Pytest自动化发现测试数据并进行数据驱动-支持YAML/JSON/INI/CSV数据文件
需求
- 在测试框架中,往往需要测试数据和代码分离,使用CSV或JSON等数据文件存储数据,使用代码编写测试逻辑
- 一个用例过程往往可以测试多组数据,Pytest原生的参数化往往需要我们自己手动读取数据文件,比较麻烦又略显混乱
- 我们如何能把数据文件按约定的目录和文件名存起来,文件中可以存一组或多组数据,用例自动根据里面的数据进行数据驱动呢?
- 另外,为了灵活,我们尽量可以支持多种数据类型,如YAML/JSON/INI/CSV等
- 是否能仅自动化发现测试数据,不启用数据驱动
约定
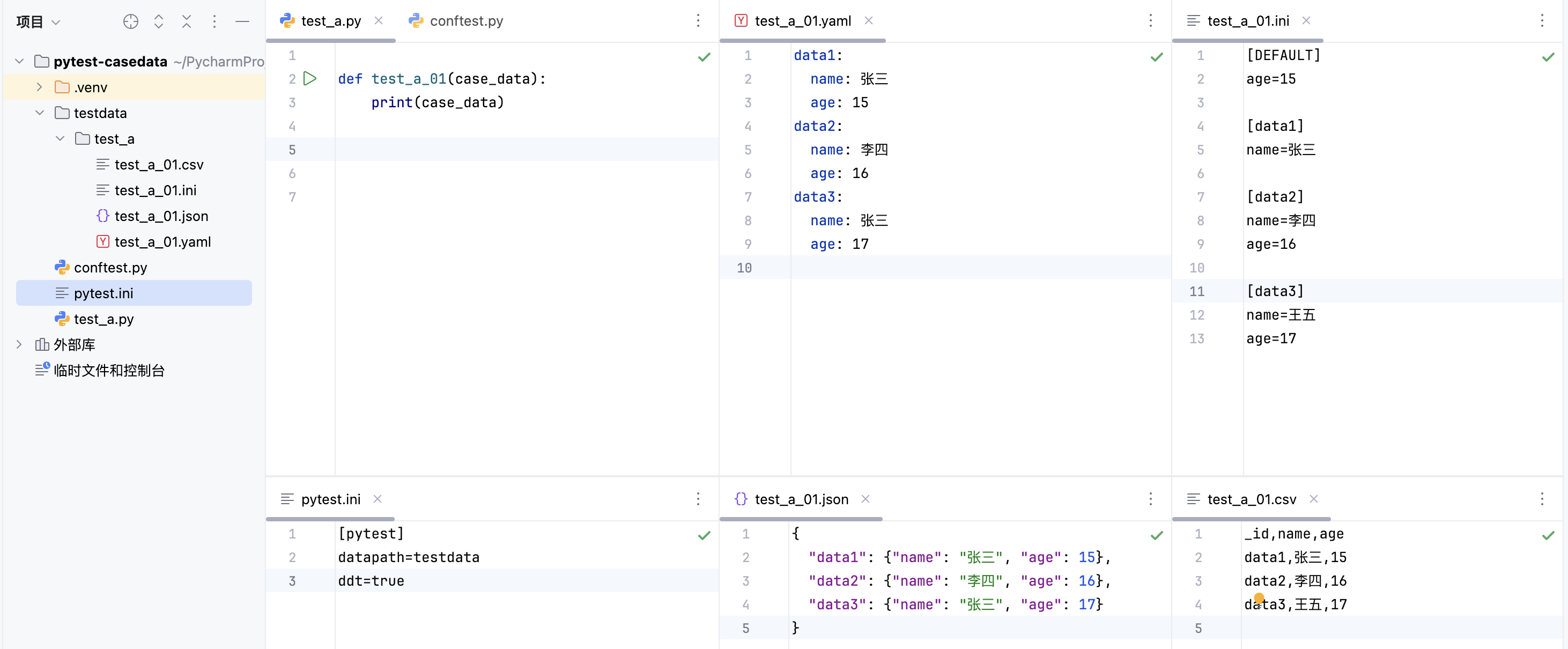
- 我们约定,用例使用
case_data这个fixture时,可以自动获取到用例对应数据,如
# filename: test_a.py
def test_a_01(case_data):
print(case_data)
- 我们添加一个自定义参数和配置项 datapath,设定为测试数据的根目录,添加一个ddt参数和配置项,设置是否启用ddt模式,默认不启用,如
# filename: pytest.ini
[pytest]
datapath=testdata
ddt=true
- 我们约定 测试用例(测试函数)的数据,存放在 测试数据的根目录/测试文件名/目录下 (暂时忽略模块),测试数据文件名(不包含后缀) 必须 与 测试函数名相同,如 test_a.py中test_a_01用例对应数据
testdata/
test_a/
test_a_01.yaml
- 测试数据文件.yaml/.json/.ini/.csv任选一种,同时加载优先级为 .yaml > .json > .ini > .csv
- ini文件 分段名 如
[data1]"为该数据的id标识,并支持自动继承[DEFAULT]段默认数据,如
# filename: test_a_01.ini
[DEFAULT]
age=15
[data1]
name=张三
[data2]
name=李四
age=16
[data3]
name=王五
age=17
- json或yaml文件,如为字典格式,则每个key为该数据的id标识,如为列表格式,每组数据中如果有_id字段,则视为数据id标识,如不包含_id,则数据无id标识,如
# filename: test_a_01.yaml
data1:
name: 张三
age: 15
data2:
name: 李四
age: 16
data3:
name: 张三
age: 17
或
# filename: test_a_01.yaml
- _id: data1
name: 张三
age: 15
- _id: data2
name: 李四
age: 16
- _id: data3
name: 张三
age: 17
- csv文件第一行必须字段标题行,如
name,age,每组数据中如果有_id字段,则视为数据id标识,如不包含_id,则数据无id标识,如
test_a_01.csv
_id,name,age
data1,张三,15
data2,李四,16
data3,王五,17
实现
实现思路:使用pytest hooks方法pytest_generate_tests来根据数据文件内容动态生成用例
所需依赖:pip install pytest filez pyyaml
- 添加自定义配置项
# filename: conftest.py
def pytest_addoption(parser):
# 制定测试数据根目录
parser.addoption("--datapath", action="store", help="testdata dir path")
parser.addini('datapath', help='testdata dir path')
# 是否启用数据驱动
parser.addoption("--ddt", action="store_true", help="enable data driven test for testdata")
parser.addini('ddt', help='enable data driven test for testdata')
- 核心实现
# filename: conftest.py
def pytest_generate_tests(metafunc):
if "case_data" in metafunc.fixturenames:
config = metafunc.config
datapath = config.getoption("--datapath") or config.getini("datapath")
ddt = config.getoption("--ddt") or config.getini("ddt")
# 如果配置的datapath为绝对路径,则直接视为测试数据根目录
if datapath.startswith("/"):
testdata_dir = Path(datapath)
else:
# 如果不是绝对路径则前面添加测试项目根目录
testdata_dir = config.rootdir / datapath
# 用例文件名(不带扩展名),如test_a
testfile_name = metafunc.definition.fspath.purebasename
# 用例函数名,如test_a_01
testcase_name = metafunc.definition.name
# 用例节点id,如test_a.py::test_a_01
testcase_node_id = metafunc.definition.nodeid
# 读取对应数据文件
testcase_csv_datafile = testdata_dir / testfile_name / f'{testcase_name}.csv'
testcase_ini_datafile = testdata_dir / testfile_name / f'{testcase_name}.ini'
testcase_json_datafile = testdata_dir / testfile_name / f'{testcase_name}.json'
testcase_yaml_datafile = testdata_dir / testfile_name / f'{testcase_name}.yaml'
if testcase_yaml_datafile.exists():
# 读取yaml文件
with open(testcase_yaml_datafile) as f:
file_data = yaml.safe_load(f)
elif testcase_json_datafile.exists():
# 读取json文件
file_data = file.load(testcase_json_datafile)
elif testcase_ini_datafile.exists():
# 读取ini文件
file_data = file.load(testcase_ini_datafile)
elif testcase_csv_datafile.exists():
# 读取csv文件-带标题行
file_data = file.load(testcase_csv_datafile, header=True)
else:
return
# 对列表和字典格式数据进行处理
data, ids = None, None
if isinstance(file_data, list):
data = file_data
if len(file_data) > 0 and file_data[0].get('_id'):
ids = [item.get('_id') for item in file_data]
data = [item for item in file_data if item!='_id']
elif isinstance(file_data, dict):
ids = list(file_data.keys())
data = list(file_data.values())
else:
logging.warning(f"测试用例 {testcase_node_id} 数据格式错误, 应为列表或字典格式")
if ddt and isinstance(data, list):
metafunc.parametrize("case_data", data, ids=ids, scope="function")
else: # 不启用ddt时,整体作为一个数据
metafunc.parametrize("case_data", [file_data], scope="function")
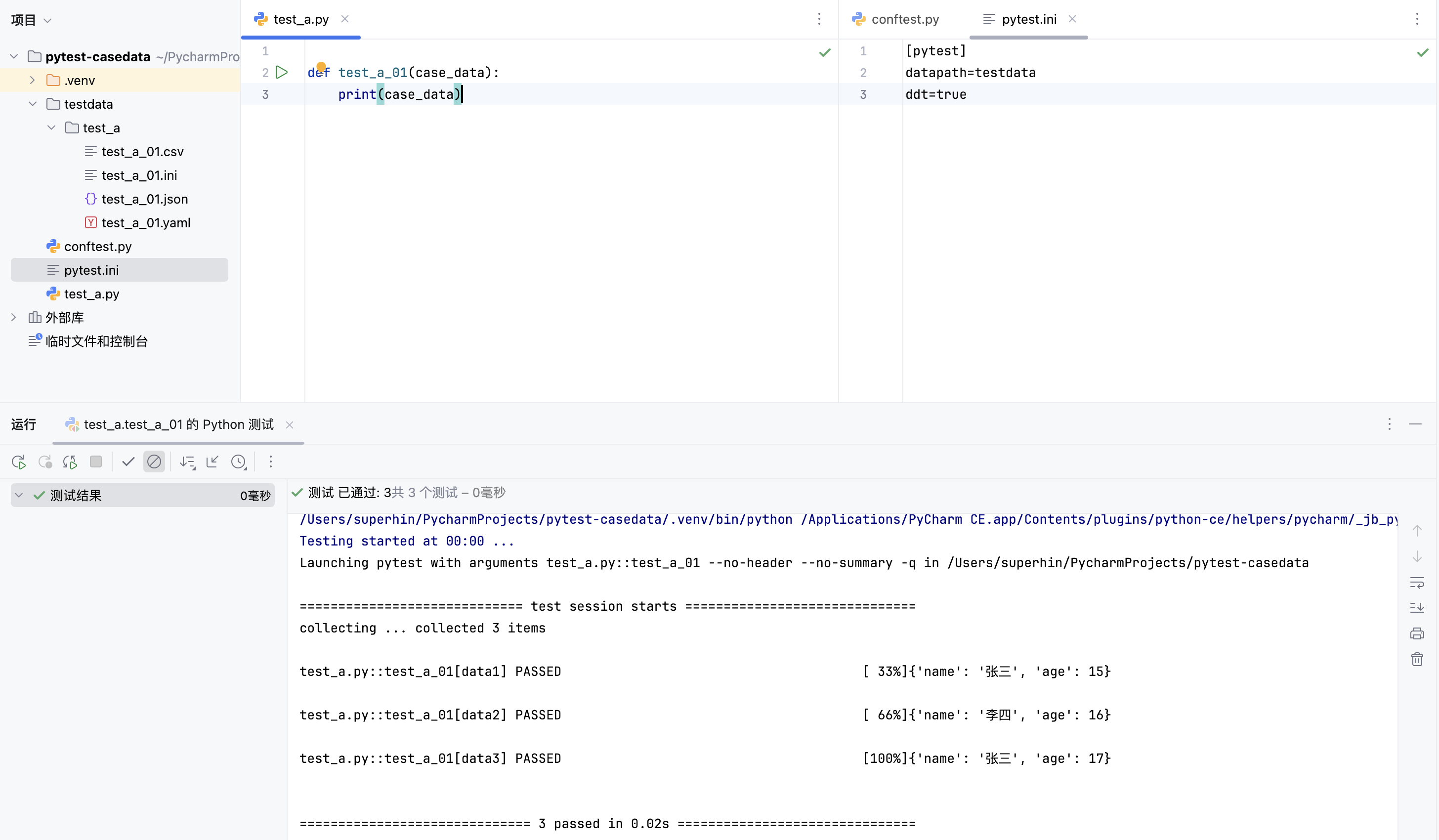
用例运行效果如下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号