * (avgDiffNormMagn - inst->featureData[4]); }
代码对 magnAvgPause和MagIn进行了联合计算,MagIn为原始频谱 magnAvgPause为在声音概率较低的时候进行更新的参数
//语音概率较小 更新magnAvgPause if (probSpeech < PROB_RANGE) { inst->magnAvgPause[i] += GAMMA_PAUSE * (magn[i] - inst->magnAvgPause[i]); }
代码公式推导如下
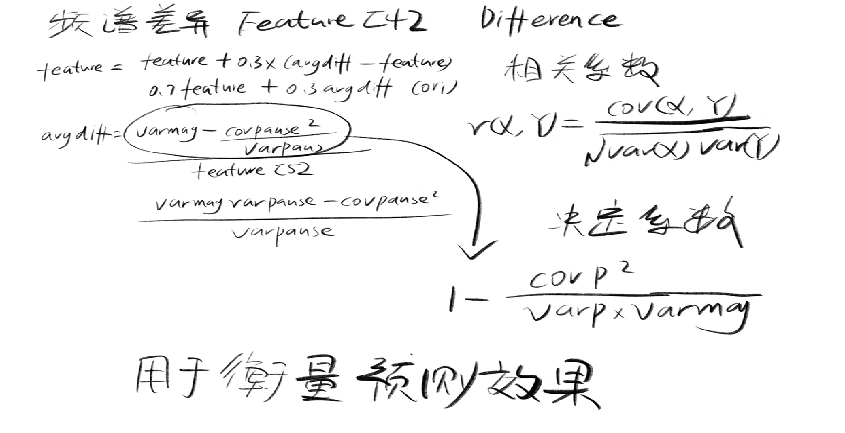
代码中分别计算了两个变量的方差和协方差,从公式可以看出是决定系数的计算方法
决定系数介绍:在上面的线性回归过程中用来衡量数据的拟合程度,(类似的相关系数用来衡量非回归场景下的拟合程度)。
7)特征值筛选与权重计算
过程如下:

代码如下:
(flag=0)500帧内对特征值(lrt均值,平坦度,差异度)进行直方图分布计算(即将特征值(feature)除以某个特定的参数(bin_size),就能得到声音频谱的整个特征值在某个固定范围内的分布情况(x轴:i))
i = feature/bin_size ==> feature = bin_size*i
(flag=1)达到500帧后对特征值进行收敛和筛选
处理过程就是首先对lrt特征进行起伏系数的计算以及值的限制
对平坦度和差异度两个系数提取最大出现次数对应的feature和feature数量,通过这个数据来判断这两个feature是否使用
lrt为必须使用的特征
得到三个特征的权重
void WebRtcNs_FeatureParameterExtraction(NSinst_t* inst, int flag) { int i, useFeatureSpecFlat, useFeatureSpecDiff, numHistLrt; int maxPeak1, maxPeak2; int weightPeak1SpecFlat, weightPeak2SpecFlat, weightPeak1SpecDiff, weightPeak2SpecDiff; float binMid, featureSum; float posPeak1SpecFlat, posPeak2SpecFlat, posPeak1SpecDiff, posPeak2SpecDiff; float fluctLrt, avgHistLrt, avgSquareHistLrt, avgHistLrtCompl; //3 features: lrt, flatness, difference //lrt_feature = inst->featureData[3]; //flat_feature = inst->featureData[0]; //diff_feature = inst->featureData[4]; //update histograms if (flag == 0) { // LRT if ((inst->featureData[3] < HIST_PAR_EST * inst->featureExtractionParams.binSizeLrt) && (inst->featureData[3] >= 0.0)) { i = (int)(inst->featureData[3] / inst->featureExtractionParams.binSizeLrt); inst->histLrt[i]++; } // Spectral flatness if ((inst->featureData[0] < HIST_PAR_EST * inst->featureExtractionParams.binSizeSpecFlat) && (inst->featureData[0] >= 0.0)) { i = (int)(inst->featureData[0] / inst->featureExtractionParams.binSizeSpecFlat); inst->histSpecFlat[i]++; } // Spectral difference if ((inst->featureData[4] < HIST_PAR_EST * inst->featureExtractionParams.binSizeSpecDiff) && (inst->featureData[4] >= 0.0)) { i = (int)(inst->featureData[4] / inst->featureExtractionParams.binSizeSpecDiff); inst->histSpecDiff[i]++; } } // extract parameters for speech/noise probability if (flag == 1) { //lrt feature: compute the average over inst->featureExtractionParams.rangeAvgHistLrt avgHistLrt = 0.0; avgHistLrtCompl = 0.0; avgSquareHistLrt = 0.0; numHistLrt = 0; for (i = 0; i < HIST_PAR_EST; i++) {
//由feature = i*bin_size 得出binMid=feature+0.5*0.1 即binMid约等于feature原值 hisLrt存储对应feature数量
binMid = ((float)i + (float)0.5) * inst->featureExtractionParams.binSizeLrt;
//即feature(lrt)<1的情况 binmid < 10(rangeAvfHistLrt:10)
if (binMid <= inst->featureExtractionParams.rangeAvgHistLrt) { avgHistLrt += inst->histLrt[i] * binMid;
numHistLrt += inst->histLrt[i]; } avgSquareHistLrt += inst->histLrt[i] * binMid * binMid; avgHistLrtCompl += inst->histLrt[i] * binMid; }
//类似lrt<1的情况下所有特征平均值 num存储特征总数量 if (numHistLrt > 0) { avgHistLrt = avgHistLrt / ((float)numHistLrt); }
//所有lrt下特征的平均值 此处分母用500 avgHistLrtCompl = avgHistLrtCompl / ((float)inst->modelUpdatePars[1]);
//特征平方的平均值 avgSquareHistLrt = avgSquareHistLrt / ((float)inst->modelUpdatePars[1]);
//起伏特征:所有特征平方平均值-特征小于1的情况平均值*所有特征平均值 fluctLrt = avgSquareHistLrt - avgHistLrt * avgHistLrtCompl; // get threshold for lrt feature: thresFluctLrt 0.05
//接下来就是系数的值域限制
if (fluctLrt < inst->featureExtractionParams.thresFluctLrt) { //very low fluct, so likely noise 起伏系数? inst->priorModelPars[0] = inst->featureExtractionParams.maxLrt; } else { inst->priorModelPars[0] = inst->featureExtractionParams.factor1ModelPars * avgHistLrt; // check if value is within min/max range if (inst->priorModelPars[0] < inst->featureExtractionParams.minLrt) { inst->priorModelPars[0] = inst->featureExtractionParams.minLrt; } if (inst->priorModelPars[0] > inst->featureExtractionParams.maxLrt) { inst->priorModelPars[0] = inst->featureExtractionParams.maxLrt; } } // done with lrt feature // // for spectral flatness and spectral difference: compute the main peaks of histogram maxPeak1 = 0; maxPeak2 = 0; posPeak1SpecFlat = 0.0; posPeak2SpecFlat = 0.0; weightPeak1SpecFlat = 0; weightPeak2SpecFlat = 0; // peaks for flatness 平整度最大值和次大值 for (i = 0; i < HIST_PAR_EST; i++) { binMid = ((float)i + (float)0.5) * inst->featureExtractionParams.binSizeSpecFlat; if (inst->histSpecFlat[i] > maxPeak1) { // Found new "first" peak maxPeak2 = maxPeak1; weightPeak2SpecFlat = weightPeak1SpecFlat; posPeak2SpecFlat = posPeak1SpecFlat; maxPeak1 = inst->histSpecFlat[i]; weightPeak1SpecFlat = inst->histSpecFlat[i]; posPeak1SpecFlat = binMid; } else if (inst->histSpecFlat[i] > maxPeak2) { // Found new "second" peak maxPeak2 = inst->histSpecFlat[i]; weightPeak2SpecFlat = inst->histSpecFlat[i]; posPeak2SpecFlat = binMid; } } //compute two peaks for spectral difference 差异度最大值和次大值 maxPeak1 = 0; maxPeak2 = 0; posPeak1SpecDiff = 0.0; posPeak2SpecDiff = 0.0; weightPeak1SpecDiff = 0; weightPeak2SpecDiff = 0; // peaks for spectral difference for (i = 0; i < HIST_PAR_EST; i++) { binMid = ((float)i + (float)0.5) * inst->featureExtractionParams.binSizeSpecDiff; if (inst->histSpecDiff[i] > maxPeak1) { // Found new "first" peak maxPeak2 = maxPeak1; weightPeak2SpecDiff = weightPeak1SpecDiff; posPeak2SpecDiff = posPeak1SpecDiff; maxPeak1 = inst->histSpecDiff[i]; weightPeak1SpecDiff = inst->histSpecDiff[i]; posPeak1SpecDiff = binMid; } else if (inst->histSpecDiff[i] > maxPeak2) { // Found new "second" peak maxPeak2 = inst->histSpecDiff[i]; weightPeak2SpecDiff = inst->histSpecDiff[i]; posPeak2SpecDiff = binMid; } } // for spectrum flatness feature useFeatureSpecFlat = 1; // merge the two peaks if they are close //inst->featureExtractionParams.limitPeakSpacingSpecFlat = 0.1 // inst->featureExtractionParams.limitPeakWeightsSpecFlat = (float)0.5 //平坦度 最大次大满足需求后叠加取均值 以及判断是否使用 if ((fabs(posPeak2SpecFlat - posPeak1SpecFlat) < inst->featureExtractionParams.limitPeakSpacingSpecFlat) && (weightPeak2SpecFlat > inst->featureExtractionParams.limitPeakWeightsSpecFlat * weightPeak1SpecFlat)) { weightPeak1SpecFlat += weightPeak2SpecFlat; posPeak1SpecFlat = (float)0.5 * (posPeak1SpecFlat + posPeak2SpecFlat); } //reject if weight of peaks is not large enough, or peak value too small if (weightPeak1SpecFlat < inst->featureExtractionParams.thresWeightSpecFlat || posPeak1SpecFlat < inst->featureExtractionParams.thresPosSpecFlat) { useFeatureSpecFlat = 0; } // if selected, get the threshold if (useFeatureSpecFlat == 1) { // compute the threshold inst->priorModelPars[1] = inst->featureExtractionParams.factor2ModelPars * posPeak1SpecFlat; //check if value is within min/max range 限制大小在:0.1-0.95 if (inst->priorModelPars[1] < inst->featureExtractionParams.minSpecFlat) { inst->priorModelPars[1] = inst->featureExtractionParams.minSpecFlat; } if (inst->priorModelPars[1] > inst->featureExtractionParams.maxSpecFlat) { inst->priorModelPars[1] = inst->featureExtractionParams.maxSpecFlat; } } // done with flatness feature // for template feature useFeatureSpecDiff = 1; // merge the two peaks if they are close //差异度 取极大次大值合并 判断是否使用 if ((fabs(posPeak2SpecDiff - posPeak1SpecDiff) < inst->featureExtractionParams.limitPeakSpacingSpecDiff) && (weightPeak2SpecDiff > inst->featureExtractionParams.limitPeakWeightsSpecDiff * weightPeak1SpecDiff)) { weightPeak1SpecDiff += weightPeak2SpecDiff; posPeak1SpecDiff = (float)0.5 * (posPeak1SpecDiff + posPeak2SpecDiff); } // get the threshold value inst->priorModelPars[3] = inst->featureExtractionParams.factor1ModelPars * posPeak1SpecDiff; //reject if weight of peaks is not large enough if (weightPeak1SpecDiff < inst->featureExtractionParams.thresWeightSpecDiff) { useFeatureSpecDiff = 0; } //check if value is within min/max range if (inst->priorModelPars[3] < inst->featureExtractionParams.minSpecDiff) { inst->priorModelPars[3] = inst->featureExtractionParams.minSpecDiff; } if (inst->priorModelPars[3] > inst->featureExtractionParams.maxSpecDiff) { inst->priorModelPars[3] = inst->featureExtractionParams.maxSpecDiff; } // done with spectral difference feature // don't use template feature if fluctuation of lrt feature is very low: // most likely just noise state if (fluctLrt < inst->featureExtractionParams.thresFluctLrt) { useFeatureSpecDiff = 0; } // select the weights between the features // inst->priorModelPars[4] is weight for lrt: always selected // inst->priorModelPars[5] is weight for spectral flatness // inst->priorModelPars[6] is weight for spectral difference featureSum = (float)(1 + useFeatureSpecFlat + useFeatureSpecDiff); inst->priorModelPars[4] = (float)1.0 / featureSum; inst->priorModelPars[5] = ((float)useFeatureSpecFlat) / featureSum; inst->priorModelPars[6] = ((float)useFeatureSpecDiff) / featureSum; // set hists to zero for next update if (inst->modelUpdatePars[0] >= 1) { for (i = 0; i < HIST_PAR_EST; i++) { inst->histLrt[i] = 0; inst->histSpecFlat[i] = 0; inst->histSpecDiff[i] = 0; } } } // end of flag == 1 }
得到以下参数

8)语音/噪音概率估计
主要是计算在带噪语音和特征条件下是语音的概率为
P(H1 | YF) (H1:语音状态 Y:原始信号 F:特征集)
利用的原理如下:
1)贝叶斯公式:假设A和B为独立分布的时间,存在P(AB)=p(A|B)*P(B) (同时发生AB的概率等于B的发生概率*B发生条件下A发生的概率)在这里假设噪音跟语音是独立分布的两种事件
2)语音的线性关系:设定H0为噪音 H1为语音 Y为原始信号 存在 P(H0|YF) + P(H1|YF) = 1 , P(H0|Y) + P(H1|Y) =1
推导过程如下

P(H0|F) = 1-P(H1|F)
根据推导出的公式得出求出以下两个值 就可以计算出P(H1|YF)

简化为下面的公式

求解似然比系数采用联合高斯概率密度分布的操作
高斯概率密度介绍如下:

这里假设噪音和语音符合均值为0的概率密度分布

对应似然比计算如下

代码如下:
void WebRtcNs_SpeechNoiseProb(NSinst_t* inst, float* probSpeechFinal, float* snrLocPrior, float* snrLocPost) { int i, sgnMap; float invLrt, gainPrior, indPrior; float logLrtTimeAvgKsum, besselTmp; float indicator0, indicator1, indicator2; float tmpFloat1, tmpFloat2; float weightIndPrior0, weightIndPrior1, weightIndPrior2; float threshPrior0, threshPrior1, threshPrior2; float widthPrior, widthPrior0, widthPrior1, widthPrior2; widthPrior0 = WIDTH_PR_MAP; widthPrior1 = (float)2.0 * WIDTH_PR_MAP; //width for pause region: // lower range, so increase width in tanh map widthPrior2 = (float)2.0 * WIDTH_PR_MAP; //for spectral-difference measure //threshold parameters for features threshPrior0 = inst->priorModelPars[0]; threshPrior1 = inst->priorModelPars[1]; threshPrior2 = inst->priorModelPars[3]; //sign for flatness feature sgnMap = (int)(inst->priorModelPars[2]); //weight parameters for features weightIndPrior0 = inst->priorModelPars[4]; weightIndPrior1 = inst->priorModelPars[5]; weightIndPrior2 = inst->priorModelPars[6]; // compute feature based on average LR factor // this is the average over all frequencies of the smooth log lrt //通过似然比与高斯密度概率函数求解lrt均值 logLrtTimeAvgKsum = 0.0; for (i = 0; i < inst->magnLen; i++) { tmpFloat1 = (float)1.0 + (float)2.0 * snrLocPrior[i]; tmpFloat2 = (float)2.0 * snrLocPrior[i] / (tmpFloat1 + (float)0.0001); besselTmp = (snrLocPost[i] + (float)1.0) * tmpFloat2; inst->logLrtTimeAvg[i] += LRT_TAVG * (besselTmp - (float)log(tmpFloat1)- inst->logLrtTimeAvg[i]); logLrtTimeAvgKsum += inst->logLrtTimeAvg[i]; } //以上计算得到极大似然比 //取极大似然比的平均值 logLrtTimeAvgKsum = (float)logLrtTimeAvgKsum / (inst->magnLen); inst->featureData[3] = logLrtTimeAvgKsum;
接下来求特征条件下的语音概率
用到了上面特征筛选中计算出的权重与特征值
代码如下
这里采用了取反正切sigmod函数用来限制feature的值域(反正切的值域为[-1,1])
方法如下:

代码如下
//以下操作对三个特征值进行sigmod函数变换 将值控制在同一范围内 // sigmod函数采用tanh(单调增 值域【-1,1】 代码中控制在[-0.5,0.5]中间) // average lrt feature widthPrior = widthPrior0; //use larger width in tanh map for pause regions if (logLrtTimeAvgKsum < threshPrior0) { widthPrior = widthPrior1; } // compute indicator function: sigmoid map indicator0 = (float)0.5 * ((float)tanh(widthPrior * (logLrtTimeAvgKsum - threshPrior0)) + (float)1.0); //spectral flatness feature tmpFloat1 = inst->featureData[0]; widthPrior = widthPrior0; //use larger width in tanh map for pause regions 使用flatnesss if (sgnMap == 1 && (tmpFloat1 > threshPrior1)) { widthPrior = widthPrior1; } //feature0>feature1 不使用flatness if (sgnMap == -1 && (tmpFloat1 < threshPrior1)) { widthPrior = widthPrior1; } // compute indicator function: sigmoid map indicator1 = (float)0.5 * ((float)tanh((float)sgnMap * widthPrior * (threshPrior1 - tmpFloat1)) + (float)1.0); //for template spectrum-difference tmpFloat1 = inst->featureData[4]; widthPrior = widthPrior0; //use larger width in tanh map for pause regions if (tmpFloat1 < threshPrior2) { widthPrior = widthPrior2; } // compute indicator function: sigmoid map indicator2 = (float)0.5 * ((float)tanh(widthPrior * (tmpFloat1 - threshPrior2)) + (float)1.0); //combine the indicator function with the feature weights indPrior = weightIndPrior0 * indicator0 + weightIndPrior1 * indicator1 + weightIndPrior2 * indicator2; // done with computing indicator function //compute the prior probability inst->priorSpeechProb += PRIOR_UPDATE * (indPrior - inst->priorSpeechProb);
接下来取计算好的两个概率计算最终的语音概率 得到特征条件以及原始信号条件下的语音概率
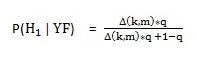
//final speech probability: combine prior model with LR factor: gainPrior = ((float)1.0 - inst->priorSpeechProb) / (inst->priorSpeechProb + (float)0.0001); for (i = 0; i < inst->magnLen; i++) { invLrt = (float)exp(-inst->logLrtTimeAvg[i]); invLrt = (float)gainPrior * invLrt; probSpeechFinal[i] = (float)1.0 / ((float)1.0 + invLrt); }
9)根据语音概率的结果更新之前估计的噪音(反馈)
由P(H0|YF) = 1-P(H1|YF)得出
代码如下:计算类似上面噪声初始化估计的过程
//更新完语音概率后 更新noise gammaNoiseTmp = NOISE_UPDATE; for (i = 0; i < inst->magnLen; i++) { probSpeech = probSpeechFinal[i]; probNonSpeech = (float)1.0 - probSpeech; // temporary noise update: // use it for speech frames if update value is less than previous noiseUpdateTmp = gammaNoiseTmp * inst->noisePrev[i] + ((float)1.0 - gammaNoiseTmp) * (probNonSpeech * magn[i] + probSpeech * inst->noisePrev[i]); // // time-constant based on speech/noise state gammaNoiseOld = gammaNoiseTmp; gammaNoiseTmp = NOISE_UPDATE; // increase gamma (i.e., less noise update) for frame likely to be speech //语音概率较大 减少本帧噪音的占比 if (probSpeech > PROB_RANGE) { gammaNoiseTmp = SPEECH_UPDATE; } // conservative noise update //语音概率较小 更新magnAvgPause if (probSpeech < PROB_RANGE) { inst->magnAvgPause[i] += GAMMA_PAUSE * (magn[i] - inst->magnAvgPause[i]); } // noise update if (gammaNoiseTmp == gammaNoiseOld) { noise[i] = noiseUpdateTmp; } else { noise[i] = gammaNoiseTmp * inst->noisePrev[i] + ((float)1.0 - gammaNoiseTmp) * (probNonSpeech * magn[i] + probSpeech * inst->noisePrev[i]); // allow for noise update downwards: // if noise update decreases the noise, it is safe, so allow it to happen if (noiseUpdateTmp < noise[i]) { noise[i] = noiseUpdateTmp; } } } // end of freq loop // done with step 2: noise update // // STEP 3: compute dd update of prior snr and post snr based on new noise estimate //filter:比重 for (i = 0; i < inst->magnLen; i++) { // post and prior snr currentEstimateStsa = (float)0.0; if (magn[i] > noise[i]) { currentEstimateStsa = magn[i] / (noise[i] + (float)0.0001) - (float)1.0; } // DD estimate is sume of two terms: current estimate and previous estimate // directed decision update of snrPrior snrPrior = DD_PR_SNR * previousEstimateStsa[i] + ((float)1.0 - DD_PR_SNR) * currentEstimateStsa; // gain filter tmpFloat1 = inst->overdrive + snrPrior; tmpFloat2 = (float)snrPrior / tmpFloat1; theFilter[i] = (float)tmpFloat2; } // end of loop over freqs // done with step3
10)维纳滤波
维纳滤波介绍如下:
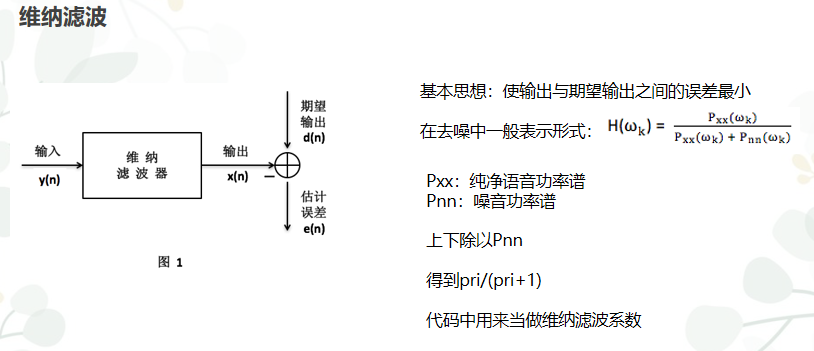
由于上面已经计算出Pri即先验概率的值 所以可以直接用来求最终的结果
期望信号 = 原始信号*维纳系数
维纳系数计算的代码如下: override设置为1
for (i = 0; i < inst->magnLen; i++) { // post and prior snr currentEstimateStsa = (float)0.0; if (magn[i] > noise[i]) { currentEstimateStsa = magn[i] / (noise[i] + (float)0.0001) - (float)1.0; } // DD estimate is sume of two terms: current estimate and previous estimate // directed decision update of snrPrior snrPrior = DD_PR_SNR * previousEstimateStsa[i] + ((float)1.0 - DD_PR_SNR) * currentEstimateStsa; // gain filter tmpFloat1 = inst->overdrive + snrPrior; tmpFloat2 = (float)snrPrior / tmpFloat1; theFilter[i] = (float)tmpFloat2; } // end of loop over freqs // done with step3
通过维纳滤波系数以及原始信号计算语音信号 代码如下:
for (i = 0; i < inst->magnLen; i++) { // flooring bottom if (theFilter[i] < inst->denoiseBound) { theFilter[i] = inst->denoiseBound; } // flooring top if (theFilter[i] > (float)1.0) { theFilter[i] = 1.0; } if (inst->blockInd < END_STARTUP_SHORT) { // flooring bottom if (theFilterTmp[i] < inst->denoiseBound) { theFilterTmp[i] = inst->denoiseBound; } // flooring top if (theFilterTmp[i] > (float)1.0) { theFilterTmp[i] = 1.0; } // Weight the two suppression filters theFilter[i] *= (inst->blockInd); theFilterTmp[i] *= (END_STARTUP_SHORT - inst->blockInd); theFilter[i] += theFilterTmp[i]; theFilter[i] /= (END_STARTUP_SHORT); } // smoothing #ifdef PROCESS_FLOW_0 inst->smooth[i] *= SMOOTH; // value set to 0.7 in define.h file inst->smooth[i] += ((float)1.0 - SMOOTH) * theFilter[i]; #else inst->smooth[i] = theFilter[i]; #endif real[i] *= inst->smooth[i]; imag[i] *= inst->smooth[i]; }
将计算好的数据存储到prev中用于下次的计算迭代平滑
将数据进行一些收敛判断,进行反傅里叶变换,就得出最终的语音信号
for (i = 0; i < inst->magnLen; i++) { inst->noisePrev[i] = noise[i]; inst->magnPrev[i] = magn[i]; } // back to time domain winData[0] = real[0]; winData[1] = real[inst->magnLen - 1]; for (i = 1; i < inst->magnLen - 1; i++) { winData[2 * i] = real[i]; winData[2 * i + 1] = imag[i]; } //反傅里叶变换 幅度谱生成原始数据 WebRtc_rdft(inst->anaLen, -1, winData, inst->ip, inst->wfft);
参考:书籍《实时语音处理实践指南》
blog:https://blog.csdn.net/david_tym?type=blog

 浙公网安备 33010602011771号
浙公网安备 33010602011771号