Python自动化测试面试题-MySQL篇
SQL查询
tb1表,字段name,chinese,math,english,求平均分 > 60的人的姓名
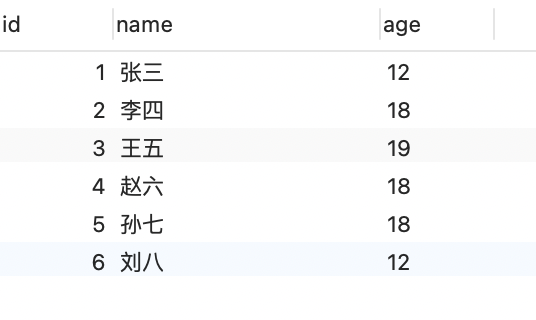
参考答案
SELECT name FROM tb3 WHERE chinese + math + english > 180;
tb2表,字段为name, class, score,查询平均分大于60分的班级
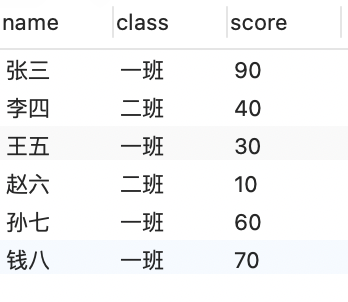
解析:
- 按class进行分组
- 使用having结合聚合函数avg取平均数>60的
参考答案
SELECT class FROM tb2 GROUP BY class HAVING AVG(score) > 60;
tb3表,字段为,id,name,age,查询 相同年龄,人数最多的age

解析:
- 使用GROUP BY按age进行分组
- 使用聚合函数COUNT计数,并赋予别名num
- 使用ORDER BY按计数结果num进行DESC降序排列
- 使用LIMIT取第一条数据
参考答案
SELECT age, COUNT(age) as num from tb3 GROUP BY age ORDER BY num DESC LIMIT 1;
tb4表,字段name,course,score,查询平均成绩大于60的学生
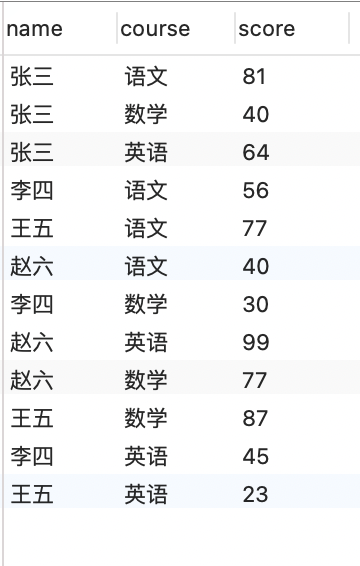
解析
- 按name进行分组
- 使用having结合聚合函数avg取平均数>60的
参考答案
SELECT name, AVG(score) FROM tb4 GROUP BY name HAVING AVG(score) > 60;
查询1课程比2课程高的所有学生的学号
查询所有学生的学号/姓名/选课数/总成绩
查询没有学完所有课程的学生学号,姓名
MySQL查询消费大于1000的用户
MySQL索引
MySQL有几种索引
MySQL支持多种类型的索引,常见的索引类型包括:
-
B-Tree索引:B-Tree(平衡树)索引是MySQL中最常用的索引类型。它适用于等值查询、范围查询和排序操作。B-Tree索引适用于大多数场景,包括单列索引、组合索引和唯一索引。
-
哈希索引:哈希索引适用于等值查询,但不支持范围查询和排序操作。哈希索引将索引列的值通过哈希函数映射到一个哈希表中,可以快速定位到具体的数据行。但是,哈希索引不适用于范围查询和模糊查询。
-
全文索引:全文索引用于全文搜索,适用于对文本内容进行关键字搜索的场景。全文索引可以提供更高级的搜索功能,如关键字匹配、模糊搜索和排序。
-
空间索引:空间索引用于处理地理空间数据,如地理位置坐标。它支持空间数据类型和空间函数,可以进行空间范围查询和距离计算。
-
前缀索引:前缀索引是指只对索引列的前缀部分进行索引,而不是整个列。它可以减少索引的存储空间,但可能会影响查询的性能。
-
其他特殊索引:MySQL还支持其他一些特殊类型的索引,如全文空间索引、JSON索引等,用于特定的数据类型和查询需求。
根据具体的业务需求和查询模式,选择合适的索引类型非常重要。通常,使用B-Tree索引是最常见和通用的选择,但在特定场景下,其他类型的索引也可以提供更好的性能和功能。
MySQL索引原理
MySQL索引是一种数据结构,用于加快数据库查询操作的速度。索引基于B-Tree(平衡树)或哈希表等数据结构实现,它们允许快速定位和访问存储在数据库表中的数据。
MySQL索引的原理如下:
- B-Tree索引原理:
- B-Tree是一种平衡树结构,它具有多个层级,每个层级都有多个节点。根节点位于最上层,叶子节点位于最下层。
- 每个节点包含多个键值对,其中键是索引列的值,值是指向对应数据行的指针。
- B-Tree索引按照键的顺序进行排序,使得查询时可以使用二分查找的方式快速定位到目标数据。
- B-Tree索引支持等值查询、范围查询和排序操作,它可以有效地减少查询的数据访问量。
- 哈希索引原理:
- 哈希索引使用哈希函数将索引列的值映射到一个哈希表中的槽位。
- 哈希表是一个数组,每个槽位存储一个指针,指向对应数据行的位置。
- 哈希索引通过哈希函数的计算,可以快速定位到目标数据行,具有O(1)的查询时间复杂度。
- 哈希索引适用于等值查询,但不支持范围查询和排序操作。
MySQL索引的工作原理如下:
-
创建索引:当在表的列上创建索引时,MySQL会根据索引类型(如B-Tree或哈希)创建相应的数据结构,并将索引列的值和对应的指针存储在索引结构中。
-
查询优化器:当执行查询语句时,MySQL的查询优化器会分析查询语句和表的结构,决定使用哪个索引来执行查询。优化器会考虑索引的选择性、列的顺序、查询条件等因素,选择最优的索引。
-
索引扫描:当使用索引执行查询时,MySQL会根据索引的数据结构进行索引扫描。对于B-Tree索引,MySQL会根据查询条件的范围进行二分查找,定位到目标数据行。对于哈希索引,MySQL会通过哈希函数计算,直接定位到目标数据行。
-
数据访问:一旦定位到目标数据行,MySQL会使用指针获取对应的数据,并返回给查询结果。
需要注意的是,索引的创建和维护会带来一定的开销,包括存储空间和写操作的性能。因此,需要根据具体的业务需求和查询模式,合理选择和使用索引,以平衡查询性能和存储开销。
MySQL索引是如何支持百万级别查询的
MySQL索引是基于B+树的,B+树是类似与跳表的一种数据结构,查询效率为log(N)。
MySQL引擎,哪个读的快,哪个写的快
- MyISAM:读取快
- InoDB:基于聚簇索引,数据和叶子结点在一起,支持事务,行级锁。插入快,适合频繁修改的场景。
- Memory
MySQL索引为什么不能过多也不能太少
MySQL索引的数量需要适度,既不能过多也不能太少,这是为了平衡查询性能和存储空间的考虑。
如果索引过多,会导致以下问题:
-
存储空间占用:每个索引都需要占用额外的存储空间。如果索引过多,会增加数据库的存储需求,占用更多的磁盘空间。
-
写操作性能下降:每次对表进行插入、更新或删除操作时,都需要更新索引。如果索引过多,写操作的性能会下降,因为需要更新更多的索引。
-
查询优化器的选择困难:查询优化器在决定使用哪个索引来执行查询时,需要考虑多个索引的选择。如果索引过多,查询优化器的选择过程会变得复杂,可能导致性能下降。
另一方面,如果索引太少,会导致以下问题:
-
查询性能下降:没有足够的索引可能导致查询的性能下降。查询需要扫描更多的数据行,而不是直接使用索引进行快速定位,从而增加了查询的时间复杂度。
-
数据库负载增加:缺乏索引可能导致数据库的负载增加。查询需要扫描更多的数据行,消耗更多的CPU和内存资源,降低整体的数据库性能。
因此,为了平衡查询性能和存储空间的需求,需要根据具体的业务场景和查询模式来合理选择和创建索引。需要根据经验和性能测试来评估索引的效果,并根据实际情况进行调整和优化。
数据库优化思路
数据库优化是提高数据库性能和效率的过程。以下是一些常见的数据库优化思路:
-
索引优化:合理创建和使用索引可以提高查询性能。分析常用的查询语句,确定需要的索引类型和字段,并避免创建过多或不必要的索引。定期检查索引的使用情况,进行索引重建或删除不需要的索引。
-
查询优化:优化查询语句可以减少数据库的负载和提高查询性能。使用合适的查询语法和操作符,避免使用全表扫描和不必要的连接操作。使用EXPLAIN语句分析查询计划,优化查询的执行路径。
-
看数据库设计优化:合理的数据库设计可以提高查询和操作的效率。使用适当的数据类型和字段长度,避免冗余和重复数据。规范化和反规范化的选择要根据具体的业务需求和查询模式进行权衡。
-
缓存优化:使用缓存技术可以减少对数据库的访问,提高响应速度。常见的缓存技术包括数据库查询缓存、应用程序级缓存、分布式缓存等。根据业务需求和数据更新频率,选择合适的缓存策略和缓存工具。
-
硬件优化:合理配置和优化数据库服务器的硬件资源可以提高数据库性能。增加内存容量,优化磁盘和网络配置,调整数据库参数等都可以对性能产生影响。
-
定期维护和监控:定期进行数据库维护和监控是保持数据库性能的关键。包括备份和恢复、数据清理、统计信息收集、日志管理等。监控数据库的性能指标,如CPU利用率、内存使用、磁盘IO等,及时发现和解决性能问题。
-
并发控制和事务管理:合理管理并发访问和事务操作可以提高数据库的并发性和数据一致性。使用适当的锁机制、事务隔离级别和并发控制策略,避免死锁和数据冲突。
数据库优化是一个持续的过程,需要根据实际情况进行分析、调整和优化。通过综合考虑索引、查询、设计、缓存、硬件、维护和并发控制等方面的优化,可以提高数据库的性能和效率。
慢查询如何优化
事务
什么是事务
事务是指一系列相关的操作或活动,通常作为一个整体来执行,要么全部成功完成,要么全部回滚到初始状态,以确保数据的一致性和完整性。
事务的4大特性ACID
-
原子性(Atomicity):事务是一个原子操作单元,要么全部执行成功,要么全部回滚到初始状态。如果事务中的任何一部分操作失败,整个事务将被回滚,以保持数据的一致性。
-
一致性(Consistency):事务在执行前后,数据库的状态必须保持一致。这意味着事务的执行不会破坏数据库的完整性约束和业务规则。
-
隔离性(Isolation):事务的执行应该与其他并发事务相互隔离,以防止数据的不一致性。并发事务之间应该相互独立,不会相互干扰或影响彼此的结果。
-
持久性(Durability):一旦事务成功提交,其结果应该永久保存在数据库中,即使在系统故障或崩溃的情况下也是如此。这确保了数据的持久性和可靠性。
什么是分布式事务
分布式事务是指涉及多个独立的计算机系统或数据库的事务操作。在分布式系统中,每个计算机系统或数据库都可以独立执行事务,但这些事务可能需要保持一致性和原子性。
为了实现分布式事务,通常使用一些协调机制和协议,如两阶段提交(Two-Phase Commit,2PC)、三阶段提交(Three-Phase Commit,3PC)、补偿事务(Compensating Transaction)等。这些机制和协议用于确保所有参与的系统或数据库在事务执行期间保持一致,并在需要时进行回滚或恢复。
分布式事务的设计和实现需要考虑网络延迟、故障恢复、并发访问等因素,以确保事务的正确性和可靠性
分布式节点的接入和一致性
- 分布式节点的接入:当新的节点加入分布式系统时,需要确保其能够正确地与其他节点进行通信和协作。以下是一些常见的方法和技术:
-
注册和发现:新节点可以通过注册自身的信息,如IP地址、端口号等,使其他节点能够发现和连接它。常见的注册和发现机制包括服务注册中心、DNS等。
-
节点间通信:节点之间需要建立可靠的通信渠道,以便进行消息传递和协作。常见的通信协议包括HTTP、TCP/IP、消息队列等。
-
负载均衡:为了平衡节点的负载和提高系统的可扩展性,可以使用负载均衡技术,将请求分发到不同的节点上。常见的负载均衡策略包括轮询、最少连接等。
- 分布式节点的一致性:在分布式系统中,节点之间的数据一致性是一个重要的问题。当多个节点同时对数据进行读写操作时,需要确保数据的一致性。以下是一些常见的方法和技术:
-
一致性协议:使用一致性协议来确保节点之间的数据一致性。常见的一致性协议包括两阶段提交(2PC)、三阶段提交(3PC)、Paxos、Raft等。
-
数据复制:将数据复制到多个节点上,以提高数据的可用性和容错性。常见的数据复制策略包括主从复制、多主复制等。
-
时钟同步:节点之间的时钟同步是保证分布式系统一致性的关键。通过使用时钟同步协议,可以确保节点之间的时间一致性,以便进行正确的时间戳和顺序处理。
-
冲突解决:当多个节点同时对数据进行写操作时,可能会发生冲突。使用冲突解决策略,如乐观锁、悲观锁、版本控制等,可以解决冲突并保持数据的一致性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号