Requests从入门到进阶
特点
- Keep-Alive & 连接池
- 国际化域名和 URL
- 带持久 Cookie 的会话
- 浏览器式的SSL认证
- 自动内容解码
- 基本/摘要式的身份认证
- 优雅的key/value Cookie
- 自动解压
- Unicode 响应体
- HTTP(S) 代理支持
- 文件分块上传
- 流下载
- 连接超时
- 分块请求
- 支持 .netrc
缺点:
- 同步阻塞模式,不支持异步和协程
- 尚不支持HTTP2.0
官方文档:https://requests.readthedocs.io/zh_CN/latest/
安装
通过pip命令安装即可:pip install requests
发送请求
发送GET请求
使用requests发送请求,只要使用request.get(url)方法填入对应的接口地址即可,支持携带URL参数。调用方法返回响应对象,可以通过响应对象的status_code、text、headers等属性,来获取状态码、响应文本和响应头等数据,示例如下。
import requests
res = requests.get('https://httpbin.org/get?name=临渊&age=18')
print('状态码', res.status_code)
print('响应文本', res.text)
print('响应头', res.headers)
URL只支持ASCII(美国标准码),在实际的传输过程中,中文及一些特殊字符需要经过urlencode(URL编码)。如上例中的接口地址会被编码成:
https://httpbin.org/get?name=%E4%B8%B4%E6%B8%8A&age=18
requests在发送请求时会自动进行编码,运行后显示如下。
状态码 200
响应文本 {
"args": {
"age": "18",
"name": "\u4e34\u6e0a"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.4"
},
"origin": "111.194.126.253, 111.194.126.253",
"url": "https://httpbin.org/get?name=\u4e34\u6e0a&age=18"
}
响应头 {'Access-Control-Allow-Credentials': 'true', 'Access-Control-Allow-Origin': '*', 'Content-Encoding': 'gzip', 'Content-Type': 'application/json', 'Date': 'Mon, 20 Jan 2020 02:33:47 GMT', 'Referrer-Policy': 'no-referrer-when-downgrade', 'Server': 'nginx', 'X-Content-Type-Options': 'nosniff', 'X-Frame-Options': 'DENY', 'X-XSS-Protection': '1; mode=block', 'Content-Length': '222', 'Connection': 'keep-alive'}
使用Params
Params又叫Query Params,即URL参数,如?name=临渊&age=18。如果参数很多,直接写到URL中会比较长,不方便查看和修改。URL参数由多组键值对组成。可以通过字典传给requests请求放到的params参数,即request.get(url, params={}),示例如下。
import requests
res = requests.get('https://httpbin.org/get', params={'name': '临渊', 'age': '18'})
print('响应文本转为字典', res.json())
由于参数可能较多,一般我们可以使用变量,先把url及参数等数据组装好,然后在传入请求方法中。
res.json()方法实际上是使用了json.loads(res.text)将响应文本尝试以JSON格式转为字典。由于该方法存在异常(比如正常情况下返回JSON格式,500报错时则会返回非JSON格式的报错信息),建议使用try...except处理,修改如下。
import requests
url = 'https://httpbin.org/get'
url_params = {'name': '临渊', 'age': '18'}
res = requests.get(url, params=url_params)
try:
print('响应文本转为字典', res.json())
except:
print('响应文本', res.text)
url_params是自定义的变量名,一般笔者习惯使用params作为变量名,来表示和请求方法参数params的对应关系。即
params = {'name': '临渊', 'age': '18'}
res = requests.get(url, params=params)
运行结果如下。
响应文本转为字典 {'args': {'age': '18', 'name': '临渊'}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.18.4'}, 'origin': '111.194.126.253, 111.194.126.253', 'url': 'https://httpbin.org/get?name=临渊&age=18'}
使用请求头
请求头是链接和请求数据的一些辅助说明信息,常见的请求头有:
- Accept:客户端能接受的内容类型
- Accept-Charset:浏览器可以接受的字符编码
- Accept-Encoding:浏览器可以支持的压缩编码类型
- Accept-Languge:浏览器可以接受的语言
- Referer:连接来路
- User-Agent:发送请求的客户端信息
- Connection:连接类型(Keepalive保持连接/Close关闭连接)
- X-Requested-With:XMLHttpRequest(是Ajax异步请求)
- Cookie:服务器标记信息
- Cache-Control:缓存机制(no-cache无缓存或max-age=缓存保存时间)
- Expries:缓存过期时间
- Content-Type:内容类型(MIME类型)
- Content-Length:数据长度
请求头项一般不区分大小写。Cookie是请求头的一项(注意为单数形式,不带s)。因此在请求一些需要登录状态的接口时可以手动抓取到Cookie,放到请求头中使用,示例如下。
(1)手动登录后,通过Chrome开发者工具抓取请求正常访问时的请求头信息。
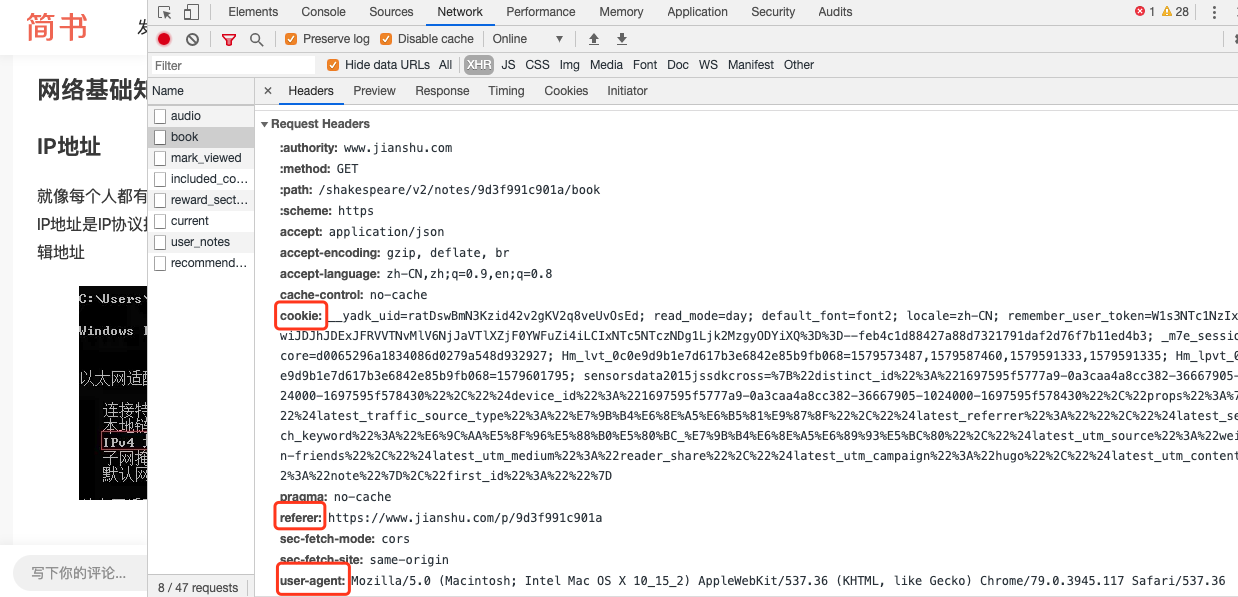
请求头中一般cookie用于验证登录,referer用于防止盗链,user-agent用于反爬。
(2)组装字典格式的请求头并使用
请求头一般有一组组键值对组成,我们同样使用Python中的的字典格式,构造出请求头数据,并传递给请求方法的headers参数即可。
import requests
url = 'https://www.jianshu.com/shakespeare/v2/notes/9d3f991c901a/book'
headers = {
'user-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36',
'referer': 'https://www.jianshu.com/p/9d3f991c901a',
'cookie': '__yadk_uid=ratDswBmN3Kzid42v2gKV2q8veUvOsEd; read_mode=day; default_font=font2; locale=zh-CN; remember_user_token=W1s3NTc1NzIxXSwiJDJhJDExJFRVVTNvMlV6NjJaVTlXZjF0YWFuZi4iLCIxNTc5NTczNDg1Ljk2MzgyODYiXQ%3D%3D--feb4c1d88427a88d7321791daf2d76f7b11ed4b3; _m7e_session_core=d0065296a1834086d0279a548d932927; Hm_lvt_0c0e9d9b1e7d617b3e6842e85b9fb068=1579573487,1579587460,1579591333,1579591335; Hm_lpvt_0c0e9d9b1e7d617b3e6842e85b9fb068=1579601795; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221697595f5777a9-0a3caa4a8cc382-36667905-1024000-1697595f578430%22%2C%22%24device_id%22%3A%221697595f5777a9-0a3caa4a8cc382-36667905-1024000-1697595f578430%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_utm_source%22%3A%22weixin-friends%22%2C%22%24latest_utm_medium%22%3A%22reader_share%22%2C%22%24latest_utm_campaign%22%3A%22hugo%22%2C%22%24latest_utm_content%22%3A%22note%22%7D%2C%22first_id%22%3A%22%22%7D'
}
res = requests.get(url, headers=headers)
print(res.text)
headers=headders第一个headers是请求方法的固定参数,第二个headers是我们自定义的字典变量(变量也可以使用其他名称),执行后打印信息如下。
{"notebook_id":26739010,"notebook_name":"Python接口测试","liked_by_user":false}
注:本例中请求头实际并没有登录限制,只需要在请求头添加了
user-agent即可正常使用。
使用Cookies
Cookies可以作为一个整体的字符串放到请求头的Cookie字段中,当Cookies很多并且需要组装时,使用字符串会比较长并难以维护。此时可以将Cookies拆开成一组组键值对,构造为字典格式的数据,传递给请求方法的cookies参数,示例如下。
import requests
url = 'https://www.jianshu.com/shakespeare/v2/notes/9d3f991c901a/book'
headers = {
'user-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36',
'referer': 'https://www.jianshu.com/p/9d3f991c901a',
}
cookies = {'Hm_lpvt_0c0e9d9b1e7d617b3e6842e85b9fb068': '1579601795',
'Hm_lvt_0c0e9d9b1e7d617b3e6842e85b9fb068': '1579573487,1579587460,1579591333,1579591335',
'__yadk_uid': 'ratDswBmN3Kzid42v2gKV2q8veUvOsEd',
'_m7e_session_core': 'd0065296a1834086d0279a548d932927',
'default_font': 'font2',
'locale': 'zh-CN',
'read_mode': 'day',
'remember_user_token': 'W1s3NTc1NzIxXSwiJDJhJDExJFRVVTNvMlV6NjJaVTlXZjF0YWFuZi4iLCIxNTc5NTczNDg1Ljk2MzgyODYiXQ%3D%3D--feb4c1d88427a88d7321791daf2d76f7b11ed4b3',
'sensorsdata2015jssdkcross': '%7B%22distinct_id%22%3A%221697595f5777a9-0a3caa4a8cc382-36667905-1024000-1697595f578430%22%2C%22%24device_id%22%3A%221697595f5777a9-0a3caa4a8cc382-36667905-1024000-1697595f578430%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_utm_source%22%3A%22weixin-friends%22%2C%22%24latest_utm_medium%22%3A%22reader_share%22%2C%22%24latest_utm_campaign%22%3A%22hugo%22%2C%22%24latest_utm_content%22%3A%22note%22%7D%2C%22first_id%22%3A%22%22%7D'
}
res = requests.get(url, headers=headers, cookies=cookies)
print(res.text)
注:Cookies中不能拥有非ASCII字符,中文应进行URL编码后使用。
同名参数处理:
假设url中具有同名参数,如name=临渊,age=18,age=30。由于字典中不能存在同名的键,我们可以使用嵌套列表实现。示例如下。
params = [('name','临渊'), ('age', '18'), ('age', '30')]
请求方法中的其他参数,如data、headers等,如果存在同名变量也可以这样处理。
发送POST请求
POST方法和GET方法本质上一样的,都是HTTP请求的一种请求动作。只是通常情况下GET请求不使用请求体数据,而POST使用。既然POST方法会发送请求体数据,就会涉及到数据类型的问题。客户端和服务端商量好,才能正常的解析和通讯。这种数据类型又称为媒体类型,标准称法为MIME(Multipurpose Internet Mail Extensions)类型,即多用途互联网邮件扩展类型。数据类型的声明,一般放在请求头(请求辅助信息)的Content-Type字段中,常见的有以下几种格式。
- application/x-www-form-url-encoded:表单URL编码格式
- multipart/form-data:复合表单格式(支持文件上传,文件二进制
- application/json:JSON格式
- application/xml:XML格式
不同数据类型的请求,数据组装方式也不同,至于什么时候用表单,什么时候用JSON格式要看接口文档或问开发小哥哥,接口在编写时便已确定好了需要使用的的数据(媒体)类型。
发送POST请求使用requests的post方法即可,格式如下。
res = requests.post(url,data={}, json={}, files={})
data、json、files都是可选参数(一般同时只用其中一个)。分别用来将数据按不同格式编码发送。
- data参数接受字典时将数据按普通表单(application/x-www-form-url-encoded)格式发送。
- json参数存在时将字典格式的请求数据按JSON格式(application/json)发送
- files参数将字典格式的请求数据(可以包含打开的文件)按混合表单(multipart/form-data)格式发送。
同时使用三者之一时,会自动在请求头中添加对应的内容类型声明Content-Type:...。
当data参数接受字符串格式的参数是按Raw原始格式发送,不进行编码和添加请求头。当data参数接受文件对象时按binary二进制格式发送。
发送FORM表单格式数据
Form表单指网页中包含输入框、选择框、按钮等组成的一组用户填写及选择的数据。如登录、注册表单。表单是最常用的一种请求数据类型,对应的请求头媒体类型声明:Content-Type:application/x-www-form-urlencoded。
之所以称为urlencoded,是因为,请求体数据,实际会按url编码格式发送,如name=临渊,password=123456实际上会编码为
name=%E4%B8%B4%E6%B8%8A&password=123456作为请求体数据,后台传输。
表单类型的参数同样是由多组键值对组成,我们同样适用字典格式构造请求体数据并传递给请求方法的data参数即可,示例如下。
import requests
url = 'https://httpbin.org/post'
data = {'name': '临渊', 'password': '123456'}
res = requests.post(url, data=data)
print(res.text)
发送POST请求只要使用requests.post()方法即可,方法中的data=data,第一个data是请求方法的一个固定的关键字参数,后面的data是上面我自定义的变量,即{'name': '临渊', 'password': '123456'},使用其他变量名可以。打印结果如下。
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "\u4e34\u6e0a",
"password": "123456"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "39",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.4"
},
"json": null,
"origin": "111.194.126.253, 111.194.126.253",
"url": "https://httpbin.org/post"
}
发送时,请求头中会自动添加"Content-Type": "application/x-www-form-urlencoded"。
对于JSON格式的响应数据,我们可以使用res.json()转为字典格式并通过字典取值提取响应字段的变量进行断言。假设我们要断言响应结果的url为"https://httpbin.org/post",form不为空且name和password是我们传的值,示例如下。
res_dict = res.json()
form = res_dict.get('form')
assert "https://httpbin.org/post" == res_dict.get('url')
assert form and "临渊" == form.get('name') and '123456' == form.get('password')
再次运行,结果和上次一致。没有报错即为assert断言通过,断言失败时会报AssertionError。
发送JSON格式数据
JSON格式是一种通用的数据格式,在Python中JSON实际为“符合JSON语法格式的字符串”,本质是str类型。JSON格式和Python的字典一一对应,略有不同,如JSON中的true/false/null对应字典中的True/False/None。我们同样可以使用字典来构造JSON请求的数据,然后传递够请求方法的json参数即可,示例如下。
import requests
url = 'https://httpbin.org/post'
json_data = {'name': '临渊', 'age': 18, 'on_site': True, 'favorite': None}
res = requests.post(url, json=json_data)
print(res.text)
URL参数和FORM变动格式中的数字实际都是转为字符串格式去发送的,而JSON中可以区分数字格式和字符串格式。如{"age": 18}和{"age":"18"}有可能是不一样的。响应文本打印结果如下。
{
"args": {},
"data": "{\"name\": \"\\u4e34\\u6e0a\", \"age\": 18, \"on_site\": true, \"favorite\": null}",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "70",
"Content-Type": "application/json",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.4"
},
"json": {
"age": 18,
"favorite": null,
"name": "\u4e34\u6e0a",
"on_site": true
},
"origin": "111.194.126.253, 111.194.126.253",
"url": "https://httpbin.org/post"
}
发送时,请求头中会自动添加"Content-Type": "application/json"。
细心的同学会发现,FORM表单格式发送的数据会出现在响应的form字段中,JSON格式的却出现在data字段中。这是因为JSON和XML等格式一样属于Raw(原始格式),即原样发送。但是在实际发送时仍要确保请求数据都转为ASCII(美国标准码)来传输。因此中文参数“临渊”在传输是会按utf-8编码转换为“\u4e34\u6e0a”。由于JSON格式中只能使用双引号,响应中data参数是一个JSON格式的字符串,需要使用转义字符“\”。
发送XML格式的数据
上例提到XML和JSON都属于Raw格式的数据,XML和JSON在Python中实际都是不同格式的文本字符串。我们将字符串传递给请求方法的data参数即可原样发送,即data参数有以下3重作用:
- data = {} 或 [(,), (,)]:接受一个字典或嵌套列表格式的数据,会按表单Url编码格式
- data = '':接受一个字符串或bytes二进制字符串,会原样发送(需要手动添加请求头,如果存在中文需要手动编码)
- data = open('...', 'rb'):接受一个文件对象,按binary格式流式上传。
发送XML格式的数据只要将XML格式的多行字符串传递给请求方法的data参数即可,示例如下。
import requests
url = 'https://httpbin.org/post'
xml_data = '''
<xml>
<name>临渊</name>
<age>12</name>
</xml>
'''
headers = {'Content-Type': 'application/xml'}
res = requests.post(url, data=xml_data.encode('utf-8'), headers=headers)
print(res.text)
由于xml_data数据中存在非ASCII码,需要将数据按utf-8格式编码为bytes二进制字符串发送。由于使用Raw格式发送数据时不会自动添加请求头,因此一般要手动在请求头中添加内容类型声明,并将构造的字典类型的请求头变量,传递给请求方法的关键字参数headers。响应结果如下。
{
"args": {},
"data": "\n<xml>\n <name>\u4e34\u6e0a</name>\n <age>12</name>\n</xml>\n",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "57",
"Content-Type": "application/xml",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.4"
},
"json": null,
"origin": "111.194.126.253, 111.194.126.253",
"url": "https://httpbin.org/post"
}
Raw格式的数据都会记录在该接口响应数据的data字段中。
Raw格式的请求(Text、JavaScript、JSON、XML、HTML等)都可以按这种方式发送。JSON请求自然也可以按原始方式发送,示例如下。
import requests
url = 'https://httpbin.org/post'
json_data_str = '''
{
"name": "临渊",
"age": 18,
"on_site": true,
"favorite": null
}
'''
headers = {'Content-Type': 'application/json'}
res = requests.post(url, data=json_data_str.encode('utf-8'), headers=headers)
print(res.text)
注意以上的json_data_str须是符合JSON格式的字符串,包括必须使用双引号,应该使用小写的true,无值应该是null,由于字符串中存在中文,同样要手动进行encode编码,同时要手动添加请求头指定内容类型。
为方便构造请求数据,也可以先构造一个字典格式的请求数据,再使用json.dumps(),将字典格式的数据转为JSON字符串发送,示例如下。
import requests
import json
url = 'https://httpbin.org/post'
json_data = {
'name': '临渊',
'age': 18,
'on_site': True,
'favorite': None
}
headers = {'Content-Type': 'application/json'}
res = requests.post(url, data=json.dumps(json_data), headers=headers)
print(res.text)
注意以上json_data是字典格式的变量,因此要使用True及None。在将字典转为JSON字符串时,需要首先导入json库。json.dumps()将字典格式的json_data转换为JSON字符串,并通过默认的ensure_ascii=True参数将中文转换为\u形式的ASCII字符(如“临渊”会转换为“\u4e34\u6e0a”),因此不再需要进行编码后发送。
发送Multipart/form-data请求(文件上传)
网页上的表单有两种,一种是不包含文件上传,所有用户输入或选择的数据都可以使用字符串格式表示,这种称为普通表单或纯文本表单,对应MIME类型为application/x-www-form-urlencoded。
另一种即包括普通输入框等,也包含一个或多个文件上传框。普通输入框中的变量值可以已字符串格式编码,而上传的文件(如图片文件)则不一定能直接转为字符串,要使用二进制格式。因此要使用多部分的混合格式,笔者称之为混合表单,对应MIME类型为multipart/form-data。在表单中,每个需要上传的文件和普通输入框一样对应一个指定的变量。因此同样可以使用字典格式组装混合表单的请求数据传递给请求方法的files参数即可,示例如下。
import requests
url = 'https://httpbin.org/post'
multi_form_data = {
'name': '临渊',
'age': '18', # 不能使用int类型
'avatar': open('/Users/apple/Pictures/robot.png', 'rb'),
'avatar2': open('/Users/apple/Pictures/robot.jpg', 'rb'),
}
res = requests.post(url, files=multi_form_data)
print(res.text)
表单数据中的数字要使用字符串格式的数字,文件要以rb二进制格式打开传输,支持多个变量以及多个文件。
文件类型的数据avatar可以只穿一个打开的文件对象open('/Users/apple/Pictures/robot.png', 'rb'),也可以传递三个参数:要保存的文件名,打开的文件及文件MIME类型,即
'avatar': ('robot.png', open('/Users/apple/Pictures/robot.png', 'rb'), 'image/png'),
比如有些接口上传Excel文件时必须声明文件名和MIME类型,如:
res = request.post(url, files={'upload_file':
('data.xlsx',
open('data.xlsx', 'rb'),
'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet')
})
MIME类型参考:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Basics_of_HTTP/MIME_types
发送Binary格式数据(单文件/流式上传)
import requests
url = 'https://httpbin.org/post'
res = requests.post(url, data=open('/Users/apple/Pictures/robot.jpg', 'rb'))
print(res.text)
JSON与字典的相互转换
JSON(JavaScript Object Notation),即JavaScript对象标记。 是一种通用的轻量级的数据交换格式。在Python中,JSON本质上是符合JSON格式的字符串(str类型),即JSON字符串。
JSON字符串中支持Object对象、Array数组、String字符串、Number数字、true/false布尔值、null空值6中数据类型,并支持层次嵌套。Python中的字典和JSON字符串中描述的数据类型一一对应,对应关系如下表所示。
| JSON字符串 | Python |
|---|---|
| Object | 字典 |
| Array [...] | 列表 [...] |
| String "..." | 字符串 '...' 或 "..." |
| Number 1.5或3 | 浮点型或整型 1.5或3 |
| true或false | True或False |
| null | None |
注意,JSON格式较为严格,和Python字典格式略有不同:
- 字典中的引号支持单引号和双引号,JSON格式只支持双引号
- 字典中的True/False首字母大写,JSON格式为true/false
- 字典中的空值为None, JSON格式为null
- 字典中可以使用#好注释,JSON中不允许使用任何形式的注释
- 字典列表最后一项后可以有逗号,JSON数组最后一项后不可以有逗号
作为一种标准格式的字符串,JSON方便在不同系统中进行数据交换,方便进进行传输和存储,却不方便从整段字符串中提取响应的字段对应的值。
而字典作为内存中的一种数据结构,可以很方便的对其中的数据进行提取或添加等操作。因此我们常常需要在JSON字符串和字典之间相互转换。
在接口请求中常用的转换如下。
- (1)使用字典格式构造请求数据
- (2)转为JSON字符串发送请求
- (3)服务端解析处理
- (4)返回JSON字符串格式的响应数据
- (5)转为字典格式提取相应的字段并断言
Python自带的json库提供JSON字符或JSON文件对象和字典之间的相互转换,主要方法如下:
- json.loads(JSON字符串)/json.load(JSON文件对象):JSON字符串/文件转字典
- json.dumps(字典)、json.dump(字典,文件对象):字典转JSON字符串/文件
使用示例如下。
import json
data = {
'name': '临渊',
'age': 18,
'on_site': True,
'favorite': None
}
# dict --> JSON
data_str = json.dumps(data)
print('字典转JSON字符串', type(data_str), data_str)
# JSON --> dict
data_dict = json.loads(data_str)
print('JSON字符串转回字典', data_dict)
# dict --> JSON文件
with open('data.json', 'w', encoding='utf-8') as f:
json.dump(data, f)
# JSON文件 --> dict
with open('data.json', 'r', encoding='utf-8') as f:
data_dict = json.load(f)
print('JSON文件转回字典', data_dict)
运行结果如下:
字典转JSON字符串 <class 'str'> {"name": "\u4e34\u6e0a", "age": 18, "on_site": true, "favorite": null}
JSON字符串转回字典 {'name': '临渊', 'age': 18, 'on_site': True, 'favorite': None}
JSON文件转回字典 {'name': '临渊', 'age': 18, 'on_site': True, 'favorite': None}
生成的data.json文件内容如下:
{"name": "\u4e34\u6e0a", "age": 18, "on_site": true, "favorite": null}
在使用json.dumps()将字典转为JSON字符串时,默认为确保ASCII码已方便HTTP传输会将中文进行转换,同时默认使用单行格式。如果想要更清晰的查看JSON字符串结果,可以使用ensure_ascii=False不进行转换,使用indent=2空2格缩进显示,sort_keys=True按key排序输出,示例如下。
import json
data = {
'name': '临渊',
'age': 18,
'on_site': True,
'favorite': None
}
data_str = json.dumps(data, ensure_ascii=False, indent=2, sort_keys=True)
print(data_str)
输出格式如下:
{
"age": 18,
"favorite": null,
"name": "临渊",
"on_site": true
}
通用的请求方法
PUT/DELETE等请求方法使用requests对应的方法即可。
- requests.get(url, **kwargs):发送GET请求
- requests.post(url, **kwargs):发送POST请求
- requests.put(url, **kwargs):发送PUT请求
- requests.delete(url, **kwargs):发送DELETE请求
- requests.head(url, **kwargs):发送head请求
- erquests.options(url, **kwargs):发送options请求
这些请求方法的参数和用法一致,必选参数为url,其他参数为可选参数,常用参数如下。
- url: 字符串格式,参数也可以直接写到url中
- params:url参数,字典格式
- data: 请求数据,字典或字符串格式
- headers: 请求头,字典格式
- cookies: 字典格式,可以通过携带cookies绕过登录
- files: 字典格式,用于混合表单(form-data)中上传文件
- auth: Basic Auth授权,数组格式 auth=(user,password)
- timeout: 超时时间(防止请求一直没有响应,最长等待时间),数字格式,单位为秒
这些方法都源于一个通用的请求方法requests.request(method, url, **kwargs)。这个通用的方法通过必选参数method来指定使用的请求动作。字符串格式,不区分大小写,即requests.get(url)相当于requests.request('get', url)。
因此我们可以用同样结构的的数据来组装任何的HTTP请求,示例如下。
import requests
res = request.request(
method='post', # 也可以只写'post',
url='https://httpbin.org/post', # 也可以只写'https://httpbin.org/post',
headers={},
data={'name': '临渊', 'password': '123456'}
)
print(res.text)
请求中也可以根据需求添加其他参数,这一组组键值对参数可以使用一个统一的字典来表示,即:
req = {
'method': 'post',
'url': 'https://httpbin.org/post',
'headers: {},
'data': {'name': '临渊', 'password': '123456'}
}
然后通过**req字典解包,可以将一个字典参数req重新还原为其中的4组参数,因此上例子可以改为。
import requests
req = {
'method': 'post',
'url': 'https://httpbin.org/post',
'headers: {},
'data': {'name': '临渊', 'password': '123456'}
}
res = request.request(**req)
print(res.text)
这样做的好处是可以将任何类型的HTTP请求数据配置到数据文件中(如JSON或Yaml文件),然后将数据转为字典直接发送。示例如下。
data.json文件内容:
[
{
"method": "get",
"url": "https://httpbin.org/get"
},
{
"method": "post",
"url": "https://httpbin.org/post",
"headers": {},
"data": {"name": "临渊", "password": "123456"}
}
]
发送请求脚本如下:
import requests
import json
with open('data.json', encoding='utf-8') as f:
datas = json.load(f) # 将JSON文件转为字典
for req in datas:
res = requests.request(**req)
print(res.text)
SSL证书验证
requests在请求HTTPS接口时,默认验证SSL证书,请求方法中默认参数为verify=True,如果想要关闭证书验证,可以设置为False,示例如下。
requests.get('https://www.baidu.com', verify=False)
不自动重定向
当遇到重定向接口,requests默认跟随重定向,返回所重定向接口的响应对象(<Response [200]>),对于一些单点登录后转向的接口,有时我们需要获取原接口响应中的token信息,则需要使用allow_redirects=False关闭自动重定向,使用方法如下。
import requests
res = requests.get('https://httpbin.org/status/302')
print(res)
res = requests.get('https://httpbin.org/status/302', allow_redirects=False)
print(res)
第一个自动跟随重定向,返回<Response [200]>,关闭重定向后返回<Response [302]>。
代理设置
requests支持使用代理,对于HTTP和HTTPS分别使用不同的代理,使用方式如下。
import requests
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
requests.get("http://example.org", proxies=proxies)
超时设置
requests支持对请求设置超时时间,以防止请求长时间无响应而阻塞,设置方法如下。
import requests
requests.get('https://github.com', timeout=5) # 设置整体的超时时间5s
requests.get('https://github.com', timeout=(3, 2)) # 分别设置连接和下载响应内容的超时时间3s,2s。
如果在超时时间内未完成响应,则抛出TimeoutError
授权设置(身份认证)
授权是请求身份验证的一些开放协议标准,授权协议很多,包括Basic Auth基础授权,Digist Auth摘要授权,Oauth等。
Basic Auth
Basic Auth基础授权使用用户名和密码来验证身份,在requests中使用方法如下。
import requests
requests.get('https://api.github.com/user', auth=('githab账号', '密码'))
OAuth2.0
需要使用requests-oauthlib,参考链接:https://requests-oauthlib.readthedocs.io/en/latest/oauth2_workflow.html
会话保持及默认配置
会话Session一般指客户端和服务端的一次连接交互过程。在使用requests.get()等方法时,每次会建立一个新的会话与服务器进行连接。这样不便于保持会话(如登录)状态,如果想要保持会话状态,可以使用同一个会话对象来请求所有接口,示例如下。
import requests
s = requests.Session() # 新建一个会话对象
s.get('http://httpbin.org/cookies/set/sessioncookie/123456789') # 使用该会话对象请求
r = s.get("http://httpbin.org/cookies") # 使用同样的会话对象请求
print(r.text)
会话对象还可以用来设置默认的请求头等HTTP配置,示例如下。
s = requests.Session()
s.auth = ('user', 'pass') # 在会话中设置默认授权
s.headers.update({'x-test': 'true'}) # 在会话中设置默认请求头
s.get('http://httpbin.org/headers', headers={'x-test2': 'true'}) # 默认请求头也会被发送
预制请求Preprared-request
假设有多个请求需要先准备好,再逐个发送,可以使用requests.Request()对象的prepare()方法生成预制请求对象,然后使用会话发送即可,示例如下。
import requests
s = request.Session()
req1 = requests.Request('GET', 'https://httpbin.org/get').prepare()
req2 = requests.Request('POST', 'https://httpbin.org/post', data={'a':1}).prepare()
s.send(req1) # 发送预制请求
s.send(req2, headers={'x-test': 'true'}) # 支持添加额外项
使用适配器
适配器用于对匹配到的指定形式的请求做特殊处理,可以直接使用requests.adapters中的HTTPAdapter给定响应参数,也可以继承HTTPAdapter或BaseAdapter自定义处理方式,示例如下。
import requests
s = requests.Session()
a = requests.adapters.HTTPAdapter(max_retries=3) # 设置最大重试3次
s.mount('http://', a) # 对该会话所有http://开头的请求使用
详细可参考API:HTTPAdapter 及 BaseAdapter
并发请求
requests本身并不支持异步。想要并发请求常用的有多线程多进程或gevent方式。
多线程
直接使用threading的Thread对象即可,通过target指定要运行的方法,示例如下。
import requests
from threading import Thread
def print_res(res, *args, **kwargs):
print(res.text)
s = requests.Session()
s.hooks={'response': print_res}
t1 = Thread(target=s.get, args=('https://httpbin.org/get',)) # 指定线程运行方法
t2 = Thread(target=s.post, args=('https://httpbin.org/post',), kwargs={'data': {'a': 1}})
t1.start() # 启动线程
t2.start()
t1.join() # 连接主线程
t2.join()
默认线程运行无法获取target函数的运行结果,这里给会话添加了默认hooks方法,来打印响应文本(也可以通过自定义请求方法来实现)。
如果想获取线程结果,需要继承Thread并编写自己的线程处理类,示例如下。
import requests
from threading import Thread
class MyThread(Thread):
def __init__(self, func, *args, **kwargs): # 改变线程的使用方式,可以直接传递函数方法和函数参数
super(MyThread, self).__init__()
self.func = func
self.args = args
self.kwargs = kwargs
self.result = None
def run(self):
self.result = self.func(*self.args, **self.kwargs) # 为线程添加属性result存储运行结果
t1 = MyThread(requests.get, 'https://httpbin.org/get')
t2 = MyThread(requests.post, 'https://httpbin.org/post', data={'a':1})
t1.start()
t2.start()
t1.join()
t2.join()
print(t1.result) # 响应对象
print(t2.result.text) # 响应对象的text属性即响应文本
使用gevent
pip install gevent
示例如下。
from gevent import monkey;monkey.patch_all() # 要放import requests上面
import requests
import gevent
g1 = gevent.spawn(requests.get, 'https://httpbin.org/get')
g2 = gevent.spawn(requests.post, 'https://httpbin.org/post', data={'a': 1})
gevent.joinall([g1, g2])
print(g1.value) # 响应对象
print(g2.value)
使用grequests
pip install grequests
grequests封装了gevent和requests方法,用起来更简单,示例如下。
import grequests
req_list = [
grequests.get('https://httpbin.org/get', ),
grequests.post('https://httpbin.org/post', data={'a': 1})
]
res_list = grequests.map(req_list)
print(res_list)
响应处理
res是请求返回的响应对象(变量名随意)。res.text会自动将二进制格式的响应数据,使用默认编码转为文本(字符串)格式。
res响应对象包含各种响应的信息,常用的如下。
- res.content:二进制响应数据
- res.text:将二进制响应数据按默认编码转为文本(字符串格式)
- res.json():将JSON格式响应文本(res.text)按转为字典(!!!非JSON格式响应文本,使用此方法会报JSONDecoderError)
- res.status_code:状态码
- res.reason:状态码说明
- res.headers:响应头
- res.cookies:响应Cookies(响应Cookies中有时候不能包含所有响应头的Set-Cookies内容,可以通过解析响应头获取)
- res.encoding:当前解码格式,可以通过修改req.encoding来解决一部分乱码问题
- res.apparent_encoding:明显编码,使用chardet库对响应数据分析出的编码格式
乱码处理
当res.encoding解码格式和res.apparent_encoding明显编码格式不一致时,便可能出现乱码,如请求百度首页,打印res.text会发现有乱码,重新设置res.encoding为明显编码的格式,再次打印res.text便可以修复乱码。示例如下。
import requests
res = requests.get('https://www.baidu.com/')
print(res.text) # 有乱码
print('解码格式', res.encoding) # 解码格式 ISO-8859-1
print('明显编码', res.apparent_encoding) # 明显编码 utf-8
res.encoding = res.apparent_encoding # 修改解码格式
print(res.text) # 乱码解决
文件下载(流式下载)
对应资源类接口(如图片链接),想要保持文件,可以直接使用res.content按二进制保存文件即可,示例如下。
import requests
res = requests.get('https://upload.jianshu.io/users/upload_avatars/7575721/5339c9d6-be6b-47cf-87cc-c0517467c6bc.jpg?imageMogr2/auto-orient/strip|imageView2/1/w/240/h/240')
with open('avatar.png', 'wb') as f:
f.write(res.content)
对应较大的文件,可是使用流式下载,示例如下。
import requests
res = requests.get('https://upload.jianshu.io/users/upload_avatars/7575721/5339c9d6-be6b-47cf-87cc-c0517467c6bc.jpg?imageMogr2/auto-orient/strip|imageView2/1/w/240/h/240')
with open('avatar.png', 'wb') as f:
for data in res.iter_content(128): # 按128字节分块保存
f.write(data)
with open('avatar.png', 'wb') as f:
for data in res.iter_content(128): # 按128字节分块保存
f.write(data)
Hooks使用
Hooks即钩子方法,用于在某个框架固定的某个流程执行是捎带执行(钩上)某个自定义的方法。
requests库只支持一个response的钩子,即在响应返回时可以捎带执行我们自定义的某些方法。可以用于打印一些信息,做一些响应检查或想响应对象中添加额外的信息,示例如下。
import requests
url = 'https://httpbin.org/post'
def verify_res(res, *args, **kwargs):
print('url', res.url)
res.status='PASS' if res.status_code == 200 else 'FAIL'
res = requests.get(url, data=data, hooks={'response': verify_res})
print(res.text)
print(res.status)
执行结果如下。
https://httpbin.org/post
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
<title>405 Method Not Allowed</title>
<h1>Method Not Allowed</h1>
<p>The method is not allowed for the requested URL.</p>
FAIL
verfiy_res是我们自定义的方法,第一个参数为响应对象,后面kwargs里是请求的一些配置。钩子方法不能返回响应对象以外的有意义值,否则会破坏后面对响应对象的处理。
由于该接口只支持post请求,使用get请求时响应状态码为405(请求方法不被允许),因此响应对象被添加的status的值为FAIL。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号