
使用相似矩阵对伴奏和人声进行划分 MUSIC/VOICE SEPARATION USING THE SIMILARITY MATRIX
-----原文:MUSIC/VOICE SEPARATION USING THE SIMILARITY MATRIX by Zafar RAFII
In this work, we generalize the repetition-based source
separation approach to handle cases where repetitions also
happen intermittently or without a fixed period. Instead of
looking for periodicities, the proposed method identifies
repeating elements by looking for similarities, by means
of a similarity matrix. Once identified, median filtering
is then performed on the repeating elements to calculate a
repeating spectrogram model for the background.
A time frequency mask can finally be derived to
extract the repeating patterns (see Section 3).
This allows the processing of music pieces with fast-varying repeating
structures and isolated repeating elements, without the need to identify
periods of the repeating structure beforehand.
foreground:人声
background:伴奏
方法1:
Recently, a relatively simple approach has also been
proposed for music/voice separation. The method is based
on a median filtering of the mixture spectrogram at different frequency resolutions,
in such a way that the harmonic and percussive elements of the accompaniment can be smoothed out,
leaving out the vocals .
在不同频率分辨率下对混合频谱图进行中值滤波,以使伴奏的谐波和打击元素平滑,从而消除人声。
方法2:
REpeating Pattern Extraction Technique (REPET)
Another recent and promising approach is to apply
analysis of the repeating structure in the audio
to extract the repeating musical background from the non-repeating vocal foreground.
分析重复结构,从非重复的声音中提取重复的背景用于过滤人声
本文采用第二种方法
相似矩阵:
二维表示,每个点(a,b)测量a和b之间 的相似性。
给定一个单通道信号x,计算x的短时傅里叶变换X
使用N个样本长度的半重叠汉明窗(half overlapping hamming windows)
通过取X元素的绝对值,我们可以推导出幅度谱图V
丢弃对称部分,保持直流分量(DC component)
通过求V和V的转置矩阵的乘积得到相似矩阵S
通过欧几里得范数对V的列进行归一化
相似矩阵S中的每个点(ja,jb)代表幅度谱图中时间帧Vja和jb的余弦相似度
计算公式如下
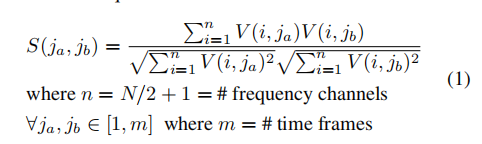
重复元素:
一旦计算出相似矩阵S,我们就用他来识别V中的重复元素。
对于V中的所有时间帧j 我们寻找跟跟定的j最相似的另一个时间帧j ,然后将他们保存在Jj的向量中,
一个较合理的假设是假定不重复的人声与重复的伴奏有很大的差异
对音乐中的人声来说,相似矩阵提供的重复元素应该就是底层具有重复结构的伴奏。
相似矩阵的使用是我们识别非周期性发生的重复元素。
我们在算法中增加了下面所示的约束参数,为了限制帧j的重复帧的数量。
我们定义k,代表允许重复帧数量的最大值。定义t,代表重复帧和给定帧(t[0,1])之间相似度的最小阈值,
连续帧可以表示出很高的相似度。帧的时长和音乐元素的时长无关(所以不用展示新的相同结构元素的入口?????)。
我们又定义d,表示两个连续重复帧之间具有足够的相似元素认定相似之间的最小(时间)距离。
重复模型
一旦确定了V中所有帧j的重复元素,
我们就用他们构造一个重复的背景音乐W,
对V中的所有j来说,我们通过重复帧中对应的中位值构造W中的对应帧j
对每个频段来说,W重复频谱计算如下所示
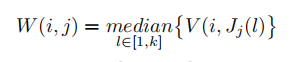
Jj = [j1...jk] 代表重复帧的下标
k是重复帧的中值

基本原理如下:
假设不重复的人声具有稀疏时频,底层背景音乐具有重复的时频。
时频桶
重复时频W
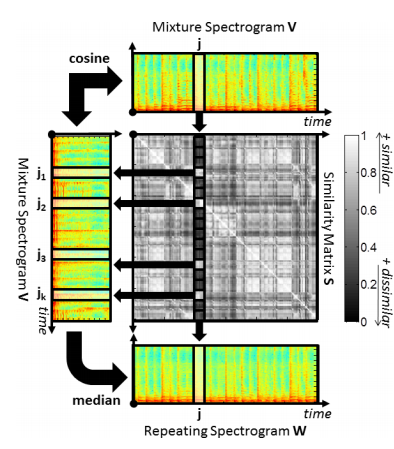
上图展示了W的推导过程,
(1)由混合频谱V通过余弦相似度计算出相似矩阵S,
(2)对V中的所有帧j来说,通过S识别出k个属于j的最大相似帧
(3)对每个重复的频道,通过k个相似帧推断出重复频谱W模型中的j帧
重复帧质检的微小差距将构成重复模式,并且被中位数捕捉。
由较大差距的重复帧组成的时频桶将构成不重复模式,并且被中位数剔除。
时频掩模
计算出W之后,我们通过它来推导一个时序掩模M。
首先我们需要创建一个针对背景音乐的精确的重复频谱模型W0。
通过对每个时频桶提取W和V之间的最小值,
我们假设非负混合频谱V是非负重复频谱W和非负不重复频谱的和V-W。
W中的时频桶最多可以有V中对应时频桶的一样的值。
即W<=V
对弈对每个时频桶用最小值函数
我们通过对W的转置矩阵的归一化对每个时频桶得出时频掩模M,
原理是时频桶可能会构成V中的重复模式将会接近1 并且对重复的背景音乐进行加权。
因此,在时频掩模中时频桶不太可能构成接近0值的V中的重复模式。
时频掩模计算如下图所示:

时频掩模M对称化应用于x的混合信号X的短时傅里叶变换(STFT)。
通过得出的STFT转换为时域得到最终的音乐信号。
通过从混合信号中减去音乐信号得到最终的人声信号。
评估
竞争方法和数据集:
基于相似矩阵给提出的方法贴上标签。
我们在14首全音轨流行音乐上比较了两种竞争力的分离方法。
第一种方法是原始REPET算法扩展,用于处理底层重复结构变化。
这种方法成为REPET+。
方法首先跟踪底层的节奏频谱图的重复结构,然后使用中值方法对重复背景音乐进行建模,
最终实现从混合频谱中利用时频掩模中提取出重复模式。
通过软视频掩模和高通滤波和100Hz的人声限制对REPET+的分离结果进行处理。
第二种竞争方法:
多通道中值滤波分离(MMFS),另一个最近提出的人声分离方法,是基于不同频率分辨率下对混合频谱图进行中值滤波,平滑伴奏和打击元素,忽略人声。
为了比较,使用高通滤波和100Hz的声音限制,对MMFS 的四个建议方法的分离结果进行对比。
将100Hz以上的人声去除(人声很少在100Hz以下出现)
评估结果方法:
BSS Eval toolbox(评估源数据和相应估计之间的分离)
Source-to-Distortion Ratio (SDR),
Sources-to Interferences Ratio (SIR),
and Sources-to-Artifacts Ratio(SAR)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号