
DOM操作
初识DOM操作
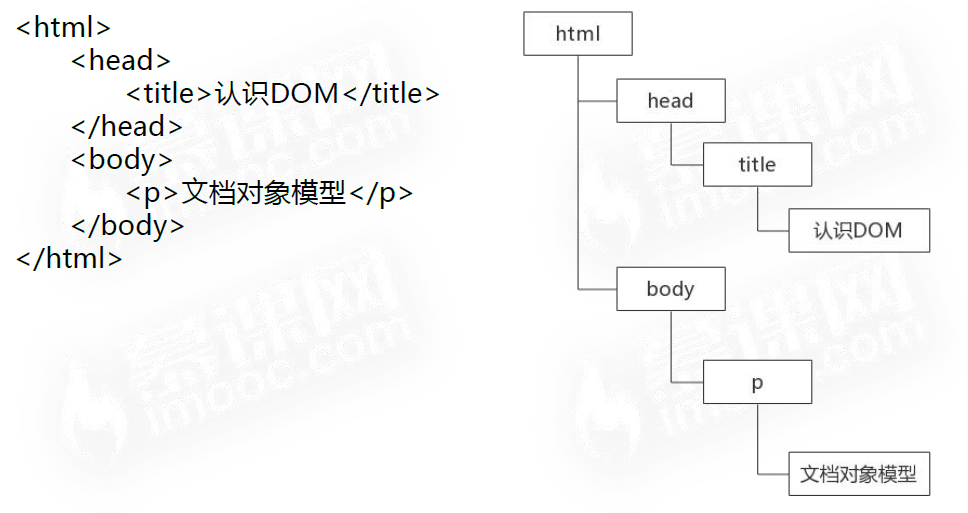
1 认识DOM
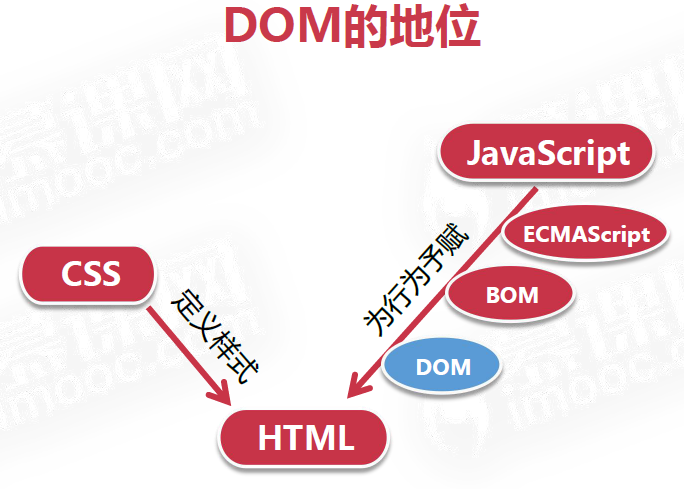


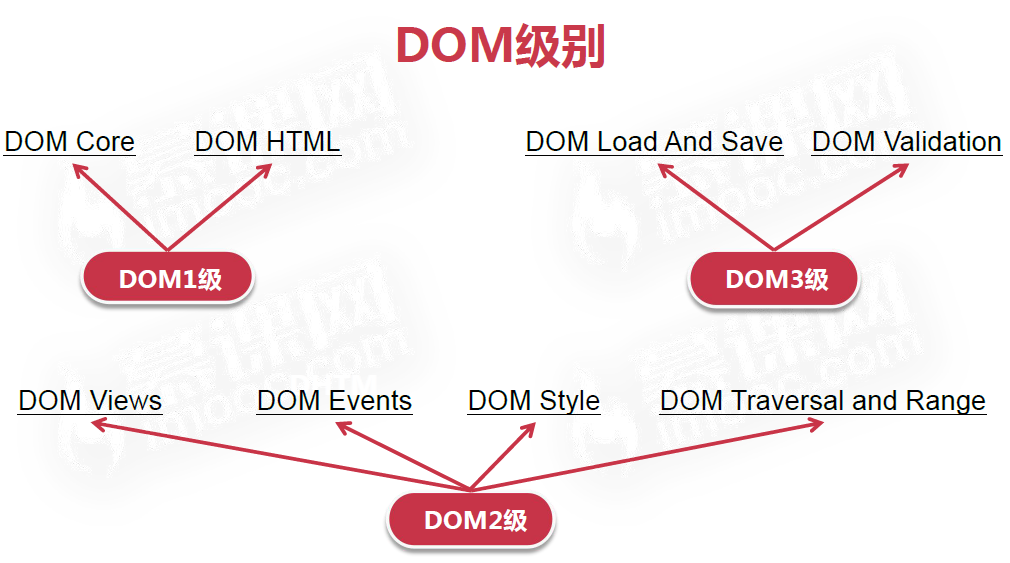
DOM1级:映射文档结构
DOM2级:视口、事件、CSS样式和遍历和范围
DOM3级:引入了以统一方式加载和保存文档的方法、验证文档的方法
DOM0级:实际上这个标准是不存在的,只是DOM历史坐标系中的一个参照点(IE最初支持的DHTML中的DOM)
2 文档类型
不同的领域采用不同类型的语言

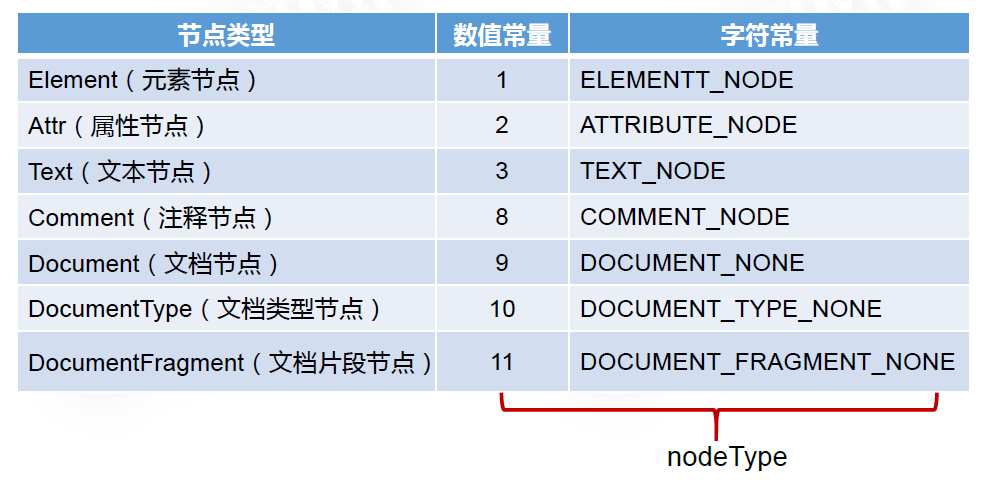
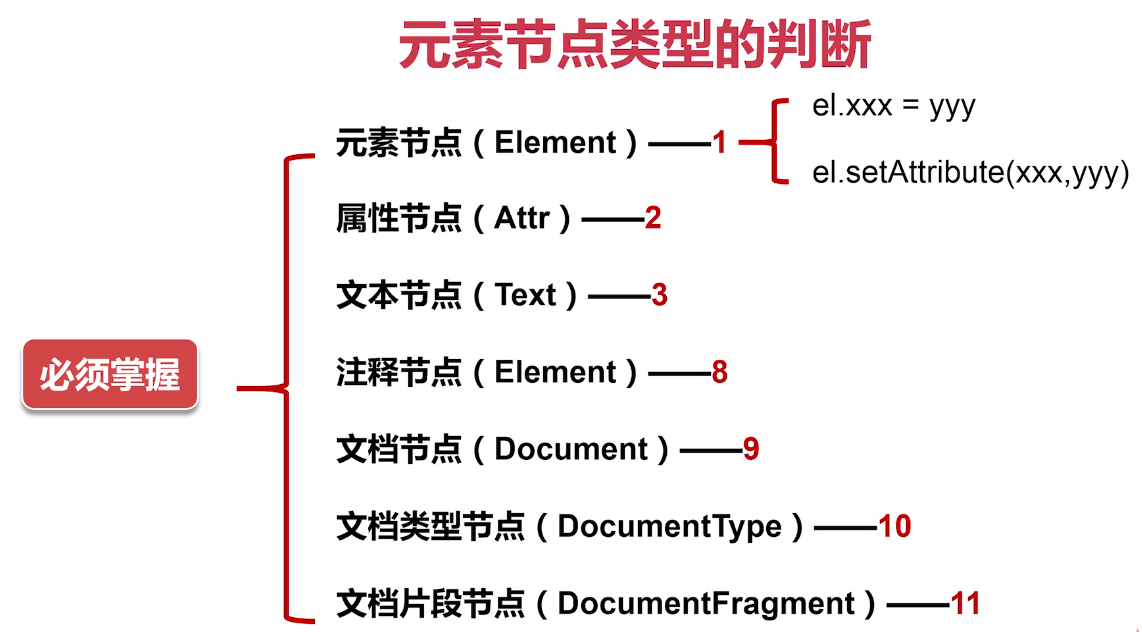
3 节点类型
一共十二种,常用以下七种
根元素是文档节点的子节点。文档节点是整个文档。
文档类型节点:doctype代码
文档片段节点:文档的一部分
理解:
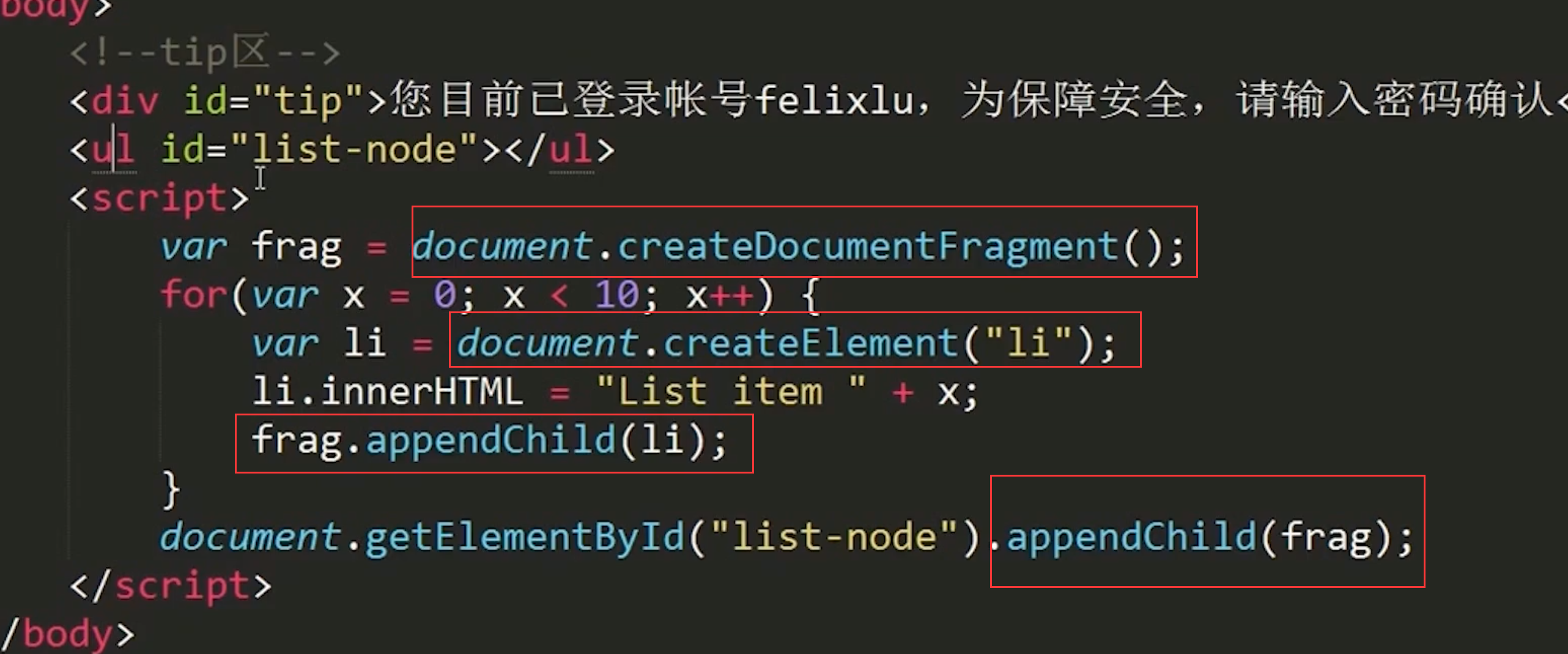
1、 document.createDocumentFragment()是创建一个新的空白的文档片段。
2、document.createElement() 方法通过指定名称创建一个元素
3、appendChild() 方法可向节点的子节点列表的末尾添加新的子节点。
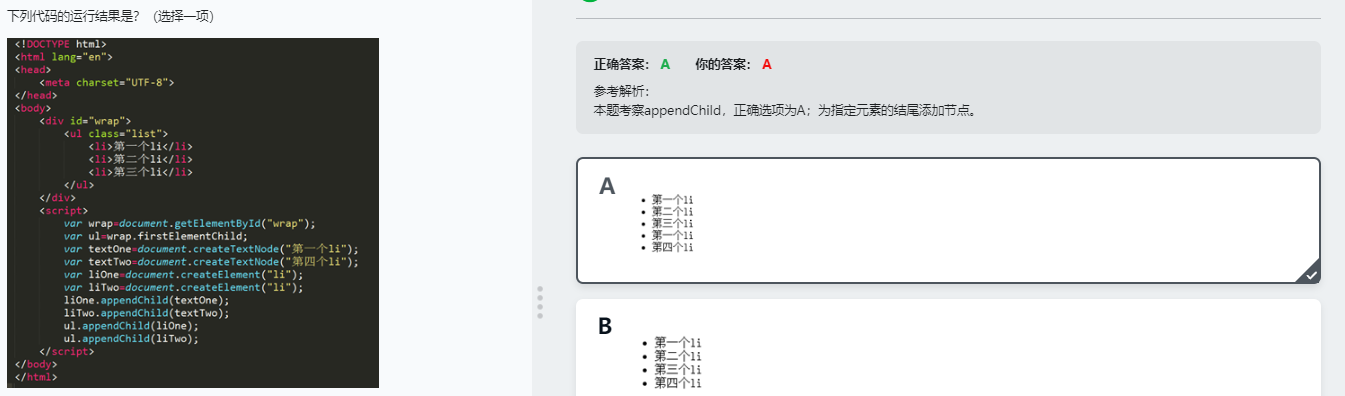
这段代码的意思是创建一个文档片段,通过遍历创建li元素,在li中添加内容,将li添加在文档片段中,然后再将文档片段添加到list-node元素中,这样页面中就会显示出来

另外文档片段是临时占位符,虽然通过appendChild方法将有li元素的文档片段添加在页面中,但是文档片段在element中不会显示,只有li。
4 nodeType
理解:
可以通过节点类型的字符常量来判断它是什么类型的节点。
1 <div id="container">这是一个元素节点</div> 2 <script> 3 var divNode = document.getElementById("container"); 4 if (divNode.nodeType == Node.ELEMENT_NODE){ 5 alert("Node is an element."); 6 } 7 </script>
IE浏览器没有内置NODE对象,会报错。
在IE浏览器中可以采用节点类型的数值常量来判断。
<div id="container">这是一个元素节点</div> <script> var divNode = document.getElementById("container"); if (divNode.nodeType == 1){ alert("Node is an element."); } </script>
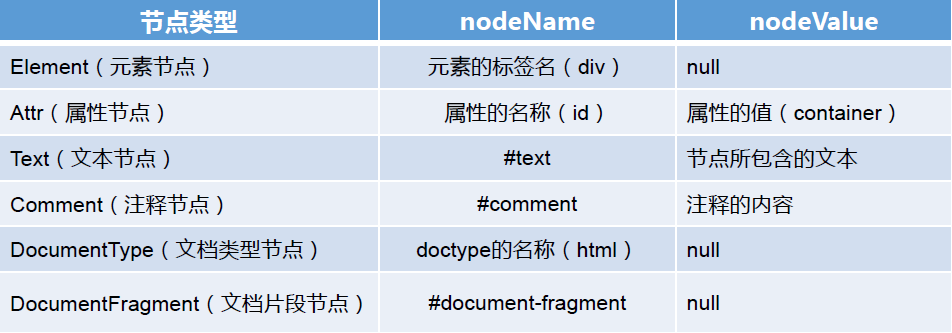
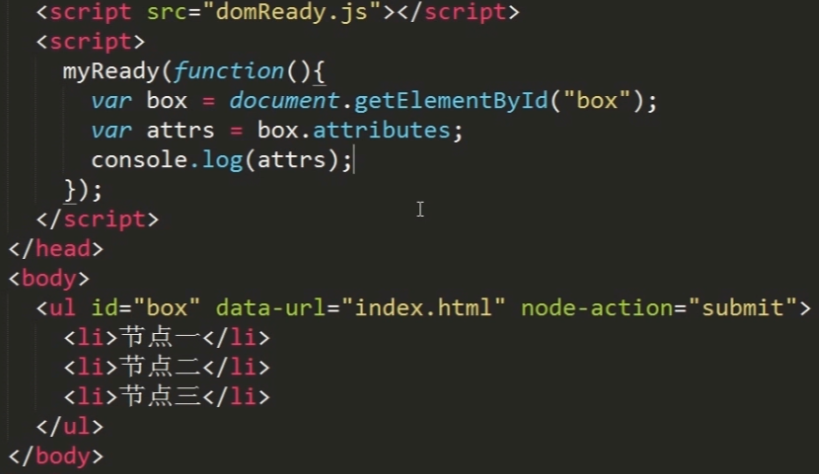
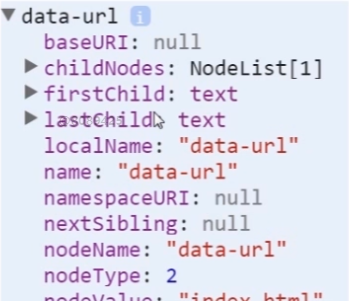
5 nodeName 和 nodeValue
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>nodeName,nodeValue</title> 6 </head> 7 <body> 8 <!--nodeName, nodeValue实验--> 9 <div id="container">这是一个元素节点</div> 10 <script> 11 var divNode = document.getElementById("container"); 12 console.log(divNode.nodeName + "/" + divNode.nodeValue); 13 var attrNode = divNode.attributes[0]; 14 console.log(attrNode.nodeName + "/" + attrNode.nodeValue); 15 var textNode = divNode.childNodes[0];//获取div中所有子元素 16 console.log(textNode.nodeName + "/" + textNode.nodeValue); 17 var commentNode = document.body.childNodes[1];//body的第一个节点是标签到注释之间的空白节点 18 console.log(commentNode.nodeName + "/" + commentNode.nodeValue); 19 console.log(document.doctype.nodeName + "/" + document.doctype.nodeValue); 20 var frag = document.createDocumentFragment(); 21 console.log(frag.nodeName + "/" + frag.nodeValue); 22 23 </script> 24 </body> 25 </html>
理解:
1、attributes 属性返回指定节点的属性集合,例如


2、childNodes 属性返回节点的子节点集合,例如


3、document.body.childNodes是获取body下的子节点,例如


4、document.doctype属性指向<!DOCTYPE html>标签,nodeName是获取节点名。例如


5、document.doctype.nodeValue是获取节点值。例如


文档标签没有值,所以为null 。
6、document.createDocumentFragment是创建一个新的空白的文档片段。
操作DOM需要节点属性,节点名称时就可以通过这些属性去获取,视代码情况而定。创建文档片段一般用在向文档中添加内容时,如果在for循环中一个一个的添加,会触发多次DOM改变,所以就可以先放到文档片段中,最后再将这个片段一次性添加到DOM中。
domReady
1 什么是domReady
1 <!DOCTYPE html> 2 <html lang="zh-CN"> 3 <head> 4 <meta charset="utf-8"> 5 <meta http-equiv="X-UA-Compatible" content="IE=edge"> 6 <meta name="viewport" content="width=device-width, initial-scale=1"> 7 <title>Dom not ready</title> 8 <script> 9 document.getElementById("header").style.color = "red"; 10 </script> 11 </head> 12 <body> 13 <h1 id="header">这里是h1元素包含的内容</h1> 14 </body> 15 </html>

html标签需要通过浏览器解析,才会变成DOM节点,而浏览器是从上至下解析代码的。
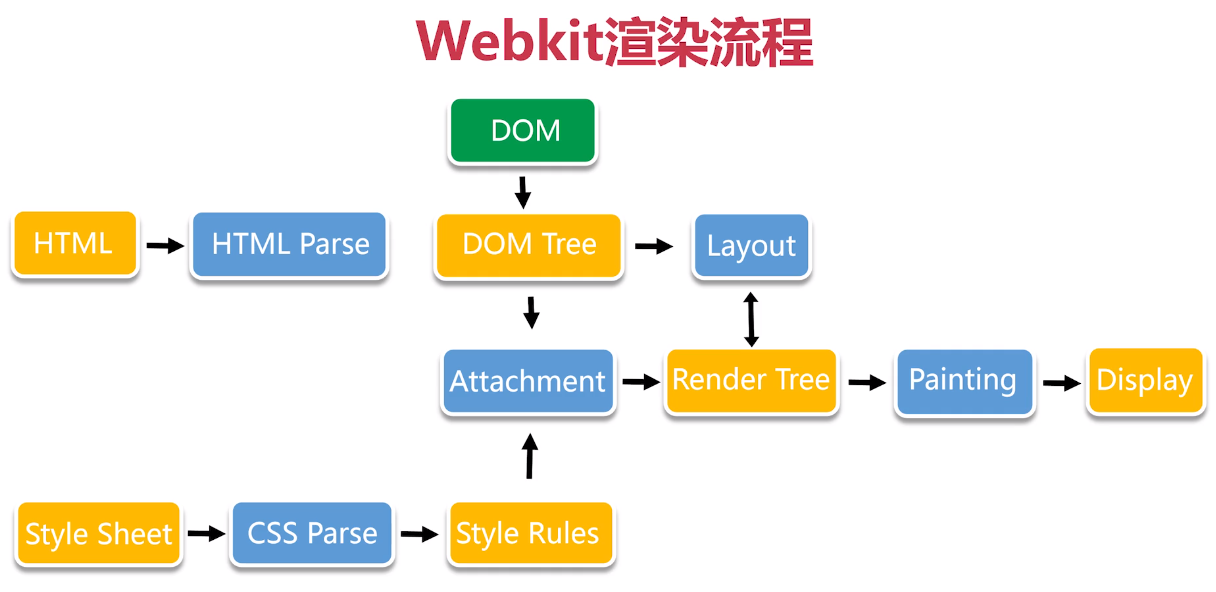
2 渲染引擎的渲染流程


渲染引擎的渲染流程 (1)解析HTML构建DOM树(构建DOM节点): 渲染引擎开始解析HTML并将标签转化为内容树的DOM节点. (2)构建渲染树(解析样式信息): 解析外部的CSS文件以及style标签中的样式信息,渲染树由 一些包含有各种属性的矩形组成,它们将被按照正确的顺序显示在 屏幕上. (3)布局渲染树(布局DOM节点): 执行布局的过程,它将确定每个节点在屏幕上的确切左边 (4)绘制渲染树(绘制DOM节点): 绘制即遍历渲染树,并使用UI后端层来绘制每个节点
这个过程不包括加载外部资源(如图片、脚本、iframe等)的过程,仅仅是html结构渲染的过程。
3 domReady的实现

理解(有难度)
-
DOMContentLoaded就是dom内容加载完毕。因为把js代码放在head中,代码顺序执行,当页面在浏览器中打开时,会先执行js代码,再执行body里面的dom结构。如果js执行时要获取body中的元素,那么就会报错,因为页面的结构还没有加载进来。下面自己封装实现一个DOMReady,就是解决这个问题,让页面结构加载完毕再执行js。
-
window.onload也可以实现此效果。区别是DOMReady不会等待图片加载,假如页面结构中有一个很大的图片,加载的时间过长。那么页面结构会继续往下加载。而window.onload是要等待图片加载完毕之后,才会继续加载下面的结构。
-
通过jQuery,也有一个方法 ,即$(document).ready(function(){}) ,与DOMReady实现的效果一样。
-
这里只是为了方便理解,才自己封装了一个方法,后续学到了jQuery,直接使用$(document).ready(function(){}) 即可。
自己实现一个domready
1 function myReady(fn){ 2 3 //对于现代浏览器,对DOMContentLoaded事件的处理采用标准的事件绑定方式 4 if ( document.addEventListener ) { 5 document.addEventListener("DOMContentLoaded", fn, false); 6 } else { 7 IEContentLoaded(fn); 8 } 9 10 //IE模拟DOMContentLoaded 11 function IEContentLoaded (fn) { 12 var d = window.document; 13 var done = false; 14 15 //只执行一次用户的回调函数init() 16 var init = function () { 17 if (!done) { 18 done = true; 19 fn(); 20 } 21 }; 22 23 (function () { 24 try { 25 // DOM树未创建完之前调用doScroll会抛出错误 26 d.documentElement.doScroll('left'); 27 } catch (e) { 28 //延迟再试一次~ 29 setTimeout(arguments.callee, 50); 30 return; 31 } 32 // 没有错误就表示DOM树创建完毕,然后立马执行用户回调 33 init(); 34 })(); 35 36 //监听document的加载状态 37 d.onreadystatechange = function() { 38 // 如果用户是在domReady之后绑定的函数,就立马执行 39 if (d.readyState == 'complete') { 40 d.onreadystatechange = null; 41 init(); 42 } 43 } 44 } 45 }
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>domReady</title> <script src="domReady.js"></script> <script> myReady(function(){ document.getElementById("header").style.color = "red"; }); </script> </head> <body> <h1 id="header">这里是h1元素包含的内容</h1> </body> </html>
4 domReady综合案例
在网页中加载六张高清图片,打印出DOMready和window.onload的事件戳,可以看出 DOMready加载更快。
1 <!DOCTYPE html> 2 <html lang="zh-CN"> 3 <head> 4 <meta charset="utf-8"> 5 <meta http-equiv="X-UA-Compatible" content="IE=edge"> 6 <meta name="viewport" content="width=device-width, initial-scale=1"> 7 <title>domReady</title> 8 <script src="../domReady.js"></script> 9 </head> 10 <body> 11 <div id="showMsg"></div> 12 <div> 13 <img src="1.jpg" /> 14 <img src="2.jpg" /> 15 <img src="3.jpg" /> 16 <img src="4.jpg" /> 17 <img src="5.jpg" /> 18 <img src="6.jpg" /> 19 </div> 20 <script> 21 var d = document; 22 var msgBox = d.getElementById("showMsg"); 23 var imgs = d.getElementsByTagName("img"); 24 var time1 = null, time2 = null; 25 myReady(function(){ 26 msgBox.innerHTML += "dom已加载!<br>"; 27 time1 = new Date().getTime(); 28 msgBox.innerHTML += "时间戳:" + time1 + "<br>"; 29 }); 30 window.onload = function(){ 31 msgBox.innerHTML += "onload已加载!<br>"; 32 time2 = new Date().getTime(); 33 msgBox.innerHTML += "时间戳:" + time2 + "<br>"; 34 msgBox.innerHTML +="domReady比onload快:" + (time2 - time1) + "ms<br>"; 35 }; 36 </script> 37 </body> 38 </html>
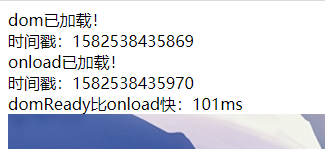 这里是加载本地的资源,如果加载网络资源差距会更加明显!
这里是加载本地的资源,如果加载网络资源差距会更加明显!
元素节点类型判断
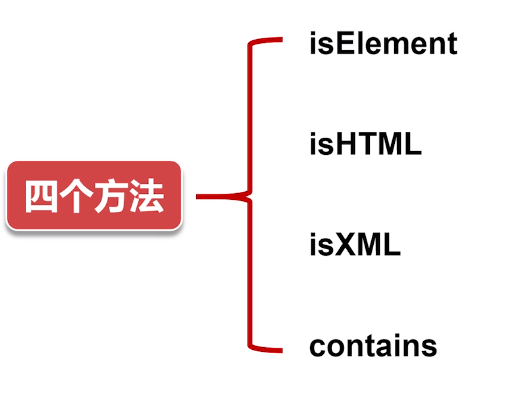
1 isElement:某个节点是否为元素节点
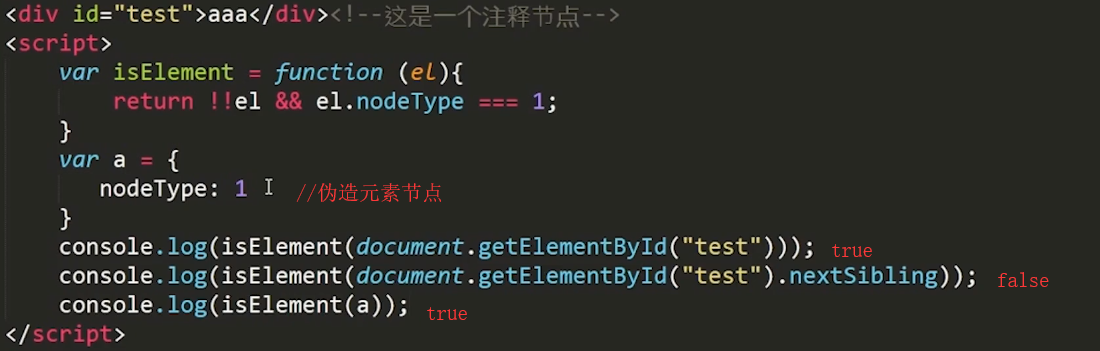
完美的方案
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>isElement</title> 6 </head> 7 <body> 8 <div id="test">aaa</div> 9 <!--这是一个注释节点--> 10 <script> 11 var testDiv = document.createElement('div'); 12 var isElement = function (obj) { 13 if (obj && obj.nodeType === 1) {//先过滤最简单的 14 if( window.Node && (obj instanceof Node )){ //如果是IE9,则判定其是否Node的实例 15 return true; //由于obj可能是来自另一个文档对象,因此不能轻易返回false 16 } 17 try {//最后以这种效率非常差但肯定可行的方案进行判定 18 testDiv.appendChild(obj); 19 testDiv.removeChild(obj); 20 } catch (e) { 21 return false; 22 } 23 return true; 24 } 25 return false; 26 } 27 var a = { 28 nodeType: 1 29 } 30 console.log(isElement(document.getElementById("test"))); 31 console.log(isElement(document.getElementById("test").nextSibling)); 32 console.log(isElement(a)); 33 </script> 34 </body> 35 </html>
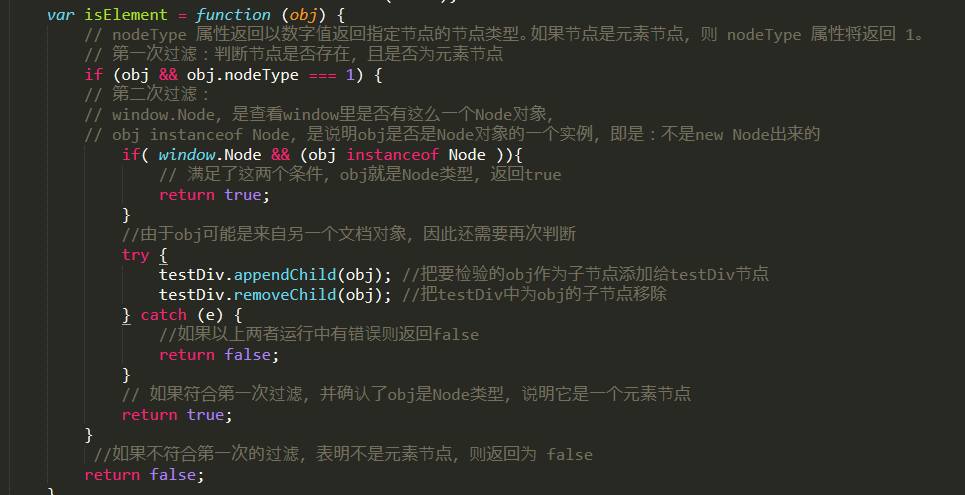
关于另一个文档对象:文档对象分为html文档对象和xml文档对象,这里的意思是,由于xml与html对象均支持createElement()方法,所以使用createElement()方法创建的节点可能是xml对象的节点,也可能是html对象的节点。
2 isHTML:是否为HTML文档的元素节点
方法一:
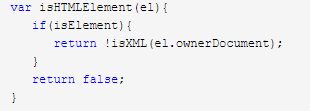
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>isHTMLElement</title> 6 </head> 7 <body> 8 <script> 9 var testDiv = document.createElement('div'); 10 var isElement = function (obj) { 11 if (obj && obj.nodeType === 1) {//先过滤最简单的 12 if( window.Node && (obj instanceof Node )){ //如果是IE9,则判定其是否Node的实例 13 return true; //由于obj可能是来自另一个文档对象,因此不能轻易返回false 14 } 15 try {//最后以这种效率非常差但肯定可行的方案进行判定 16 testDiv.appendChild(obj); 17 testDiv.removeChild(obj); 18 } catch (e) { 19 return false; 20 } 21 return true; 22 } 23 return false; 24 } 25 var isHTMLElement(el){ 26 if(isElement){ 27 return !isXML(el.ownerDocument); 28 } 29 return false; 30 } 31 </script> 32 </body> 33 </html>
方法二:
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>isHTML</title> 6 </head> 7 <body> 8 <script> 9 var isHTML = function(doc) { 10 return doc.createElement("p").nodeName === doc.createElement("P").nodeName; 11 } 12 console.log(isHTML(document)); 13 </script> 14 </body> 15 </html>
3 isXML:是否为XML文档的元素节点
方法一:
1 //Sizzle, jQuery自带的选择器引擎 2 var isXML = function(elem) { 3 var documentElement = elem && (elem.ownerDocument || elem).documentElement; 4 return documentElement ? documentElement.nodeName !== "HTML" : false; 5 }; 6 console.log(isXML(document.getElementById("test"))); 7 8 //但这样不严谨,因为XML的根节点,也可能是HTML标签,比如这样创建一个XML文档 9 try { 10 var doc = document.implementation.createDocument(null, 'HTML', null); 11 console.log(doc.documentElement); 12 console.log(isXML(doc)); 13 } catch (e) { 14 console.log("不支持creatDocument方法"); 15 }
方法二:
1 //我们看看mootools的slick选择器引擎的源码: 2 var isXML = function(document) { 3 return (!!document.xmlVersion) || (!!document.xml) || (toString.call(document) == '[object XMLDocument]') 4 || (document.nodeType == 9 && document.documentElement.nodeName != 'HTML'); 5 }; 6 7 //精简版 8 var isXML = window.HTMLDocument ? function(doc) { 9 return !(doc instanceof HTMLDocument); 10 } : function(doc) { 11 return "selectNodes" in doc; 12 }
方法三:
1 var isXML = function(doc) { 2 return doc.createElement("p").nodeName !== doc.createElement("P").nodeName; 3 }
理解:
①html不区分大小写,默认都按照大写处理。例如有一个p标签,那么写成<p>或者<P>浏览器都能解析。所以如果是html元素,doc.createElement("p").nodeName 和doc.createElement("P").nodeName都能成功的创建元素并获取到元素名。所以doc.createElement("P").nodeName和doc.createElement("P").nodeName;是相等的。
return doc.createElement("p").nodeName !== doc.createElement("P").nodeName;
示例:
console.dir()显示一个对象的所有属性和方法 ,下面使用的小写字母p

输出:

找一下标签名属性,是大写的P:

②这个函数用来判断元素是否为html元素。html和xml都是页面中的元素节点。if判断中,如果结果能够返回true,则执行if里面的语句。所以这里调用isElement()判断el是否为元素节点。当el为元素节点,则返回true .然后继续判断元素节点是xml还是html。如果传入el的是html元素,执行isXML(el.ownerDocument)返回的就是false ,再取非返回true。如传入的不是元素节点,if就不会执行。则直接执行最后的retuen false。
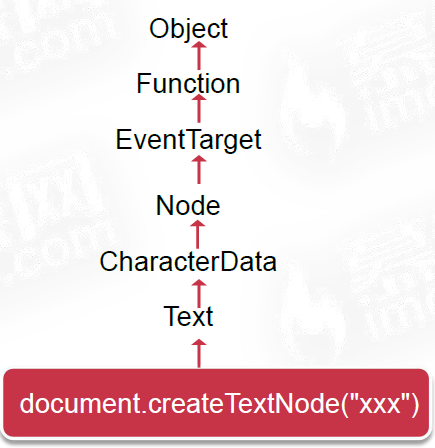
③ownerDocument属性返回的是document文档对象,例如


使用创建元素方法的时候前面需要是document.createElement(),所以需要传入el.ownerDocument,也就是document。
④var doc = document.implementation.createDocument(null, 'HTML', null);是什么意思?
代码的意思是创建并返回一个 XMLDocument对象。
关于DOMImplementation.createDocument()方法可以看一下官方文档:
https://developer.mozilla.org/zh-CN/docs/Web/API/DOMImplementation/createDocument

⑤关于四个属性:
xmlVersion 属性可设置或返回文档的 XML 版本。
xml 属性可返回节点及其后代的 XML。
document对象转化为字符串是不是[object XMLDocument](XML文档对象)
document的节点类型值是不是9(指定值)以及节点名称是不是HTML
4 contains:两个节点的包含关系
任何版本浏览器都兼容,但是只能判断元素节点。
IE等低版本浏览器中不能判断其他类型节点的包含关系。
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>contains</title> 6 </head> 7 <body> 8 <div id="p-node"> 9 <div id="c-node">子节点内容</div> 10 </div> 11 <script> 12 var pNode = document.getElementById("p-node"); 13 var cNode = document.getElementById("c-node").childNodes[0]; 14 alert(pNode.contains(cNode)); 15 </script> 16 </body> 17 </html>
自己编写任何浏览器任何类型节点都兼容的contains方法
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>contains</title> 6 </head> 7 <body> 8 <div id="p-node"> 9 <div id="c-node">子节点内容</div> 10 </div> 11 <script> 12 function fixContains(a, b) { 13 try { 14 while ((b = b.parentNode)){ 15 if (b === a){ 16 return true; 17 } 18 } 19 return false; 20 } catch (e) { 21 return false; 22 } 23 } 24 var pNode = document.getElementById("p-node"); 25 var cNode = document.getElementById("c-node").childNodes[0]; 26 alert(fixContains(pNode, cNode)); 27 //alert(fixContains(document, cNode)); 28 </script> 29 </body> 30 </html>

创建(添加)节点
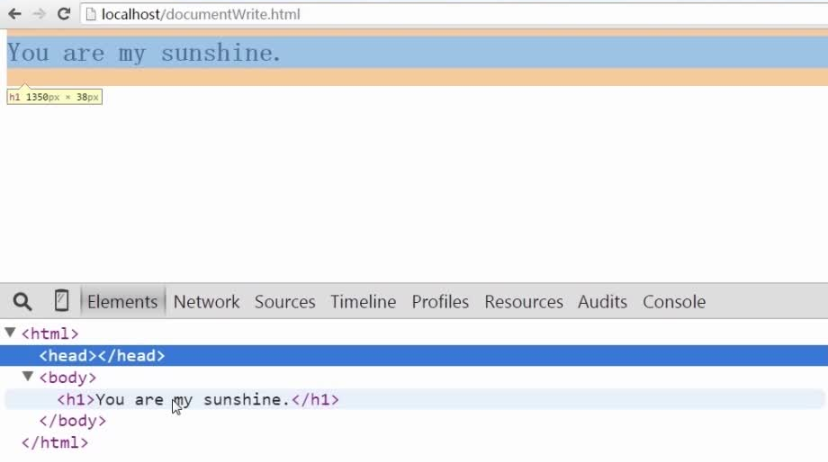
1 document.write()
缺点:如果是domReady后加载的document.write.那页面上原来的节点会被清空,被新创建的节点覆盖。这是不能容忍的。
2 create系列

1 <!DOCTYPE html> 2 <html lang="zh-CN"> 3 <head> 4 <meta charset="utf-8"> 5 <meta http-equiv="X-UA-Compatible" content="IE=edge"> 6 <meta name="viewport" content="width=device-width, initial-scale=1"> 7 <title>create方法</title> 8 <script src="domReady.js"></script> 9 <script> 10 myReady(function(){ 11 var comment = document.createComment("A comment"); //创建注释节点 12 var fragment = document.createDocumentFragment();//创建文档片段 13 var ul = document.getElementById("myList"); 14 var li = null; 15 for (var i = 0; i < 3; i++){ 16 li = document.createElement("li");//创建li元素 17 li.appendChild(document.createTextNode("Item " + (i+1)));//创建文本节点,并将该文本节点装填到li标签后 18 fragment.appendChild(li);//将li装填到文档片段后 19 } 20 ul.appendChild(fragment);//将文档片段装填到ul标签后 21 document.body.insertBefore(comment, document.body.firstChild);//在body的最前面添加节点,传入的两个参数(要添加的内容,插到哪个节点前) 22 }); 23 </script> 24 </head> 25 <body> 26 <ul id="myList"></ul> 27 </body> 28 </html>
理解:
document.body.insertBefore(document.createComment,所要插入标签的前面);
document.createDocumentFragment()创建文档片段:文档片段就是来帮助我们,把创建的一大堆新元素都放在文档片段中,然后提交给文档中。
特别注意两个点:
当把文档片段插入DOM树的时候,只会把它的子节点插进去,它作为容器本身是不会进入DOM树的。
当把DOM树种的节点插入文档片段的时候,这些节点,会真的从DOM树种消失。我们也把这个过程叫做劫持。
类比的话,就好像自助餐厅,文档片段是我们的托盘,先在取餐区里面把想要的东西都放在托盘里面,也可以把自己桌子上已经有的东西放在托盘里,再把托盘里的全部东西都放在饭桌上,当然托盘本身不需要的。对性能提升很有帮助哦,也可以减少重排。

1 <!DOCTYPE html> 2 <html lang="zh-CN"> 3 <head> 4 <meta charset="utf-8"> 5 <meta http-equiv="X-UA-Compatible" content="IE=edge"> 6 <meta name="viewport" content="width=device-width, initial-scale=1"> 7 <title>html5shiv</title> 8 <style> 9 /*html5*/ 10 article { 11 font-size: 40px; 12 color: red; 13 } 14 </style> 15 <script> 16 (function() { 17 if (! 18 /*@cc_on!@*/ 19 0) return; 20 var e = "abbr, article, aside, audio, canvas, datalist, details, dialog, eventsource, figure, footer, header,
hgroup, mark, menu, meter, nav, output, progress, section, time, video".split(', '); 21 var i = e.length; 22 while (i--){ 23 document.createElement(e[i]); 24 } 25 })(); 26 </script> 27 </head> 28 <body> 29 <article> 30 You are my sunshine. 31 </article> 32 </body> 33 </html>
hack:为了解决兼容不同浏览器的问题。
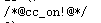
上面的代码是针对Ie浏览器的,如果是ie浏览器会被解析为!,如果不是ie浏览器,则作为注释被忽略。
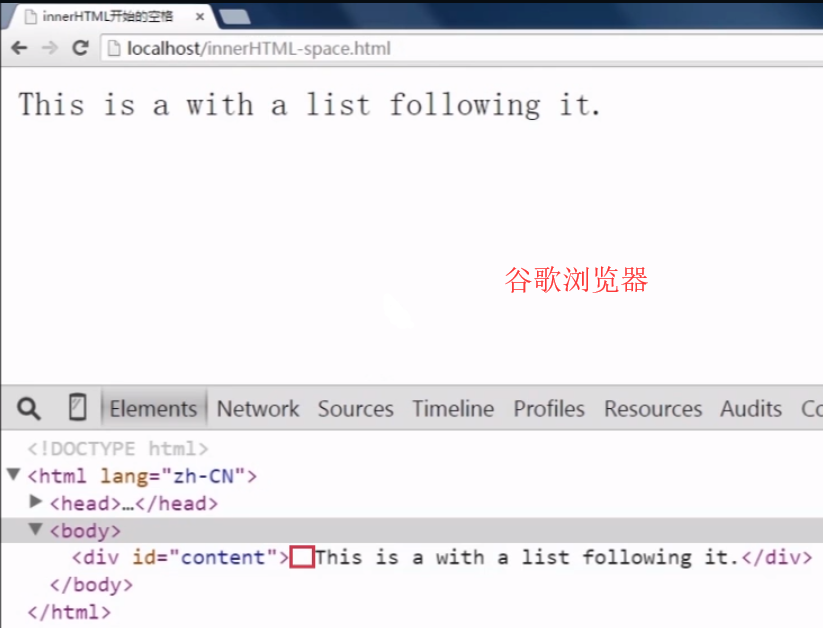
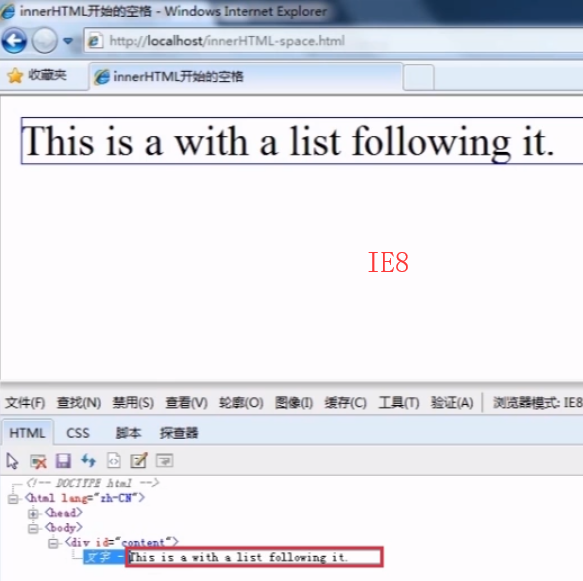
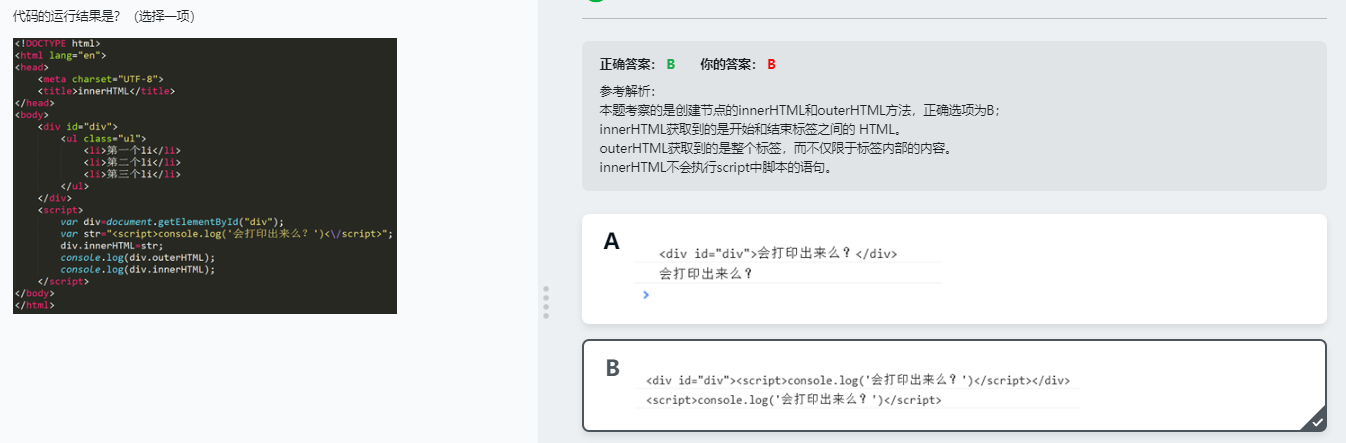
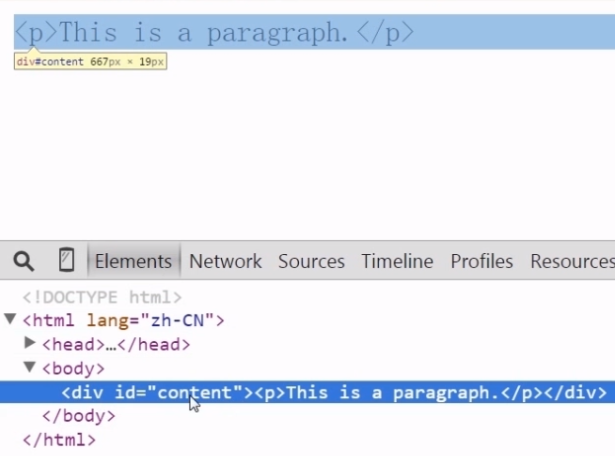
3 高效创建节点的方法——innerHTML 和 outerHTML
inner HTML:用来设置或获取当前标签的起始和结束里面的内容。
1 <!DOCTYPE html> 2 <html lang="zh-CN"> 3 <head> 4 <meta charset="utf-8"> 5 <meta http-equiv="X-UA-Compatible" content="IE=edge"> 6 <meta name="viewport" content="width=device-width, initial-scale=1"> 7 <title>innerHTML</title> 8 <script src="domReady.js"></script> 9 <script> 10 myReady(function(){ 11 var content = document.getElementById("content"); 12 var str = "<p>This is a <strong>paragraph</strong> with a list following it.</p>" 13 + "<ul>" 14 + "<li>Item 1</li>" 15 + "<li>Item 2</li>" 16 + "<li>Item 3</li>" 17 + "</ul>"; 18 content.innerHTML = str; 19 alert(content.innerHTML); 20 }); 21 </script> 22 </head> 23 <body> 24 <div id="content"></div> 25 </body> 26 </html>




解决上述问题,也是要在style标签前面添加一个有作用域的元素。(可以添加一个文本节点,如下划线,或者一个包含空格文本节点的div标签,再通过removechild将它们删除;另外常用的方法是添加一个type属性为hidden的input元素)
理解:
无作用域元素就是指在页面中看不到的元素, 例如:script元素,style元素, 那么,有作用域元素就是指在页面中可以看到的元素,示例:input元素等。
script标签要在有作用域的元素之后,这句话是规定,也就是说需要script元素前添加内容才可以执行标签中的代码。



outerHTML:返回调用它的元素即所有子节点的HTML标签。

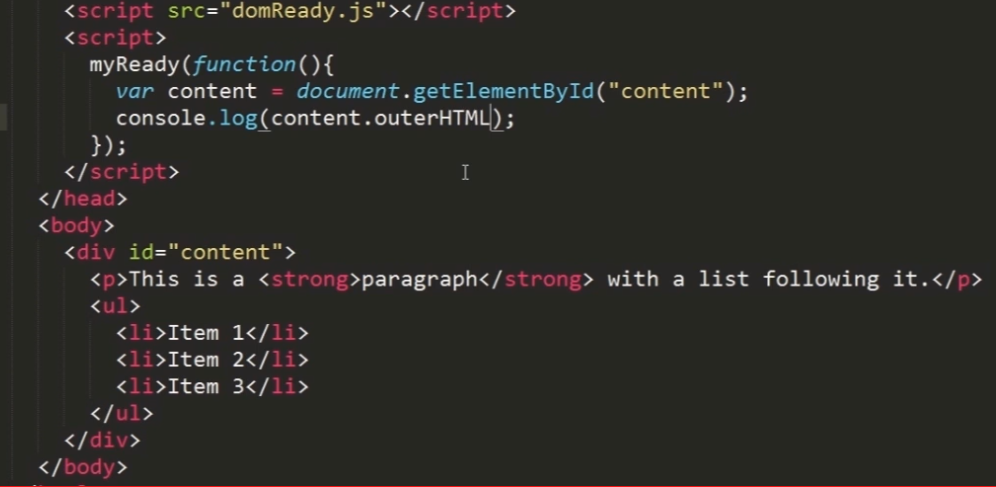
打印结果:

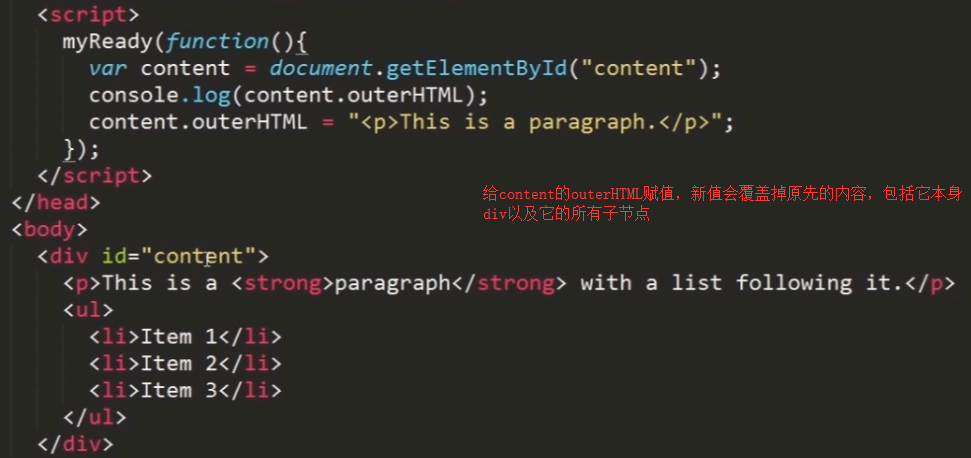
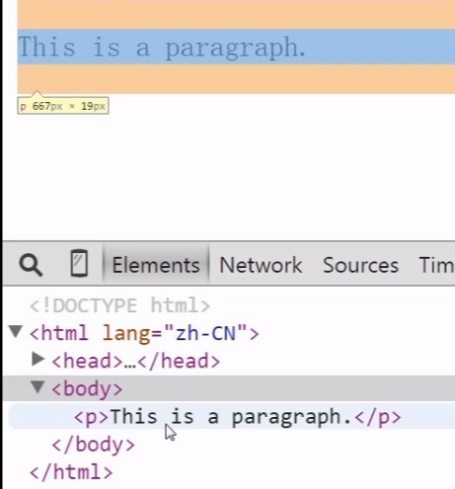
控制台结果:原来的div没了~被p标签及p标签子节点们覆盖了
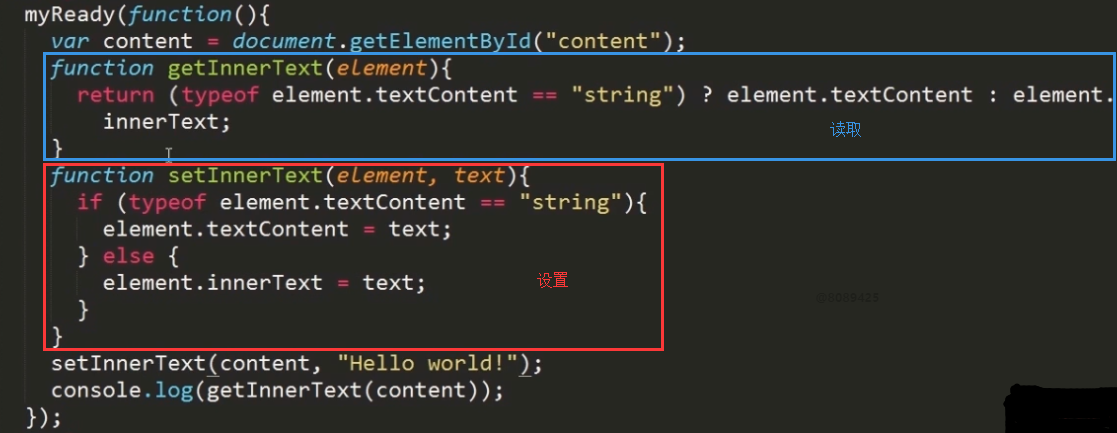
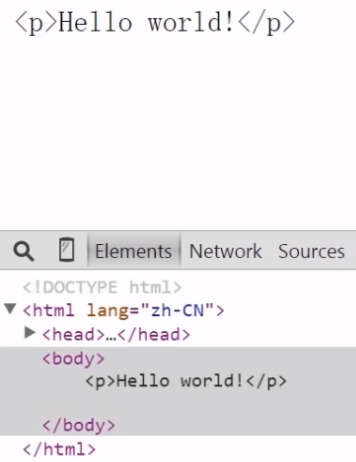
4 高效创建节点的方法——innerText 和 outerText

firefox虽然不支持innerText,但支持作用类似的textContent属性。
innerText作用:操作元素中包含的所有文本内容,包括子文档树中的文本,在通过innerText读取值的时候,会按照由浅入深的顺序将子文档树中的所有文本拼接起来,再通过inner Text写入值的时候,结果会删除元素的所有子节点,插入包含相应文本值的文本节点。
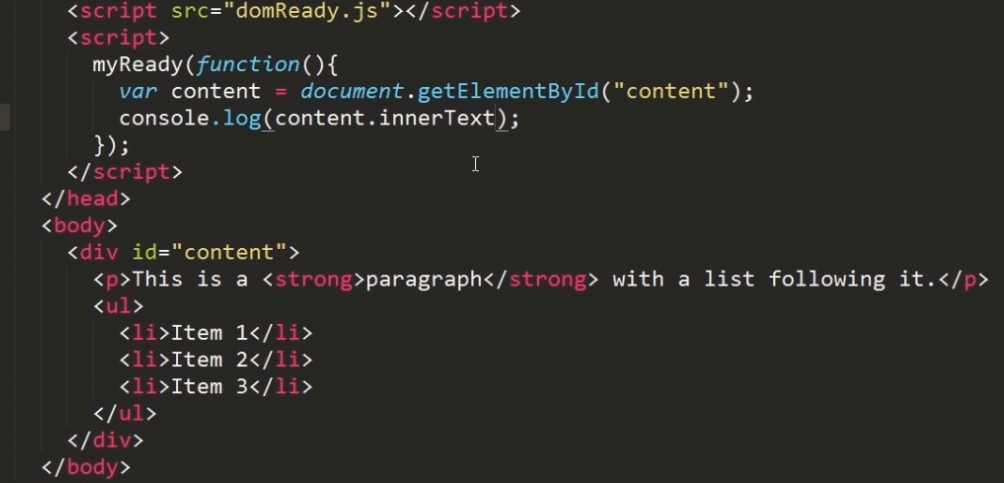
打印结果:


Firefox:

通用方法

除了作用范围扩大到了包含调用它的节点之外, outerText和innerText的读取是一样的。
outerText和innerText在写入模式下,结果是不同的。
outerText不只是替换调用它的元素的子节点,会替换整个元素包括子节点。
这个属性会导致调用它的元素不存在,因此并不常用,建议尽量不要使用。
理解:
在写模式下,outerHTML 会根据指定的 HTML 字符串创建新的 DOM 子树,然后用这个DOM子树完全替换调用元素。

5 textContent和deleteContents(实际开发中很少用,了解即可)
1、textContent属性设置或者返回指定节点的文本内容。 与innerHTML的作用类似,区别就是 textContent值获取文本内容。

效果图:textContent只获取文本内容,不包含标签:
2、deleteContents方法是删除文档的区域。该方法将删除当前范围表示的所有文档内容。
参考如下:

页面:

里面涉及到了我们没有学到过的Range,了解下即可,这个属性基本用不上了。
节点遍历
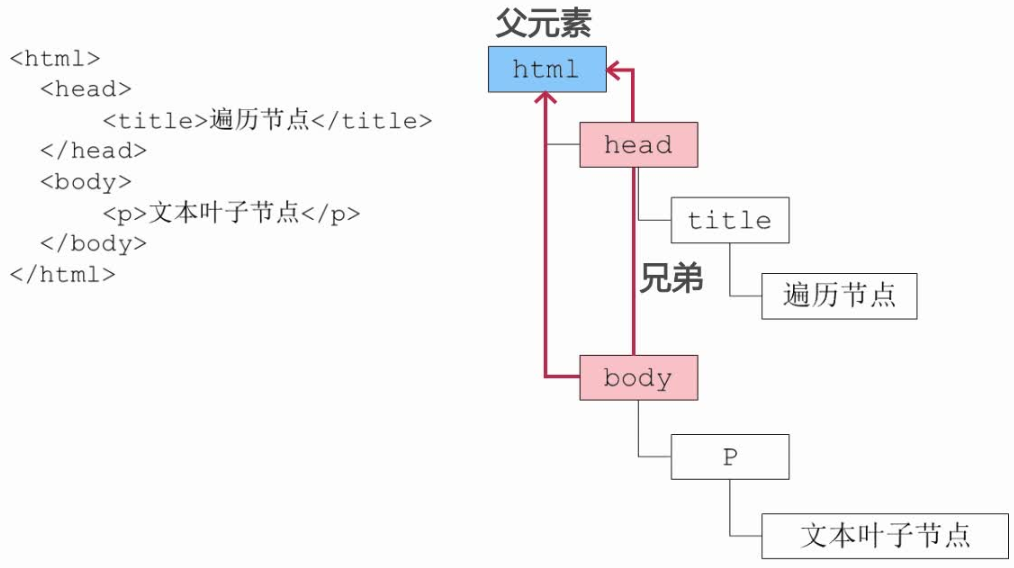
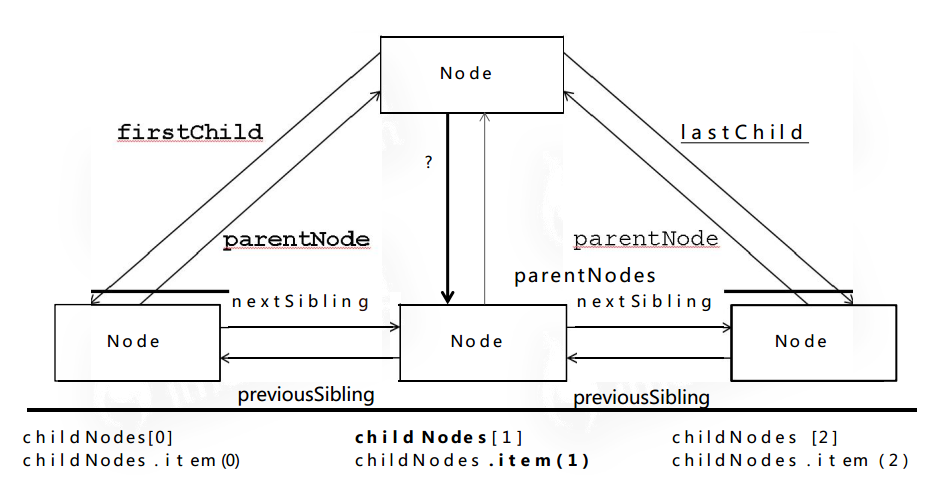
firstChild:第一个子节点 lastChild:最后一个子节点 parentNode:父节点 nextSibling:下一个紧挨的兄弟节点 previousSibling:上一个紧挨的兄弟节点 childNodes[1] 或 childNodes.item(1) 查找第几个子节点
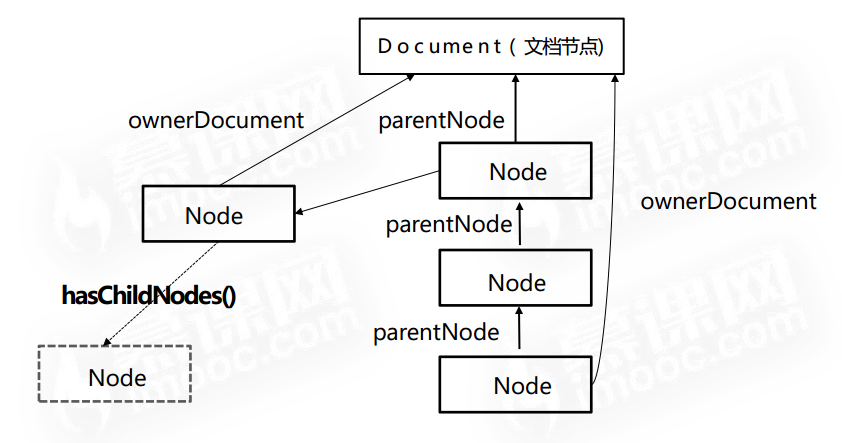
ownerDocument:获得节点的祖先节点,即直接获得Document节点。跟直接写document是一样的,实际中不常用,这里只是用来理解
hasChildNodes():节点是否存在子节点
节点遍历实现

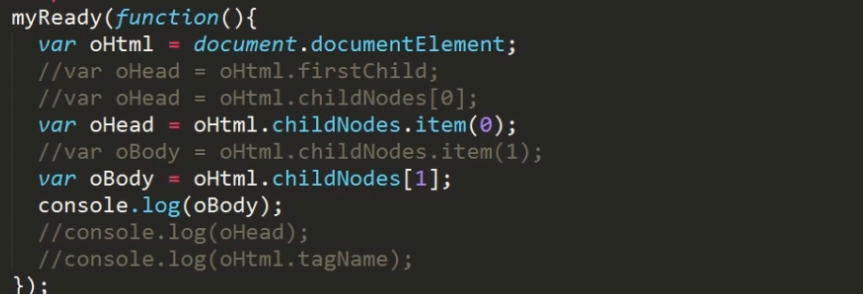
上图中控制台输出的结果,在主流浏览器中是#text文本节点,而IE8及以下的浏览器是body节点。
这是因为新的浏览器会将标签之间的空格当作空白文本节点,而在IE8及以前的浏览器中会自动忽略这个文本节点。(注意:html和head之间的空格or换行是获取不到的。)
思考:如何正确获得body呢?去掉多余空格或判断tagName返回值,这两种方法都不推荐,后面会介绍更优的方法。
1 <!DOCTYPE html> 2 <html lang="zh-CN"> 3 <head> 4 <meta charset="utf-8"> 5 <meta name="viewport" content="width=device-width, initial-scale=1"> 6 <title>dom Tree walker</title> 7 <script src="domReady.js"></script> 8 <script> 9 myReady(function(){ 10 var oHtml = document.documentElement; 11 var p = document.getElementById("paragraph"); 12 var txt = p.childNodes[0]; 13 //var oHead = oHtml.firstChild; 14 //var oHead = oHtml.childNodes[0]; 15 var oHead = oHtml.childNodes.item(0); 16 //var oBody = oHtml.childNodes.item(1); 17 var oBody = oHtml.childNodes[1]; 18 19 //console.log(oHead.parentNode == oHtml); 20 //console.log(oBody.parentNode == oHtml); 21 22 //console.log(oBody.previousSibling == oHead); 23 //console.log(oHead.nextSibling == oBody); 24 //console.log(oBody); 25 //console.log(oHead); 26 //console.log(oHtml.tagName); 27 28 //console.log(p.ownerDocument == document); 29 console.log(p.hasChildNodes()); 30 console.log(txt.hasChildNodes()); 31 }); 32 </script> 33 </head><body> 34 <p id="paragraph">文本叶子节点</p> 35 </body> 36 </html>
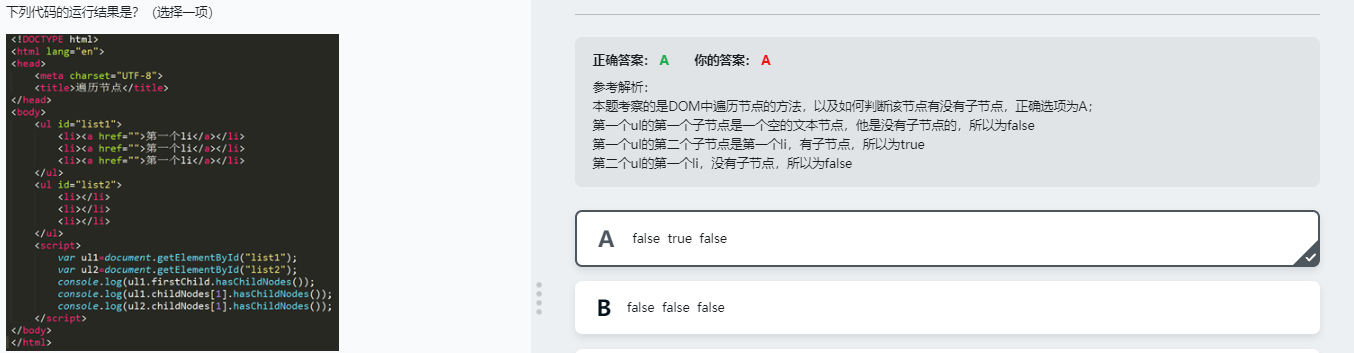
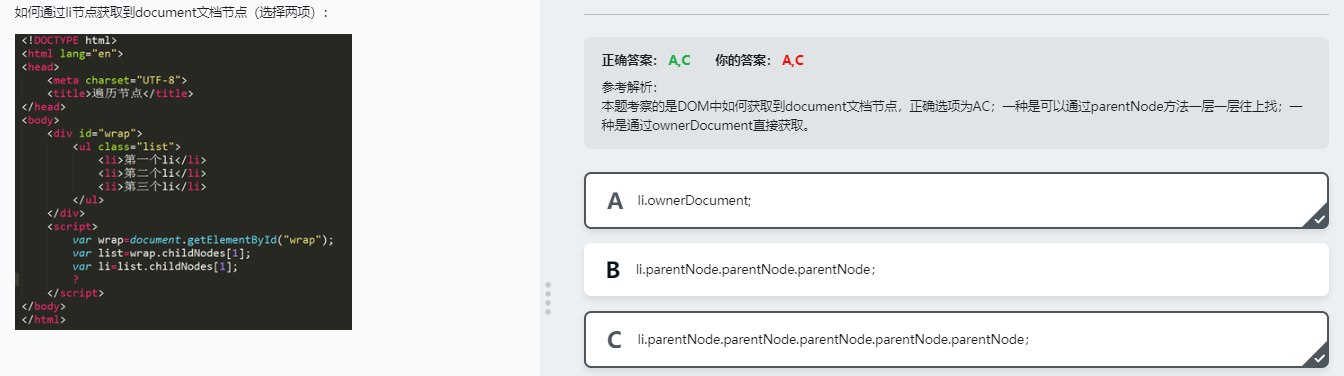
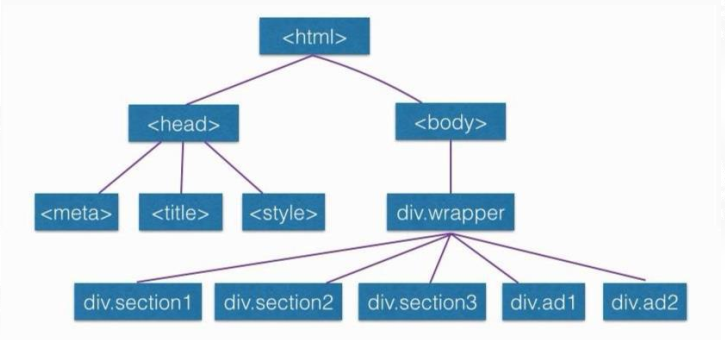
遍历并打印一个html树
1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="utf-8"> 5 <meta name="viewport" content="width=device-width, initial-scale=1"> 6 <title>DOM Travel</title> 7 <script src="domReady.js"></script> 8 <script> 9 myReady(function(){ 10 var s = ""; 11 function travel(space, node) { 12 if (node.tagName) { // 如果当前节点是标签,不是空的,就拼接字符串 13 s += space + node.tagName + "<br/>"; 14 } 15 var len = node.childNodes.length; //保存当前节点的子节点的个数 16 for (var i = 0; i < len; i++) { //遍历节点的子节点 17 travel(space + "|-", node.childNodes[i]); 18 } 19 } 20 travel("", document); 21 document.write(s); 22 }); 23 </script> 24 </head> 25 <body> 26 <form> 27 <input type="button" id="button1" name="button1" value="Click Me!" /> 28 </form> 29 </body> 30 </html>
s:用来存储将要打印在页面上的字符串
space:存储节点之间分隔的字符串
node:保存遍历的当前节点

解决空白节点的问题
方案一:
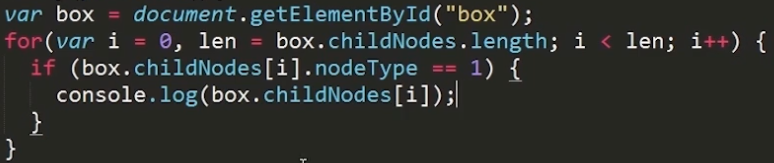
方案二:
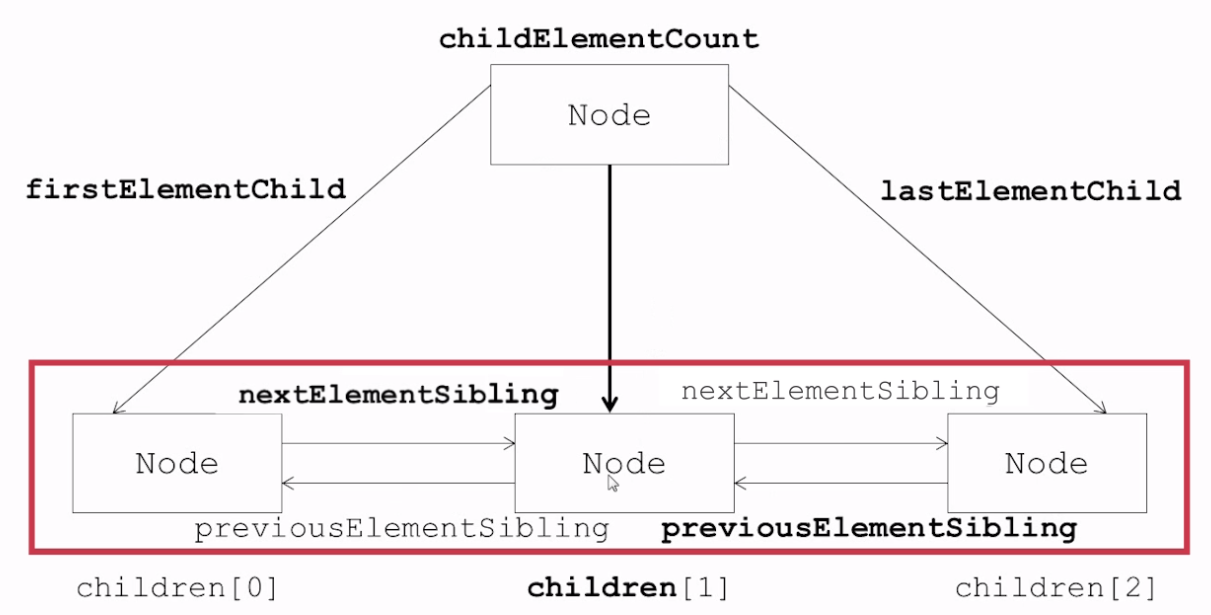
children数组只包含直接子元素节点 ,不包含子文本节点。
childElementCount:当前节点直接子元素节点的个数。(再次强调:直接子元素节点,不包含子文本节点,不包含后代子元素节点)

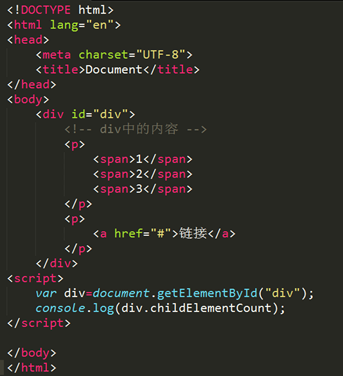
打印结果:2

NodeList


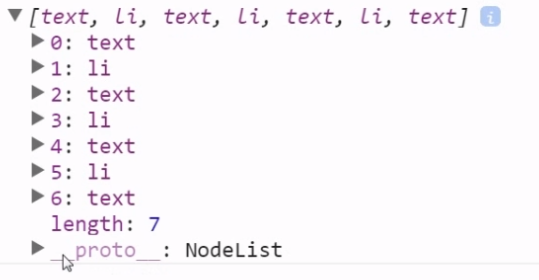
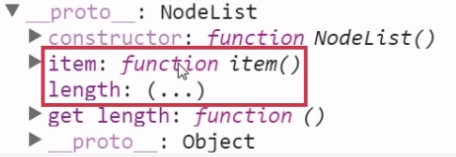

如何让这个类数组有数组的功能,并且可以操作呢?
方法一:我们可以遍历各个节点,并将它们装填到一个数组中即可。
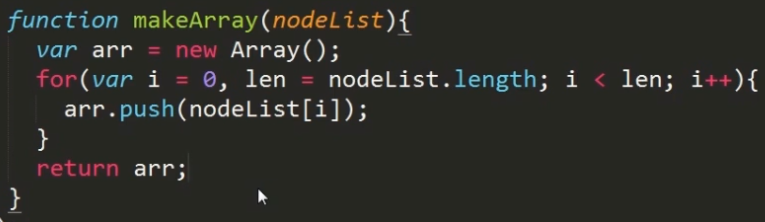
方法二:通过调用Array对象的prototype属性下的slice方法。但在IE低版本浏览器中不兼容
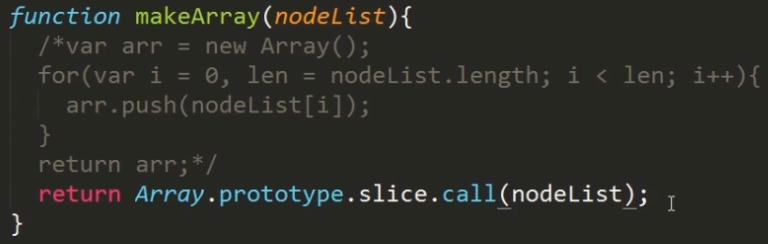
解决兼容问题:
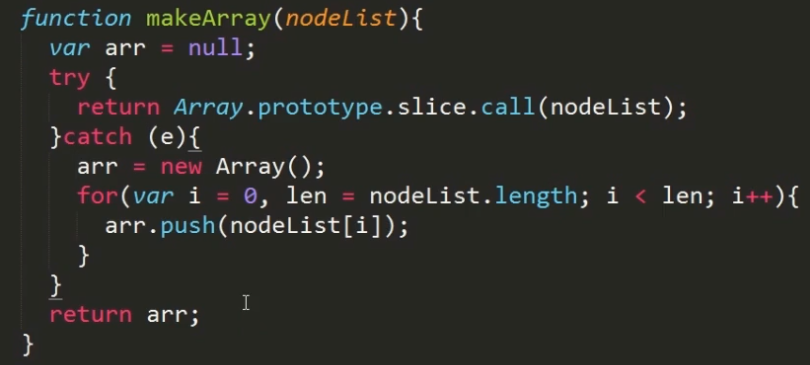
类数组对象HTMLCollection
HTMLCollection——HTML元素集合
-Ele.getElementsByTagName() 根据元素的名称返回一组元素的集合 -documen.scripts 返回页面的全部script元素的集合 -document.links 返回页面的全部a元素的集合 -document.images 返回页面的全部images(图片元素)的集合 -document.forms 返回页面的全部form元素集合 -tr.cells 返回这个tr的所有td子元素的集合 -select.options 返回这个select的全部option元素集合 -......
可以在控制台看到他们的_proto_(原型的意思)都是类数组对象HTMLCollection,cells还具有nameTtem方法
1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="utf-8"> 5 <meta name="viewport" content="width=device-width, initial-scale=1"> 6 <title>类数组对象HTMLCollection</title> 7 <script src="domReady.js"></script> 8 <script> 9 myReady(function(){ 10 var scripts = document.scripts; 11 var links = document.links; 12 var cells = document.getElementById("tr").cells; 13 var imgs = document.images; 14 var forms = document.forms; 15 var options = document.getElementById("select").options; 16 var ps = document.getElementsByTagName("p"); 17 18 /*console.log(scripts); 19 console.log(links); 20 console.log(cells); 21 console.log(imgs); 22 console.log(forms); 23 console.log(options); 24 console.log(ps);*/ 25 26 console.log(cells.namedItem('td')); 27 }); 28 </script> 29 </head> 30 <body> 31 <ul id="box"> 32 <li>节点一</li> 33 <li>节点二</li> 34 <li>节点三</li> 35 </ul> 36 37 <table border="1"> 38 <tr id="tr"> 39 <td>第一行</td> 40 <td name="td">第二行</td> 41 <td name="td">第三行</td> 42 </tr> 43 </table> 44 45 <img src="duer.jpg" alt="img1" /> 46 <img src="ipone6s+.png" alt="img2" /> 47 48 <form action=""> 49 <input type="text" value="用户名"> 50 </form> 51 <form action=""> 52 <input type="text" value="密码"> 53 </form> 54 55 <a href="#">忘记密码</a> 56 <a href="#">更多内容</a> 57 58 <select id="select"> 59 <option value="0">北京</option> 60 <option value="1">天津</option> 61 <option value="2">河北</option> 62 </select> 63 64 <p>DOM探索之基础详解篇</p> 65 <p>DOM探索之节点操作篇</p> 66 </body> 67 </html>

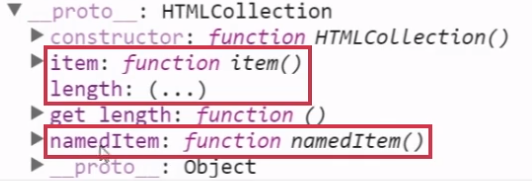
namedItem 方法:
该方法会首先查询带有匹配给定名称的 id 属性的节点,如果不存在匹配的 id 属性,则查询带有匹配给定名称的 name 属性的节点,如果都不存在,返回null。只返回第一个符合条件的。

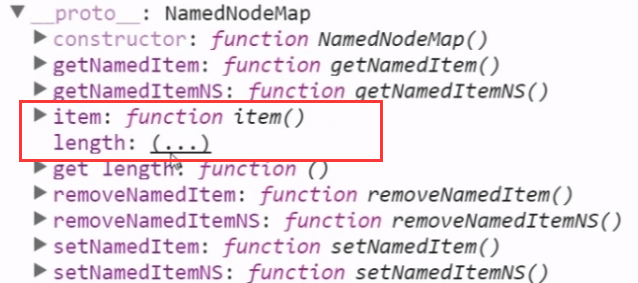
类数组对象NamedNodeMap

返回的是元素属性的集合 XXX.attributes属性 存储attribute(属性)集合 可用方法:.length 数组长度 .item() 、[] 两种 方式可获取其中某个属性,从0开始 索引。

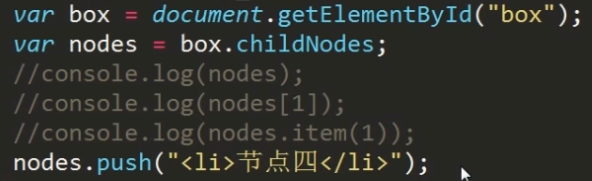
类数组对象的动态性

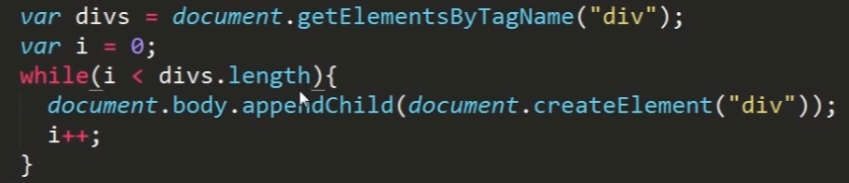
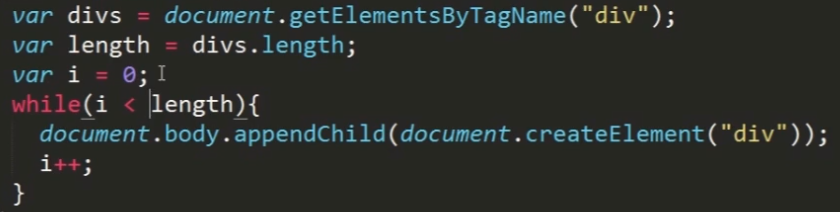
上述代码产生死循环,表明了这三个类数组对象的动态性。
要解决这个问题,将数组的长度提前保存下来即可。
获取节点

IE6~IE8可以使用前三个
见文章:DOM元素获取
操作节点
appendchild()
为指定元素节点的最后一个子节点之后添加节点。该方法返回新的子节点。
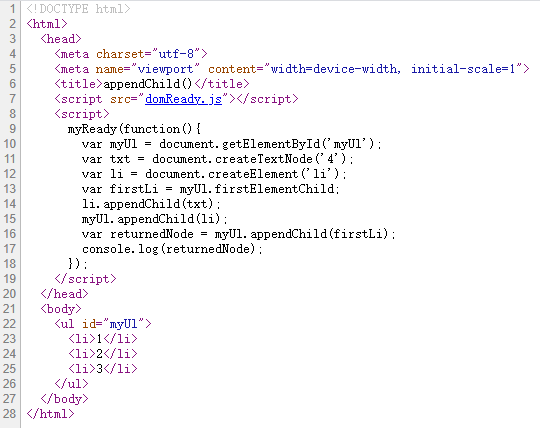
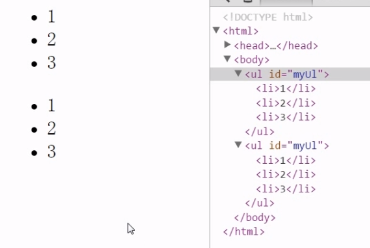
var firstLi = document.firstElementChild;---获取第一个子节点li myUl.appendChild(firstLi);----将获取的第一个子节点移动到最后,所以并没有复制
 👉
👉 
insertBefore()
在指定的已有子节点之前插入新的子节点。传两个参数,第一个是新节点,第二个是要插入到哪个节点前面。如果要插到其子节点最后(同apendchild功能),第二个参数传null。返回的是新插入的节点。
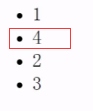
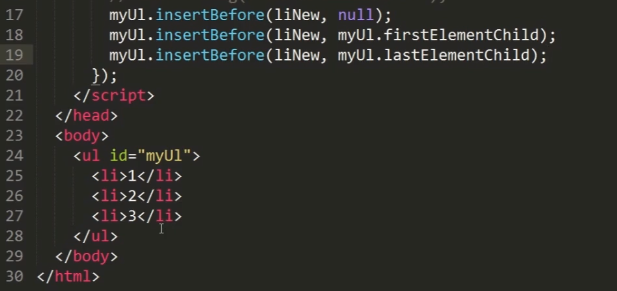
第二句代码结果: 第三句代码结果:
第三句代码结果: 
replaceChild()

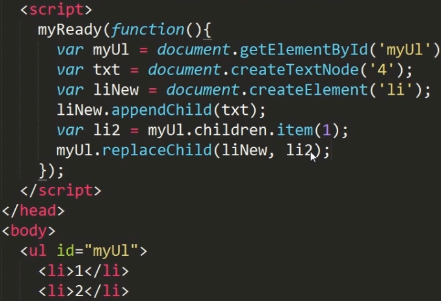
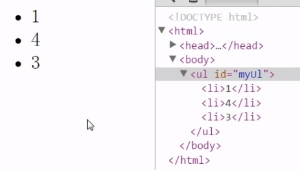

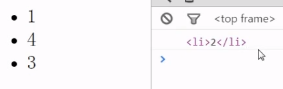
cloneNode(boolean)
创建节点的拷贝,返回该副本; 拷贝的节点要有父节点,如果没有父节点,在dom上是看不见的,要通过appendChild 、insertBefore、replaceChild等方法将其添加到文档中; 参数默认为false,如果写true,则为深度复制(包括子节点全部复制);
boolean为true时,复制ul下的li,false仅仅复制所获取的节点,不复制该节点下的子节点,比如获取ul,ul下有li,true不仅复制了ul还复ul下的li,而false仅仅复制ul没有复制子节点li。

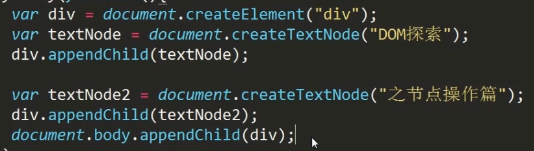
normalize()
合并相邻的文本节点
以前的方法:
normalize方法:
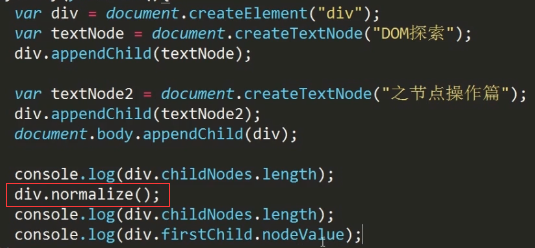
理解:
① normalize是合并相邻的文本节点,并不是单单只合并两个文本。
② 不是合并所有的节点,只是合并相邻的文本节点。
③ 举个例子:

打印结果:

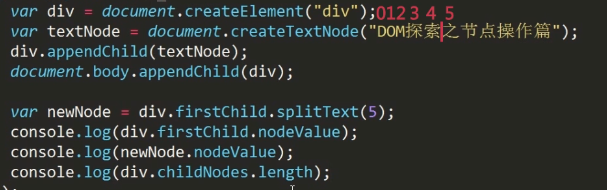
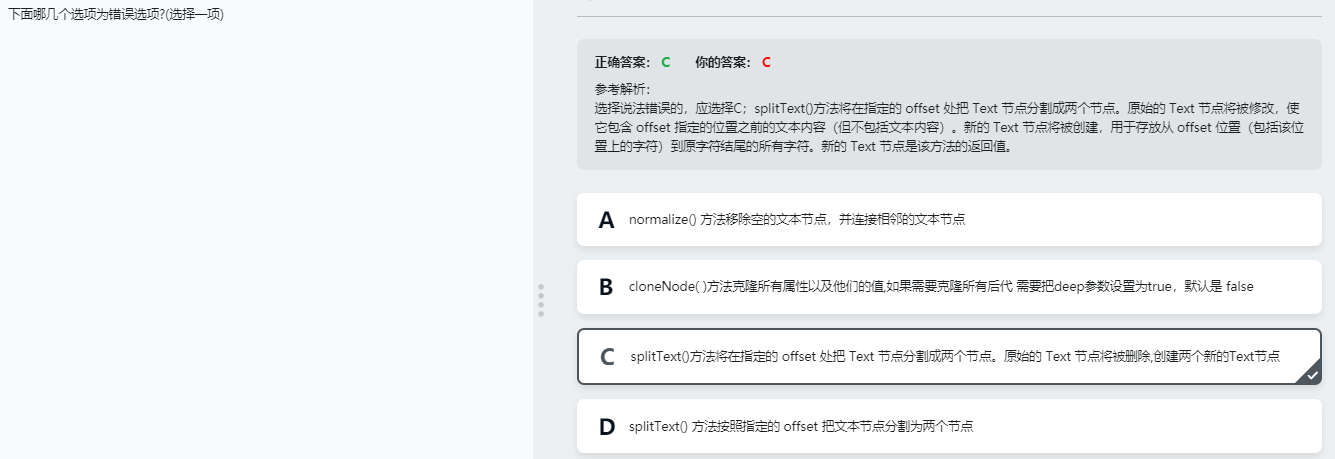
splitText()
按照指定的位置把文本节点分割为两个节点。返回新的文本节点。

删除节点

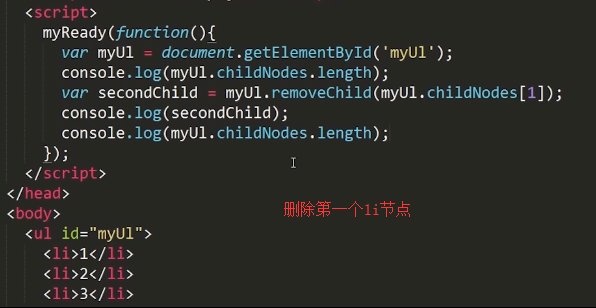
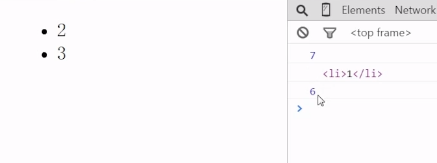
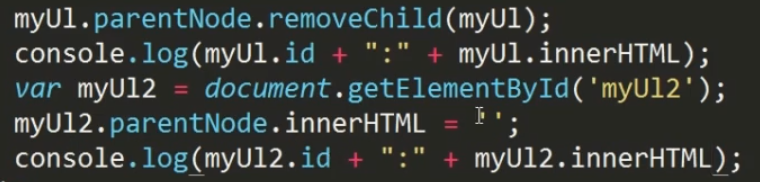
removeChild():删除某个节点中指定的子节点,removeChild()必须有参数,想要删除所有子节点,要遍历每个子节点并删除。
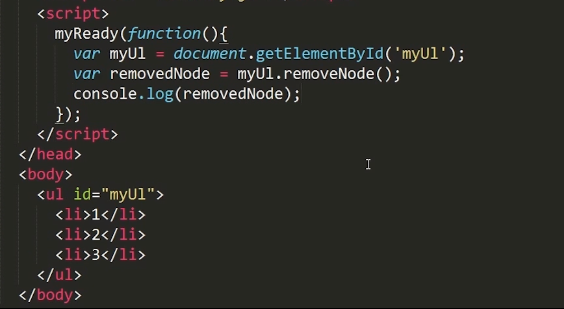
removeNode():IE的私有实现,将目标节点从文档中删除,保留其子节点,返回目标节点,参数是布尔值,默认值是false。如果参数为true,不仅删除父元素也删除子元素
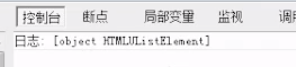

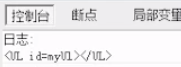

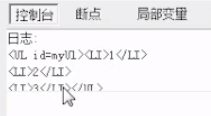
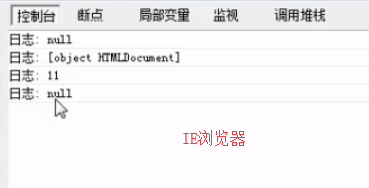
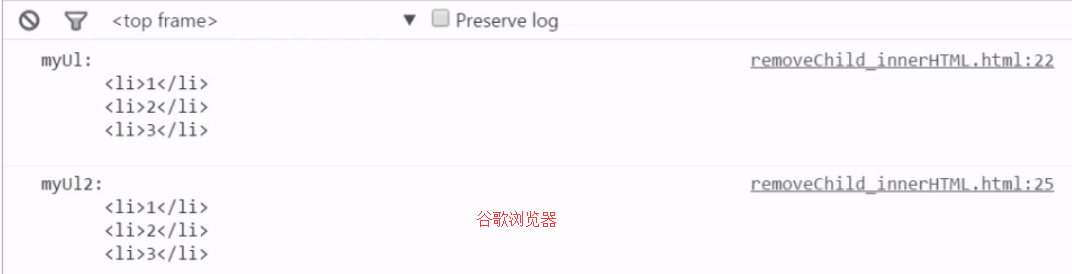
removeChild 和 innerHTML比较
ie6-ie8 的removeChild内容可以重复使用,但是容易造成内存泄漏。 ie6-ie8 removeChild就是掰断树枝,树枝还可以用, ie6-ie8 innerHTML就是掰断树枝,并把树枝烧掉。
Chrome浏览器 两个都是掰断树枝,树枝还可以用。
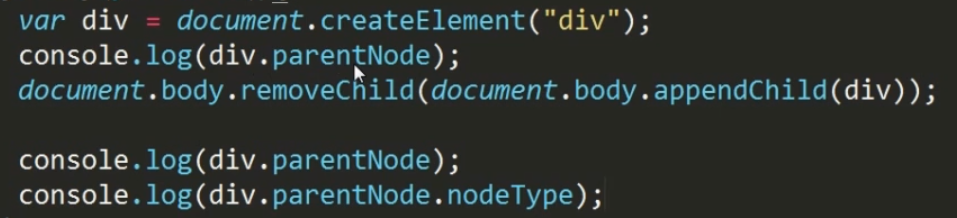
 谷歌浏览器
谷歌浏览器
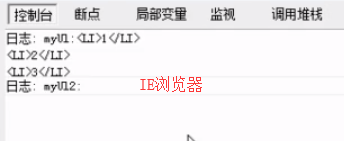
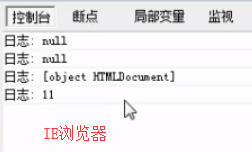 IE还存有文档片段
IE还存有文档片段


总结


 浙公网安备 33010602011771号
浙公网安备 33010602011771号