java集合详解
一、概念
1.集合的由来
数组长度是固定,当添加的元素超过了数组的长度时需要对数组重新定义,太麻烦,java内部给我们提供了集合类,能存储任意对象,长度是可以改变的,随着元素的增加而增加,随着元素的减少而减少。
2.数组和集合的区别
区别1 :
数组既可以存储基本数据类型,又可以存储引用数据类型,基本数据类型存储的是值,引用数据类型存储的是地址值。
集合只能存储引用数据类型(对象)集合中也可以存储基本数据类型,但是在存储的时候会自动装箱变成对象。
区别2:
数组长度是固定的,不能自动增长。
集合的长度的是可变的,可以根据元素的增加而增长。
3.数组和集合什么时候用
1.如果元素个数是固定的推荐用数组
2.如果元素个数不是固定的推荐用集合
4.集合继承体系图
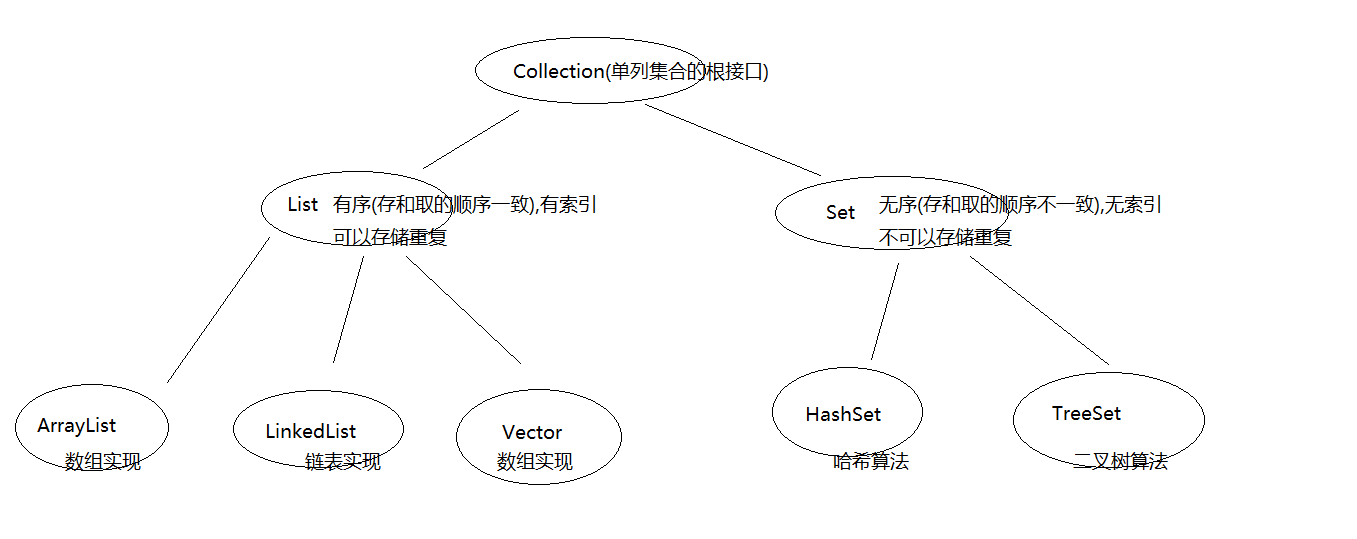
二、Collection与List具体方法及实现
1.Collection集合的基本功能及方法
Collection为集合的根接口,所以只能实例化他的子类。
Collection coll = new ArrayList();
Colleciton的方法如下:
boolean add(E e) //添加元素并返回是否包含指定元素布尔值
boolean remove(Object o) //从该集合中删除指定元素的单个实例
void clear() //从此集合中删除所有元素
boolean contains(Object o) //如果此集合包含指定的元素,则返回 true
boolean isEmpty() //如果此集合不包含元素,则返回 true 。
int size() //返回此集合中的元素数。
boolean addAll(Collection c)
boolean removeAll(Collection c)
boolean containsAll(Collection c)
boolean retainAll(Collection c)
......
注意:add方法如果是List集合会一直返回true,因为List集合可以存储重复元素;
如果是Set集合当存储重复元素的时候就会返回false。
2.集合的遍历之迭代器遍历
Collection c = new ArrayList(); c.add("a"); c.add("b"); c.add("c"); c.add("d"); Iterator it = c.iterator(); //获取迭代器的引用 while(it.hasNext()) { //集合中的迭代方法(遍历) System.out.println(it.next()); }
迭代器原理
迭代器原理:迭代器是对集合进行遍历,而每一个集合内部的存储结构都是不同的,所以每一个集合存和取都是不一样,那么就需要在每一个类中定义hasNext()和next()方法,这样做是可以的,但是会让整个集合体系过于臃肿,迭代器是将这样的方法向上抽取出接口,然后在每个类的内部,定义自己迭代方式,这样做的好处有二,第一规定了整个集合体系的遍历方式都是hasNext()和next()方法,第二,代码有底层内部实现,使用者不用管怎么实现的,会用即可。
3.List集合的特有功能概述和测试
A:List集合的特有功能概述
List list = new ArrayList();
void add(int index,E element)
E remove(int index)
E get(int index)
E set(int index,E element)
B、List集合存储学生对象并遍历
通过size()和get()方法结合使用遍历。
List list = new ArrayList(); list.add(new Student("张三", 18)); list.add(new Student("李四", 18)); list.add(new Student("王五", 18)); list.add(new Student("赵六", 18)); for(int i = 0; i < list.size(); i++) { Student s = (Student)list.get(i); System.out.println(s.getName() + "," + s.getAge()); }
4.ConcurrentModificationException并发修改异常
集合遍历时添加元素会抛出ConcurrentModificationException并发修改异常。
解决办法:
迭代器迭代元素,迭代器修改元素(ListIterator的特有功能add)。
ListIterator lit = list.listIterator();
lit.add("javaee");
三、ArrayList与LinkedList、泛型
1.ArrayList去除集合中字符串的重复值(字符串的内容相同)
public static ArrayList getSingle(ArrayList list) { ArrayList newList = new ArrayList(); //创建一个新集合 Iterator it = list.iterator(); //获取迭代器 while(it.hasNext()) { //判断老集合中是否有元素 String temp = (String)it.next(); //将每一个元素临时记录住 if(!newList.contains(temp)) { //如果新集合中不包含该元素 newList.add(temp); //将该元素添加到新集合中 } } return newList; //将新集合返回 }
2.LinkedList的特有功能
1.LinkedList类特有功能
public void addFirst(E e)及addLast(E e)
public E getFirst()及getLast()
public E removeFirst()及public E removeLast()
public E get(int index);
3.泛型
1.泛型概述
Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。
泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。
2.泛型的特征
B:泛型好处
提高安全性(将运行期的错误转换到编译期)
省去强转的麻烦
C:泛型基本使用
<>中放的必须是引用数据类型
D:泛型使用注意事项
前后的泛型必须一致,或者后面的泛型可以省略不写(1.7的新特性菱形泛型)
四、set集合及之类
1.HashSet原理
我们使用Set集合都是需要去掉重复元素的, 如果在存储的时候逐个equals()比较, 效率较低,哈希算法提高了去重复的效率, 降低了使用equals()方法的次数
当HashSet调用add()方法存储对象的时候, 先调用对象的hashCode()方法得到一个哈希值, 然后在集合中查找是否有哈希值相同的对象
如果没有哈希值相同的对象就直接存入集合
如果有哈希值相同的对象, 就和哈希值相同的对象逐个进行equals()比较,比较结果为false就存入, true则不存
2.将自定义类的对象存入HashSet去重复
类中必须重写hashCode()和equals()方法
hashCode(): 属性相同的对象返回值必须相同, 属性不同的返回值尽量不同(提高效率)
equals(): 属性相同返回true, 属性不同返回false,返回false的时候存储
3.LinkedHashSet的概述和使用
底层是链表实现的,是set集合中唯一一个能保证怎么存就怎么取的集合对象。
因为是HashSet的子类,所以也是保证元素的唯一性,与HashSet的原理一样。
4.TreeSet
1.特点
TreeSet是用来排序的, 可以指定一个顺序, 对象存入之后会按照指定的顺序排列
2.使用方式
a.自然顺序(Comparable)
TreeSet类的add()方法中会把存入的对象提升为Comparable类型
调用对象的compareTo()方法和集合中的对象比较
根据compareTo()方法返回的结果进行存储
b.比较器顺序(Comparator)
创建TreeSet的时候可以制定 一个Comparator
如果传入了Comparator的子类对象, 那么TreeSet就会按照比较器中的顺序排序
add()方法内部会自动调用Comparator接口中compare()方法排序
调用的对象是compare方法的第一个参数,集合中的对象是compare方法的第二个参数
c.两种方式的区别
TreeSet构造函数什么都不传, 默认按照类中Comparable的顺序(没有就报错ClassCastException)
TreeSet如果传入Comparator, 就优先按照Comparator
五、Map集合
1.集合框架
A:Map接口概述
将键映射到值的对象
一个映射不能包含重复的键
每个键最多只能映射到一个值
B:Map接口和Collection接口的不同
Map是双列的,Collection是单列的
Map的键唯一,Collection的子体系Set是唯一的
Map集合的数据结构值针对键有效,跟值无关;Collection集合的数据结构是针对元素有效
2.HashMap和LinkedHashMap

 浙公网安备 33010602011771号
浙公网安备 33010602011771号