基于Excel的接口测试框架的设计与实现
v1.0-循环发送接口
数据格式schema1
文件data.xlsx
| name | method | url | data | headers | verify | result |
|---|---|---|---|---|---|---|
| get请求 | get | https://httpbin.org/get?a=1&b=2 | res.status_code==200 | |||
| post-form | post | https://httpbin.org/post | name=Kevin&age=1 | Content-Type: application/x-www-form-urlencoded | res.status_code == 200 res.json()['form']['name']=='Kevin'] |
|
| post-json | post | https://httpbin.org/post | Content-Type: application/json | |||
| post-xml | post | https://httpbin.org/post | Content-Type: application/xml | result.json()["data"]==" |
格式说明:
- name: 接口测试用例名称
- method: 请求方法,不区分大小写
- url: 完整url,如果有Query参数时,需要写到url里
- data: 原始数据格式(raw data),使用的Content-Type必须在headers声明
- headers: 请求头配置,key, value以冒号分割,每一项一行
- verify: 断言语句, Python表达是格式,支持各种对比方式,res代表requests响应对象
- result: 测试结果
数据格式说明:
- 表单格式:data格式为
name=Kevin&age=1, headers必须添加Content-Type: application/x-www-form-urlencoded - JSON格式:data为JSON格式,headers必须添加
Content-Type: application/json - 其他格式:headers按对应格式添加相应的Content-Type,支持数据为空
功能限制:
- 不支持文件上传(multipart-formdata格式)
- 不支持变量提取和关联
- 仅支持基于Cookie的登录方式,登录接口必须写到第一个
代码实现
- data解析:由于所有data按raw data格式发送,我们无需额外的处理,只需将data转bytes后(已支持data中的非ASCII码)发送即可。
- headers解析:按行分割后,每一项再按冒号分割,组成字典格式
- verify解析:请求得到res变量,使用Python的eval函数进行表达式求值,加上assert语句进行断言
- result判断:发送请求及断言时,使用try-except捕获异常,AssertError视为Fail, 其他异常视为Error,无异常视为Pass
具体实现代码如下
openpyxl和requests需要使用pip安装
pip install openpyxl requests
import openpyxl
import requests
timeout = 60 # 默认请求超时时间
def run_excel(excel_file):
excel = openpyxl.load_workbook(excel_file) # 加载excel
sheet = excel.active # 得到第一张表(Sheet1)
session = requests.session() # 使用session来保留登录后的Cookies(如果有)
session.timeout = timeout # 设置统一超时时间
for index, line in enumerate(sheet.values): # 遍历excel所有行(仅数据)
if index == 0: # 跳过标题行
continue
name, method, url, data, headers, verify, *_ = line # 解包,舍弃第7列以后的值
# 处理请求头
if headers:
try:
headers = {line.split(':')[0].strip(): line.split(':')[1].strip()
for line in headers.split('\n')}
except Exception as ex:
print('请求头格式异常:', ex)
# 处理请求数据,为支持中文数据,需要将文本按utf-8编码为bytes
if data is not None:
data = data.encode('utf-8')
# 发送请求
print(f'请求第{index + 1}行接口: {name}')
try:
res = session.request(method, url, data=data, headers=headers) # 使用同一个session发送请求,以保留过程中的Cookies
except Exception as ex:
result = 'ERROR'
print('请求异常:', ex)
else:
result = 'PASS'
print('响应:', res.text)
# 处理断言
if verify: # 如果存在断言描述
lines = verify.split('\n') # 按行分割转为列表
for line in lines:
if not line: # 跳过空行
continue
try:
assert eval(line) # 使用eval()来计算表达式的值
except AssertionError:
print("断言出错")
result = "FAIL"
break # 该条断言失败后,后面的断言不再执行
except Exception as ex:
print("断言异常:", ex)
result = "ERROR"
break # 该条断言失败后,后面的断言不再执行
finally:
print('执行断言:', line, '结果:', result)
sheet.cell(index + 1, 7).value = result # 在当前行第7列写入结果
excel.save(excel_file) # 保存并覆盖原文件
使用方式如下
# 接上面代码
if __name__ == '__main__':
run_excel('data.xlsx')
优化建议
v1.1-改为面向对象
数据格式schema1
数据格式同上
代码实现
这里设计了两个对象
- TestCase:测试用例,对应Excel的一行数据,类中使用不同的方法来处理各个列的数据,并提供了单条运行的run方法
- Runner:用例运行期,用于批量运行用例,提供加载用例和批量运行的方法
TestCase实现如下:
import openpyxl
import requests
class TestCase:
def __init__(self, index, name, method, url, data, headers, verify, result):
self.index = index
self.name = name
self.method = method
self.url = url
self.data = data
self.headers = headers
self.verify = verify
self.result = result
@staticmethod
def _handle_data(data):
if data is not None:
return data.encode('utf-8')
@staticmethod
def _handle_headers(headers):
if headers:
return {line.split(':')[0].strip(): line.split(':')[1].strip() # todo try
for line in headers.split('\n')}
@staticmethod
def _handle_verify(verify):
if verify:
return [line for line in verify.split('\n') if line.strip()] # 按行分割转为列表
def _send_request(self):
# 发送请求
print(f'请求接口: {self.name}')
data = self._handle_data(self.data)
headers = self._handle_headers(self.headers)
res = requests.request(self.method, self.url, data=data, headers=headers) # todo try
print('响应:', res.text)
return res
def _do_verify(self, res):
result = "PASS"
if self.verify:
lines = self.verify.split('\n') # 按行分割转为列表
for line in lines:
if not line: # 跳过空行
continue
try:
assert eval(line) # 使用eval()来计算表达式的值
except AssertionError:
print("断言出错")
result = "FAIL"
break
except Exception as ex:
print("断言异常:", ex)
result = "ERROR"
break
finally:
print('执行断言:', line, '结果:', result)
return result
def run(self):
res = self._send_request()
result = self._do_verify(res)
return result
Runner实现如下
# 接上面的代码
class Runner:
def __init__(self, excel_file):
self.excel_file = excel_file
def load_testcases(self):
excel = openpyxl.load_workbook(self.excel_file)
self.sheet = excel.active
testcases = []
for index, line in enumerate(self.sheet.values):
if index == 0: # 跳过标题行
continue
testcases.append(TestCase(index, *line))
return testcases
def write_result(self, index, result, result_col=7):
self.sheet.cell(index + 1, result_col).value = result
def run(self):
testcases = self.load_testcases()
for testcase in testcases:
result = testcase.run()
self.write_result(testcase.index, result)
使用方式如下
# 接上面代码
if __name__ == '__main__':
Runner('data.xlsx').run()
v1.2-使用Pytest框架
已知Pytest框架支持收集和运行非.py脚本的用例,官方提供了一个使用YAML文件作为测试用例的例子,
同理,我们有也可以实现基于Excel数据的测试用例。
基于Pytest的好处是可以生成漂亮的HTML报告。
数据格式schema1
数据格式同上
代码实现
# conftest.py文件内容
import openpyxl
import requests
import pytest
def pytest_collect_file(parent, file_path): # 收集用例的钩子方法
if file_path.suffix == '.xlsx' and file_path.name.startswith("test"):
return ExcelFile.from_parent(parent, path=file_path)
class ExcelFile(pytest.File): # Excel文件对象,用于收集用例
def collect(self):
excel = openpyxl.load_workbook(self.path)
sheet = excel.active
for row in sheet.iter_rows(2, values_only=True):
name, *values = row
yield ExcelTest.from_parent(self, name=name, values=values)
class ExcelTest(pytest.Item): # Excel用例对象,对应Excel中的每一行数据
def __init__(self, name, parent, values):
super().__init__(name, parent)
self.values = values
self.verify = None
self.s = requests.Session() # 请求会话,注意self.session是pytest框架的执行会话
def prepare_request(self)->requests.PreparedRequest: # 这里使用了requests的请求准备(先准备好请求,再批量发送)
method, url, data, headers, self.verify, *_ = self.values
if headers:
headers = {line.split(':')[0].strip(): line.split(':')[1].strip()
for line in headers.split('\n')}
if data:
data = data.encode('utf-8')
req = requests.Request(method, url, headers=headers, data=data).prepare() # todo try and timeout
return req
def do_verify(self, **context):
locals().update(context) # 支持注册变量 (这个版本数据格式有吗?)
if self.verify:
lines = self.verify.split('\n') # 按行分割转为列表
for line in lines:
if line:
assert eval(line)
def runtest(self): # 核心实现-用例运行逻辑,方法名必须是runtest
print('运行', self.name, self.values)
req = self.prepare_request()
res = self.s.send(req)
print(res)
self.do_verify(res=res)
命令行运行 python3 -m pytest -vs,运行结果如下:
platform darwin -- Python 3.8.9, pytest-7.1.0, pluggy-1.0.0 -- /Users/superhin/venvs/wkcrm-apitest-yaml/bin/python3
cachedir: .pytest_cache
rootdir: /Users/superhin/Projects/wkcrm-apitest-yaml
collected 4 items
test_data.xlsx::get请求 运行 get请求 ['get', 'https://httpbin.org/get?a=1&b=2', None, None, 'res.status_code==200', None]
<Response [200]>
PASSED
test_data.xlsx::post-form 运行 post-form ['post', 'https://httpbin.org/post', 'name=Kevin&age=1', 'Content-Type: application/x-www-form-urlencoded', "res.status_code==200\nres.json['form']['name']=='Kevin'", None]
<Response [200]>
PASSED
test_data.xlsx::post-json 运行 post-json ['post', 'https://httpbin.org/post', '{"name": "Kevin", "age": 1}', 'Content-Type: application/json', None, None]
<Response [200]>
PASSED
test_data.xlsx::post-xml 运行 post-xml ['post', 'https://httpbin.org/post', '<xml>hello</xml>', 'Content-Type: application/xml', 'res.json()["data"]=="<xml>hello</xml>"', None]
<Response [200]>
PASSED
v1.3-支持数据提取及关联
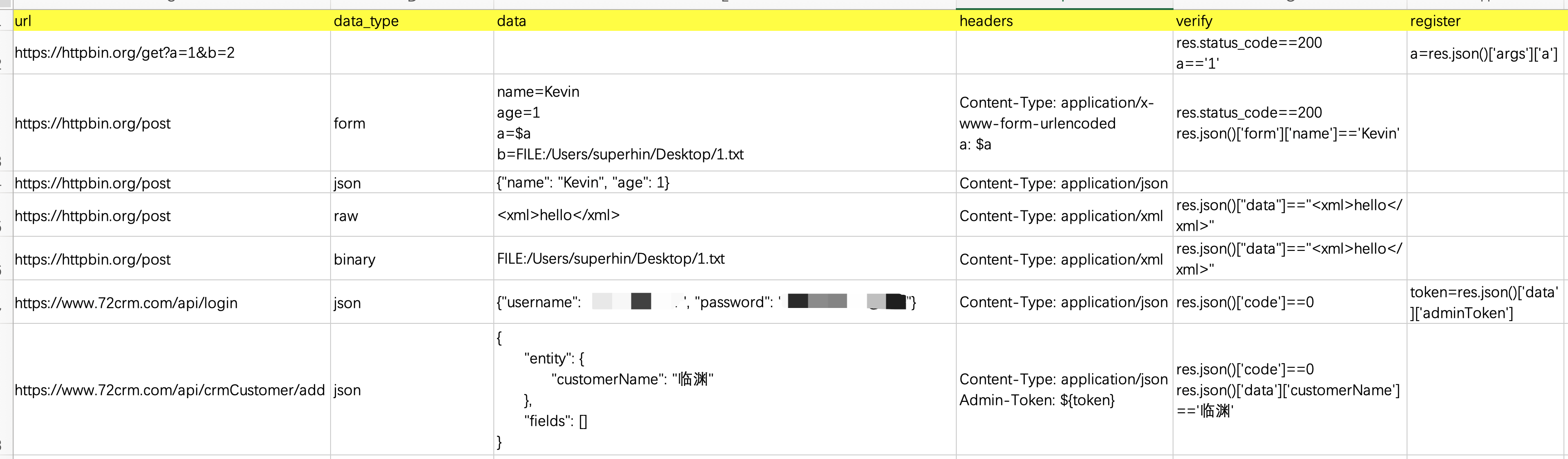
数据格式schema1.1
增加一列register,如下图
| name | method | url | data | headers | verify | register | result |
|---|---|---|---|---|---|---|---|
| get请求 | get | https://httpbin.org/get?a=1&b=2 | res.status_code == 200 a == '1' |
a=res.json()['args']['a'] | |||
| post-form | post | https://httpbin.org/post | name=Kevin&age=1 | Content-Type: application/x-www-form-urlencoded | res.status_code == 200 res.json()['form']['name']=='Kevin'] |
||
| post-json | post | https://httpbin.org/post | Content-Type: application/json | ||||
| post-xml | post | https://httpbin.org/post | Content-Type: application/xml | result.json()["data"]==" |
代码实现
- 使用字典格式的全局变量
context来支持变量提取和引用 - 使用
string.Template().safe_substitute()来支持$变量的替换 - 改为使用
requests.hooks处理请求后步骤(变量提取和断言)
用例收集
# conftest.py文件内容
from string import Template
import openpyxl
import requests
import pytest
context = {}
def pytest_collect_file(parent, file_path):
if file_path.suffix == '.xlsx' and file_path.name.startswith("test"):
return ExcelFile.from_parent(parent, path=file_path)
class ExcelFile(pytest.File):
def collect(self):
excel = openpyxl.load_workbook(self.path)
sheet = excel.active
for row in sheet.iter_rows(2, values_only=True):
name, *values = row
yield ExcelTest.from_parent(self, name=name, values=values)
ExcelTest测试逻辑
# 接上面的代码
class ExcelTest(pytest.Item):
def __init__(self, name, parent, values):
super().__init__(name, parent)
self.values = values
self.s = requests.Session() # 请求会话,注意self.session是pytest框架的执行会话
def send_request(self):
method, url, data, headers, self.verify, self.register, *_ = map(lambda x: Template(x).safe_substitute(context) if isinstance(x, str) else x, self.values)
print('self.register', self.register)
if headers:
headers = {line.split(':')[0].strip(): line.split(':')[1].strip()
for line in headers.split('\n')}
if data:
data = data.encode('utf-8')
res = self.s.request(method, url, headers=headers, data=data, hooks={'response': [self.print_res, self.register_var, self.verify_res]})
return res
def register_var(self, res, *args, **kwargs):
if self.register:
for line in self.register.split('\n'):
key, expr = line.split('=')
context[key.strip()] = eval(expr.strip())
def verify_res(self, res, *args, **kwargs):
locals().update(context)
if self.verify:
for line in self.verify.split('\n'):
if line:
assert eval(line)
def print_res(self, res, *args, **kwargs):
print(res.text)
def runtest(self):
print('运行', self.name, self.values)
self.send_request()
v1.4-添加自定义异常
数据格式schema1.2
代码实现
- 增加了多个自定义异常
- 增加了Excel数据格式合法性检查
- 改为使用json5,支持非严格的JSON格式,json5需要安装,
pip install json5
用例收集
# conftest.py文件内容
import warnings
from string import Template
from collections import ChainMap
import os
import json5
import openpyxl
import requests
import pytest
context = ChainMap({}, os.environ)
ALLOWED_HTTP_METHODS = {'GET', 'POST', 'HEAD', 'PUT', 'DELETE', 'PATCH', 'TRACE', 'OPTIONS'}
ALLOWED_DATA_TYPES = {'FORM', 'JSON', 'RAW', 'BINARY'}
def pytest_collect_file(parent, file_path):
if file_path.suffix == '.xlsx' and file_path.name.startswith("test"):
return ExcelFile.from_parent(parent, path=file_path)
class ExcelFile(pytest.File):
def collect(self):
excel = openpyxl.load_workbook(self.path)
sheet = excel.active
case_name = None
steps = []
for row in sheet.iter_rows(2, values_only=True):
name, *values = row
if name:
steps = [values]
if case_name:
yield ExcelTest.from_parent(self, name=case_name, steps=steps)
case_name = name
else:
steps.append(values)
if case_name:
yield ExcelTest.from_parent(self, name=case_name, steps=steps)
自定义异常
# 接上面的代码
class DataError(Exception):
"""用例数据格式错误"""
class ConfigMissing(Exception):
"""配置缺失"""
class JSON5DecodeError(Exception):
"""JSON5解析出错"""
class FileNotExistError(Exception):
"""文件不存在"""
ExcelTest测试逻辑
# 接上面的代码
class ExcelTest(pytest.Item):
def __init__(self, name, parent, steps):
super().__init__(name, parent)
self.steps = steps
self.s = requests.Session() # 请求会话,注意self.session是pytest框架的执行会话
try:
self.base_url = self.config.getoption('--base-url') or self.config.getini('base_url')
except ValueError:
self.base_url = None # TODO 处理getini异常
def handle_method(self, method):
if not isinstance(method, str) or method.upper() not in ALLOWED_HTTP_METHODS:
raise DataError(f'请求方法:{method} 必须为字符串, 且必须为GET, POST, HEAD, PUT, DELETE, PATCH, TRACE, OPTIONS其中之一')
return method
def handle_url(self, url):
if not isinstance(url, str) or not url.startswith('http') and not url.startswith('/'):
raise DataError(f'接口URL:{url} 必须为字符串, 且必须以http开头或以/开头')
url = self.render(url)
if url.startswith('http'):
return url
if not self.base_url:
raise ConfigMissing('命令行缺失--base-url参数, 或缺失base_url配置')
def handle_data_type(self, data_type):
if not isinstance(data_type, str) or data_type.upper() not in ALLOWED_DATA_TYPES:
raise DataError(f'请求方法:{data_type} 必须为字符串, 且必须为FORM, JSON, RAW, BINARY其中之一') # TODO 处理 data_type为空但data有数据
return data_type
def handle_json_data(self, data):
try:
data = json5.loads(data)
except ValueError:
raise JSON5DecodeError('data数据按JSON5解码转字典或列表出错')
else:
return data
def handle_raw_data(self, data):
return data.encode('utf-8')
def handle_form_data(self, data):
_data, _files = {}, {}
for row in data.split('\n'):
if not row:
continue
try:
key, value = row.split('=', 1)
except ValueError:
raise DataError(f'form格式请求数据行: {row} 应以=号分割')
else:
key, value = key.strip(), value.strip()
if not value.startswith('FILE:'):
_data[key] = value
else:
file_path = value.lstrip('FILE:').strip()
if not os.path.isfile(file_path):
raise FileNotExistError(f'data数据中文件路径:{file_path}不存在')
_files['key'] = open(file_path, 'rb') # todo 三元数组
return _data, _files
def handle_binary_data(self, data):
if not data.startswith('FILE:'):
raise DataError(f'Binary格式data数据:{data} 应以FILE:开头')
file_path = data.lstrip('FILE:').strip()
if not os.path.isfile(file_path):
raise FileNotExistError(f'data数据中文件路径:{file_path}不存在')
return open(file_path, 'rb')
def handle_data(self, data, data_type):
if data is None:
return data
if not isinstance(data, str):
raise DataError('data应为空或字符串')
data = self.render(data.strip())
if data_type is None:
warnings.warn('data_type缺失')
if data.startswith('{') or data.startswith('['):
data_type = 'JSON'
elif '=' in data.split('\n')[0]:
data_type = 'FORM'
elif data.startswith('FILE:'):
data_type = 'BINARY'
else:
data_type = 'RAW'
print(f'使用data_type={data_type}')
if data_type.upper() == 'JSON':
return dict(json=self.handle_json_data(data))
elif data_type.upper() == 'FORM':
data, files = self.handle_form_data(data)
return dict(data=data, files=files)
elif data_type.upper() == 'RAW':
return dict(data=self.handle_raw_data(data))
elif data_type.upper() == 'BINARY':
return dict(data=self.handle_binary_data(data))
else:
raise ValueError('data_type仅支持FORM, JSON, RAW, BINARY其中之一')
def render(self, text):
global context
return Template(text).safe_substitute(context)
def handle_headers(self, headers):
if headers is None:
return headers
if not isinstance(headers, str):
raise DataError('headers应为空或者字符串')
headers = self.render(headers)
_headers = {}
for row in headers.split('\n'):
if not row:
continue
try:
key, value = row.split(':', 1)
except ValueError:
raise DataError(f'form格式请求数据行: {row} 应以:号分割')
else:
_headers[key] = value
def get_request(self, data):
method, url, data_type, data, headers, self.verify, self.register, *_ = data
request = dict(
method = self.handle_method(method),
url = self.handle_url(url),
headers = self.handle_headers(headers)
)
request.update(self.handle_data(data, data_type))
return request
def send_request(self, data):
request = self.get_request(data)
print('发送请求', request)
res = self.s.request(**request,
hooks={'response': [self.print_res, self.register_var, self.verify_res]})
return res
def register_var(self, res, *args, **kwargs):
if self.register:
for line in self.register.split('\n'):
key, expr = line.split('=')
context[key.strip()] = eval(expr.strip())
def verify_res(self, res, *args, **kwargs):
locals().update(context)
if self.verify:
for line in self.verify.split('\n'):
if line:
assert eval(line)
def print_res(self, res, *args, **kwargs):
print(res.text)
def runtest(self):
print('运行', self.name)
for data in self.steps:
self.send_request(data)
优化建议
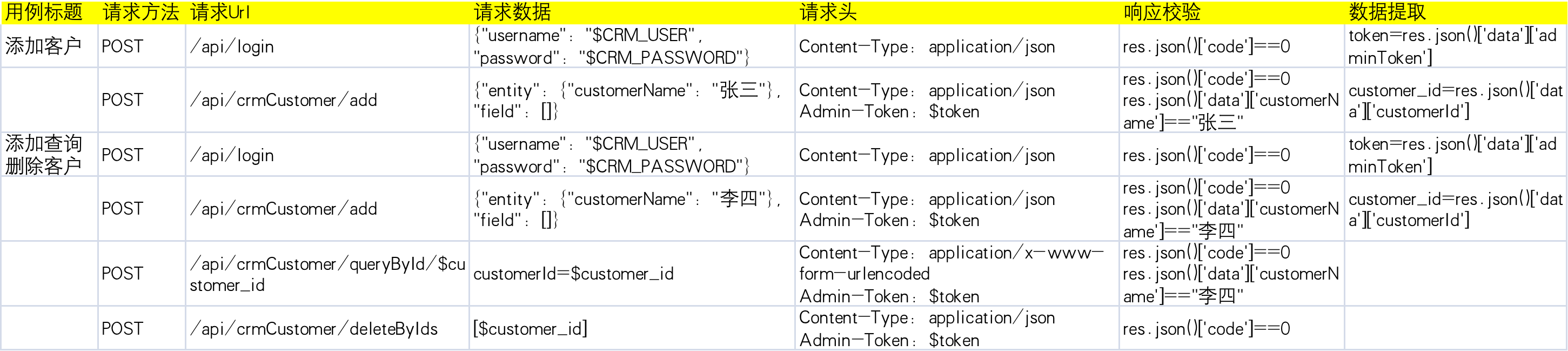
v2.0-改为用例多步骤
数据格式schema2
代码实现
特性及变更
- 支持插件
pytest-base-url来配置base_url - 改为使用
ChainMap并支持使用环境变量
ChainMap(链接字典)是Python内置的模块collections中的一种容器类型,支持添加多个字典,从按顺序从里面查找值,部分操作方式与字典类似
用例收集
# conftest.py文件内容
from string import Template
from collections import ChainMap
import os
import openpyxl
import requests
import pytest
# 用于存储过程中的变量,以实现接口关联
# {},用于注册变量,os.environ是系统环境变量
# 从上下文中取值是,如果从注册的变量中找不到,支持从环境变量中查找
context = ChainMap({}, os.environ)
def pytest_collect_file(parent, file_path):
if file_path.suffix == '.xlsx' and file_path.name.startswith("test"):
return ExcelFile.from_parent(parent, path=file_path)
class ExcelFile(pytest.File):
def collect(self):
excel = openpyxl.load_workbook(self.path)
sheet = excel.active
name = None
case_name = None
steps = []
for row in sheet.iter_rows(2, values_only=True):
name, *values = row
if name:
steps = [values]
if case_name:
yield ExcelTest.from_parent(self, name=case_name, steps=steps)
case_name = name
else:
steps.append(values)
if case_name:
yield ExcelTest.from_parent(self, name=case_name, steps=steps)
ExcelTest测试逻辑
# 接上面的代码
class ExcelTest(pytest.Item):
def __init__(self, name, parent, steps):
super().__init__(name, parent)
self.steps = steps
self.s = requests.Session() # 请求会话,注意self.session是pytest框架的执行会话
self.base_url = self.config.getoption('--base-url') or self.config.getini('base_url')
def send_request(self, values):
method, url, data, headers, self.verify, self.register, *_ = map(
lambda x: Template(x).safe_substitute(context) if isinstance(x, str) else x, values)
if not url.startswith('http') and self.base_url:
url = f'{self.base_url}{url}'
if headers:
headers = {line.split(':')[0].strip(): line.split(':')[1].strip()
for line in headers.split('\n')}
if data:
data = data.encode('utf-8')
print('发送请求', url, headers, data)
res = self.s.request(method, url, headers=headers, data=data,
hooks={'response': [self.print_res, self.register_var, self.verify_res]})
return res
def register_var(self, res, *args, **kwargs): # 提取变量并存储到context中
if self.register:
for line in self.register.split('\n'):
key, expr = line.split('=')
context[key.strip()] = eval(expr.strip())
def verify_res(self, res, *args, **kwargs):
locals().update(context) # 将上下文变量更新到局部变量中,在eval时可以引用到
if self.verify:
for line in self.verify.split('\n'):
if line:
assert eval(line)
def print_res(self, res, *args, **kwargs):
print(res.text)
def runtest(self):
print('运行', self.name)
for values in self.steps:
self.send_request(values)
运行方法
需要在www.72crm.com申请用户,并开通组织(示例数据中的接口已变更-请更换为自己的接口)- 在命令行运行
CRM_USER=你的用户名 CRM_PASSWORD=你的密码 python3 -m pytest -qs --base-url=https://www.72crm.com
也可配合pytest-html或allure-pytest生成报告
pip install allure-pytest并下载 allure-commandline工具并配置PATH后
运行
CRM_USER=你的用户名 CRM_PASSWORD=你的密码 python3 -m pytest -q --base-url=https://www.72crm.com --alluredir=allure-results
allure server allure-results
显示报告如下
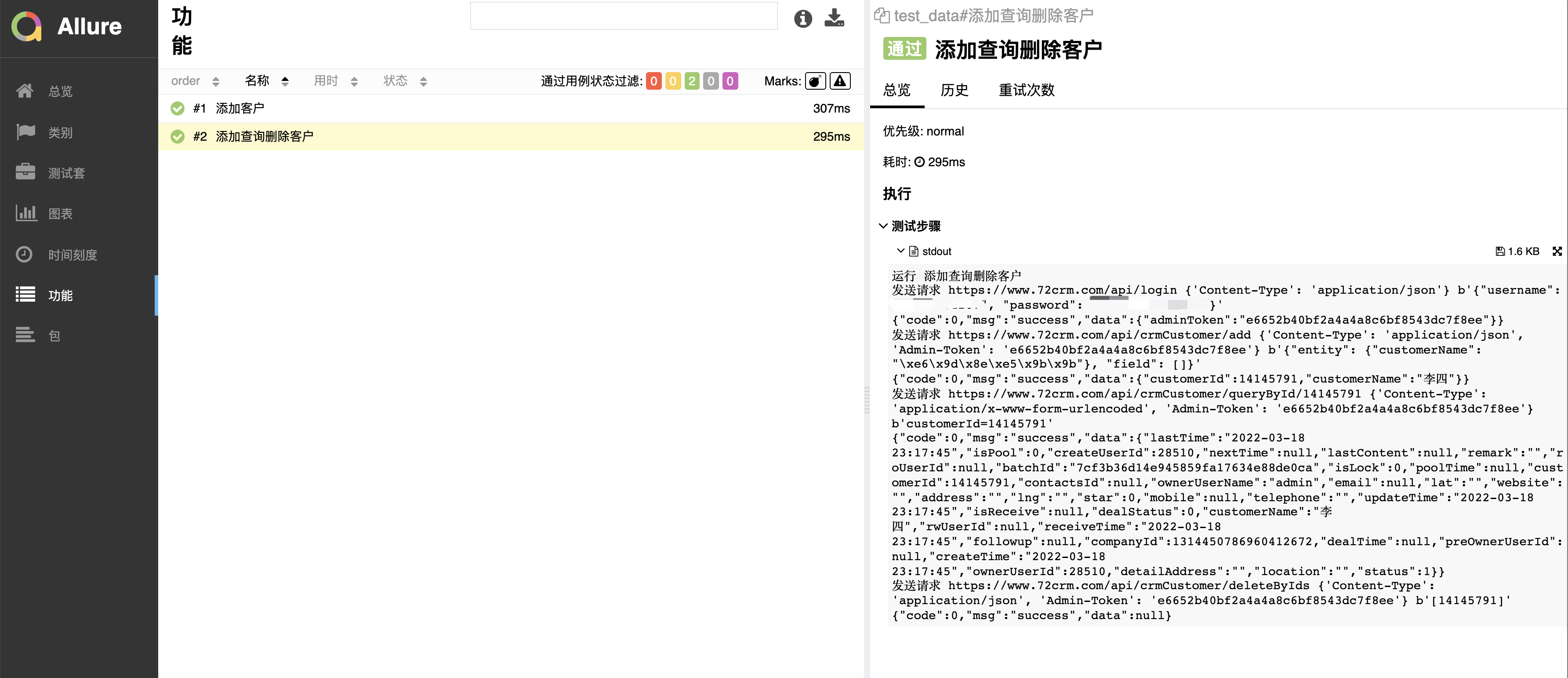
已知问题
- 每个用例都需要编写登录步骤
- 单元格中编写JSON没有提示非常容易出错
- 响应断言
res.json()['code']==0这种形式书写较麻烦 - 步骤不支持命名
优化建议

 浙公网安备 33010602011771号
浙公网安备 33010602011771号