
浅析GPU架构与异构计算CUDA
个人导航网站:yun916831.github.io
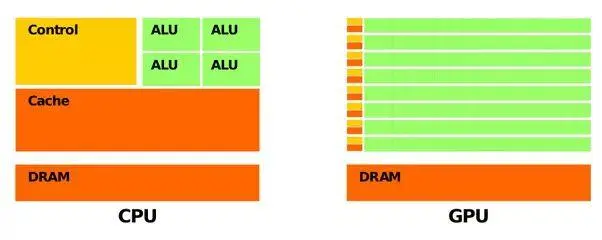
下图有几个重点的元素,也是我们下文重点要阐述的概念,绿色代表的是computational units(可计算单元) 或者称之为 cores(核心),橙色代表memories(内存) ,黄色代表的是control units(控制单元)。
因此想要理解GPU的底层核心构成,就必须明确这几个元素的作用,下文会逐一讲解每个元素的作用。
Computational units(cores)
总的来看,CPU的Computational units是“大”而“少”的,然而GPU的Computational units是“小”而“多”的,这里的大小是指的计算能力,多少指的是设备中的数量。通过观察上图,显然可以看出,绿色的部分,CPU“大少”,GPU“小多”的特点。
CPU的cores 比GPU的cores要更加聪明(smarter),这也是所谓“大”的特点。
在过去的很长时间里,CPU的core计算能力增长是得益于主频时钟最大的频率增长。相反,GPU不仅没有主频时钟的提升,而且还经历过主频下降的情况,因为GPU需要适应嵌入式应用环境,在这个环境下对功耗的要求是比较高的,不能容忍超高主频的存在。例如英伟达的Jetson NANO,安装在室内导航机器人身上,就是一个很好的嵌入式环境应用示例,安装在机器人身上,就意味着使用电池供电,GPU的功耗不可以过高。
CPU比GPU聪明,很大一个原因就是CPU拥有"out-of-order exectutions"(乱序执行)功能。出于优化的目的,CPU可以用不同于输入指令的顺序执行指令,当遇到分支的时候,它可以预测在不久的将来哪一个指令最有可能被执行到(multiple branch prediction 多重分支预测)。通过这种方式,它可以预先准备好操作数,并且提前执行他们(soeculative execution 预测执行),通过上述的几种方式节省了程序运行时间。
memory
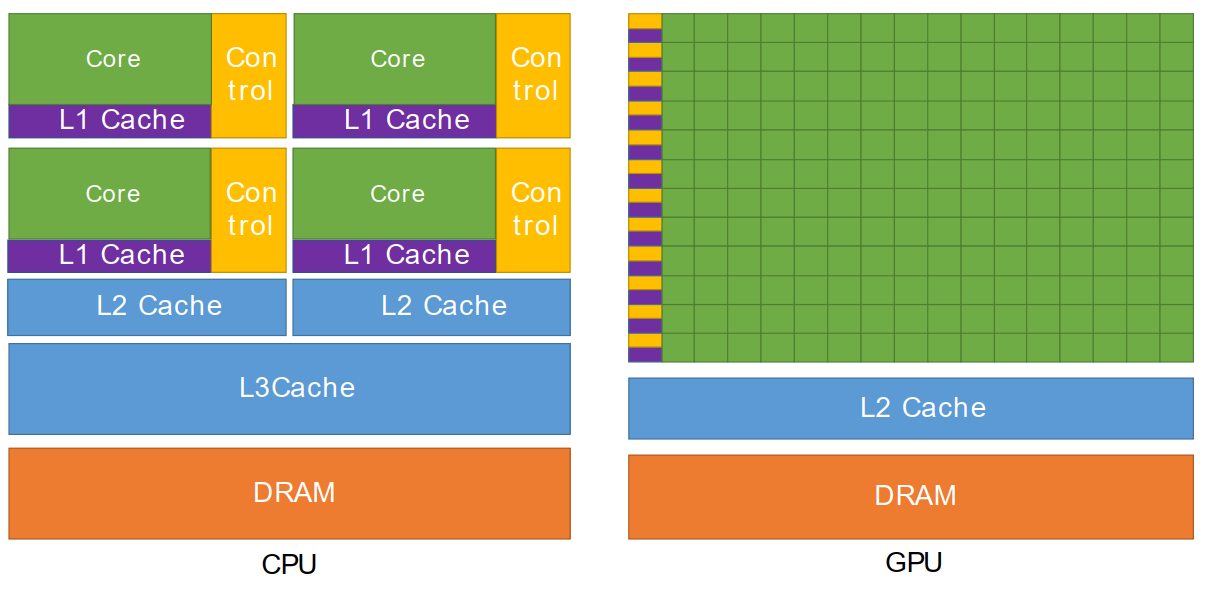
CPU的memory系统一般是基于DRAM的,在桌面PC中,一般来说是8G,在服务器中能达到数百(256)Gbyte。
CPU内存系统中有个重要的概念就是cache,是用来减少CPU访问DRAM的时间。cache是一片小,但是访问速度更快,更加靠近处理器核心的内存段,用来储存DRAM中的数据副本。cache一般有一个分级,通常分为三个级别L1,L2,L3 cache,cache离核心越近就越小访问越快,例如 L1可以是64KB L2就是256KB L3是4MB。
从第一张图可以看到GPU中有一大片橙色的内存,名称为DRAM,这一块被称为全局内存或者GMEM。GMEM的内存大小要比CPU的DRAM小的多,在最便宜的显卡中一般只有几个G的大小,在最好的显卡中GMEM可以达到24G。GMEM的尺寸大小是科学计算使用中的主要限制。十年前,显卡的容量最多也就只有512M,但是,现在已经完全克服了这个问题。
关于cache,从第一张图中不难推断,左上角的小橙色块就是GPU的cache段。
Turing架构
在 GPU 的组成模块中,与 CPU 中的 ALU 作用相同、执行具体计算操作的单元被称为 CUDA Core(处理核心),也就是流处理器 SP。多个流处理器和其他运算单元组成流多处理器(SM)架构,多个流多处理器进一步组成流处理器阵列(SPA),最终流处理器阵列和存储系统共同构成 GPU 的主要部分。 GeForce RTX 2080Ti 硬件架构 如下
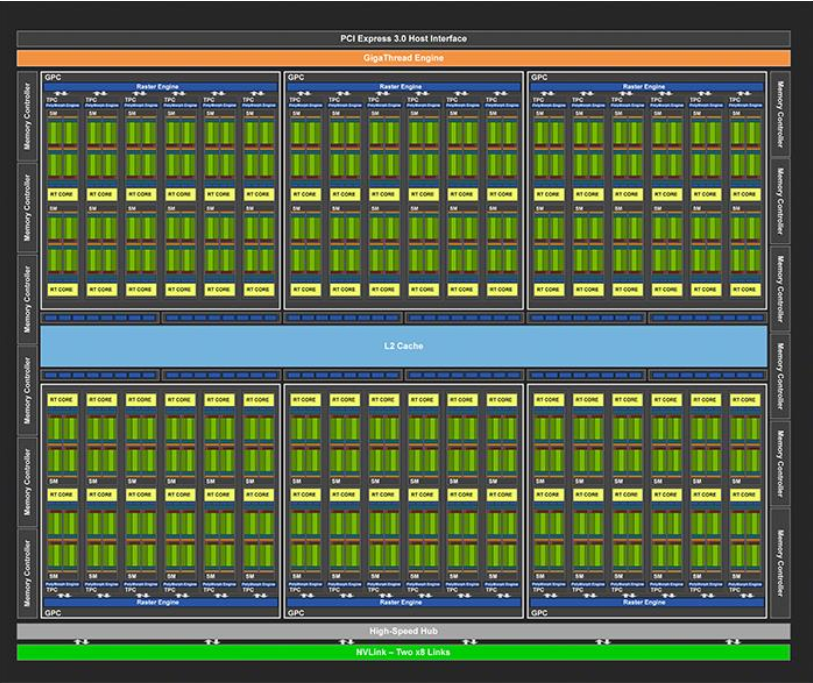
Turing架构目前一共有三种核心:
-
- TU102核心
- TU104核心
- TU106核心

从图中可看出,每个流多处理器(SM)所包含的资源如下:
(1)64个32位整数单元(INT32)、64个32位浮点单元(FP32)、8个张量核心(Tensor Core)和1个光线追踪核心(RT Core)。张量核心和光线追踪核心为图灵架构的专属处理单元,其中,Tensor核心本质上就是一个数据容器,其可以包含三维或者更多维度数据,专门负责矩阵数学运算的加速,以及人工智能相关的运算;RT核心专门负责处理光线追踪运算。
(2)16个特殊运算单元(Special Function Unit,SFU),负责执行特殊的数学运算,如三角函数、指数和对数等操作。
(3)4个线程束调度器( Warp Scheduler)和指令调度单元(Dispatch Unit)模块。这个模块负责线程束( warp)的调度工作,用于将一批批的warp发送给特定的计算核心SP执行运算,其中的指令调度单元负责将线程束调度的指令送往SP执行。32个线程组成一个warp,warp中所有线程并行的执行相同的指令。
(4)16个Load/Store (LDIST)单元,负责从GPU显存当中将数据内容写到寄存器,或者从寄存器当中写回到GPU显存。
参考:https://zhuanlan.zhihu.com/p/598173226
CPU+GPU混合架构下的多模式星载SAR回波快速仿真方法研究
