

Spark SQL catalyst概述和SQL Parser的具体实现
之前已经对spark core做了较为深入的解读,在如今SQL大行其道的背景下,spark中的SQL不仅在离线batch处理中使用广泛,structured streamming的实现也严重依赖spark SQL。因此,接下来,会对spark SQL做一个较为深入的了解。
本文首先介绍一下spark sql的整体流程,然后对这个流程之中涉及到的第一个步骤:SQL语法解析部分做一下较为深入的分析。
1,spark sql概述
首先截取一张任何介绍spark sql实现都会出现的图(如下)。
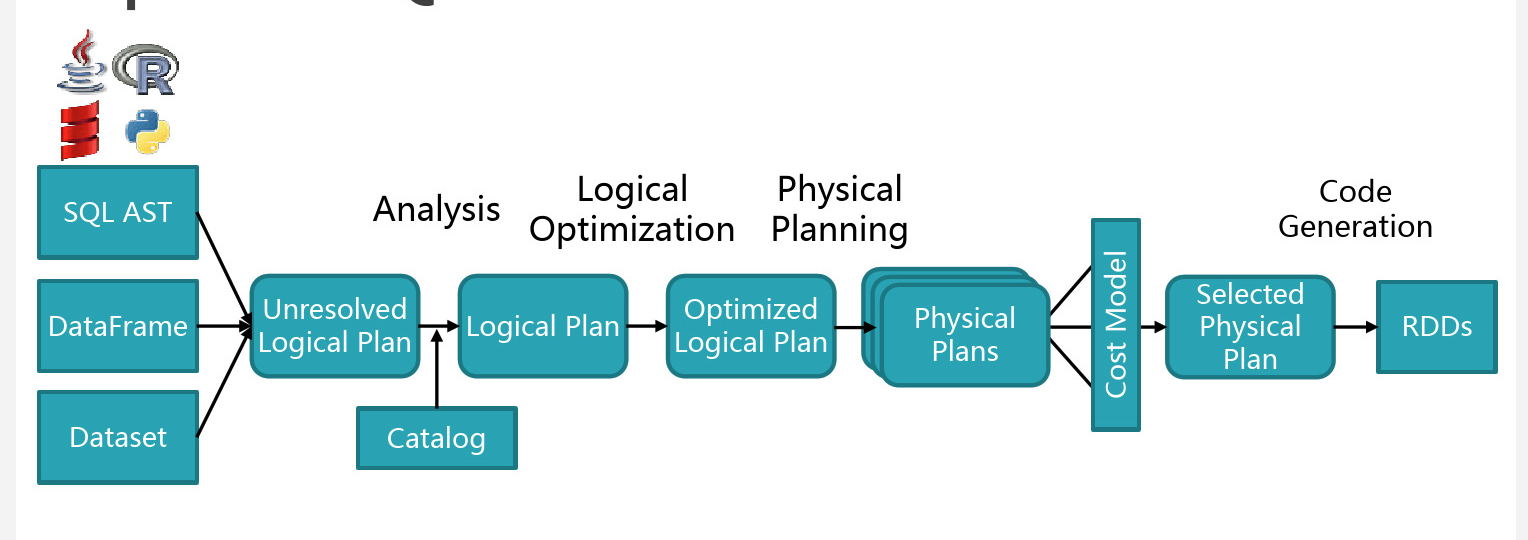
总体执行流程如下:从提供的输入API(SQL,Dataset, dataframe)开始,依次经过unresolved逻辑计划,解析的逻辑计划,优化的逻辑计划,物理计划,然后根据cost based优化,选取一条物理计划进行执行。从unresolved logical plan开始, sql的查询是通过抽象语法树(AST)来表示的,所以以后各个操作都是对AST进行的等价转换操作。 针对以上过程作如下几点说明:
1,编程接口:通过像df.groupBy("age")这样的Dataset接口构造查询过程,抽象语法树(AST)会自动建立。而通过“SELECT name, count(age) FROM people where age > 21 group by name” 这样的sql语句进行查询时,需要增加一个步骤是,需要将SQL解析成AST(spark 2.2中目前是借助于antlr4来做的,具体见后面分析)。
2,经过步骤1后,我们可以得到unresolved logical plan,此时像以上sql中的name,count(age),people都是unresolved attribute,relation等,他们是AST树TreeNode的一中类型,但是他们是不能被计算的(实现了Unevaluable接口)。
3,unresolved logical plan通过Analyzer模块定义的一系列规则,将步骤2中的unresolved的attribute,relation借助catalog去解析,如将之前提到的unresolved attribute转换成resolved attribute。此时,如果sql中某个表不存在或者列和表不对应,在此阶段便可以发现。Analyzer定义一系列部分规则如下:

4,解析成resolved logical plan以后,通过一系列优化规则会将resolved logical plan的AST转化成optimized logical plan的AST。这些优化包括基于规则和代价的优化,比如谓词下推,列值裁剪等。

5,AST到了optimized logical plan以后,利用如下的策略将逻辑计划转化成物理计划,物理计划是可以执行的计划。当有相关的action操作时,物理计划便可以执行。

2,SQL Parser的具体实现
在上节步骤1中提到,如果使用选择使用SQL进行查询,首先需要将SQL解析成spark中的抽象语法树(AST)。在spark中是借助开源的antlr4库来解析的。Spark SQL的语法规则文件是:SqlBase.g4。该文件以及生成的相关文件截图如下。

在生成的文件中SqlBaseBaseListener和SqlBaseBaseVistor分别代表两种遍历AST的方法,在spark中主要用了visitor模式。
接下来,将看一下spark中,当使用spark.sql("select *** from ...")时,sql怎么解析成spark内部的AST的?
1,用户调用的spark.sql的入口是sparkSession中sql函数,该函数最终返回DataFrame(DataSet[Row]),sql的解析的过程主要是在
sessionState.sqlParser.parsePlan(sqlText)中发生的。
def sql(sqlText: String): DataFrame = {
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
}
2,调用到parsePlan,将调用parse函数,传入的两个参数分为:sql语句,sqlBaseParse到LogicalPlan的一个函数。
override def parsePlan(sqlText: String): LogicalPlan = parse(sqlText) { parser =>
astBuilder.visitSingleStatement(parser.singleStatement()) match {
case plan: LogicalPlan => plan
case _ =>
val position = Origin(None, None)
throw new ParseException(Option(sqlText), "Unsupported SQL statement", position, position)
}
}
3,在parse函数中,首先构造SqlBaseLexer词法分析器,接着构造Token流,最终SqlBaseParser对象,然后一次尝试用不同的模式去进行解析。最终将执行parsePlan中传入的函数。

4,在步骤2中,astBuilder是SparkSqlAstBuilder的实例,在将Antlr中的匹配树转换成unresolved logical plan中,它起着桥梁作用。
astBuilder.visitSingleStatement使用visitor模式,开始匹配SqlBase.g4中sql的入口匹配规则:
singleStatement
: statement EOF
;
递归的遍历statement,以及其后的各个节点。在匹配过程中,碰到叶子节点,就将构造Logical Plan中对应的TreeNode。如当匹配到
singleTableIdentifier
: tableIdentifier EOF
;
规则时(单表的标识符)。即调用的函数如下:
override def visitSingleTableIdentifier(
ctx: SingleTableIdentifierContext): TableIdentifier = withOrigin(ctx) {
visitTableIdentifier(ctx.tableIdentifier)
}
可以看到将递归遍历对应的tableIdentifier,tableIdentifier的定义和遍历规则如下:
tableIdentifier
: (db=identifier '.')? table=identifier
;
override def visitTableIdentifier(
ctx: TableIdentifierContext): TableIdentifier = withOrigin(ctx) {
TableIdentifier(ctx.table.getText, Option(ctx.db).map(_.getText))
}
可以看到当匹配到tableIdentifier,将直接生成TableIdentifier对象,而该对象是TreeNode的一种。经过类似以上的过程,匹配结束后整个spark内部的抽象语法树也就建立起来了。
3,小结
本文主要介绍spark catalyst的总体执行情况,以及sql parse的具体实现细节。接下来,计划还将对Analyzer,Optimization,以及执行的过程做更深入的分析。

